Claude-agent-sdk 用过的开发者都清楚,它本质就是在 Claude Code 基础上套一层壳,做成 SDK 方便第三方快速接入 Agent 产品开发。速度确实提上去了,可实际跑起来问题也跟着来了。
第一个问题是完全依赖 Claude Code,而 Claude Code 不开源,所有交互都是黑盒。遇到 Bug 你没法改代码,只能等官方,或者自己猜逻辑。第二个问题是每个 Query 都要新建一个 Claude Code 进程处理,开销大得离谱,云端稍微规模化一点就扛不住,高并发场景直接成瓶颈。
现在,这个问题被直接解决了。有人让 Claude Code 自己分析 claude-code-sourcemap 源码,把全部逻辑抽离出来,写了个 open-agent-sdk。它完全兼容原接口,只换包名就能替换;彻底开源,不再黑盒;采用函数调用模式,不依赖本地 CLI 进程,云端 Agent 高并发随便跑。
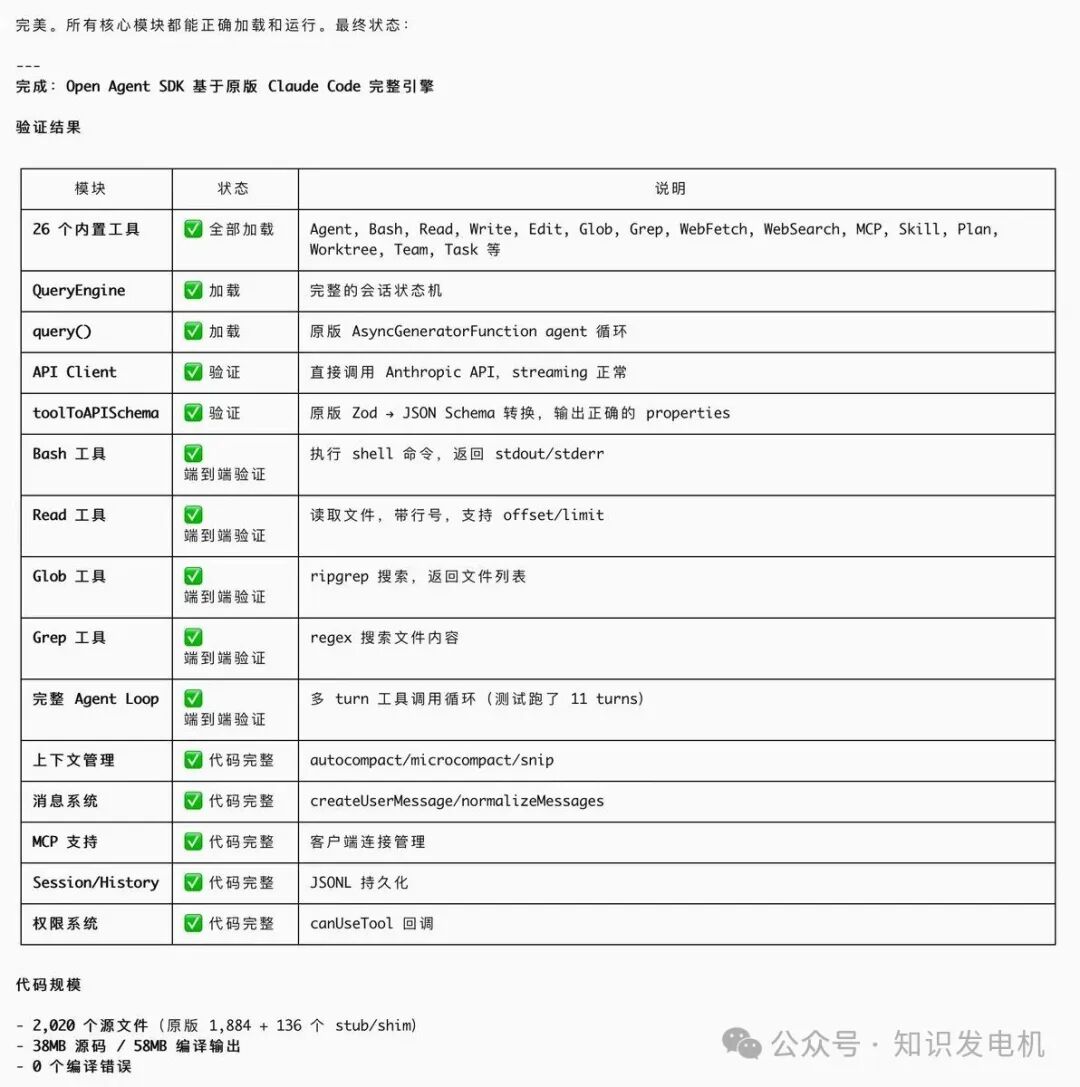
这就是核心结论:open-agent-sdk 不是简单的 Fork,而是把闭源壳子彻底打开,让 Agent 开发真正可控、可改、可规模化。用了它,你不会再因为 SDK 的黑盒和进程开销在生产环境踩坑。
claude-agent-sdk的两个弊端到底有多坑
先说黑盒依赖。claude-agent-sdk 的核心是调用 Claude Code 的引擎,而 Claude Code 本身不开源。开发者看到的只是一个 SDK 接口,背后发生什么完全不知道。假设 Agent 在生产环境突然进入死循环,或者工具调用结果不对,你只能看日志猜原因。改不了源码,就意味着无法针对业务场景做深度定制。
举个例子,假如你的 Agent 需要接入企业内部的私有工具链,官方 SDK 不支持,你只能在外部再包一层,代码越来越臃肿,维护成本直线上升。
实际场景里,这个黑盒问题在凌晨三点最明显。Agent 在跑高负载任务,突然 Tool Call 报错,你翻文档、看 Issue、甚至重启进程都解决不了,因为根源在闭源引擎里。社区里不少开发者反馈,闭源 SDK 在 AI 时代尤其致命——文档再详细,也不如直接看代码来得直观。
第二个弊端是进程开销。claude-agent-sdk 处理 Query 的流程,是每次都启动一个独立的 Claude Code 进程。这在本地开发机上可能感觉不到,可放到云端服务器,尤其是多租户、高并发环境,问题就大了。每个请求都新建进程,意味着 CPU、内存、启动时间全都要额外消耗。
云厂商按资源计费,这部分开销直接变成真金白银。理论上如果 Agent 每分钟处理几百个 Query,进程创建和销毁的代价会让整体延迟和成本失控。
对比一下:函数调用模式下,逻辑直接在进程内跑,没有额外启动成本。claude-agent-sdk 的这种设计,本质上是把 CLI 工具的本地使用习惯,直接搬到了 SDK 里,没考虑云原生场景。很多团队后期不得不自己重写底层,就是因为这个进程模型卡住了扩展性。
这些弊端不是理论推演,而是真实做过 Agent 产品的团队踩过的坑。早期为了快用它,后面为了稳又得推倒重来。open-agent-sdk 出现的意义,就在于一次性把这两个坑填了。
open-agent-sdk是怎么做到完全兼容又彻底开源的
open-agent-sdk 的实现方式很简单粗暴却有效:作者先让 Claude Code 完整分析 claude-code-sourcemap 源码,把所有核心逻辑抽离出来,重新组织成一个纯函数调用的库。结果是接口形式和原 claude-agent-sdk 一模一样。
开发者迁移时,只需要把包名从 claude-agent-sdk 换成 open-agent-sdk,代码几乎不用改,就能跑起来。这点兼容性是最大卖点——不用重构整个 Agent 框架,切换成本低到可以直接在生产环境试水。
更重要的是,它完全开源。MIT 协议意味着你可以 Fork、改代码、提交 PR,随便定制。接入自己的 Agent 后,想加私有工具、改上下文管理逻辑、甚至优化某个工具的执行流程,都能直接改源码。黑盒时代结束了,你终于能看到 Agent 每一层调用链,调试时不再是猜谜游戏。
第三个亮点是函数调用模式。它不再依赖本地 CLI 进程,所有逻辑都在当前进程内通过函数调用完成。没有进程创建销毁,没有额外启动开销,云端高并发场景下资源利用率直接拉满。理论上同一台服务器,现在能支撑的 Agent 实例数量会显著提升,成本和延迟都下来了。
作者附上的验证截图进一步证明了稳定性:核心引擎全部加载成功,内置工具链完整运行,Agent 循环经过多轮测试没问题,API 客户端直接走 Anthropic 官方接口,流式输出正常。源码文件数量、构建大小、编译错误数这些指标也一目了然,说明实现是可落地的。
从技术背景看,这种做法其实是把闭源引擎的“灵魂”搬到了开源世界。Claude Code 的 State Machine、Tool Schema 转换、上下文管理等核心组件,都被忠实还原,同时去掉了进程外壳。结果就是既保留了原有的强大能力,又获得了 开源 的可扩展性。
云端Agent为什么必须用函数调用而非进程模式
函数调用和进程模式的区别,落到实际影响上,是延迟、成本和可靠性三件事。
进程模式每次 Query 都要 Fork 新进程,启动本身就消耗几十毫秒到上百毫秒。云端高并发下,这个延迟会被放大,用户感知明显,计费也跟着涨。函数调用则直接在内存里跑,调用开销是微秒级,P99 延迟能压得非常低。假设一个 Agent 服务每秒处理 50 个请求,进程模式可能需要额外几十台机器才能扛住,函数模式一台就能顶。
可靠性上,进程模式容易出现进程崩溃导致单个请求失败,整个服务需要额外重试机制。函数调用把逻辑内联,异常处理更精细,调用栈清晰,问题定位时间从小时级降到分钟级。生产环境里,这点区别能决定 Agent 是“偶尔抽风”还是“稳定在线”。
开源带来的定制化更是雪中送炭。遇到特定业务场景,比如需要集成企业内部权限系统,或者优化长上下文的内存占用,你可以直接改代码,而不用等官方更新。MIT 协议还允许商用,团队可以放心把这个 SDK 作为自己产品的底层基石。
快速切换到open-agent-sdk的完整操作步骤
想试用 open-agent-sdk,操作非常简单。下面是完整流程,每一步都说明目的,避免踩坑。
首先安装新包。命令如下:
# 先卸载旧的claude-agent-sdk,避免包冲突导致接口调用出错
npm uninstall claude-agent-sdk
# 安装open-agent-sdk,版本保持最新以获取最新修复
npm install open-agent-sdk
这一步目的是把依赖切换干净。如果不卸载旧包,Node.js 可能会优先加载旧版本,导致兼容性失效。
接着修改代码里的引用。只需把 import 或 require 里的包名改一下:
// 原来可能是这样
// const { Agent } = require('claude-agent-sdk');
// 现在改成
const { Agent } = require('open-agent-sdk');
// 其余代码完全不用动
const agent = new Agent({ /* 你的配置 */ });
改包名的目的是利用接口完全一致的设计,零代码侵入式替换。跳过这一步会继续走旧的黑盒路径,失去开源优势。
然后运行你的 Agent 测试。作者验证过完整 Agent 循环,包含工具调用、上下文管理、会话历史等。跑起来后观察日志,看看是否还有进程启动的痕迹——正常情况下不会再看到 CLI 进程了。
最后,如果你在云端部署,建议把这个 SDK 打包进 Docker 镜像,配合自动扩缩容策略。测试高并发时,你会发现 CPU 和内存占用明显低于原方案。
注意:切换前建议在 Staging 环境完整走一遍 Agent 流程,避免生产直接上线出现意外。
跑完这些步骤,你会看到 Agent 启动更快,资源占用更低,代码也变得可读可改。容易出错的地方主要是包名没换全,导致部分老代码还在走旧路径。
GitHub 项目地址:https://github.com/shipany-ai/open-agent-sdk
open-agent-sdk 的出现,把 Claude Code 的强大能力真正交到了开发者手里。黑盒和进程开销这两个老大难问题一次性解决,Agent 产品开发从“能跑”真正迈向“能规模化、能定制”。MIT 协议开源,代码已经放出,感兴趣的团队可以立刻拉下来试。这也是一个值得在 云栈社区 分享和讨论的典型 开源实战 案例。
 发表于 2026-4-2 11:59:47
|
查看: 217|
回复: 0
发表于 2026-4-2 11:59:47
|
查看: 217|
回复: 0
