Transformer 模型因其标准 Softmax 注意力的二次方计算复杂度,在处理长序列时面临着显著的计算与内存瓶颈。为解决这一挑战,融合 Softmax 与线性注意力的混合架构应运而生。这种架构策略性地利用 Softmax 注意力进行关键局部信息的精确建模,同时借助线性注意力高效捕捉全局的长距离依赖。
这种设计不仅有效突破了传统模型的计算限制,更在长文本理解、高分辨率视觉任务等场景中,为模型性能与计算效率的平衡提供了新思路。本文将通过解析两篇代表性的 CVPR/AAAI 论文,深入探讨此类即插即用模块的实现原理。
内容概要:
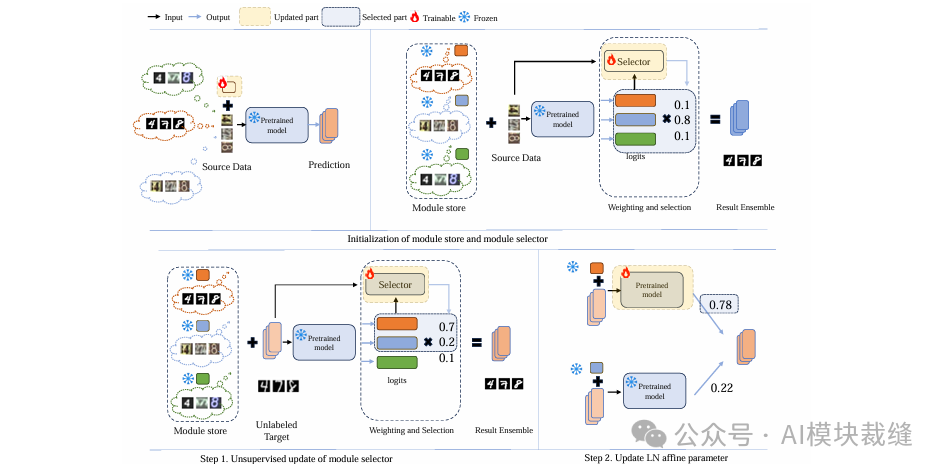
本文提出了一个即插即用模块化测试时自适应(PLUTO)策略,旨在通过少量无标签数据,在测试时将预训练模型高效地自适应到新领域。其核心创新在于设计了一个基于注意力的模块选择器,它能从一个预训练的参数高效调优(PET)“模块库”中,为每个测试样本动态地选择并加权组合最相关的模块。该方法无需调整模块权重,实现了样本级别的高效自适应,并有效避免了灾难性遗忘。
模块结构与原理:
PLUTO 的核心是一个基于 Softmax 注意力的模块选择器(Module Selector),它动态地为来自不同源域的预训练模块分配权重。其工作原理如下:
1. 输入表征:
- 将当前测试批次的输入图像
x 和来自 N 个源模块的预 softmax logits {l(x)_j} 分别通过可训练的参数矩阵,投影到新的表征空间,得到图像表征 h_x 和各模块的 logits 表征 h_l,j。
2. 注意力权重计算:
- 通过计算图像表征
h_x 和每个模块 logits 表征 h_l,j 的点积,来衡量输入样本与各个源模块输出之间的相关性。
3. Softmax 归一化:
- 将计算出的相关性得分通过 Softmax 函数进行归一化,生成一组权重
{w(x)_j}。每个权重代表了对应源模块对当前输入样本的贡献度。公式为:w(x)_j = exp(h_l,j · h_x) / Σ_k exp(h_l,k · h_x)
4. 线性组合输出:
- 最终的集成 logit
l(x) 是所有源模块 logits 的线性加权和,权重即为 Softmax 计算出的注意力权重。公式为:l(x) = Σ w(x)_j · l(x)_j
Visual Prompt Tuning
内容概要:
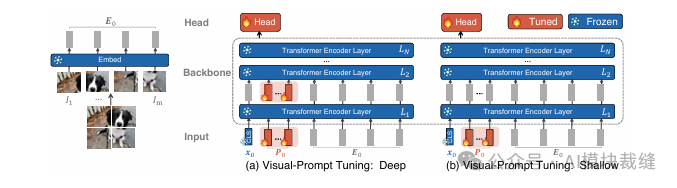
本文提出了视觉提示调优(Visual Prompt Tuning, VPT)方法,作为一种高效替代全量微调(full fine-tuning)的方案,用于适配大规模视觉 Transformer 模型。该方法的核心创新在于,在冻结整个预训练主干网络的同时,仅在模型的输入空间中引入少量(小于模型参数的1%)可学习的、任务特定的“提示”(prompts)。这些提示与图像特征一同被标准的 Softmax 注意力机制处理,从而在极大降低每个任务的存储成本的同时,在多个下游任务上达到了甚至超越了全量微调的性能。
模块结构与原理:
VPT 方法本身并不改变 Transformer 的内部结构,而是通过增强输入来适配标准的 Transformer 编码器层,该层依赖于 Softmax 注意力机制。其原理如下:
1. 输入序列增强:
- 在输入到 Transformer 编码器层之前,将一组可学习的、d 维的连续向量(即“提示”
P)拼接到图像块嵌入序列 E 的前面。
- VPT-Shallow:仅在第一个 Transformer 层前插入提示。
- VPT-Deep:在每一个 Transformer 层前都插入各自独立的提示。
2. 多头自注意力机制(MHSA):
- 包含提示的增强序列
[CLS, P, E] 被送入 MHSA 模块。模块内部通过线性投影从该序列生成查询(Query)、键(Key)和值(Value)矩阵。
3. Softmax 注意力加权:
- 通过计算
softmax(QK^T / sqrt(d_k)) 来获得注意力权重。这些权重矩阵决定了序列中每个 token(包括图像块和提示)对其他所有 token 的关注程度。提示 token 参与了整个信息交互过程,从而引导模型适应下游任务。
4. 加权线性组合输出:
- 注意力模块的输出是值(Value)向量的加权线性组合,权重由 Softmax 函数计算得出,实现了序列内信息的有效融合。
总结与思考
无论是 PLUTO 的动态模块选择,还是 VPT 的输入空间提示,其核心思想都是在不剧烈改动庞大预训练模型的前提下,通过轻量、高效的适配策略来提升模型在新场景下的表现。它们巧妙地利用了 Softmax 注意力 的“选择性聚焦”能力和 线性操作 的“高效聚合”特性,为Transformer模型的长序列应用和高效微调提供了极具启发的解决方案。这类工作也反映了当前人工智能领域向更高效、更模块化方向发展的趋势。
对于希望深入该领域的研究者或开发者而言,理解这些混合架构的设计哲学,比单纯复现代码更为重要。它们展示了如何针对具体问题(如计算瓶颈、迁移成本)进行精准的算法创新。 |  发表于 2026-4-4 11:53:03
|
查看: 166|
回复: 0
发表于 2026-4-4 11:53:03
|
查看: 166|
回复: 0
