
大模型的推理速度早已不再是瓶颈。真正卡住工程师脖子的,往往不是模型本身。
这话听起来有些反直觉,但凡真正做过视觉工程落地的人,想必都会心一笑。你可能花了几周时间调优YOLO、训练好一个检测模型,结果发现真正的麻烦才刚刚开始:如何把模型输出的那几个tensor变成能看懂的框?目标越线了吗?区域里有几个人?这个目标上一帧在哪里?每个项目似乎都要从头再写一遍这些“轮子”代码。
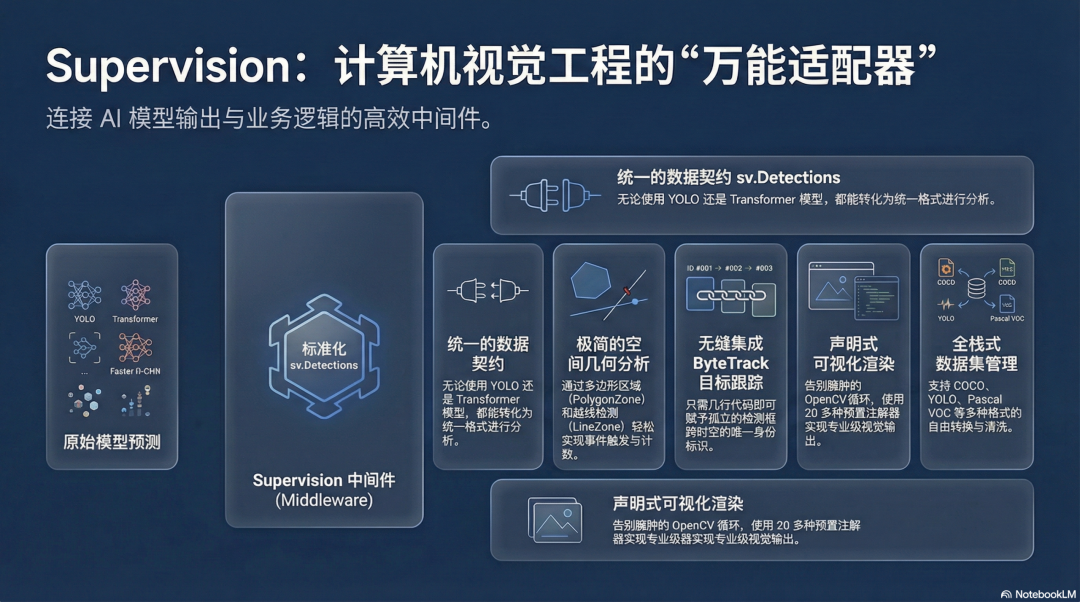
Roboflow的工程师团队大概也被这个问题折磨了很久,才憋出了 Supervision 这个开源神器。它内置了从边界框到热力图的多种Annotator,只需声明式调用,几行代码就能实现专业的可视化效果。
工程化鸿沟,比你想象的更严重
先说说背景。过去几年,目标检测模型在精度和速度上进步飞快,从YOLOv5到YOLO11,从Detectron2到PaddleDetection,推理速度基本都能达到实时级别。但研究人员和算法工程师们渐渐发现一个尴尬的现实——模型推理输出的是高维预测张量,而业务系统需要的是清晰的结构化决策。两者之间的这段“最后一公里”,每次都得手动去填。
典型的痛点可以归纳为几个:首先,不同框架的输出格式根本不统一。Ultralytics YOLO返回的结果、Hugging Face Transformers返回的结果、百度飞桨返回的结果,三套逻辑意味着三套解析代码。其次,坐标系转换、置信度过滤、NMS后处理这些事,每次都要重新写一遍,既繁琐又容易出错。最后,可视化、越线检测、区域统计等功能,听起来简单,真要自己动手实现,写起来相当费神。
Supervision想做的,就是彻底填平这段工程化鸿沟。它将自身定位为“模型无关”(Model-agnostic)的通用计算机视觉后处理中间件,通过一套标准化的数据结构和工具链,将“模型推理输出”与“业务逻辑决策”无缝连接起来。
sv.Detections:一切的起点,标准化的数据契约
整个Supervision的核心,是一个名为 sv.Detections 的数据类。简单来说,这是一张数据契约——无论你使用什么模型、什么框架进行推理,最终都能转换成这个统一的对象,后续所有操作都在这条标准化道路上进行。
它的存储方式基于NumPy的列式架构,字段包括 xyxy(边界框坐标,形状 n×4)、confidence(置信度)、class_id(类别索引)、mask(分割掩码)和 tracker_id(追踪ID)。这种列式设计意味着你可以直接进行矩阵级的布尔索引过滤,比如一行代码就能剔除所有置信度低于0.5的检测结果,底层走的是C驱动的向量化运算,效率相比逐条遍历有质的飞跃。
# 从 Ultralytics YOLOv8/11 推理结果直接转换
import supervision as sv
from ultralytics import YOLO
model = YOLO("yolo11x.pt")
results = model(frame)[0]
detections = sv.Detections.from_ultralytics(results)
# 布尔索引过滤,一行搞定
detections = detections[detections.confidence > 0.5]
更厉害的是它的工厂适配器模式。Supervision为主流框架都提供了对应的 from_xxx 方法:from_ultralytics、from_transformers(接Hugging Face)、from_mmdetection(接MMDetection)、from_detectron2、from_inference。当你更换推理框架时,只需修改一行代码,后面所有的注解、追踪、分析逻辑都无需变动。
最新的0.26.0版本还新增了 from_vlm 方法,可以直接解析通义千问-VL(Qwen-2.5 VL)等多模态大模型返回的混合文本响应中的边界框坐标。这意味着Supervision的触角已经开始从传统的AI模型检测模型,延伸向视觉语言模型生态,扩展方向颇具野心。
视频流分析三件套:越线、区域、追踪
Supervision真正让人眼前一亮的地方,在于它为视频流分析场景设计的几个组件,体现了深刻的工程思维。
PolygonZone 是多边形区域分析引擎。你在视频帧上圈定一个任意形状的多边形,它就能实时判断哪些检测对象位于该区域内。底层采用了“光栅化”预计算技术,将“点是否在多边形内”的几何判断,预先转换为一张掩码位图。查询时直接变成O(1)的索引操作,无论你画的多边形多么复杂,都不会成为性能瓶颈。
LineZone 是越线检测模块。它利用二维向量叉乘来判断目标位移方向,并内置了一套状态机来维护每个追踪目标的越线状态,有效避免了因目标在界线附近轻微抖动而导致的重复计数问题。这个细节处理得非常到位,实际工程中很多人自己实现越线检测时,第一个踩的就是这个坑。
ByteTrack 是集成进来的多目标追踪引擎。其核心思想是不轻易丢弃低置信度的检测框——这些框往往对应着被遮挡或处于边缘状态的目标。通过两阶段匹配机制,先将高置信度检测与现有轨迹进行匹配,再用低置信度检测进行第二轮补充关联,最终实现更连贯的轨迹维持。此外,还有CameraMotionCompensator(摄像机运动补偿)和DetectionsSmoother(轨迹抗抖动平滑)等配件,对于室外摄像头场景尤其有用。比如工地的监控摄像头若有轻微震动,轨迹会非常杂乱,开启补偿后则稳定得多。
通过下面这段代码,你能感受到整个链路的简洁程度,几乎没有冗余:
import supervision as sv
from ultralytics import YOLO
import numpy as np
model = YOLO("yolo11x.pt")
tracker = sv.ByteTrack()
box_annotator = sv.BoundingBoxAnnotator()
label_annotator = sv.LabelAnnotator()
def callback(frame: np.ndarray, index: int) -> np.ndarray:
results = model(frame)[0]
detections = sv.Detections.from_ultralytics(results)
detections = tracker.update_with_detections(detections)
labels = [f"#{tid}" for tid in detections.tracker_id]
frame = box_annotator.annotate(frame, detections)
return label_annotator.annotate(frame, detections, labels)
sv.process_video(source_path="input.mp4",
target_path="output.mp4",
callback=callback)
这段代码不到20行,却完成了加载模型、推理、格式转换、多目标追踪、绘制边界框、添加标签、视频输出等一系列操作——构成了一条完整的视频分析流水线。如果你没用过Supervision,实现同样功能可能需要写上百行代码。
Annotators的设计也值得一说。Supervision提供了超过15种注解器:基础的BoxAnnotator、圆角框RoundBoxAnnotator、目标追踪轨迹TraceAnnotator、热力图HeatMapAnnotator,还有专为隐私脱敏设计的BlurAnnotator(模糊)和PixelateAnnotator(像素化)。0.26.0版本中对HeatMapAnnotator进行了一次大幅优化,在1920×1080分辨率下渲染速度提升了惊人的28倍,足见团队对性能优化的认真态度。
除了视频分析,Supervision在数据集管理上也下了功夫。DetectionDataset 是统一的数据集管理类,支持COCO、YOLO、Pascal VOC三种格式的读取与转换,可以进行数据集合并和按比例分割。在进行数据清洗和格式迁移时,这个工具能节省大量精力,尤其是当需要整合多个来源的标注数据并转换成统一格式时,手动写脚本很容易出现各种细节Bug。
在模型评估方面,0.26.0版本自研了纯Python原生的 MeanAveragePrecision 模块,完全对齐pycocotools的计算标准,并解决了pycocotools在Windows上编译C扩展的老大难问题。这个模块现在已是Roboflow官方计算机视觉模型排行榜的底层评估引擎,颇具基础设施的意味。
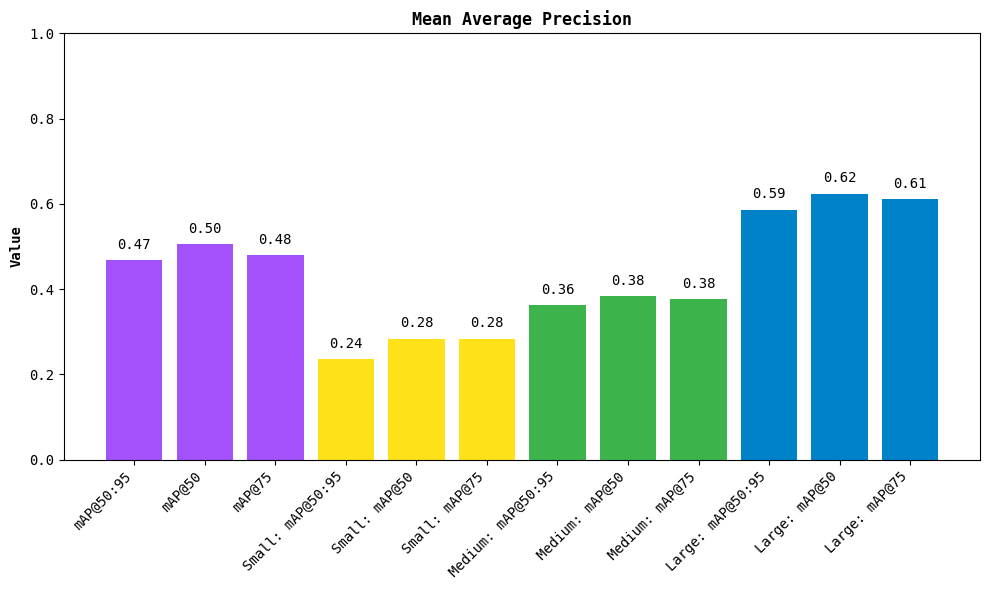
谈到性能优化,Supervision的策略非常清晰:凡是能用NumPy向量化解决的,绝不写Python循环。PolygonZone的光栅化预计算、HeatMapAnnotator的HSV颜色映射、mAP计算的矩阵化实现,都是这一思路的体现。此外,LineZone中还加入了 is_point_in_limits 边界检查,只对视野范围内的检测目标进行计算,减少了不必要的CPU开销——这类细节往往是决定视频流实时处理能否流畅运行的关键。
在真实应用场景中,Supervision被广泛应用于多个方向:智能交通(如违规变道识别、路口车流量统计)、零售门店客流分析(如顾客驻留时长统计)、工厂质检(如缺陷定位与区域报警)、安防监控(如非法闯入检测、隐私脱敏)。这些场景的共同特点是,都需要在稳定的视频流推理基础上,叠加复杂的空间逻辑分析,而这恰好是Supervision最擅长的领域。
当然,它并非没有短板。对像素级分割的深度支持、更丰富的时空复合事件逻辑(例如“目标A在区域B内停留超过30秒后触发”)、与国内PaddlePaddle等框架更深度的集成,目前仍在完善中。官方明确的下步方向包括:向视觉语言大模型全面延伸、支持低代码/无代码工作流编排,以及将像素级语义实体分割纳入完整的后处理链路。
在当下这个时间点,计算机视觉的工程生态正在快速重构。大模型降低了感知能力的门槛,却抬高了工程集成的复杂度。Supervision这类工具的价值,不仅在于让开发者少写几行代码,更在于在一个异构、碎片化的推理生态中,提供了一个稳定可靠的“接地层”。它做到了,而且做得比大多数同类工具更为彻底。访问其 GitHub 仓库,或许能为你接下来的项目带来新的灵感。欢迎在云栈社区分享你在使用类似工具时的经验和心得。
 发表于 2026-4-3 02:42:26
|
查看: 270|
回复: 0
发表于 2026-4-3 02:42:26
|
查看: 270|
回复: 0
