加州大学的研究人员提出了一种名为 PLUTO 的创新框架,它让预训练的 Transformer 模型在面对未知数据时,能像使用“应用商店”一样动态选择和组合功能模块,实现高效的测试时自适应。这篇干货将带你深入理解其核心原理、技术细节与应用价值。

核心创新点
- 首创多源PET模块的测试时自适应框架:首次将多个参数高效微调模块应用于测试时自适应问题,构建了一个可即插即用的“模块库”。
- 无监督的模块选择与融合机制:提出了一种基于注意力机制的模块选择器,能在仅有少量无标签测试数据的情况下,动态地为每个样本选择并加权组合最相关的预训练模块,无需对模块本身进行微调。
- 结合锐度感知优化的参数高效自适应:通过仅更新最相关模块对应的LayerNorm层仿射参数,并引入锐度感知最小化策略,有效防止了模型在自适应过程中的性能退化和灾难性遗忘。
- 卓越的少样本和零样本适应性能:实验证明,该方法在少样本乃至零样本场景下,性能远超现有TTA方法,仅需选择少量(≤5个)模块即可获得大部分性能增益。
方法详解
整体结构概述
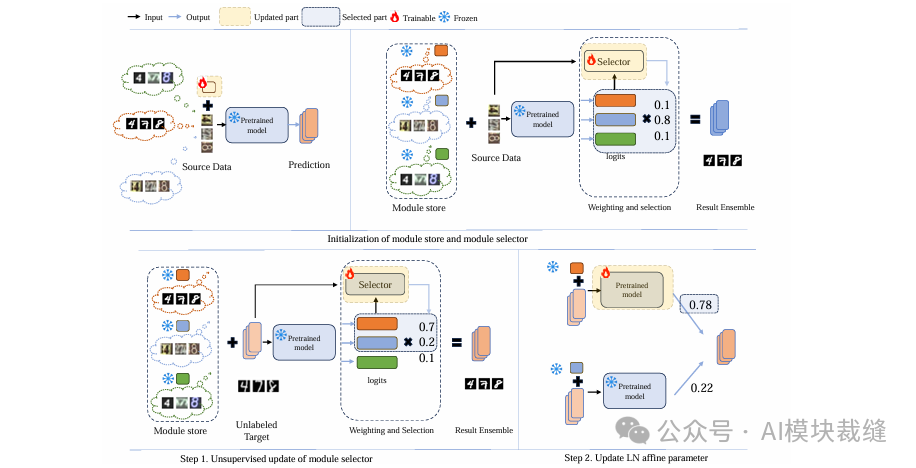
PLUTO方法的核心思想是,首先为多个源域分别预训练一系列参数高效的PET模块,构成一个“模块库”。在测试阶段,面对来自新目标域的无标签数据,PLUTO通过两个核心步骤进行自适应:
- 利用一个注意力模块(模块选择器)对模块库中的模块进行动态选择和加权组合;
- 仅对与当前测试批次最相关的源模型的LayerNorm仿射参数进行微调。
整个过程无需访问源域数据,实现了高效、灵活的测试时自适应。
步骤分解
-
模块库的预训练与选择器初始化:
- 首先,针对N个不同的源域,在一个冻结的预训练Transformer模型基础上,为每个源域单独训练一个PET模块(如VPT、Adapter等),形成模块库
{θj} (j=1 to N)。
- 模块选择器
G 是一个注意力模块,它在源域数据上进行预训练,学习捕捉输入样本与不同源域模型输出之间的相关性。
-
测试时模块动态加权与选择:
- 当一个测试样本
x 到达时,它首先通过所有N个加载了不同模块的Transformer模型,得到N组对应的logits {l(x)j}。
- 模块选择器
G 将样本 x 的特征表示 h_x 与每组logits的特征表示 h_l,j 作为输入,通过注意力机制计算出每个模块的权重 w(x)j。该权重反映了第 j 个模块对当前样本的贡献度。
- 最终模型的输出是对所有模块的logits进行加权求和:
l(x) = Σ w(x)j * l(x)j。
- 为了在无标签的目标域上更新模块选择器
G,PLUTO采用伪标签熵最小化的无监督目标。它首先生成加权伪标签 ŷ = Σ w(x)j * ŷj,然后最小化该伪标签分布的香农熵,从而提升预测的置信度并优化权重分配。
-
基于锐度感知的LayerNorm参数自适应:
备注:分析中引用了论文中的关键表格,如 表2、表3 展示了在Digits和Office-Home数据集上的优越性能;表4、表5 凸显了在少样本和零样本设置下的显著优势;表7 则验证了仅选择少量模块即可达到接近全量模块的性能。
即插即用模块的作用
适用场景
该技术主要用于解决机器学习模型在部署后遇到的域漂移问题,特别适用于以下场景:
- 测试时自适应:模型需要在测试过程中,利用流式、无标签的数据实时适应新的环境分布。
- 少样本/零样本域适应:目标域只有极少量甚至没有可用样本,无法从头开始微调模型。
- 多源域自适应:存在多个预训练好的源模型,需要智能地选择和利用它们来处理未知的目标域。
- 具体任务:论文中验证的任务包括图像分类(如数字识别、物体识别)和对图像损坏的鲁棒性评估,但该框架具备扩展到其他视觉任务(如语义分割)的潜力。
主要作用
该技术为预训练大模型带来了显著的实际收益:
- 模拟多专家会诊能力:通过动态组合“模块库”中的专家,模拟了一个专家组根据具体问题进行会诊决策的过程,提升了模型的泛化性和准确性。
- 大幅降低适应成本:无需为每个新领域都重新训练或完整微调大模型,仅需更新极少量的参数,极大地降低了计算和存储开销,增强了模型在资源受限设备上的可部署性。
- 增强模型的鲁棒性和抗遗忘能力:采用即插即用和仅微调LN层的策略,有效保留了预训练模型的核心知识,显著缓解了传统TTA方法中的灾难性遗忘问题。
- 提升样本效率:独特的无监督选择和加权机制使得模型在少样本乃至零样本场景下依然能有效自适应,解决了冷启动问题。
总结
PLUTO将一个庞大的预训练Transformer模型,转变为一个具备动态“插件”管理能力的自适应系统。它通过一个预先构建的“模块应用商店”,在面对未知测试环境时,能够智能地为每个样本“按需加载”并组合最合适的微型功能模块,从而以极低的成本实现快速、精准且稳健的在线自适应。这种思路为模块化的模型设计与高效部署提供了新的方向。 |  发表于 2026-4-4 11:55:17
|
查看: 126|
回复: 0
发表于 2026-4-4 11:55:17
|
查看: 126|
回复: 0
