在很多人的印象里,Redis 只是一个高性能的缓存工具。但如果仅仅把它当作缓存来用,未免有些“大材小用”。事实上,Redis 凭借其丰富的数据结构和特性,能够解决分布式系统中的众多复杂问题,从提升性能到保障可靠性,作用巨大。
本文将从实际业务场景出发,详细解析 Redis 的十种高级用法,并提供可直接运行的代码示例,帮助你在项目中更好地驾驭 Redis。
一、布隆过滤器
在高并发系统中,缓存穿透是一个令人头疼的问题——大量请求绕过缓存直接查询数据库中不存在的数据,导致数据库压力骤增甚至宕机。布隆过滤器正是解决此类问题的利器。
1.1 什么是布隆过滤器
布隆过滤器是一种空间效率极高的概率型数据结构,用于快速判断一个元素是否可能存在于一个集合中。它的核心特点包括:
- 极省内存:存储上亿个元素,可能只需要百兆级别的内存。
- 存在误判:判断一个元素“不存在”是100%准确的;但判断一个元素“存在”则有小概率误判。
- 不可删除:传统的布隆过滤器不支持删除元素(如需删除,可考虑使用变体“计数布隆过滤器”)。
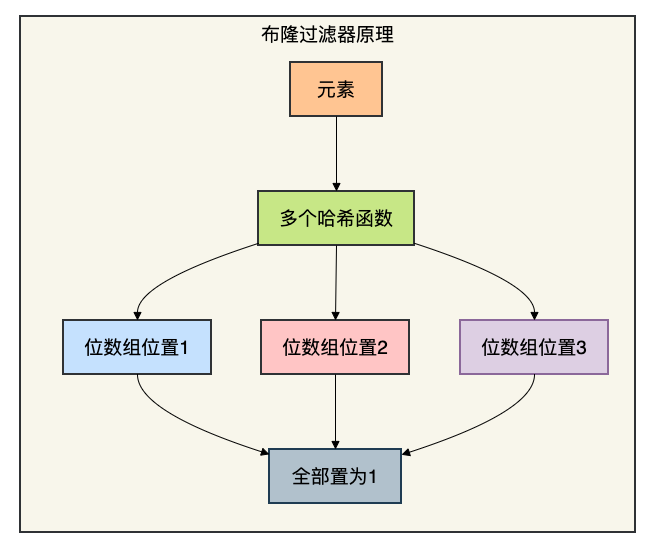
1.2 原理
向布隆过滤器添加元素时,会使用多个哈希函数将元素映射到位数组(Bit Array)的多个不同位置,并将这些位置置为1。
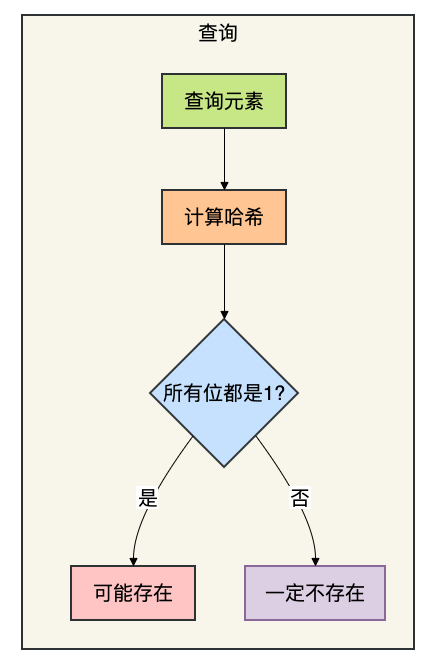
查询一个元素是否存在时,同样用这些哈希函数计算位置,并检查这些位置是否都为1。
1.3 代码示例(使用Redisson)
@Component
public class BloomFilterService {
@Autowired
private RedissonClient redissonClient;
private RBloomFilter<String> bloomFilter;
@PostConstruct
public void init() {
bloomFilter = redissonClient.getBloomFilter("user:bloom");
// 初始化:预计插入100万条数据,误判率0.01
bloomFilter.tryInit(1000000L, 0.01);
}
// 添加白名单数据
public void addUser(Long userId) {
bloomFilter.add(userId.toString());
}
// 查询前进行拦截
public User getUserById(Long userId) {
// 如果不在布隆过滤器中,直接返回空,避免查库
if (!bloomFilter.contains(userId.toString())) {
return null;
}
// 存在则查库(缓存兜底)
return queryFromDB(userId);
}
}
优点:内存占用极小,能有效防止缓存穿透。
缺点:存在误判,不支持删除。
适用场景:防止恶意请求穿透缓存、垃圾邮件过滤、爬虫URL去重。
二、Redisson分布式锁
使用简单的 SET key value NX EX seconds 命令实现分布式锁在复杂场景下存在隐患,例如锁提前释放、误删他人锁等。Redisson 提供了生产级可用的分布式锁解决方案。
2.1 为什么不用SET NX EX
- 锁过期时间设置不当:业务执行时间可能超过锁的过期时间,导致锁提前释放。
- 释放锁未校验持有者:可能释放其他客户端持有的锁。
- 无法自动续期:长任务执行中,锁可能因过期而失效。
2.2 Redisson分布式锁原理
Redisson 使用 Lua 脚本保证加锁、设置过期时间等操作的原子性,并内置了 看门狗(Watchdog)机制,在业务执行期间自动为锁续期,防止因执行时间过长导致锁过期。
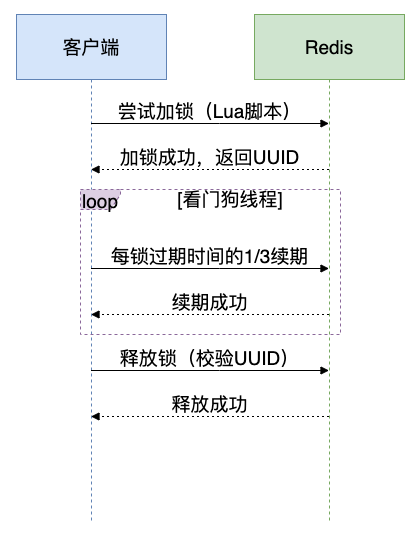
2.3 代码示例
@Service
public class OrderService {
@Autowired
private RedissonClient redissonClient;
public void processOrder(String orderId) {
RLock lock = redissonClient.getLock("order:lock:" + orderId);
try {
// 尝试加锁,最多等待10秒,锁有效期30秒(看门狗会自动续期)
if (lock.tryLock(10, 30, TimeUnit.SECONDS)) {
// 执行业务逻辑
doProcess(orderId);
} else {
throw new RuntimeException("获取锁失败");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("中断", e);
} finally {
// 必须释放锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
优点:自动续期避免业务执行中锁失效;支持可重入锁、读写锁、红锁等多种锁类型。
缺点:需引入 Redisson 客户端,比原生 Redis 命令稍重。
适用场景:分布式任务调度、库存扣减、订单创建等需要互斥访问的场景。
三、Redisson延迟队列
业务中常需要延迟处理,例如“订单30分钟未支付自动取消”。传统的数据库定时任务扫描方案效率低且存在延迟。Redisson 的延迟队列基于 Redis 的 Sorted Set 实现,精准且可靠。
3.1 原理图
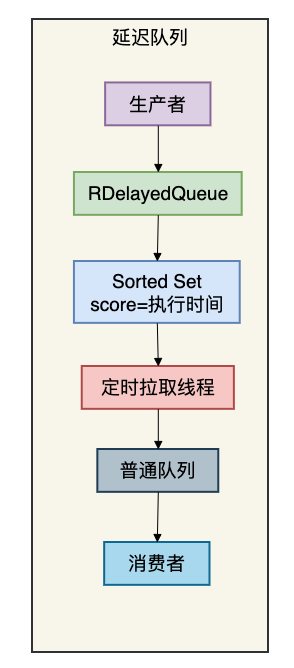
3.2 代码示例
@Component
public class DelayQueueService {
@Autowired
private RedissonClient redissonClient;
private RBlockingQueue<Order> blockingQueue;
private RDelayedQueue<Order> delayedQueue;
@PostConstruct
public void init() {
blockingQueue = redissonClient.getBlockingQueue("order:queue");
delayedQueue = redissonClient.getDelayedQueue(blockingQueue);
}
// 添加延迟任务
public void addOrder(Order order, long delay, TimeUnit unit) {
delayedQueue.offer(order, delay, unit);
}
// 消费者(单独线程)
@Async
public void startConsumer() {
while (true) {
try {
Order order = blockingQueue.take();
// 处理延迟到期的订单
processExpiredOrder(order);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
}
优点:延迟精准、支持分布式、数据可持久化。
缺点:依赖 Redis 稳定性;消息消费失败需要自行实现补偿机制。
适用场景:订单超时关闭、延迟通知、定时任务触发。
四、令牌桶限流
面对突发流量,限流是保护系统稳定的关键防线。利用 Redis + Lua 脚本可以轻松实现高性能的令牌桶限流算法。
4.1 令牌桶原理
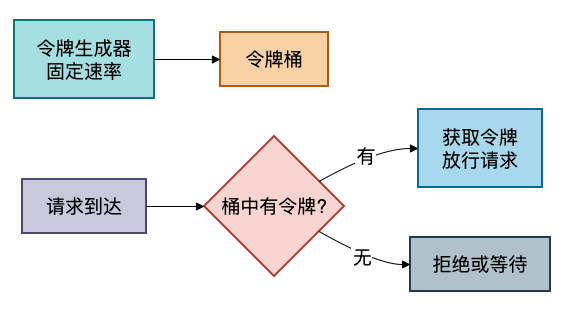
4.2 Lua脚本实现
@Component
public class RateLimiterService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String LUA_SCRIPT =
"local key = KEYS[1]\n" +
"local limit = tonumber(ARGV[1])\n" +
"local interval = tonumber(ARGV[2])\n" +
"local current = redis.call('get', key)\n" +
"if current and tonumber(current) >= limit then\n" +
" return 0\n" +
"else\n" +
" redis.call('incr', key)\n" +
" redis.call('expire', key, interval)\n" +
" return 1\n" +
"end";
public boolean tryAcquire(String key, int limit, int intervalSec) {
DefaultRedisScript<Long> script = new DefaultRedisScript<>(LUA_SCRIPT, Long.class);
Long result = redisTemplate.execute(script, Collections.singletonList(key), limit, intervalSec);
return result != null && result == 1L;
}
}
优点:支持一定程度的突发流量,实现相对简单。
缺点:如需更平滑或更复杂的限流策略(如滑动窗口),需额外实现。
适用场景:API接口限流、防刷、秒杀活动入口流量控制。
五、位图(Bitmap)统计
位图是 Redis 中一种极其节省内存的数据结构,它通过操作比特位(bit)来存储布尔值信息,非常适合海量数据的布尔统计。
5.1 应用场景
- 日活用户统计:将用户ID作为偏移量(offset),对应的 bit 置为 1 表示该用户当日活跃。
- 用户签到记录:一年 365 天,一个用户只需 365 个 bit(约46字节)即可存储全年的签到情况。
5.2 代码示例
@Component
public class BitmapService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 用户签到
public void signIn(Long userId, LocalDate date) {
String key = "sign:" + date.toString();
redisTemplate.opsForValue().setBit(key, userId, true);
}
// 统计某天签到人数
public Long countSignIn(LocalDate date) {
String key = "sign:" + date.toString();
return redisTemplate.execute(
(RedisCallback<Long>) connection -> connection.bitCount(key.getBytes())
);
}
// 统计连续签到天数(需结合Lua或BITFIELD命令)
public Long continuousSignDays(Long userId, LocalDate date) {
// 使用BITFIELD命令获取连续签到天数
// 实现略
}
}
优点:内存占用极低(1亿用户仅需约12MB),位运算速度快。
缺点:只能表示0/1状态,不适用于需要复杂统计的场景。
适用场景:用户签到、在线状态标记、实现简易布隆过滤器。
六、HyperLogLog
当需要统计海量数据的唯一值数量(如网站UV),且对精度要求不是100%时,使用 Set 集合会消耗巨大内存。HyperLogLog 是一种概率算法,用极小的固定内存完成近似去重统计。
6.1 原理
HyperLogLog 通过一定的概率统计方法,仅使用约 12KB 的固定内存,即可估算出数量级高达 $2^{64}$ 的集合基数,标准误差约为 0.81%。
6.2 代码示例
@Component
public class UVService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 添加访问记录
public void addVisit(String date, String userId) {
String key = "uv:" + date;
redisTemplate.opsForHyperLogLog().add(key, userId);
}
// 统计UV
public Long countUV(String date) {
String key = "uv:" + date;
return redisTemplate.opsForHyperLogLog().size(key);
}
// 合并多天UV(如计算周活跃用户)
public Long countWeeklyUV(List<String> dates) {
String destKey = "uv:weekly:" + LocalDate.now();
for (String date : dates) {
redisTemplate.opsForHyperLogLog().union(destKey, "uv:" + date);
}
return redisTemplate.opsForHyperLogLog().size(destKey);
}
}
优点:固定且极小的内存消耗,适合超大规模数据去重统计。
缺点:结果是近似值,且无法获取或判断集合中的具体元素。
适用场景:网站/文章 UV(独立访客)统计、大规模日志数据去重估算。
七、GEO地理位置
Redis 自 3.2 版本起内置了地理位置处理能力,基于 Sorted Set 实现,可以轻松实现“附近的人”、门店搜索等功能。
7.1 原理
使用 GeoHash 算法将二维的经纬度编码为一维的字符串,并作为 Score 存入 Sorted Set。支持按半径搜索、计算两点距离等操作。
7.2 代码示例
@Component
public class GeoService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 添加门店位置
public void addStore(Long storeId, double lng, double lat) {
String key = "stores:geo";
redisTemplate.opsForGeo().add(key, new Point(lng, lat), storeId.toString());
}
// 搜索附近门店
public List<Store> findNearbyStores(double lng, double lat, double radiusKm) {
String key = "stores:geo";
Circle circle = new Circle(new Point(lng, lat), new Distance(radiusKm, Metrics.KILOMETERS));
GeoResults<RedisGeoCommands.GeoLocation<Object>> results =
redisTemplate.opsForGeo().radius(key, circle);
List<Store> stores = new ArrayList<>();
for (GeoResult<RedisGeoCommands.GeoLocation<Object>> result : results) {
// 解析结果,构造Store对象
}
return stores;
}
// 计算两点距离
public Distance distanceBetweenStores(Long storeId1, Long storeId2) {
String key = "stores:geo";
return redisTemplate.opsForGeo().distance(key, storeId1.toString(), storeId2.toString());
}
}
优点:功能丰富,支持多种地理位置查询,性能高。
缺点:查询精度受 GeoHash 编码精度影响,更新地理位置可能需要删除后重新添加。
适用场景:外卖/打车附近的商户/司机搜索、朋友匹配、地理围栏。
八、Stream消息队列
Redis 5.0 引入的 Stream 是一个功能完备的轻量级消息队列数据结构,支持消费者组(Consumer Group)、消息确认(ACK)、消息历史回溯等特性,可作为 RabbitMQ 或 Kafka 在某些轻量场景下的替代方案。
8.1 架构图
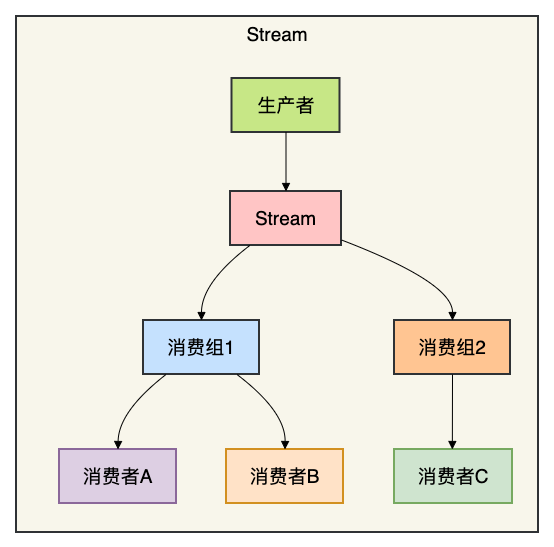
8.2 代码示例(使用Redisson)
@Component
public class StreamService {
@Autowired
private RedissonClient redissonClient;
private RStream<String, String> stream;
@PostConstruct
public void init() {
stream = redissonClient.getStream("order-stream");
// 创建消费组(如果不存在)
stream.createGroup("order-group", StreamMessageId.AUTO);
}
// 生产者
public void publish(String orderId) {
Map<String, String> data = new HashMap<>();
data.put("orderId", orderId);
data.put("timestamp", String.valueOf(System.currentTimeMillis()));
stream.add(data);
}
// 消费者(批量拉取)
@Async
public void consume() {
while (true) {
Map<StreamMessageId, Map<String, String>> messages =
stream.readGroup("order-group", "consumer-1", 10);
for (Map.Entry<StreamMessageId, Map<String, String>> entry : messages.entrySet()) {
// 处理消息
process(entry.getValue());
// 确认消费
stream.ack("order-group", entry.getKey());
}
// 无消息时短暂休眠
if (messages.isEmpty()) {
try { Thread.sleep(1000); } catch (InterruptedException e) { break; }
}
}
}
}
优点:支持消息持久化、消费组负载均衡、消息确认与重试、历史消息查看。
缺点:相比专业MQ,在消息堆积能力、高级路由规则等方面较弱。
适用场景:任务队列、日志收集、实时消息通知(如点赞、评论)。
九、Lua脚本
在需要多个 Redis 命令原子性执行,或减少网络往返开销时,Lua 脚本是最佳选择。Redis 保证 Lua 脚本在执行期间是原子的。
9.1 典型场景
- 扣减库存:检查库存、扣减库存必须在同一个原子操作中,防止超卖。
- 复杂条件锁:实现比
SET NX EX 更复杂的加锁逻辑。
- 数据聚合:在服务端一次性完成多个键值的计算。
9.2 代码示例
@Component
public class LuaScriptService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// Lua脚本:库存扣减
private static final String DECREASE_STOCK_SCRIPT =
"local key = KEYS[1]\n" +
"local count = tonumber(ARGV[1])\n" +
"local stock = redis.call('get', key)\n" +
"if not stock or tonumber(stock) < count then\n" +
" return 0\n" +
"else\n" +
" redis.call('decrby', key, count)\n" +
" return 1\n" +
"end";
public boolean decreaseStock(String productId, int count) {
DefaultRedisScript<Long> script = new DefaultRedisScript<>(DECREASE_STOCK_SCRIPT, Long.class);
Long result = redisTemplate.execute(script, Collections.singletonList("stock:" + productId), count);
return result != null && result == 1L;
}
// 带超时的分布式锁
private static final String LOCK_SCRIPT =
"if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then\n" +
" redis.call('expire', KEYS[1], ARGV[2])\n" +
" return 1\n" +
"else\n" +
" return 0\n" +
"end";
public boolean lock(String key, String value, int expireSec) {
DefaultRedisScript<Long> script = new DefaultRedisScript<>(LOCK_SCRIPT, Long.class);
Long result = redisTemplate.execute(script, Collections.singletonList(key), value, expireSec);
return result != null && result == 1L;
}
}
优点:保证操作原子性;减少网络通信次数,提升性能;复杂逻辑在服务端执行,减轻客户端压力。
缺点:脚本编写和调试相对复杂;错误的脚本可能阻塞 Redis。
适用场景:秒杀库存扣减、复杂限流、需要原子性的多步骤更新。
十、RedisJSON
RedisJSON 是一个 Redis 模块,允许直接将 JSON 文档存储在 Redis 中,并能够对文档内部的任意字段进行原子性的读写、更新和删除操作,无需反序列化整个文档。
10.1 安装
RedisJSON 需要作为模块加载(官方发行的 Redis Stack 版本已包含),或从源码编译后单独安装。
10.2 代码示例(概念演示)
需要注意的是,Spring Data Redis 的 RedisTemplate 默认不支持 RedisJSON 的特殊命令,通常需要使用支持 RESP3 协议且支持模块命令的客户端,如 Lettuce,并直接执行命令。
@Component
public class RedisJsonService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 存储JSON对象(需使用Lettuce等客户端直接调用JSON.SET命令)
public void saveUser(Long userId, User user) {
String key = "user:" + userId;
// redisTemplate.opsForValue().set(key, user); // 普通SET命令,存储为序列化字符串
// 实际应使用:connection.execute("JSON.SET", key, ".", objectMapper.writeValueAsString(user));
}
// 更新特定字段(如年龄)
public void updateUserAge(Long userId, int age) {
String key = "user:" + userId;
// 使用JSON.SET命令,仅更新指定路径($.age)的值
// redisTemplate.execute(connection -> connection.execute("JSON.SET", key, "$.age", String.valueOf(age)));
}
}
优点:可直接操作 JSON 内部字段,无需读写整个文档;可配合 RediSearch 模块实现 JSON 文档的复杂查询和全文索引。
缺点:需额外安装模块;存储 JSON 文档相比纯字符串或哈希,内存开销可能稍大。
适用场景:存储用户配置、会话信息、产品目录、动态表单数据等结构化文档。
总结
本文梳理的十种 Redis 高级用法,展现了其超越缓存的强大能力。合理运用这些特性,可以用较低的成本构建高性能、高可用的分布式系统。
| 用法 |
核心优势 |
典型场景 |
| 布隆过滤器 |
内存极省,防穿透 |
缓存击穿防护、垃圾邮件过滤 |
| Redisson分布式锁 |
自动续期,可重入 |
分布式任务、资源互斥访问 |
| 延迟队列 |
精准定时,分布式 |
订单超时、延迟通知 |
| 令牌桶限流 |
平滑突发流量 |
API限流、防刷 |
| 位图 |
极省内存,位运算快 |
用户签到、在线状态 |
| HyperLogLog |
固定极小内存,海量去重统计 |
网站UV统计 |
| GEO |
地理位置计算与搜索 |
附近的人、门店搜索 |
| Stream |
轻量级消息队列,支持消费组 |
任务队列、日志收集 |
| Lua脚本 |
原子操作,减少网络开销 |
库存扣减、复杂限流 |
| RedisJSON |
原生JSON文档操作 |
用户配置、动态数据存储 |
需要注意的是,Redis 本质上是内存数据库,在数据量极大的场景下,成本是需要考虑的因素。应根据业务特点,将 Redis 的强大特性与持久化数据库(如 MySQL、PostgreSQL)结合使用,构建健壮的架构。
希望这份指南能帮助你更深入地理解和应用 Redis。如果你有更多有趣的 Redis 实践经验,欢迎在 云栈社区 与其他开发者交流分享。
 发表于 2026-4-2 13:35:29
|
查看: 216|
回复: 0
发表于 2026-4-2 13:35:29
|
查看: 216|
回复: 0
