近期,北京大学的研究团队开源了一项名为 GREPO 的项目,展示了仅拥有 1000万参数 的小型图神经网络(GNN),在代码Bug定位任务上,其性能超越了参数规模达千亿级别的大型语言模型。
没错,10M对比千亿,差距足有四个数量级,但结果却是 小模型赢了。

首先需要明确,这里比拼的不是让AI生成代码,而是让AI定位Bug——给定一个GitHub Issue的描述,在一个拥有数十万行代码的庞大仓库中,精准地找到需要修改的具体文件乃至具体的函数。
这个任务听起来简单,实则非常困难。对于程序员来说,调试过程中往往有一半时间都耗费在“寻找问题所在”上。在大型项目中,成百上千的代码文件和错综复杂的依赖关系,使得快速锁定问题位置变得极具挑战性,往往依赖经验、直觉,甚至运气。
当前的AI代码助手也面临同样的困境。 以GitHub Copilot为代表的代码智能体已经能够根据Issue描述自动编写修复代码、运行测试并提交PR。然而,它们常常失败在第一步:找错了位置。 不是在错误的文件里徒劳修改,就是因为定位不准而引入了新的问题。这种“找不到北”的情况,极大地限制了智能体的实际效用。
北大研究团队发现了图神经网络(GNN)在这个特定任务上的天然优势。代码仓库本身就是一个复杂的图结构:函数调用、类继承、文件依赖都可以被视为图中的边。一个Bug通常并非孤立存在,它会在调用链中传播,在多级依赖关系里显现。
GNN的核心——消息传递机制,恰好擅长对这种多跳的、基于结构的关系进行建模和推理。 然而,过去缺乏一个专门针对“仓库级Bug定位”任务的标准化图数据基准。研究者若想在此方向探索,需要自行从GitHub爬取数据、构建图、标注、处理版本时间线,繁重的数据准备工作构成了很高的门槛。
GREPO项目的核心贡献,正是填补了这一空白。 它是一个标准化的“图数据+评测基准”,专为仓库级Bug定位而设计。其特点包括:
- 86个真实的Python仓库
- 47,294个真实世界中的Bug修复任务
- 异构时序图结构(将代码依赖关系和时间版本信息都编码进图中)
- 严格的泄露控制(确保训练数据不会泄露到测试集中)
此外,它还提供了一套增量构图方案。传统方法需要为每一次代码提交重建整张图,计算成本极高。GREPO的方案是只解析发生变更的文件,未变化的部分直接复用,这使得处理大规模代码仓库图变得高效可行。
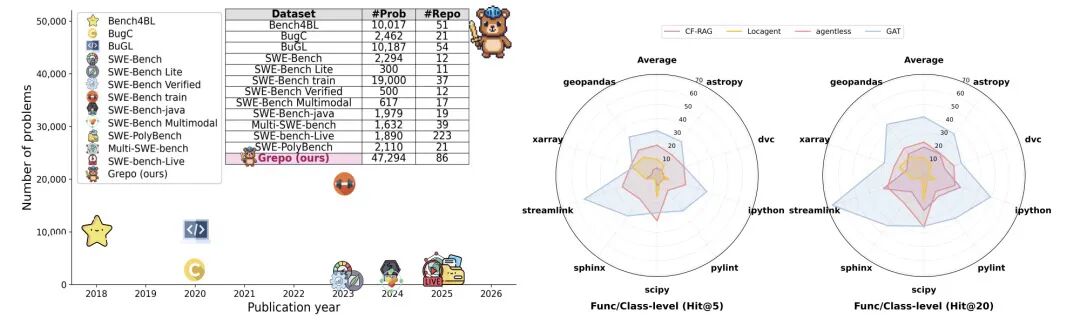
实验结果:10M参数 vs. 千亿参数
研究团队在论文中对比了多种方法,包括:
- LLM/智能体基线(直接使用大模型进行Bug定位)
- 多种GNN架构(如GCN、GAT、GATv2、GPS等)
结果令人印象深刻。 在9个代表性仓库的测试集上,仅拥有1000万参数的GATv2模型,在Hit@1/5/10/20等关键指标上全面超越了LLM基线。
这意味什么?
- Hit@1:模型给出的第一个猜测就是正确答案,GNN比大模型更精准。
- Hit@5/10/20:在模型给出的前K个候选位置中能覆盖到真正的修改位置,GNN的召回率更高。
小模型不仅赢了,而且赢得合情合理。Bug定位本质上是一个检索和推理任务,而非创造性生成任务。它更需要对代码结构的精确理解和多跳关系推理能力。在这个场景下,专门为图结构数据设计的GNN,比通用的Transformer架构更为对口。
“缩放定律”同样适用于GNN
更进一步的发现是,研究团队观察到了GNN在此任务上的“缩放定律”。随着训练所用仓库的数量从10个增加到77个,GNN在零样本设置(测试仓库完全未参与训练)下的表现持续提升。这表明,仓库级的Bug定位能力具有跨项目可迁移性——在一个项目上训练得到的模型,能够帮助调试另一个从未见过的项目。
这揭示了一个颇具前景的可能性:未来或许可以训练一个通用的“Bug定位专用GNN”,将其部署到各类代码仓库中,作为AI智能体的“导航系统”。智能体专注于代码生成和修改,而GNN则负责精确制导,指明问题所在。二者分工协作,各司其职。

这对AI开发范式的启示
过去几年,AI领域似乎被“越大越好”的思维主导。模型参数从十亿飙升至万亿,算力消耗呈指数级增长,但性能的边际收益却出现递减。
GREPO的研究提供了一个有力的反例:在拥有明确结构特征的特定任务上,小而专精的模型架构,可能比大而全的通用模型更高效、效果更好。 代码理解、Bug定位、结构推理等任务天然具备图结构特征,使用GNN比使用LLM更为自然,计算成本更低,且效果更优。
这或许预示着,AI的下一个重要突破方向,不一定在于构建更庞大的全能模型,而在于更精细地分解任务,为每一个子任务匹配合适的、专门的工具。在追求通用人工智能的同时,领域特定架构的价值正日益凸显。对于开发者而言,这项研究也为在开源实战中探索更高效的代码辅助工具提供了新思路,欢迎在云栈社区继续交流相关技术进展。
 发表于 2026-4-2 14:26:48
|
查看: 147|
回复: 0
发表于 2026-4-2 14:26:48
|
查看: 147|
回复: 0
