一周之内,将Google的TurboQuant算法成功集成到llama.cpp推理框架中,一个由开发者与Claude Code、Codex协同完成的开源项目迅速走红。
Google Research于2026年3月24日发布了TurboQuant算法。这篇论文定位为一套面向大模型与向量检索场景的高效压缩量化方案,其核心目标是显著降低高维向量处理时的内存占用。

随后,一个名为 turboquant_plus 的第三方开源项目在GitHub上引发了广泛关注。
据社交媒体用户总结,该项目在短短7天内完成了从Python原型到llama.cpp框架内Metal GPU内核优化的完整流程。从项目README文档来看,其已完成C语言移植、Metal内核集成,并在Qwen 3.5 35B-A3B模型上验证了高达4.6倍的KV缓存压缩效果。
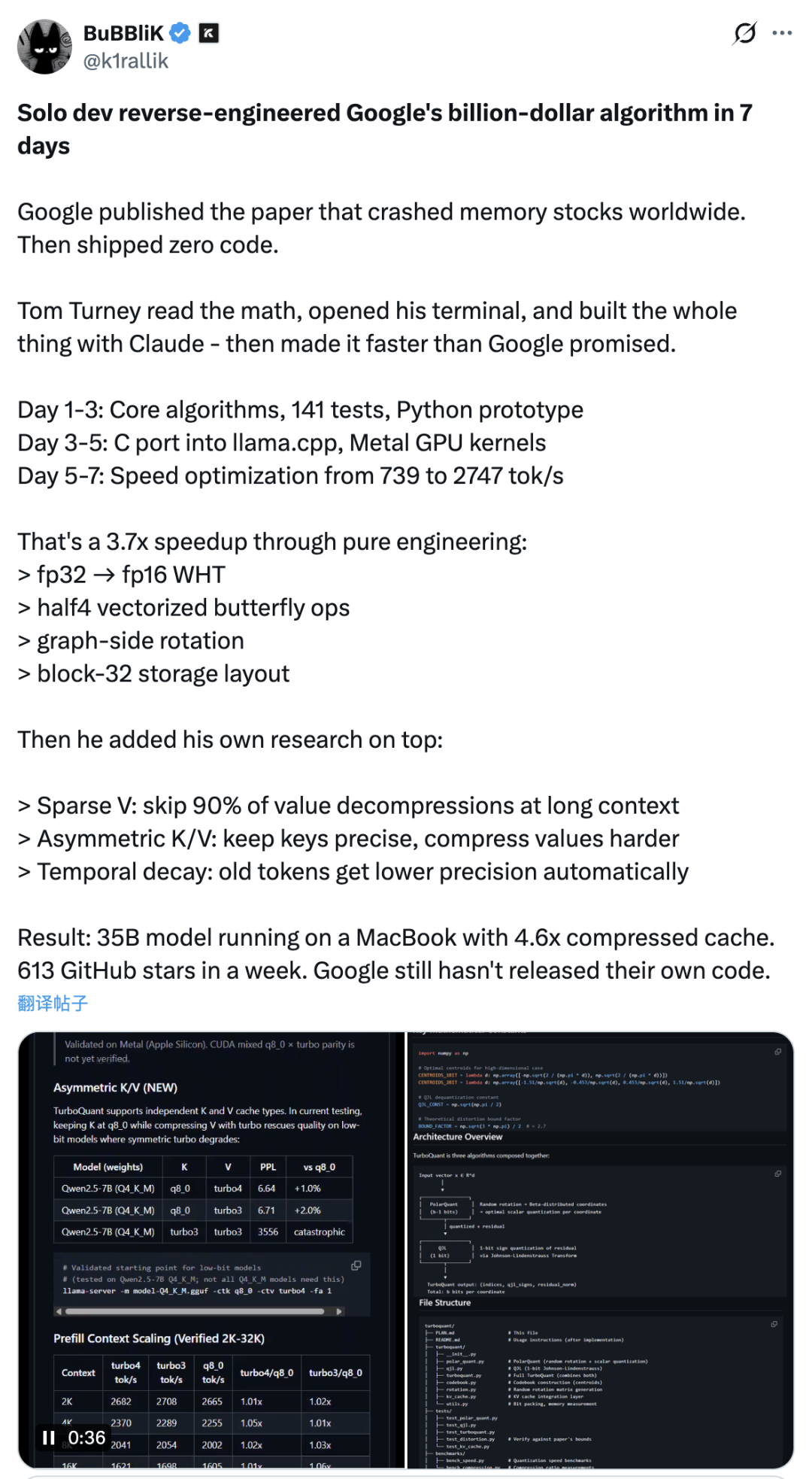
该项目仓库首页自称是 “TurboQuant (ICLR 2026)” 论文的实现版本,专注于本地大语言模型推理场景。README中明确指出,其重点是将KV缓存压缩技术应用于本地LLM推理,并计划进一步扩展到自适应比特分配、时间衰减压缩以及针对混合专家模型的感知压缩等方向。
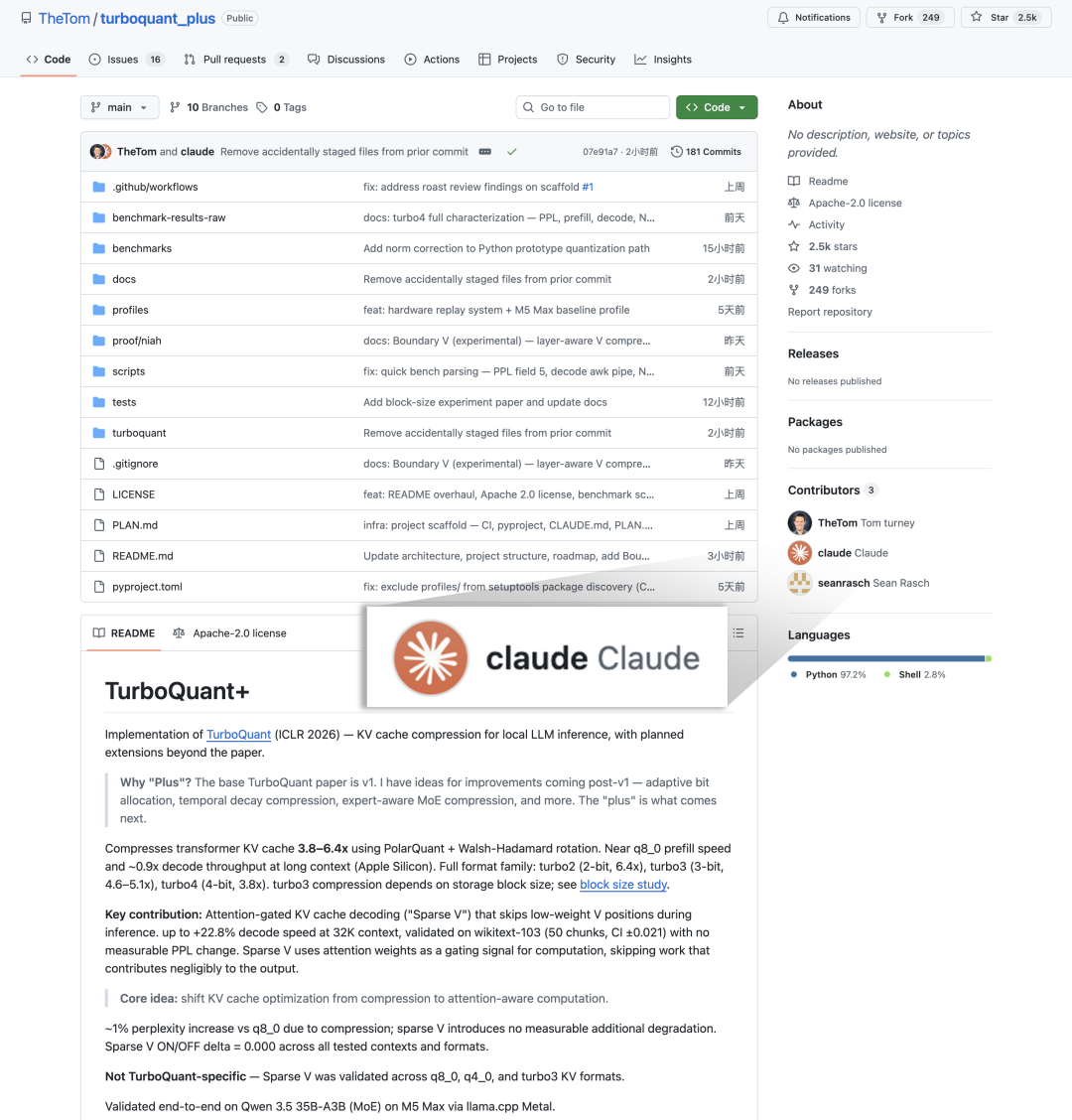
从项目描述来看,turboquant_plus 并不仅仅是简单的论文复现。
README中写道,该项目可将Transformer架构中的KV缓存压缩约3.8倍至6.4倍,提供了turbo2、turbo3、turbo4三种量化格式,并在Apple Silicon芯片上实现了接近q8_0量化级别的预填充速度,以及在长上下文场景下约0.9倍的解码吞吐量。
项目作者还额外加入了一项名为 “Sparse V” 的、基于注意力门控的解码优化技术。据称,该技术可在32K上下文长度下带来最高22.8%的解码速度提升,并且已在Qwen 3.5 35B-A3B模型上完成了端到端的验证。
真正让这个开源项目出圈的,不仅仅是其公布的性能数据,更是其背后所采用的开发模式。
项目作者Tom Turney在社交平台公开发文称,自己已将Google的TurboQuant论文实现并集成到了llama.cpp中,并适配了Apple Silicon的Metal计算内核。在同一条发文的说明里,他特别补充道,文中所说的“我”,实际上是“与claudecode、codex一起”,自己更多承担的是“引导和照看”的工作。

这标志着,一个由独立开发者主导、以Claude Code和Codex作为核心编程助手共同完成的个人开源项目,已经能够处理如此底层的系统级工程问题。
turboquant_plus 这类项目的出现,已超越了“AI帮忙补全代码”的初级阶段,意味着AI编程工具正开始深度介入真实的底层系统工程流程。
Google在3月24日刚刚发布算法论文,几天之内就有个人开发者借助多款AI编程工具,将学术成果快速推进到与llama.cpp框架集成、Metal内核优化、Apple Silicon硬件适配、以及本地35B大模型验证的工程实践层面。这清晰地表明,AI编程助手正在显著放大个人开发者的工程能力与效率。
过去,外界对于AI编程的想象,更多停留在生成前端页面、编写自动化脚本或搭建原型的层面。而这一次,讨论的焦点已经转向了KV缓存压缩、解码路径优化、Metal内核编写以及长上下文推理性能等硬核技术领域。
这个项目真正值得关注的,并不仅仅是“TurboQuant算法被复现了”这一结果,而是它展示了一种越发清晰的新范式:在前沿学术论文发布后,个人开发者已经可以借助Claude Code、Codex这类具备一定自主能力的编程工具,在极短的时间内将学术成果转化为可运行、可测试、并可广泛传播的工程实现。这种快速迭代和验证的能力,正在改变技术创新的节奏,也为广大开发者社区带来了新的可能性。
参考资料:
- https://github.com/TheTom/turboquant_plus
- https://mp.weixin.qq.com/s?__biz=MzI4OTc4MzI5OA==&mid=2247877893&idx=1&sn=f616f9741fdbdd277f90ccb520dbc342&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzI4OTc4MzI5OA==&mid=2247877597&idx=2&sn=a3be7ddc809b74ea566b77174997331a&scene=21#wechat_redirect
|  发表于 2026-4-2 11:44:26
|
查看: 234|
回复: 0
发表于 2026-4-2 11:44:26
|
查看: 234|
回复: 0
