前言
大模型的“知识”主要来源于训练数据,对于训练后新发生的事件或高度专业性的问题,模型可能会产生不准确的信息或“幻觉”。为解决这一难题,RAG 技术应运而生。它通过为模型外挂一个可动态更新的外部知识库,让模型在生成回答时能够精准地参考这些信息,从而大幅提升回答的准确性和可靠性。
实操
GPT4All
如果你想快速体验,可以尝试在桌面端使用 GPT4All。
它的优点在于提供了图形化界面,可以一站式地在线下载模型和导入知识库,操作非常直观。主要步骤就是在“本地文档”选项中添加包含文本、PDF或Markdown文件的文件夹。不过需要注意的是,GPT4All的模型文件格式与Ollama并不通用。
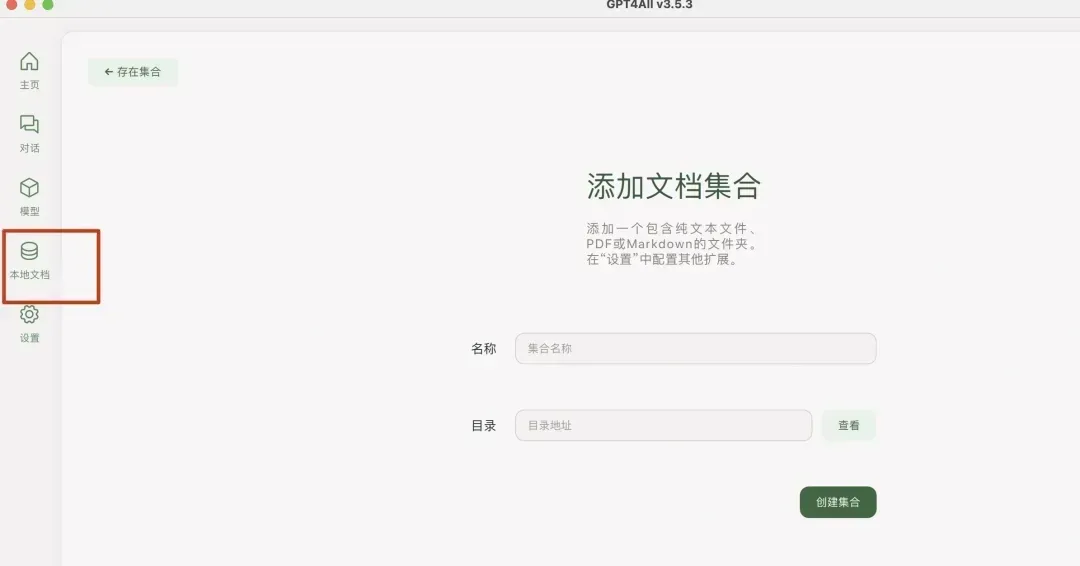
在GPT4All中添加文档集合
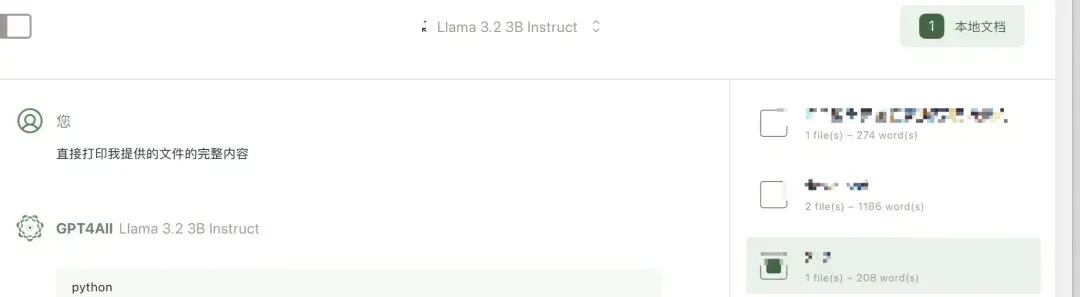
基于已上传文档进行提问和回答
Open WebUI
Open WebUI 是另一个流行的开源Web界面,功能更为强大。安装后,我们可以用它来直观地对比有无知识库时模型的回答差异。
例如,在没有上传相关知识的情况下,询问一个特定的技术问题,模型可能会给出错误的答案或表示无法回答。

未挂载知识库时,模型可能给出不准确的回答
那么,如何为它挂载知识库呢?操作流程如下:
- 点击右上角进入“工作空间”。
- 选择“知识库”。
- 点击“新增知识库空间”。
- 上传你的知识库文件(支持多种格式)。

在Open WebUI中创建新的知识库空间
知识库创建并上传文件后,当你在对话框中提问时,只需要在输入框内输入 # 符号,就可以引用并激活特定的知识库。此时再咨询知识库中包含的内容,就能获得基于文档的准确回答了。
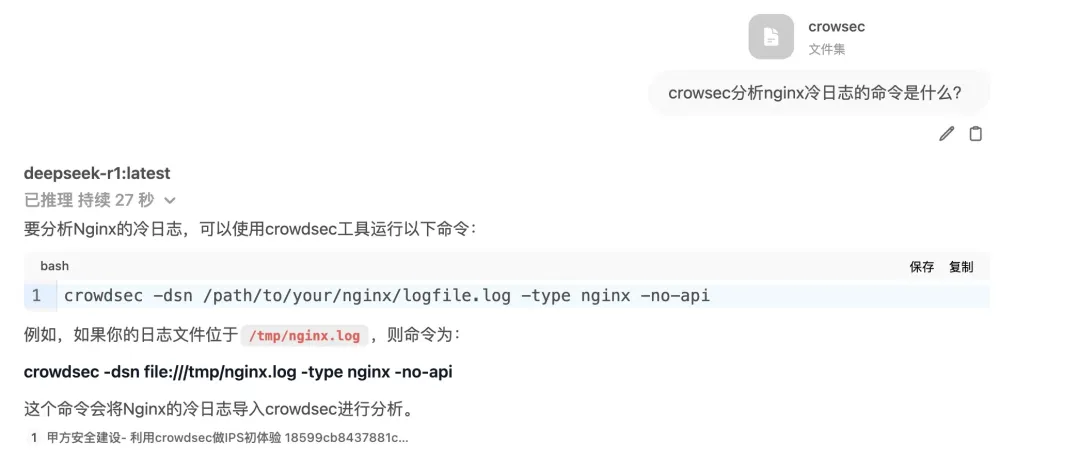
通过#引用知识库后,模型基于文档给出准确回答
IMA(腾讯出品)
IMA 是腾讯推出的AI应用,同样集成了知识库功能。创建知识库的基本流程是:进入“个人知识库” -> “创建共享知识库” -> 上传文件。
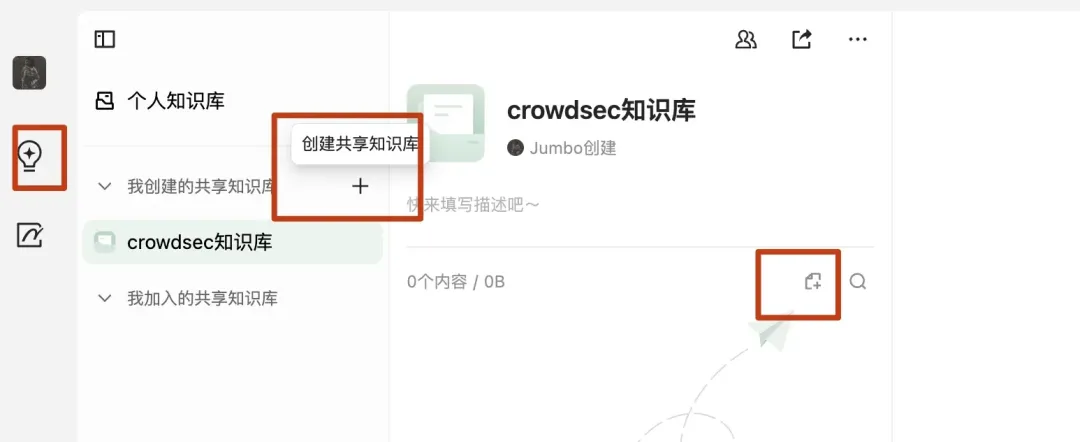
在IMA中创建共享知识库
不过在实际体验中,它也存在一些不足。例如,它不支持上传Markdown格式的文件。另外,可能会遇到一些界面上的Bug,比如明明已经创建了知识库,但在某些选择界面却无法看到或选中。
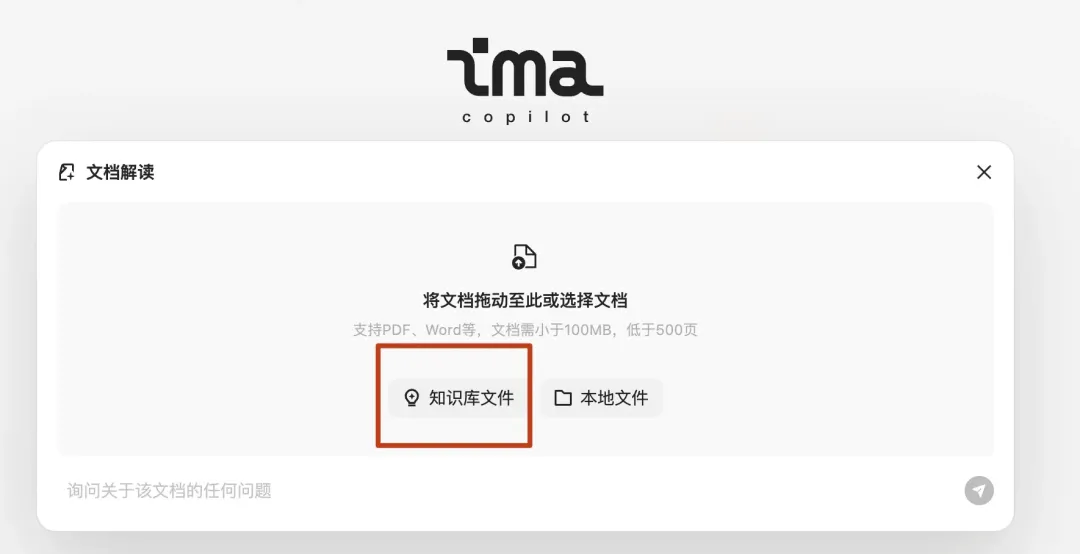

知识库可能无法被正确识别或选择
由于IMA没有提供全局的提示词(Prompt)设置,如果你希望模型严格基于知识库回答,不在其内部知识中联想,就需要在每次提问时,手动在问题中加入指令,例如“请仅根据提供的知识库内容回答,不要自行联想”。即便如此,不同模型的表现也有差异。

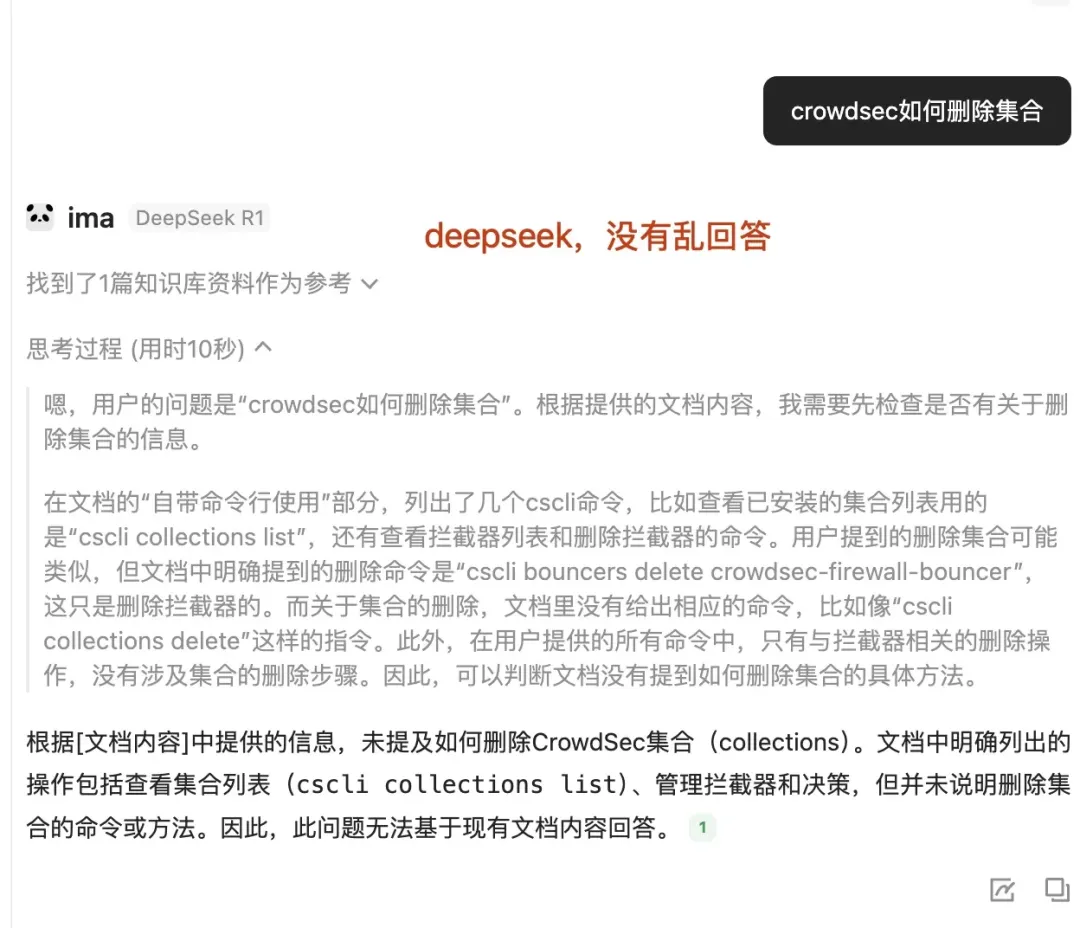
不同大模型在相同知识库和指令下的回答对比
LangChain + Chroma(代码方案)
以上介绍的都属于图形化方案,适合快速上手。但在实际的工程化部署或需要深度定制时,代码方案提供了最大的灵活性。这里我们介绍如何使用 LangChain 框架和 Chroma 向量数据库来构建RAG系统。
核心思想是:将文档内容转换为向量(Embeddings)并存入向量数据库。当用户提问时,先将问题转换为向量,然后在数据库中搜索最相似的文档片段,最后将这些片段作为上下文交给大模型来生成答案。
首先,我们看一个使用原生Chroma库的简单示例:
import chromadb
# 创建一个临时的内存客户端
client = chromadb.Client()
# 创建一个集合(类似于数据库的表)
collection = client.create_collection("all-my-documents")
# 向集合中添加文档
collection.add(
documents=["This is document1", "This is document2"], # Chroma会自动处理分词、向量化和索引
metadatas=[{"source": "notion"}, {"source": "google-docs"}], # 可以添加元数据用于过滤
ids=["doc1", "doc2"], # 每个文档必须有唯一ID
)
# 进行相似度搜索,查询最相似的2个结果
results = collection.query(
query_texts=["This is document1"],
n_results=2,
# where={"metadata_field": "is_equal_to_this"}, # 可选的元数据过滤器
# where_document={"$contains":"search_string"} # 可选的文档内容过滤器
)
print(results)
执行上述代码会得到类似下面的结果:
{'ids': [['doc1', 'doc2']], 'embeddings': None, 'documents': [['This is document1', 'This is document2']], 'uris': None, 'data': None, 'metadatas': [[{'source': 'notion'}, {'source': 'google-docs'}]], 'distances': [[0.0, 0.2221483439207077]], 'included': [<IncludeEnum.distances: 'distances'>, <IncludeEnum.documents: 'documents'>, <IncludeEnum.metadatas: 'metadatas'>]}
注意 distances 字段,它代表了查询向量与文档向量之间的距离,数值越小相似度越高。在这个例子里,查询内容与doc1完全一致,所以距离为0。这个特性非常有用,我们可以在后续环节中设定一个距离阈值,只将相似度足够高的文档片段投喂给大模型,从而有效控制上下文长度和答案的相关性。
LangChain的强大之处在于集成。它简化了Chroma、大模型、文档加载器等组件之间的连接。下面是一个使用LangChain集成Chroma和Ollama嵌入模型的例子:
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from uuid import uuid4
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="nomic-embed-text:latest")
# 创建向量存储,并指定持久化目录
vector_store = Chroma(
collection_name="example_collection",
embedding_function=embeddings,
persist_directory="./chroma_langchain_db", # 数据将保存到本地这个目录
)
# 创建一些示例文档
document_1 = Document(
page_content="I had chocolate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
id=1,
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
id=2,
)
# ... 此处省略了document_3到document_10的创建代码,结构类似 ...
documents = [
document_1, document_2, document_3, document_4, document_5,
document_6, document_7, document_8, document_9, document_10
]
# 为每个文档生成一个唯一ID并添加到向量库
uuids = [str(uuid4()) for _ in range(len(documents))]
vector_store.add_documents(documents=documents, ids=uuids)
# 进行相似度搜索,并过滤source为“news”的文档
results = vector_store.similarity_search_with_score(
"Will it be hot tomorrow?", k=1, filter={"source": "news"}
)
print("-----")
print(results)
print("-----")
for res, score in results:
print(f"* [SIM-{score:.3f}] {res.page_content} [{res.metadata}]")
print("-----")
这段代码完成了以下工作:
- 初始化嵌入模型和Chroma向量库(支持本地持久化)。
- 创建了10个文档对象,每个都包含内容和元数据。
- 将这些文档向量化后存入名为
example_collection的集合。
- 最后提出一个问题“明天热吗?”,并要求在元数据
source为news的文档中,找出最相关的1个。
运行后,我们可以在指定的chroma_langchain_db目录下看到持久化的数据库文件,并且控制台会打印出搜索结果,显示与天气相关的文档被成功检索到。
LangChain + Chroma 生成的本地向量数据库文件

代码运行后返回的相似文档及其分数
接下来,我们将检索到的文档与大模型结合。 使用LangChain可以轻松调用本地的Ollama模型:
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="deepseek-r1:latest",
temperature=0.5,
)
messages = [
("system", "角色:你是IT小助手,你只回答IT相关问题,其他问题不回答。当别人问你是谁时,你回答:我是IT小助手。"),
("human", "你是谁"),
]
ai_msg = llm.invoke(messages)
print(ai_msg)
通过设置system提示词,我们可以有效地约束大模型的输出范围和角色。

通过System Prompt成功将模型角色约束为“IT小助手”
一个完整的RAG流程是怎样的? 我们需要处理长文档、进行文本分割、向量化检索,最后生成答案。下面的代码示例展示了一个更工程化的VectorStoreQA类,它封装了这些步骤:
from typing import Dict
import logging
from pathlib import Path
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain_chroma import Chroma
class VectorStoreQA:
def __init__(self,
model_name: str = "deepseek-r1:latest",
embedding_model: str = "nomic-embed-text:latest",
temperature: float = 0.5,
k: int = 4):
"""
初始化 QA 系统
Args:
model_name: LLM 模型名称
embedding_model: 嵌入模型名称
temperature: LLM 温度参数
k: 检索返回的文档数量
"""
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
self.logger = logging.getLogger(__name__)
self.k = k
# 初始化 LLM
self.llm = ChatOllama(
model=model_name,
temperature=temperature,
)
# 初始化 embeddings
self.embeddings = OllamaEmbeddings(model=embedding_model)
# 初始化向量存储
self.vector_store = Chroma(embedding_function=self.embeddings)
# 初始化 prompt 模板
self.prompt = ChatPromptTemplate.from_messages([
("system", """上下文中没有相关资料的不要编造信息、不要从你历史库中搜索,直接说:在知识库中我找不到相关答案。"""),
("user", """上下文信息:{context}
用户问题:{question}
请提供你的回答:""")
])
def load_documents(self, file_path: str, chunk_size: int = 1000, chunk_overlap: int = 200) -> None:
"""
加载并处理文本文档
Args:
file_path: 文本文件路径
chunk_size: 文档分块大小
chunk_overlap: 分块重叠大小
"""
try:
# 验证文件
path = Path(file_path)
if not path.exists():
raise FileNotFoundError(f"文件不存在: {file_path}")
# 加载文档
loader = TextLoader(str(path))
docs = loader.load()
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(docs)
# 添加到向量存储
self.vector_store.add_documents(documents=splits)
self.logger.info(f"成功加载文档: {file_path}")
except Exception as e:
self.logger.error(f"文档处理错误: {str(e)}")
raise
def get_answer(self, question: str) -> Dict:
"""
获取问题的答案
Args:
question: 用户问题
Returns:
包含答案的字典
"""
# 使用similarity_search_with_score方法获取文档和分数
docs_and_scores = self.vector_store.similarity_search_with_score(
query=question,
k=self.k
)
# 打印每个文档的内容和相似度分数
print("\n=== 检索到的相关文档 ===")
for doc, score in docs_and_scores:
print(f"\n相似度分数: {score:.4f}") # 保留4位小数
print(f"文档内容: {doc.page_content}")
print(f"元数据: {doc.metadata}") # 如果需要查看文档元数据
print("-"*50) # 分隔线
# 提取文档内容用于后续处理
context = "\n\n".join(doc.page_content for doc, _ in docs_and_scores)
# 打印完整的prompt内容
print("\n=== 实际发送给模型的Prompt ===")
formatted_prompt = self.prompt.format(
question=question,
context=context
)
print(formatted_prompt)
print("="*50)
# 创建chain并调用
chain = self.prompt | self.llm
response = chain.invoke({
"question": question,
"context": context
})
return response
def clear_vector_store(self):
"""清空向量存储"""
try:
self.vector_store.delete_collection()
self.vector_store = Chroma(embedding_function=self.embeddings)
self.logger.info("已清空向量存储")
except Exception as e:
self.logger.error(f"清空向量存储时发生错误: {str(e)}")
raise
# 使用示例
if __name__ == "__main__":
# 初始化 QA 系统
qa_system = VectorStoreQA(
model_name="deepseek-r1:latest",
k=4
)
# 加载文档
qa_system.load_documents("/tmp/1.txt")
# 提问
question = "猪八戒是谁?"
result = qa_system.get_answer(question)
print(result)
这个类做了几件关键事情:
- 文档加载与分割:使用
TextLoader读取文件,并用RecursiveCharacterTextSplitter将长文档切分为语义连贯的小块,以适应嵌入模型和大模型的上下文窗口限制。
- 向量化与存储:自动将文档块转换为向量,并存储到Chroma中。
- 检索增强生成:根据用户问题检索最相关的文档块,将它们作为“上下文”与问题一同组装成提示词(Prompt),发送给大模型,并要求模型严格基于此上下文生成答案。
通过使用这样的 Python 代码框架,你可以灵活地控制RAG流程的每一个环节,并将其集成到自己的应用程序中。
总结
如何选择适合你的RAG方案?这里有一个简单的参考:
- 追求极简上手:如果你是个人用户,想快速体验大模型与知识库结合的效果,GPT4All和IMA这类图形化工具是最佳选择,几乎不需要任何编程基础。
- 需要更多控制与集成:如果你已经使用Ollama来管理本地模型,并且希望前端有更多的自定义能力(如角色设定、复杂提示词),那么Open Webui是一个功能强大且开源的选择。
- 面向工程化与生产环境:如果你需要在业务系统中集成RAG能力,或者进行深入的定制开发(如处理特定格式文档、优化检索策略、对接不同模型),那么基于 LangChain + Chroma 的代码方案提供了最大的灵活性和可控性,是长期构建AI应用的基础。
希望这篇对比和实战代码能帮助你找到最适合自己的“大模型知识库”搭建方式。技术的发展日新月异,在 云栈社区 这样的技术论坛里,总有开发者在分享最新的开源实战和踩坑经验,是持续学习和交流的好去处。
 发表于 2026-4-4 07:24:53
|
查看: 121|
回复: 0
发表于 2026-4-4 07:24:53
|
查看: 121|
回复: 0
