
和隔壁组的老哥聊天,他最近面试了十几个人,觉得合格的也就四五个。一问才知道,问题主要出在 Redis 上。
他忍不住吐槽:“很多人对Redis的主从、哨兵、集群这些概念根本不清楚,基本就是用过一些封装的API,简历上就敢写‘熟悉’。”
这话说得我也有点不好意思,这些深入的知识点我也不太熟悉。如果我现在去面试,恐怕也得挂。但仔细一想,掌握Redis对于开发者来说,还真不是“造火箭”那么遥不可及。在他们组的业务里,Redis被大量使用,而且和数据库不同,Redis往往没有专门的运维人员,数据迁移、故障排查这些工作都得开发自己上手。
所以,对于现代后端开发而言,Redis不应该只是一个被API封装起来的黑箱。我们需要打破认知障碍,深入理解它的原理与运作机制,这无疑是积蓄技术实力的重要一步。
1、Redis是什么?
Redis 是一种基于键值对(key-value)的NoSQL数据库。但和很多简单的键值对数据库不同,Redis中的值可以由多种数据结构和算法组成,包括 string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、 HyperLogLog以及GEO(地理信息定位)等。
这种丰富的数据类型使得Redis能够应对多样的应用场景。更重要的是,Redis将所有数据都存放在内存中,因此其读写性能非常惊人。同时,Redis也能通过快照和日志的形式将内存中的数据持久化到硬盘上,从而在断电或机器故障时,避免数据“丢失”。
此外,Redis还提供了诸如键过期、发布订阅、事务、流水线、Lua脚本等附加功能。可以说,在合适的场景下用好Redis,它就像一把瑞士军刀一样高效全能。
国内外众多互联网公司都在使用Redis,例如Twitter、GitHub、腾讯、阿里、京东、华为等。可以说,对Redis的了解与实践,已成为中高级后端开发者一项绕不开的必备技能。
2、Redis的六大典型应用场景
2.1、缓存
缓存几乎是所有大型网站的标配。合理使用缓存不仅能极大加快数据访问速度,还能有效减轻后端数据库的压力。Redis提供了灵活的键值过期时间设置,以及内存上限控制和多种淘汰策略。一个设计合理的缓存层,是网站稳定运行的重要保障。
2.2、排行榜系统
排行榜系统随处可见,比如按热度、发布时间或复杂维度计算的榜单。Redis提供的列表和有序集合数据结构,能够非常方便、高效地构建各种排行榜系统。
2.3、计数器应用
计数器在网站中至关重要,例如视频播放量、商品浏览量。为了保证实时性,每次操作都要做加1处理,高并发下对传统关系型数据库是巨大挑战。Redis天然支持计数功能,且性能极佳,是计数器系统的理想选择。
2.4、社交网络
点赞/踩、粉丝、共同好友、消息推送、下拉刷新等都是社交网站的必备功能。这类数据访问量大,结构灵活,不太适合用传统关系型数据库存储。Redis提供的多种数据结构可以相对轻松地实现这些社交功能。
2.5、消息队列系统
消息队列是大型网站的基础组件,用于业务解耦、削峰填谷。Redis提供了发布订阅和阻塞队列功能,虽然与Kafka、RabbitMQ等专业消息中间件相比功能有所欠缺,但对于一般的队列需求,完全能够满足。
2.6、分布式锁与单线程机制
- 防重复提交:可以将请求的IP、参数等哈希值作为Key存入Redis,并设置有效期,以此过滤短时间内完全相同的重复请求,实现幂等性控制。
- 秒杀系统:利用Redis单线程执行命令的特性,可以防止超高并发请求瞬间“打爆”数据库。
- 全局ID生成:同样基于其单线程和原子操作特性,可用于生成全局唯一的增量ID。
3、Redis版本演进与特性
Redis借鉴了Linux的版本号命名规则:版本号第二位如果是奇数,则为非稳定版本(如2.7, 3.1);如果是偶数,则为稳定版本(如2.6, 3.0, 3.2)。
了解版本演进对于技术选型和理解功能边界很有帮助。下图清晰地展示了Redis从2.6到6.0的主要发展历程:
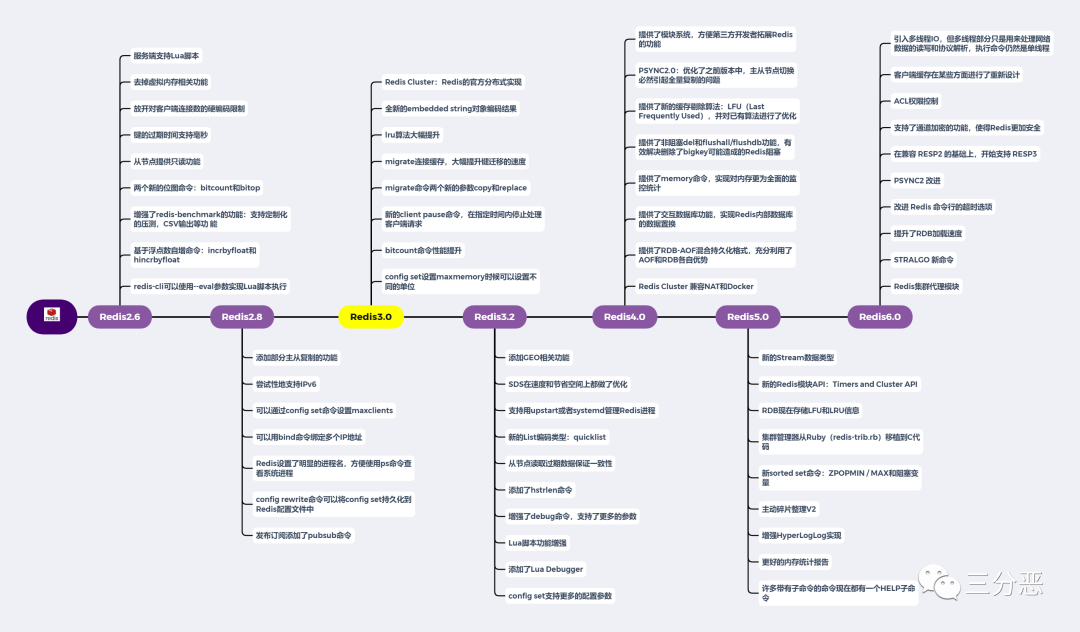
其中,Redis 3.0是一个里程碑版本,它引入了官方原生的分布式实现——Redis Cluster,填补了Redis在分布式能力上的空白。后续版本则在性能(如6.0引入多线程IO)、安全性(ACL)、数据类型(Stream)及运维体验上持续增强。
希望这篇概述能帮助你建立起对Redis的初步认知。技术的深入离不开实践与交流,如果在学习过程中有任何想法或问题,欢迎来云栈社区与我们共同探讨。
参考
- 《Redis开发与运维》
- 掘金小册《Redis深度历险:核心原理与应用实践》
 发表于 2026-4-4 05:38:44
|
查看: 152|
回复: 0
发表于 2026-4-4 05:38:44
|
查看: 152|
回复: 0
