3月27日,在2026中关村论坛上,昆仑万维做了一件颇具突破性的事情:他们将其研发的实时交互式世界模型 Matrix-Game-3.0 完全开源。代码、模型权重以及详细的技术报告一并被放到了 GitHub 和 Hugging Face 上,采用宽松的 MIT 协议,供所有人自由使用。消息一出,迅速在国内外 AI 社区引发了广泛关注。
“世界模型”这个概念在过去几年一直是研究热点,但真正能投入实用、性能出色的产品却寥寥无几。之前的尝试往往局限在生成低分辨率的经典游戏画面,或者在像《我的世界》这样的环境中进行有限时长的模拟,而且常出现画面模糊、时序崩溃的问题。其核心矛盾在于,高分辨率、长时序一致性以及低延迟实时交互这三个需求似乎难以同时满足,构成了一个工程上的巨大挑战。
那么,Matrix-Game-30 是如何回应这个挑战的呢?它给出的答案是:在50亿参数规模下,实现720p分辨率、40FPS的实时画面生成,并且能维持长达一分钟以上的记忆一致性。数字听起来很吸引人,实际表现如何还得看具体的技术实现和评测数据。
- 720p 生成分辨率
- 40FPS 实时生成帧率
- 5B 主力模型参数
- 28B MoE大模型规模
- 64× VAE时空压缩比
- 96.3% 人类盲评胜率
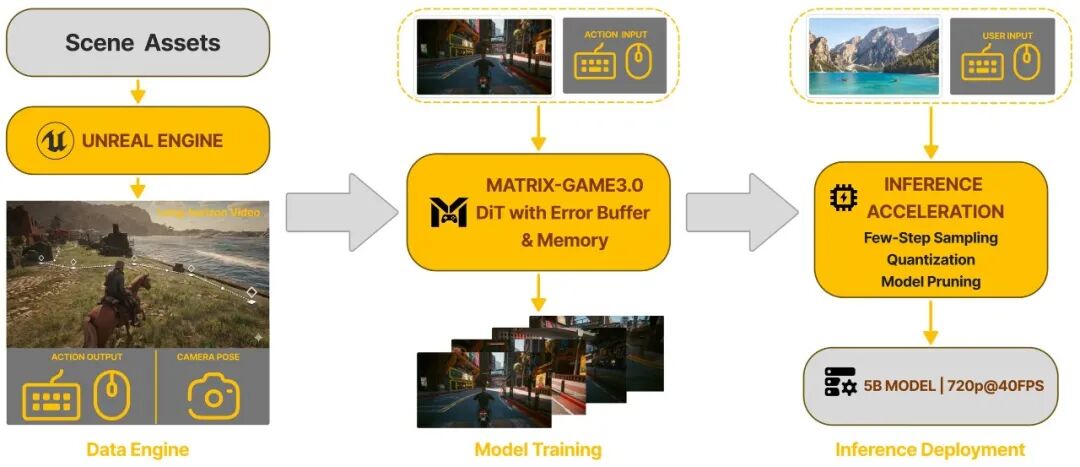
三层架构撑起这套系统
整个系统由数据引擎、模型训练和推理部署这三层紧密咬合驱动,形成了一个端到端的闭环。
模型层是整个系统的核心。其底层采用了内存增强型扩散 Transformer(DiT)。这种架构巧妙地将长期记忆帧、短期历史帧以及当前待生成的目标帧,全部置入同一个注意力空间中进行联合建模。这意味着模型不再是“从零开始”想象每一帧,而是能够“带着记忆”进行连贯生成,这是保证时序稳定性的关键。
自回归生成有一个固有的顽疾——误差累积。第一帧稍有偏差,后续帧就会越来越离谱,最终导致画面彻底崩坏。为了解决这个问题,团队在训练阶段引入了一个巧妙的“误差缓冲区”机制。简单来说,系统会显式记录每一步生成结果与真实帧之间的残差(误差),然后通过一个衰减系数 γ,将这些偏差重新“注入”给模型进行训练。这相当于强迫模型学会“把跑偏的轨迹拽回来”。这个思路有些反直觉,但消融实验证明其效果非常显著。

推理层则依赖于分布匹配蒸馏(DMD)技术。传统的扩散模型通常需要迭代50步去噪才能生成高质量图像,这完全无法满足实时交互的需求。DMD 的核心思想是直接优化学生模型与教师模型在概率分布上的差距,使用得分函数进行对齐。这使得学生模型仅需3步甚至更少的采样步骤,就能输出与教师模型质量接近的结果。再结合 INT8 量化和专门优化的轻量化 VAE 解码器(MG-LightVAE,解码速度最高提升5.2倍),整个推理链路才得以跑出 40FPS 的实机指标。
跨视角一致性是许多世界模型的“死穴”。例如,你向左转头看到一棵树,再转回来时,那棵树还在原地吗?Matrix-Game-3.0 采用了基于普吕克坐标编码的相机感知记忆检索系统。该系统能根据当前镜头的朝向,实时计算与历史帧的空间重叠度,从而只将“相关”的历史内容拉入当前帧的注意力计算中。同时,系统会将第一帧作为一个全局锚点持续注入信息,防止生成风格发生漂移。因此,当你回头看时,树还是那棵树,不会出现“幻觉”。

数据怎么来的,这才是真正的护城河
模型性能的上限,很大程度上由数据决定。Matrix-Game-3.0 背后是一个工业级的“无限”数据引擎,它融合了三大数据来源:基于虚幻引擎5生成的合成场景数据、自动化采集的3A游戏数据,以及经过增强的真实世界视频数据。合成数据提供了完美的物理规律基准,游戏数据贡献了丰富的纹理和建筑多样性,而真实视频则将照片级的真实感提升到了新高度。这三路数据互补,覆盖了超过1000个不同的场景。
还有一个值得特别关注的数据集:Matrix-Game-MC。这是专门针对《我的世界》生态策划的,包含了超过2700小时的无标签游戏视频(用于无监督预训练),以及超过1000小时带细粒度动作标签的高质量片段——键盘的离散操作和鼠标的连续移动轨迹都被精确标注。这批数据让模型不仅仅是“看过”这个世界,更是“理解”了在其中该如何行动。
训练过程分为两个阶段:第一阶段进行大规模预训练,让模型建立起对空间深度和物理动力学的基本理解;第二阶段则使用带动作标注的数据进行微调,从而实现帧级精确的控制。
在 GameWorld Score 这套综合评测体系下,Matrix-Game-3.0 的表现对当前主流的开源基准模型形成了全面优势。具体对比如下:
| 指标 |
Matrix-Game-3.0 |
Oasis |
MineWorld |
| 鼠标准确度 |
0.95 |
0.56 |
0.64 |
| 键盘准确度 |
0.95 |
— |
— |
| 对象一致性 |
0.76 |
— |
0.51 |
| 时间一致性 |
0.97 |
— |
— |
| 人类盲评胜率 |
96.3% |
对照组 |
对照组 |
与谷歌 DeepMind 的 Genie 3 进行横向比较:Genie 3 同样支持 720p 实时交互,但其帧率为 24FPS,持续时长只有几分钟,且动作空间相对有限。而 Matrix-Game-3.0 不仅将帧率提升至 40FPS,支持分钟级的长序列记忆,动作控制精度也更高——最关键的是,它完全开源,而 Genie 3 目前仍是闭源产品。
这东西真正能改变什么产业
世界模型的产业价值,绝不应只局限于游戏领域。
先说游戏产业本身。传统的3A游戏开发流程耗时极长,美术团队需要手工进行贴图、骨骼绑定和场景搭建,一个复杂场景可能就要耗费数周。如果未来能将世界模型作为“神经渲染引擎”嵌入游戏开发管线,让玩家所见的世界由模型实时推理生成,那将意味着理论上无限大的可探索地图成为可能,同时开发成本可能降至传统方式的几分之一。这并非遥不可及的科幻,而是正在逼近的现实。
在自动驾驶领域,其价值更为直接。当前进行极端场景测试时,工程师需要在仿真软件中手动搭建测试环境,一个稍微复杂的场景就可能要花费好几天。而有了 Matrix-Game-3.0 这类模型,只需输入一张参考图片和一段描述,就能在几秒钟内生成一个物理规律准确的交互式数字孪生沙箱,供智能体进行强化学习训练。这在成本和时间效率上都是数量级的提升。研究已验证,该模型能够模拟在室内办公室环境中进行复杂驾驶的场景,这是一种出色的跨域迁移能力。

机器人训练面临类似的瓶颈。具身智能当前的一大挑战就是数据匮乏:真实世界采集成本高昂,而现有的仿真平台又往往过于理想化。世界模型生成的合成训练数据,兼具多样性和物理合理性,正好能填补这一空白。正如北京智源研究院在《2026十大AI技术趋势》报告中指出的,合成数据将成为自动驾驶和机器人领域“降低训练成本、提升性能的关键资产”。
Matrix-Game-3.0 的出现,标志着“神经交互式模拟器”从学术论文走向了可实际部署的工程系统。数字世界与真实世界的边界,正在被这样的技术一点点消融。对于开发者和研究者而言,这意味着一个全新的、充满可能性的工具箱已经敞开。所有代码和模型都已上传至 GitHub 和 Hugging Face,正如昆仑万维首席科学家所言,这便是其技术底气的最佳证明。技术社区的朋友们,是时候上手体验,亲自做出判断了。关于此类前沿技术的更多开源动态和实践心得,也欢迎大家在云栈社区交流讨论。
 发表于 2026-4-3 02:39:53
|
查看: 225|
回复: 0
发表于 2026-4-3 02:39:53
|
查看: 225|
回复: 0
