一、AI 时代视频处理单元(VPU)的战略演进与功能定位
在当前异构计算体系中,视频处理单元(VPU)的职能已经发生了根本性的范式转移。它不再仅仅是执行数学压缩的硬核模块,而是演进为整个 人工智能 系统的“视觉感知中枢”。VPU 的性能直接决定了后端 NPU(神经网络处理器)的“数据燃料”质量。一旦 VPU 输出的视频流存在编码噪声或伪影,就会迫使 NPU 额外消耗计算资源进行滤波处理,甚至可能直接导致 AI 推理精度的不可逆下降。
在 AI 生态中,VPU 的战略价值根据应用场景被清晰地划分为 Physical AI(物理 AI)与 Cloud AI(云端 AI)两大驱动方向。
物理 AI 与云端 AI 核心架构需求矩阵
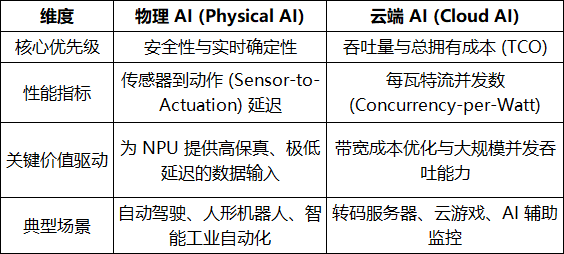
这种转变意味着,VPU 必须从单纯的“编解码引擎”升级为具备语义识别能力的“智能前处理器”。其目标是在整个计算环路中,通过降低总线占用率来缓解系统级的“存储墙”瓶颈。

二、“玲珑”V560/V760(代号“峨眉”)微架构深度解构
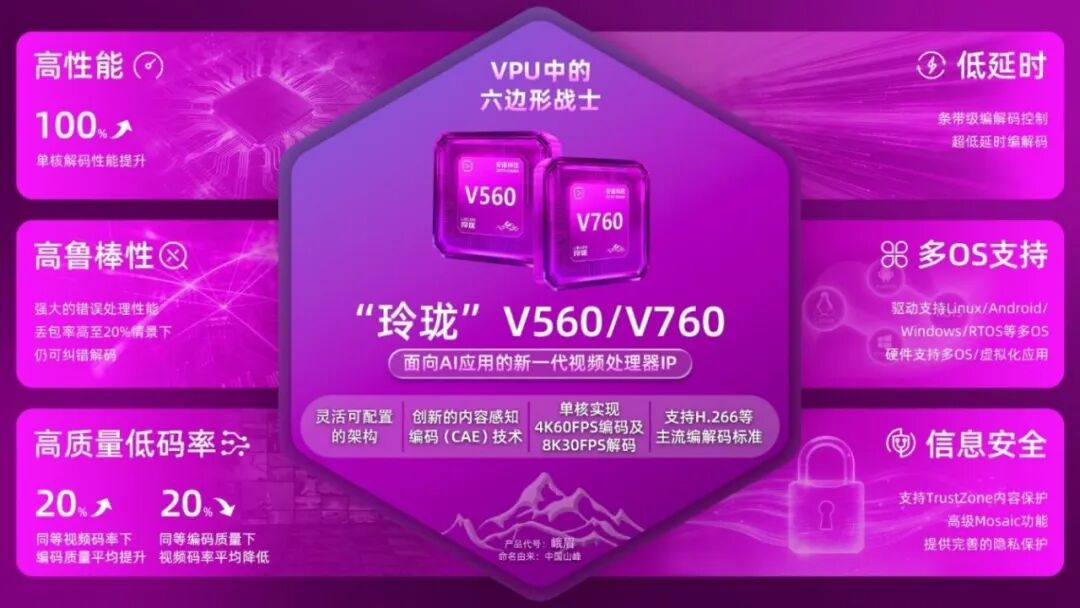
安谋科技最新推出的“峨眉”系列(V560/V760)VPU IP,是在国内半导体自主化演进及 AI 爆发的双重背景下的一次关键布局。该产品不仅解决了国产 VPU 在先进制程下的 PPA(功耗、性能、面积)平衡难题,更通过其“CSS(计算子系统)”生态优势,为 SoC 开发者提供了极短的上市周期。
安谋科技 VPU 产品总监汪奕磊表示:“在如今 AI 与视频相互赋能的时代,视频处理正面临前所未有的机遇和挑战。我们推出的‘玲珑’V560/V760 是面向 AI 应用的新一代 VPU IP,将以卓越性能为 AI 时代的各类视频应用提供强大核芯,可以覆盖云、边、端全场景。”
代际演进与单核能效比分析
相较于前代 V510/V710,“峨眉”架构实现了跨越式的性能指标突破:
- 单核解码效能翻倍:单核支持 8K 30fps 解码,相比前代性能提升 100%。在多核组合下,该架构可实现 8K 120fps 的极致处理能力。这种性能密度的提升意味着在同等芯片面积下,SoC 能够容纳更多的流处理能力。
- 高鲁棒性连接:针对 Physical AI 在无线回传(如 5G/V2X)场景下的抖动挑战,该 IP 在高达 20% 丢包率环境下仍能保持稳定的解码容错能力。这在自动驾驶等安全敏感型场景中,是确保视觉连续性的底层保障。
架构演进:从编解码加速到“六边形战士”
从传统的编解码架构演进到集成轻量化 AI 的“峨眉”架构,其核心逻辑在于应对日益严峻的 PPA 挑战。开发者关注的已不仅是单纯的吞吐量,而是系统在多维度上的均衡表现。
下表展示了“玲珑”VPU 家族从 2024 年底发布的 V510/V710 系列到全新“峨眉”V560/V760 的代际跃迁:

“峨眉”架构引入了“积木式堆叠”技术,这不仅是模块化设计的体现,更是 SoC 灵活性的核心。设计者可根据应用需求配置为“多核同任务”模式(实现 8K 120fps 超高清处理),或“多核异任务”模式(在云端实现多达 256 路视频流并发)。这种高度集成的架构为内容感知编码(CAE)提供了必要的硬件算力支撑。
模块化“积木式堆叠”架构
架构师可以通过灵活配置模块,实现对碎片化市场的精准覆盖:
- 多核同任务模式:聚合算力以应对 8K 120fps 等高动态场景。
- 多核异任务模式:在云端环境中,支持单芯片高达 256 路并发流处理,最大化提升单位面积的转码密度。
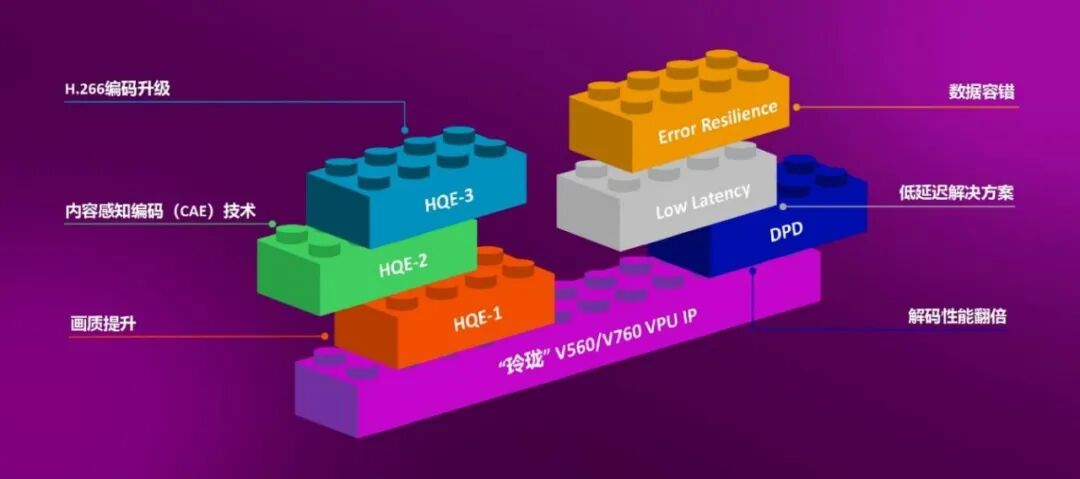
核心特性总结如下:
- 高性能:单核 8K 30fps 解码,极大降低了高分辨率设计的硅片面积开销。
- 高鲁棒性:高达 20% 丢包容错能力,适应非确定性网络环境。
- 高质量:深度集成 CAE 技术,实现语义级压缩优化。
- 低延迟:条带级(Slice-level)控制,突破帧级处理的延迟天花板。
- 多 OS 兼容:硬件支持虚拟化,原生适配 Linux、Android、RTOS 及 Windows。
- 安全等级:结合 TrustZone 及硬件级高级 Mosaic 隐私功能。
三、核心硬件技术创新:内容感知编码(CAE)与条带级控制技术
“玲珑”系列的两项核心创新——内容感知编码(CAE)与条带级控制,标志着 VPU 从“盲目压缩”向“理解后编码”的质变。
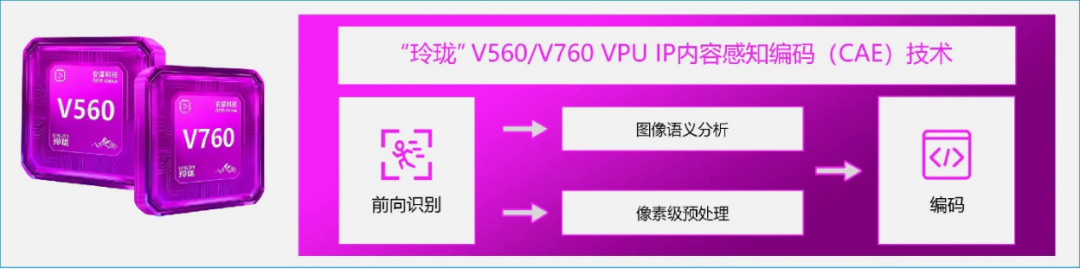
CAE 内容感知编码:从数学压缩到语义过滤
内容感知编码(CAE)是打破传统固定比特率编码局限的战略级技术。它通过引入 AI 语义理解,使 VPU 能够根据画面的感知价值动态分配资源,这对 CDN 带宽成本及存储 TCO(总拥有成本)具有决定性影响。
CAE 技术在硬件管线中集成了轻量化 AI 模型,通过三阶段链路优化 TCO:
- 语义分析:自动识别图像中的重要区域(如人脸、车辆)与静态背景。
- 像素级预处理:对背景区进行降噪,对关键区增强特征,确保 NPU 获取“洁净”的数据。
- 动态码率分配:在同等画质下,平均码率降低 20%;在监控等高冗余场景下,码率最高可降低 80%。
CAE 技术在提升图像质量的同时,保证了编码实时性,能够适应各类实时和非实时应用。
传统数学压缩 vs. AI 驱动的内容感知编码 (CAE)
传统编码(如 H.264/H.265)主要在数学层面通过运动补偿和变换去除冗余,其码率分配往往是“全帧平权”或基于简单统计特性的。而内容感知编码 (CAE) 引入了感知智能,其核心逻辑在于:并非所有像素都具有同等的语义价值。
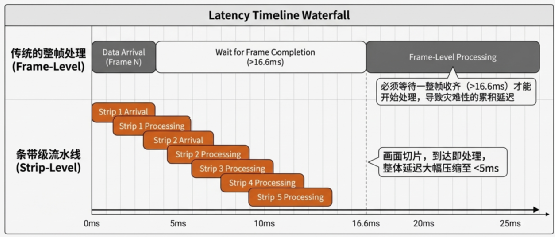
条带级(Strip-level)控制:重塑实时性基准
传统的帧级处理逻辑在 60fps 下存在固有的 16.6ms 延迟瓶颈,这对于要求确定性延迟的 Physical AI 场景是难以接受的。
- 技术原理:条带级控制将图像分割为水平切片(条带),首个条带传输完毕即可开始解码处理。
- 实战效益:该技术将 VPU 端的端到端延迟大幅缩减至
<5ms。在人形机器人或高速机器视觉场景下,这十几毫秒的延迟缩减往往是决定系统避障成功与否的关键。
在机器视觉、工业协作等物理 AI 场景中,系统的“感知-决策-执行”闭环对延时有着近乎苛刻的要求。传统的帧级处理已成为物理极限的障碍。

“玲珑”V560/V760 引入的条带级控制技术将一帧视频划分为多个水平条带。VPU 在接收到首个条带后即可启动解码,无需等待全帧接收。这种模式使 VPU 能与 NPU、显示处理器实现并行化流水线作业:当 VPU 处理当前帧底部条带时,NPU 已开始对顶部条带进行特征提取。这种底层精度的提升缓解了系统级资源竞争,为攻克“存储墙”提供了架构基础。
系统级协作:VPU 与 NPU 的共生关系
在 SoC 设计中,VPU 与 NPU 构成了深度耦合的协同关系。高质量、低噪声的视频流是 NPU 进行精确特征提取的“优质燃料”。
- VPU 作为“智能过滤器”:通过 CAE 预处理,VPU 过滤掉了可能导致 NPU 推理偏离的编码伪影(如块效应或环状噪声)。这使得 NPU 能够面对更纯净的像素特征,从而提升目标检测和识别的推理准确性。
- 功耗与总线优化:由于 CAE 显著降低了码率,它直接缓解了系统的总线占用。这种协作效应意味着开发者可以用更小的芯片面积实现更高的智能吞吐量,提升整体 TCO 竞争力。
这种“VPU-NPU 协同”不仅是软件层面的对接,更是硬件架构上向“感知中心化”理念的迈进,深刻影响着 计算机基础 架构的设计思路。
四、全球 VPU IP 竞争格局与技术基准对标
全球 VPU 市场已从单一的标准支持竞争(H.265/AV1)转向“智能+安全+生态”的多维博弈。
主要供应商差异化技术评估
- 芯原股份 (Hantro):其 VC9800E 系列是高并发场景的标杆。虽然提供了 FLEXA-AI 接口,但其智能编码更依赖于软件侧的“手动”配置,相比“玲珑”的一体化集成 CAE,其部署复杂度更高。
- Chips&Media:核心优势在于 CFrame 无损压缩技术。其 Wave6 系列已布局汽车市场,预计将获得 ASIL-B 认证,主打移动端能效。
- Synopsys (ARC EV7x):采用 VPU 与 DNN 异构融合路径。其核心壁垒在于对 ASIL-D 功能安全等级的支持,是目前车载高阶 ADAS 的强力竞争者。
- Allegro DVT:在 H.266 (VVC) 标准化进度上具有先发优势,其 E320 强调多格式资源共享,以牺牲部分峰值性能为代价换取极小的硅片面积。
全球领先 VPU IP 规格对比 (2025-2026)

在 IP 选型中,非 PPA 因素(如驱动成熟度、系统集成便利性、生态支持)往往比纯性能纸面指标更为重要。
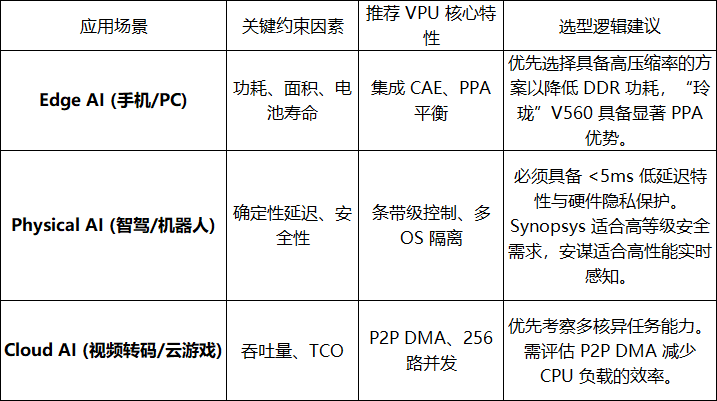
五、未来展望
VPU 技术正加速向“深度感知、全局优化”的 2.0 时代迈进。随着人形机器人等市场预计在 2030 年后的爆发式增长,未来的 VPU 将不再局限于处理 2D 视频,而是需要处理具备 3D 空间属性的多传感器融合数据流。
安谋科技规划中的后续产品将进一步模糊 VPU 与 NPU 的边界。未来的架构趋势可能包括:
- 端到端 AI 编码:VPU 与 NPU 共享或更紧密地协同同一个神经处理引擎,通过端到端的训练,实现从感知到编码的全局联合优化。
- 自治视觉系统:视觉处理单元将具备更完全的自主推理与决策能力,减少对通用 CPU 的依赖,进一步解决数据搬运带来的效率瓶颈。
安谋科技“玲珑”V560/V760 通过在底层硬件层面集成智能感知与实时控制能力,已稳步确立其在智能自主化浪潮中的核心竞争优势。对于希望深入了解最新芯片技术与行业动态的开发者,可以持续关注 云栈社区 的相关讨论。
 发表于 2026-4-3 06:24:14
|
查看: 213|
回复: 0
发表于 2026-4-3 06:24:14
|
查看: 213|
回复: 0
