在微服务架构成为主流的当下,网关作为所有外部流量的统一入口,其重要性不言而喻。它肩负着路由转发、流量过滤、负载均衡、安全认证等一系列核心职责。然而,许多现有的网关解决方案要么配置繁琐复杂,要么在扩展性上捉襟见肘,导致后期的维护和定制化开发成本高昂。
本文将以 Openclaw 的三层解耦架构为蓝本,深入剖析其网关层(Gateway) 的核心设计思想。我们将从源码层面出发,逐一拆解路由匹配、过滤器链、负载均衡等关键机制,帮助你理解如何通过模块化设计,构建一个既高可扩展又易于维护的现代化网关系统。
一、Openclaw网关层整体架构概述
Openclaw的网关层采用了三层解耦设计,将路由、过滤、负载均衡等核心功能清晰地拆分为独立的模块,并通过依赖注入的方式实现灵活的组装与替换。这种设计哲学极大地降低了模块间的耦合度,为系统的扩展和维护打开了方便之门。其核心组件主要包括:
- 路由定位器(RouteLocator):负责根据请求的路径、方法等信息,匹配预先定义好的路由规则。
- 过滤器链(Filter Chain):像一条“流水线”,对进入的请求和返回的响应进行预处理和后处理,实现鉴权、限流、日志等功能。
- 负载均衡器(LoadBalancer):智能地将请求分发到上游服务的多个实例,保障服务的高可用性。
- 断言工厂(Predicate Factory):定义了路由匹配的各种条件规则,是路由精准定位的基础。
这种对微服务架构中核心组件的清晰划分,正是构建健壮网关系统的关键所在。你可以在云栈社区的后端 & 架构板块找到更多关于系统设计的深度讨论。
二、路由匹配机制:精准定位上游服务
路由匹配是网关最基础也是最核心的功能。Openclaw通过 RouteDefinition 类抽象了路由规则,它封装了路径、断言条件、过滤器列表等关键信息。
public class RouteDefinition {
private String id;
private URI uri;
private List<PredicateDefinition> predicates;
private List<FilterDefinition> filters;
// 省略 getter 和 setter 方法
}
路由匹配的具体工作由 RouteLocator 接口的实现类来完成。下面是一个带有缓存功能的核心实现代码:
public interface RouteLocator {
Flux<Route> getRoutes();
}
public class CachingRouteLocator implements RouteLocator {
@Override
public Flux<Route> getRoutes() {
return this.delegate.getRoutes()
.map(route -> {
// 将路由规则缓存起来,提升后续匹配性能
cache.put(route.getId(), route);
return route;
});
}
}
核心解析:CachingRouteLocator 会缓存路由规则以提升性能。当一个请求到达网关时,网关会遍历所有路由的断言(Predicate),找到第一个完全匹配的路由。每个断言的判断逻辑都由特定的 PredicateFactory 实现。例如,负责路径匹配的 PathRoutePredicateFactory:
public class PathRoutePredicateFactory extends AbstractRoutePredicateFactory<PathRoutePredicateFactory.Config> {
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return exchange -> {
PathMatcher pathMatcher = getPathMatcher();
String path = exchange.getRequest().getPath().value();
// 核心:匹配请求路径与路由规则中定义的模式(如 /api/**)
return pathMatcher.match(config.getPattern(), path);
};
}
}
三、过滤器链:请求的“流水线”处理
Openclaw网关的过滤器分为两大类:局部过滤器(GatewayFilter) 和 全局过滤器(GlobalFilter)。局部过滤器仅对配置了它的特定路由生效,而全局过滤器则作用于所有经过网关的请求。过滤器的执行顺序由 Ordered 接口的 getOrder() 方法返回值决定,数值越小,优先级越高。
过滤器链的核心执行逻辑位于 FilteringWebHandler 类中:
public class FilteringWebHandler implements WebHandler {
private final List<GatewayFilter> globalFilters;
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
Route route = exchange.getAttribute(GATEWAY_ROUTE_ATTR);
List<GatewayFilter> gatewayFilters = route.getFilters();
// 合并全局过滤器和当前路由的局部过滤器
List<GatewayFilter> combined = new ArrayList<>(this.globalFilters);
combined.addAll(gatewayFilters);
// 根据 Order 值对所有过滤器进行排序
AnnotationAwareOrderComparator.sort(combined);
// 创建过滤器链并开始执行
return new DefaultGatewayFilterChain(combined).filter(exchange);
}
}
核心解析:FilteringWebHandler 将全局过滤器和匹配到的路由的局部过滤器合并成一个列表,排序后形成一个完整的执行链。DefaultGatewayFilterChain 则通过递归的方式,依次调用链中的每一个过滤器:
public class DefaultGatewayFilterChain implements GatewayFilterChain {
private final List<GatewayFilter> filters;
private final int index;
@Override
public Mono<Void> filter(ServerWebExchange exchange) {
return Mono.defer(() -> {
if (this.index < filters.size()) {
GatewayFilter filter = filters.get(this.index);
// 创建下一个链节点(递归核心)
DefaultGatewayFilterChain chain = new DefaultGatewayFilterChain(filters, index + 1);
// 执行当前过滤器,并将下一个链节点传入
return filter.filter(exchange, chain);
} else {
// 所有过滤器执行完毕,开始转发请求到上游服务
return Mono.empty();
}
});
}
}
四、负载均衡:智能分发请求到服务实例
Openclaw网关集成了 Spring Cloud LoadBalancer,通过 LoadBalancerClientFilter 这个全局过滤器来实现服务实例的智能选择与请求转发。
public class LoadBalancerClientFilter implements GlobalFilter, Ordered {
private final LoadBalancerClient loadBalancer;
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
URI uri = exchange.getAttribute(GATEWAY_REQUEST_URL_ATTR);
String schemePrefix = exchange.getAttribute(GATEWAY_SCHEME_PREFIX_ATTR);
// 判断是否为负载均衡请求(以 lb:// 开头)
if (uri == null || (!"lb".equals(uri.getScheme()) && !"lb".equals(schemePrefix))) {
return chain.filter(exchange);
}
// 调用负载均衡器,选择一个可用的服务实例
ServiceInstance instance = loadBalancer.choose(uri.getHost());
// 重构请求URI,将服务名替换为具体的实例地址
URI requestUri = loadBalancer.reconstructURI(instance, uri);
exchange.getAttributes().put(GATEWAY_REQUEST_URL_ATTR, requestUri);
// 继续执行过滤器链
return chain.filter(exchange);
}
}
核心解析:当请求的URL scheme 为 lb://(例如 lb://user-service)时,该过滤器会介入工作。它调用 LoadBalancerClient 的 choose() 方法,根据配置的策略(如轮询、随机)从服务注册中心选择一个健康的实例,然后将URL中的服务名替换为该实例的真实地址(如 http://192.168.1.10:8080),从而完成请求的定向转发。
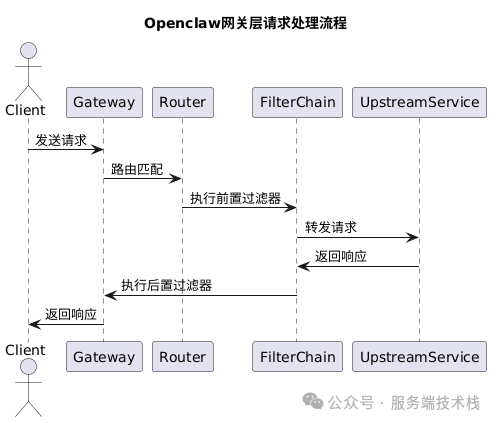
五、网关层请求处理全流程解析
结合开头的流程图,我们可以清晰地梳理出Openclaw网关层处理一个请求的完整生命周期:
- 客户端发起请求:请求首先到达网关服务器。
- 路由匹配:网关通过
RouteLocator 查询并匹配到对应的路由规则。
- 执行过滤器链(前置处理):请求进入过滤器链,依次执行所有符合条件的全局过滤器和该路由配置的局部过滤器(如身份验证、请求日志)。
- 负载均衡选址:如果路由指向的是一个服务组(
lb://),则由负载均衡器挑选一个合适的服务实例。
- 请求转发:网关将请求代理转发到选定的上游服务实例。
- 执行过滤器链(后置处理):上游服务返回响应后,响应会再次流经过滤器链,执行响应相关的后置处理逻辑(如修改响应头、记录响应时间)。
- 响应客户端:最终,处理完成的响应被返回给最初的客户端。
结语
Openclaw网关层通过 路由、过滤、负载均衡 三大核心模块的彻底解耦,展示了一种高内聚、低耦合的优雅设计。这种三层解耦架构不仅直击了传统网关在扩展和维护上的痛点,还为开发者提供了大量清晰、灵活的扩展点,使得根据业务需求定制专属的网关功能变得不再困难。
你在项目中使用或设计网关时,遇到过哪些印象深刻的挑战?对于Openclaw的这种模块化解耦思路,你认为其优势与潜在的权衡是什么?
 发表于 2026-4-2 15:07:31
|
查看: 112|
回复: 0
发表于 2026-4-2 15:07:31
|
查看: 112|
回复: 0
