LangGraph 源码圣经(第二章):状态管理与 执行机制
传统的链式调用(比如 A → B → C),就像接力赛跑,A 跑完把棒子交给 B,B 再交给 C。
问题是:A 的信息只能给 B,C 想回头查 A 干了啥?不行!
而 LangGraph 的状态是全局共享的,所有节点都能读、能写。
就像是所有人共用一个白板,谁都可以上去写字或擦掉重写。这样才支持分支判断、循环执行等复杂逻辑。
源码中,这部分的核心在langgraph/graph.py的StateGraph类里,主要干三件事:定义状态、更新状态、校验状态。
2.1、状态管理的本质:为什么LangGraph的状态设计如此关键?
核心痛点: 状态散乱不可控——传统开发中状态像“暗流”,看不见、摸不着、改不动,导致系统越复杂越容易失控。
核心方案: 把状态变“明账”——LangGraph用统一的显式状态结构,让所有数据流动都清晰可见、可查、可管。
原来的函数传参或全局变量管理状态的方式,就像在黑箱里传递纸条:你不知道谁改了什么,也不知道下一步依赖的是哪张纸条。
LangGraph从根本上改变了这一点。
它要求所有节点都从一个明确的状态对象中读取数据、写入结果。
这个设计看似简单,实则解决了智能体工作流中最根本的问题:状态漂移与副作用失控。
通过强制将交互数据集中管理,不仅提升了代码的可测试性(可以轻松构造任意中间状态),也极大增强了调试能力(每一步状态变化都可追溯),更为后续扩展提供了安全边界(新增节点不会意外破坏已有逻辑)。
2.2、两种模式的 State类的结构设计
核心痛点: 状态结构僵化或混乱——要么太死板无法适应多变流程,要么太自由导致团队协作困难。
核心方案:
- 第一种 模式,是用TypedDict 定义状态
- 第一种 模式,是用Pydantic模型(需要数据验证时)定义状态
LangGraph允许你用TypedDict或Pydantic来定义状态结构,这种灵活性让你可以根据项目阶段选择合适方式。
from typing import TypedDict, Annotated
from langgraph.graph import State
# 方式1:使用 TypedDict
class MyState(TypedDict):
user_input: str
steps: Annotated[list, "append"] # 标记为可追加字段
result: str
# 方式2:使用 Pydantic 模型(推荐)
from pydantic import BaseModel
class MyStateModel(BaseModel):
user_input: str
steps: list
result: str
# 初始化图时指定状态类
graph_builder = StateGraph(MyStateModel)
介绍:支持多种定义方式,但推荐使用Pydantic模型,类型更清晰,验证更强。
早期原型可用TypedDict快速迭代,后期生产环境切换到Pydantic获得完整校验和文档支持。
关键是,所有节点共享同一份状态契约,避免“我说的和他理解的不是一回事”的问题。
2.3 模式1:使用 TypedDict 定义状态
核心痛点: 数据结构不明确导致使用过程中容易出错,比如字段名写错、缺少必要字段或类型不匹配,尤其在多人协作或长期维护时问题更明显。
核心方案: 用带类型提示的TypedDict明确定义数据结构,让编辑器能自动提示和检查错误,提升代码可读性和健壮性。
TypedDict是一种轻量又安全的方式,用来定义像字典这样的数据结构,特别适合描述一个 Agent 的状态。
它的好处是:既保持了字典的灵活性,又能在编码时就知道哪个字段叫什么、是什么类型,避免手误写错字段名或传错数据。
第一种 模式,是用TypedDict 定义状态 参考代码:
from typing import TypedDict, List, Optional
class StateSchema(TypedDict):
messages: List[dict] # 消息历史
current_query: str # 当前查询
search_results: List[dict]
iteration: int = 0 # 默认值支持
error: Optional[str] = None
这段代码定义了一个叫StateSchema的状态结构,包含消息、当前问题、搜索结果、重试次数和可能的错误信息。
所有字段都有明确类型,部分还支持默认值,清晰又安全。
2.3.1可变与不可变字段的语义控制
from typing import Annotated
from langgraph.types import Addable
class State(TypedDict):
messages: Annotated[list, Addable] #Addable或"append", 自动合并列表
count: Annotated[int, "sum"] # 自动累加数值
config: dict # 普通字段,覆盖写入
注意:通过Annotated标注字段行为,告诉框架如何处理更新操作。
传统做法是全量替换状态,容易误删数据。
LangGraph引入“语义化更新”机制:你可以标记某些字段为Addable或"append",表示每次更新应自动拼接而非覆盖。
比如多个节点都往messages里加消息,不用手动读旧值再追加,框架自动帮你合并。
这既减少了样板代码,也防止了并发写入时的数据丢失。
2.3.2初始状态与默认值机制
def get_initial_state():
return {
"messages": [],
"steps": ["started"],
"user_input": "",
"metadata": {"source": "web"}
}
graph_builder.set_entry_point("input_node")
app = graph_builder.compile()
initial_state = get_initial_state()
result = app.invoke(initial_state)
注意:通过函数返回初始状态,灵活设置默认值和上下文信息。
没有良好的初始化机制,每次启动都要重复写一堆默认值。
LangGraph虽未内置默认值注解,但通过显式构造初始状态对象的方式,反而带来了更高灵活性。
可以根据运行场景动态生成不同初始状态,比如来自API请求、历史回放或测试用例,真正做到“一次定义,多场景复用”。
2.3 状态操作的三大核心方法
状态更新不是简单的赋值,而是通过精心设计的API进行:
# 源码中状态更新的核心逻辑(简化版)
class StateManager:
def update(self, current_state: State, new_values: dict) -> State:
"""合并更新:新值覆盖旧值,其他字段保留"""
if not new_values:
return current_state
# 深度合并逻辑
updated = current_state.copy()
for key, value in new_values.items():
if key in self._reserved_fields:
raise ValueError(f"Field {key} is reserved")
if isinstance(value, dict) and key in updated:
# 字典字段的深度合并
updated[key] = self._deep_merge(updated[key], value)
else:
# 普通字段直接覆盖
updated[key] = value
return updated
def assign(self, current_state: State, updates: dict) -> State:
"""赋值操作:只更新指定字段,其余保持原样"""
return self.update(current_state, updates)
def delete(self, current_state: State, keys: List[str]) -> State:
"""删除字段:清理不再需要的状态"""
updated = current_state.copy()
for key in keys:
if key in updated:
del updated[key]
return updated
关键设计细节:
- 深度合并:对嵌套字典进行递归合并,而不是简单覆盖
- 保留字段保护:防止系统保留字段被意外修改
- 不可变设计:总是返回新状态对象,便于状态回滚
状态不能随便改,就像不能直接拿橡皮擦涂改合同。
为了防止出错,系统提供了update /assign/delete三个标准方式来更新状态,保证每一步修改都清晰、安全。
状态本质是一个字典,简单灵活,适合快速搭建原型
在源码层面,StateGraph会通过_infer_state_schema方法自动推断状态结构,但显式定义能获得更好的类型提示和编译期检查。
建议:虽然能自动识别,但主动说明结构更稳妥,写代码时更有提示,也更容易发现拼写错误。
2.4 模式2:Pydantic模型(需要数据验证时)
核心痛点: 数据结构缺乏约束时,外部传入的无效或多余字段容易导致程序行为不可控,增加调试难度和运行风险。
核心方案: 通过定义严格的数据模型,在数据进入系统时自动校验并过滤非法字段,确保状态的一致性和安全性。
2.4.1 什么是 Pydantic 模型?
Pydantic 模型是 Python 中基于pydantic库实现的结构化数据定义与校验工具,核心是通过类(继承BaseModel)定义数据的 “契约”—— 明确字段的类型、默认值、校验规则,让非结构化的字典 / JSON 变成 “有规可依” 的结构化数据,同时自动完成数据验证、类型转换和错误提示。
简单来说:Pydantic 模型是数据的 “说明书 + 质检员”—— 既告诉你数据该长什么样(说明书),又会自动检查输入的数据是否符合要求(质检员)。
Pydantic 模型核心定位:解决 Python 动态类型的痛点
Python 是动态类型语言,变量类型不强制声明,容易出现 “传错数据类型”“字段缺失”“数值超出范围” 等问题(比如本该传字符串的查询语句传了数字,本该传 0-1 之间的置信度传了 2)。
Pydantic 模型的核心价值就是用静态的结构化定义约束动态的 Python 数据,常见场景包括:
- 配置文件解析与校验;
- API 接口请求 / 响应数据校验;
- 大模型 / Agent 框架(如 LangGraph/LangChain)的状态管理;
- 数据序列化 / 反序列化(字典 ↔ JSON ↔ 模型)。
Pydantic 是 Python 中用于数据验证、序列化和结构化定义的核心库,也是 LangGraph、LangChain 等 Agent 框架中定义状态 / 数据结构的首选方案。
Pydantic 通过类(继承BaseModel)的方式定义数据的 “契约”—— 明确字段类型、默认值、校验规则,既能自动校验数据合法性,又能保证数据格式的一致性,完美解决了 “随意传数据导致的混乱” 问题。
2.4.2 极简的定义方式:类 + 字段
只需继承pydantic.BaseModel,像定义普通类一样声明字段和类型,就能创建一个 Pydantic 模型:
from pydantic import BaseModel
from typing import List, Optional
# 定义一个 Pydantic 模型(比如 LangGraph 的 Agent 状态)
class AgentState(BaseModel):
# 必选字段:字符串类型(无默认值,必须传值)
query: str
# 可选字段:列表类型,默认值为空列表
tool_calls: List[dict] = []
# 可选字段:字符串类型,默认值为空字符串
final_answer: str = ""
# 可选字段:浮点型,允许为 None(Optional)
confidence: Optional[float] = None
上面这段代码定义了一个名为AgentState的数据模型,用来规范程序中使用的状态数据格式。
简单说:这个模型就像一张“数据入场券”,只有符合规定的字段才能进入,保证内部处理的数据干净、可靠。
2.4.2. 自动数据校验:不符合规则就报错
实例化模型时,Pydantic 会自动检查每个字段的类型、值是否符合定义,不符合则抛出清晰的异常,提前暴露问题:
# 合法实例化:所有字段符合规则
valid_state = AgentState(
query="查询订单服务CPU使用率",
tool_calls=[{"tool": "prometheus", "params": {"service": "order-service"}}],
confidence=0.9
)
# 非法实例化:confidence 是字符串(本该是浮点型)
try:
invalid_state = AgentState(
query="查询订单服务CPU使用率",
confidence="高" # 类型错误
)
except Exception as e:
print(e)
# 输出:1 validation error for AgentState
# confidence
# Input should be a valid number, got '高' [type=type_error.number]
2.4.3. 支持默认值:可选字段无需强制传值
为字段设置默认值后,实例化时可省略该字段。
Pydantic 会自动填充默认值,避免 “字段缺失” 报错:
# 省略 tool_calls 和 final_answer,自动使用默认值
state = AgentState(query="查询订单服务日志")
print(state.tool_calls) # 输出:[](默认空列表)
print(state.final_answer) # 输出:""(默认空字符串)
2.4.4. 灵活的类型支持:从基础类型到复杂结构
Pydantic 支持 Python 几乎所有类型,包括:
- 基础类型:str/int/float/bool;
- 容器类型:List/Dict/Tuple/Set;
- 复杂类型:嵌套 Pydantic 模型、datetime/UUID、自定义类;
- 可选类型:Optional[T](允许字段为 None)。
示例(嵌套模型):
from pydantic import BaseModel
# 子模型:工具调用详情
class ToolCall(BaseModel):
tool_name: str
params: dict
# 主模型:嵌套子模型
class AgentState(BaseModel):
query: str
tool_calls: list[ToolCall] = [] # 列表元素是 ToolCall 模型
# 实例化嵌套模型
state = AgentState(
query="查询日志",
tool_calls=[ToolCall(tool_name="elk", params={"service": "order-service"})]
)
# 访问嵌套字段
print(state.tool_calls[0].tool_name) # 输出:elk
2.4.5. 便捷的序列化 / 反序列化
Pydantic 模型可一键转换为字典、JSON 等格式,也可从字典 / JSON 恢复为模型,方便数据传输和存储:
# 模型 → 字典
state_dict = state.model_dump()
# 模型 → JSON 字符串
state_json = state.model_dump_json(indent=2)
# 字典 → 模型
new_state = AgentState.model_validate(state_dict)
# JSON 字符串 → 模型
new_state_from_json = AgentState.model_validate_json(state_json)
2.4.6. 自定义校验规则:适配业务场景
如果基础校验不够用,可通过@field_validator自定义校验逻辑(比如校验服务名格式、时间格式):
from pydantic import BaseModel, field_validator
class AgentState(BaseModel):
service_name: str
# 自定义校验:服务名必须以 "-service" 结尾
@field_validator("service_name")
def check_service_name(cls, value):
if not value.endswith("-service"):
raise ValueError(f"服务名必须以'-service'结尾,当前值:{value}")
return value
# 非法值:service_name 不符合规则
try:
AgentState(service_name="order")
except Exception as e:
print(e)
# 输出:1 validation error for AgentState
# service_name
# 服务名必须以'-service'结尾,当前值:order [type=value_error, input_value='order']
2.4.7、核心小结
Pydantic 模型的本质是:用类的形式定义数据的 “结构化契约”,自动完成数据校验、类型转换和序列化。
它解决了 Python 动态类型带来的 “数据混乱” 问题,让数据从 “无规则的字典” 变成 “有约束的模型”—— 这也是 LangGraph 等人工智能框架要求用 Pydantic 定义状态的核心原因:确保所有组件共用一套数据规则,避免状态传递时出错。
2.5 langgraph 状态StateManager 操作的三大核心方法
LangGraph 状态操作三大核心方法:update、assign、delete
LangGraph 中的StateManager封装了状态操作的核心逻辑,update、assign、delete三个方法构成了状态修改的 “三板斧”。
三大核心方法:update、assign、delete既保证状态更新的安全性(不可变设计),又兼顾灵活性(深度合并),是 LangGraph 实现可靠工作流的基础。
class StateManager:
def update(self, current_state: State, new_values: dict) -> State:
"""合并更新:新值覆盖旧值,其他字段保留"""
if not new_values:
return current_state
# 深度合并逻辑
updated = current_state.copy()
for key, value in new_values.items():
if key in self._reserved_fields:
raise ValueError(f"Field {key} is reserved")
if isinstance(value, dict) and key in updated:
# 字典字段的深度合并
updated[key] = self._deep_merge(updated[key], value)
else:
# 普通字段直接覆盖
updated[key] = value
return updated
def assign(self, current_state: State, updates: dict) -> State:
"""赋值操作:只更新指定字段,其余保持原样"""
return self.update(current_state, updates)
def delete(self, current_state: State, keys: List[str]) -> State:
"""删除字段:清理不再需要的状态"""
updated = current_state.copy()
for key in keys:
if key in updated:
del updated[key]
return updated
下面结合源码逐行拆解每个方法的设计思路、使用场景和核心细节:
2.5.1、核心前提:状态的 “不可变设计”
在看具体方法前,先明确一个关键原则:LangGraph 的状态是不可变的(Immutable)—— 所有状态操作都不会修改原状态对象,而是返回一个 “新的状态副本”。
源码中updated = current_state.copy()就是这个原则的体现:哪怕只改一个字段,也会先复制原状态,再在副本上修改,避免原状态被意外篡改(这是分布式 / 并发场景下数据安全的核心保障)。
2.5.2、update 方法:深度合并更新(核心中的核心)
1. 方法定位
update是状态修改的基础方法,核心逻辑是“新值覆盖旧值,字典字段深度合并,其他字段保留”—— 既支持简单字段的直接更新,也支持嵌套字典的精细化修改,是最常用的状态操作方法。
2. 源码逐行拆解
def update(self, current_state: State, new_values: dict) -> State:
"""合并更新:新值覆盖旧值,其他字段保留"""
# 边界处理:无新值时直接返回原状态(避免无意义的副本创建)
if not new_values:
return current_state
# 第一步:创建原状态的副本(不可变设计核心)
updated = current_state.copy()
for key, value in new_values.items():
# 安全校验:禁止修改预留字段(框架内置的核心字段,防止业务误改)
if key in self._reserved_fields:
raise ValueError(f"Field {key} is reserved")
# 核心分支:区分“字典字段”和“普通字段”
if isinstance(value, dict) and key in updated:
# 场景1:新值是字典,且原状态有该字段 → 深度合并(保留原字典的未修改字段)
updated[key] = self._deep_merge(updated[key], value)
else:
# 场景2:普通字段(字符串/数字/列表等)→ 直接覆盖
updated[key] = value
return updated
3. 关键细节说明
(1)预留字段校验
self._reserved_fields是框架预先定义的 “不可修改字段”(比如thread_id、checkpoint_id等核心元信息),业务代码如果试图修改这些字段,会直接抛出异常 —— 避免核心元数据被篡改导致工作流崩溃。
(2)深度合并(_deep_merge)
这是update方法的灵魂,针对嵌套字典的场景设计。
比如原状态中有tool_calls字段(字典类型):
# 原状态
current_state = {
"query": "查询订单服务CPU",
"tool_calls": {"prometheus": {"service": "order-service", "time_range": "1h"}}
}
# 新值:只修改 tool_calls 中的 time_range,新增一个参数
new_values = {
"tool_calls": {"prometheus": {"time_range": "2h", "metrics": "cpu_usage"}}
}
# update 后的结果(深度合并)
updated_state = state_manager.update(current_state, new_values)
print(updated_state["tool_calls"])
# 输出:{"prometheus": {"service": "order-service", "time_range": "2h", "metrics": "cpu_usage"}}
如果没有深度合并,直接覆盖会丢失原有的service字段;
而深度合并只修改指定子字段,保留其他内容,实现了 “精细化更新”。
(3)普通字段直接覆盖
对于非字典字段(字符串、数字、列表等),直接用新值替换旧值:
# 原状态
current_state = {"query": "查询CPU", "confidence": 0.8}
# 新值
new_values = {"confidence": 0.9}
# update 后
updated_state = state_manager.update(current_state, new_values)
print(updated_state)
# 输出:{"query": "查询CPU", "confidence": 0.9}
说明:
- 状态的 “增量更新”:只改需要改的字段,其余保留;
- 嵌套字典的精细化修改:比如修改工具调用参数、补充日志信息等;
- 大多数业务场景的默认选择(优先用 update)。
2.5.3、assign 方法:赋值操作(update 的别名)
assign是update方法的 “别名”,源码中直接返回self.update(...)。
assign 从功能上和update完全一致,核心目的是语义化区分操作意图。
源码解析
def assign(self, current_state: State, updates: dict) -> State:
"""赋值操作:只更新指定字段,其余保持原样"""
return self.update(current_state, updates)
assign 设计意图:语义化编程
为什么要做一个和update功能完全一样的方法?
核心是让代码更易读—— 不同的方法名对应不同的 “操作意图”:
- update:强调 “合并更新”(尤其是嵌套字典);
- assign:强调 “赋值”(普通字段的直接设置)。
比如:
# 语义上“赋值”一个新的查询语句(用 assign 更易读)
state = state_manager.assign(state, {"query": "查询订单服务内存使用"})
# 语义上“合并更新”工具调用参数(用 update 更易读)
state = state_manager.update(state, {"tool_calls": {"prometheus": {"metrics": "mem_usage"}}})
assign 说明
- 普通字段的 “赋值” 操作(字符串、数字、布尔值等);
- 希望代码语义更清晰的场景(明确 “我就是要给某个字段赋值”)。
2.5.4、delete 方法:删除字段(状态清理)
delete是唯一的 “状态清理” 方法,核心逻辑是删除指定字段,返回新状态副本—— 用于清理不再需要的临时字段(比如临时工具调用结果、中间计算值),避免状态无限膨胀。
源码逐行拆解
def delete(self, current_state: State, keys: List[str]) -> State:
"""删除字段:清理不再需要的状态"""
# 第一步:创建原状态副本(不可变设计)
updated = current_state.copy()
for key in keys:
# 安全删除:字段存在才删除,避免 KeyError
if key in updated:
del updated[key]
return updated
关键细节说明
(1)安全删除
源码中先判断if key in updated再执行del,避免因删除不存在的字段抛出KeyError—— 框架级的容错设计,减少业务代码的异常处理负担。
(2)批量删除
支持传入字段列表,一次性删除多个字段:
# 原状态
current_state = {
"query": "查询日志",
"temp_log_data": "...", # 临时字段,用完可删
"temp_metric_data": "...", # 临时字段
"final_answer": ""
}
# 删除两个临时字段
updated_state = state_manager.delete(current_state, ["temp_log_data", "temp_metric_data"])
print(updated_state)
# 输出:{"query": "查询日志", "final_answer": ""}
delete 适用场景
- 清理临时字段:比如工具调用的原始结果、中间计算值;
- 状态瘦身:避免状态包含过多无用信息,减少存储 / 传输开销;
- 重置字段:删除后可重新赋值(等价于 “清空字段”)。
2.5.5、三大方法对比与使用原则
| 方法 |
核心逻辑 |
适用场景 |
关键特点 |
| update |
深度合并更新(字典)/ 直接覆盖(普通字段) |
增量更新、嵌套字典修改 |
保留未修改字段,支持精细化更新 |
| assign |
与 update 完全一致(语义别名) |
普通字段赋值,强调 “设置值” 的意图 |
语义更清晰,无功能差异 |
| delete |
删除指定字段,返回新副本 |
清理临时字段、状态瘦身 |
安全删除(无 KeyError) |
核心使用原则
- 优先用 update/assign:绝大多数状态修改场景(赋值、增量更新)都用这两个方法,二选一的核心是 “语义清晰”;
- delete 只用于清理:仅当字段不再需要时使用,避免误删核心字段;
- 牢记不可变设计:所有方法都返回新状态,必须用变量接收返回值(原状态不会变):
# 错误用法:原状态不会变
state_manager.update(state, {"final_answer": "CPU使用率80%"})
# 正确用法:接收新状态
state = state_manager.update(state, {"final_answer": "CPU使用率80%"})
- 避免修改预留字段:_reserved_fields 是框架保护的字段,业务代码不要试图修改(比如 thread_id、checkpoint_id)。
2.6、检查点与持久化:断电也不怕,咱有存档!
玩游戏最怕啥? 打到一半关机,重来一遍?太痛苦了。
所以高级游戏都有“自动存档”功能。
LangGraph 也一样,在关键节点把状态保存下来,这就叫Checkpointer(检查点)。
2.6.1 检查点数据结构
你可以把它想象成一个“游戏存档文件”,Checkpointer 里面记着:
- 当前状态(state)
- 跑到了哪个节点
- 时间戳、会话ID等元信息
每次跑完一轮“超步”(即一次循环),就调用:
self.checkpointer.put(config, state)
把当前进度存进数据库 or Redis or 文件系统。 下次继续时:
checkpoint = self.checkpointer.get(config)
看看有没有存过档。
这意味着:
- 即使服务重启,你的 Agent 也不会丢失进度;
- 支持长时间运行的任务(比如调研+写报告要几个小时);
- 可以实现“断点续聊”、“中断恢复”等生产级功能。
Checkpointer 对开发者来说意味着:
- 写节点时只需关注“我要改什么”,不用管别人;
- 系统自动帮你合并、调度、存档;
2.6.2 多后端存储支持
来个 简化的检查点结构
@dataclass
class Checkpoint:
checkpoint_id: str
thread_id: str
state: Dict[str, Any] # 序列化的状态
created_at: datetime
metadata: Dict[str, Any]
# 支持分支和版本
parent_checkpoint_id: Optional[str]
checkpoint_version: int
上面这个Checkpoint类,就是一次“存档”的完整记录。我们来逐个拆解它都存了啥:
- checkpoint_id:本次存档的唯一身份证号,防止重复或搞混。
- thread_id:属于哪个“对话线程”或“任务流程”。比如你和 AI 聊天,每次新对话都有一个独立 thread_id。
- state:这是最核心的部分,保存的是当前所有变量、数据的状态,而且是序列化过的(可以简单理解为打包成 JSON 或字节流,方便存储和传输)。
- created_at:存档时间,方便做超时清理或查看历史。
- metadata:额外信息,比如是谁触发的、用了什么模型、耗时多少等,用于监控和调试。
- parent_checkpoint_id:上一个存档是谁?有了它,就能把一次次存档连成一条链,甚至支持“回滚”到之前的某个状态。
- checkpoint_version:版本号,防止并发写入导致状态覆盖。就像 Git 提交一样,版本递增,确保不会“踩脚”。
打个比方:
想象你在写一篇长文章,用的是一个会自动保存草稿的编辑器。
- 每次自动保存 = 创建一个 Checkpoint
- 不同章节的草稿 = 不同的 state
- 草稿之间的“上一版”关系 = parent_checkpoint_id
- 编辑器崩溃后恢复 = 从最新 Checkpoint 恢复执行
这样你就不会因为断电而痛失三千字了。
Checkpoint 的生命周期核心流程图:
下面这张图展示了 Checkpoint 是如何在系统中流转的:
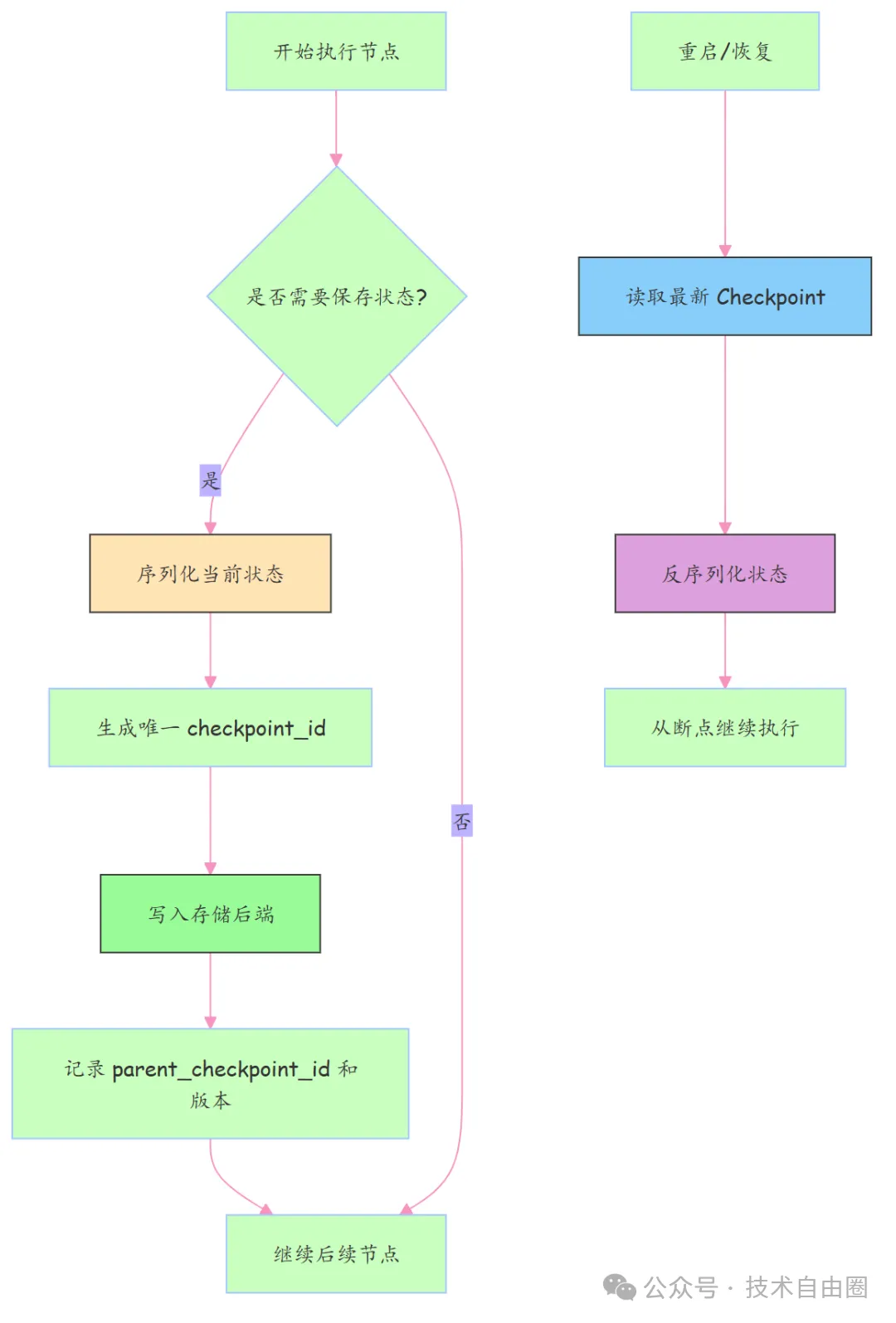
存储后端不止一种
光有数据结构还不够,你还得决定把“存档”存在哪。
就像游戏可以存到本地硬盘、云盘或者 U 盘里一样,Checkpoint 也需要灵活的存储选择。
从源码来看,框架支持多种Checkpointer 实现,比如:
- 内存存储:适合测试或单机运行,速度快但不持久。
- 文件系统:存成 .json 或 .pkl 文件,简单直观。
- 数据库:如 PostgreSQL、MongoDB,支持高并发、可追溯。
- 分布式存储:如 Redis + S3 组合,适合大规模服务部署。
这样做的好处是:业务逻辑不变,换存储就像换电池一样简单。开发时用内存,上线用数据库,完全不影响主流程代码。
提示:这些存储实现都遵循同一个接口,所以你可以根据项目需求自由切换,这也是“插件化设计”的典型体现。
总结一下:
Checkpoint不只是一个数据类,它是整个系统可恢复、可追踪、可扩展的基础。掌握它,你就掌握了构建健壮工作流的第一把钥匙。
2.6.3 内存存储类型的Checkpointer—— MemorySaver(开发测试用)
先来看一个叫MemorySaver的类。
听名字就知道,它是用来“保存检查点”的——就像你在打游戏时手动存个档,防止挂了从头开始。
这个类继承自BaseCheckpointSaver,说明它是个具体的“存档方式”。
而它干的事儿特别简单粗暴:把检查点存在内存里,也就是程序运行时的 RAM 中。
你可以把它想象成一个临时记事本:随手写点东西,记得快、找得也快,但一旦关机(程序结束),本子就没了,内容全丢。
它是怎么存的?
看它的构造函数:
class MemorySaver(BaseCheckpointSaver):
def __init__(self):
self.storage: Dict[str, List[Checkpoint]] = {}
这行代码的意思是:我搞了个字典(dict),键是字符串str,值是一个检查点列表List[Checkpoint]。
举个生活中的例子:
就像你家有好几个抽屉(每个抽屉贴了标签,比如“厨房用品”、“工具”、“药品”),每个抽屉里可以放多个对应的东西。
这里的“标签”就是str(比如用户ID或任务ID),“抽屉”就是List[Checkpoint],里面装的是不同时间点的“存档”。
所以,storage相当于一个带标签的多层收纳箱,按组管理检查点数据。
注意事项
- 优点:读写飞快,适合频繁保存/恢复场景。
- 缺点:断电即失,不能持久化。别指望重启后还能读到老数据。
所以这种存储方式,通常只用于测试、调试,或者对可靠性要求不高但追求速度的场景。
MemorySaver 核心流程图解
下面这张图展示了MemorySaver的基本工作流程,用不同颜色区分关键角色:
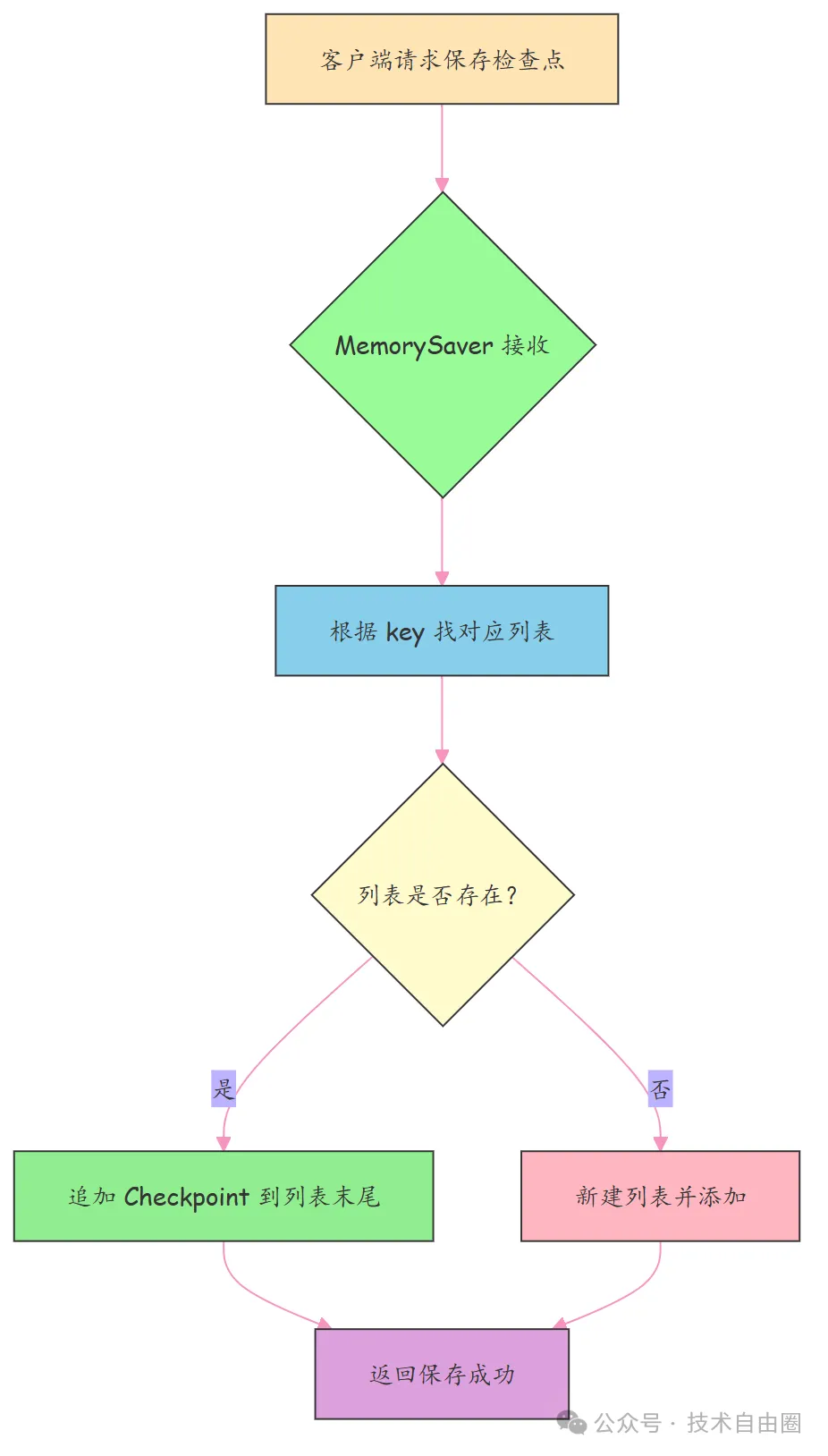
MemorySaver就是个基于内存的临时存档管家,速度快、实现简单,但不抗摔(程序一停全没)。
适合用在需要快速迭代、不怕丢数据的场景。
2.6.4 SQLite 存储 - 轻量级生产环境 检查点
来看一个叫SqliteSaver的类,它专门用来把程序运行过程中的“检查点”(Checkpoint)保存到 SQLite 数据库里。
SqliteSaver把数据存进了 SQLite 这个轻量级数据库里。
它是怎么初始化的?来看这段代码:
class SqliteSaver(BaseCheckpointSaver):
def __init__(self, conn: sqlite3.Connection):
self.conn = conn
这其实很简单:
当你创建一个SqliteSaver实例的时候,必须传进去一个已经连好的 SQLite 数据库连接(conn)。
就像你去银行开户,得先拿着身份证和钱去柜台一样——这里,“数据库连接”就是你的“入场券”。
- BaseCheckpointSaver 是它的父类,说明它遵循一套通用的存档规范。
- self.conn = conn 表示把这个连接保存下来,以后每次要存档或读档时,就通过这个连接操作数据库。
SQLite 是个文件型数据库,不用装服务器,适合本地小项目。
SqliteSaver就是个“ 本地档案管理员”,你给它一个数据库钥匙(conn),它就能帮你把程序的状态一条条规规矩矩地记到账本(SQLite 本地文件)里,随时可查。
2.6.5 PostgreSQL 存储 - 分布式生产环境
接下来看PostgresSaver类 —— 它是专门为分布式、高并发生产环境设计的检查点存储实现,把 Agent 工作流的 “存档” 持久化到 PostgreSQL 数据库中。
如果说SqliteSaver是 “本地 U 盘”,那PostgresSaver就是 “企业级云盘”:
PostgresSaver支持多节点同时读写、事务保障、数据容灾,完美适配大规模分布式部署的 LangGraph 应用(比如多实例 Agent 集群、跨机房部署)。
先看核心初始化代码,依然遵循 “单一职责” 和 “插件化设计”:
import psycopg2
from psycopg2.extensions import connection as PGConnection
from typing import Optional, Dict, Any
class PostgresSaver(BaseCheckpointSaver):
"""PostgreSQL 检查点存储实现,适配分布式生产环境"""
def __init__(
self,
conn: Optional[PGConnection] = None,
conn_kwargs: Optional[Dict[str, Any]] = None,
table_name: str = "langgraph_checkpoints"
):
# 优先使用外部传入的连接(复用连接池)
if conn:
self.conn = conn
elif conn_kwargs:
# 无外部连接时,通过参数创建新连接
self.conn = psycopg2.connect(**conn_kwargs)
else:
raise ValueError("必须提供 conn 或 conn_kwargs 初始化 PostgresSaver")
# 检查点数据表名(默认 langgraph_checkpoints)
self.table_name = table_name
# 初始化数据表(确保表存在)
self._init_table()
这段代码藏着几个生产级设计细节,我们拆解来看:
(1) 连接方式灵活:
- 支持传入现成的 PGConnection(推荐!可复用连接池,避免频繁创建 / 销毁连接);
- 也支持传入 conn_kwargs(如 host/user/password),自动创建连接;
- 二者必选其一,避免无连接导致的空指针。
(2) 表名可配置:默认 langgraph_checkpoints,但允许业务自定义(比如多租户场景分表);
(3) 自动建表:调用 _init_table() 确保数据表存在,避免 “表不存在” 的运行时错误。
PostgreSQL 是关系型数据库中的 “全能选手”,支持事务、索引、分区表 —— 给检查点加个索引在thread_id和checkpoint_id上,百万级存档查询也能毫秒级响应。
核心初始化逻辑:自动建表
_init_table()方法是生产环境的 “兜底保障”,确保数据表结构符合要求:
def _init_table(self):
"""初始化检查点数据表,不存在则创建"""
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {self.table_name} (
checkpoint_id VARCHAR(64) PRIMARY KEY,
thread_id VARCHAR(64) NOT NULL,
state JSONB NOT NULL, -- 序列化的状态(JSONB 支持高效查询)
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
metadata JSONB,
parent_checkpoint_id VARCHAR(64),
checkpoint_version INT NOT NULL DEFAULT 1,
-- 索引加速查询
CONSTRAINT fk_parent_checkpoint FOREIGN KEY (parent_checkpoint_id)
REFERENCES {self.table_name}(checkpoint_id)
);
-- 给常用查询字段加索引
CREATE INDEX IF NOT EXISTS idx_thread_id ON {self.table_name}(thread_id);
CREATE INDEX IF NOT EXISTS idx_created_at ON {self.table_name}(created_at);
"""
with self.conn.cursor() as cur:
cur.execute(create_table_sql)
self.conn.commit()
关键设计点:
- 字段类型适配:用 JSONB 存储 state 和 metadata—— 既保留结构化,又支持对状态内字段的高效查询(比如按 thread_id + state->>'query' 筛选);
- 外键约束:parent_checkpoint_id 关联自身表,保证存档链的完整性;
- 索引优化:给 thread_id(按会话查存档)、created_at(按时间查存档)加索引,避免全表扫描;
- 事务保障:建表操作在事务中执行,避免表结构创建失败。
核心流程图:PostgreSQL 检查点的完整生命周期
PostgreSQL 作为分布式存储,流程比 SQLite 多了 “连接池”“事务”“分布式一致性” 等环节,
PostgreSQL 检查点核心流程拆解:
(1) 分布式 Agent 集群中的某个节点执行到关键步骤,触发 “保存检查点”;
(2) 从连接池获取空闲数据库连接(避免重复创建连接的性能损耗);
(3) PostgresSaver 开启数据库事务(保证原子性:要么全存成功,要么全失败);
(4) 把检查点数据写入主库,同时同步到从库(容灾:主库挂了从库顶上);
(5) 事务提交,连接释放回池,返回 “保存成功”;
(6) 若 Agent 重启 / 扩容,新节点从连接池拿连接,查询最新检查点,反序列化状态后从断点继续执行。
打个比方:这就像连锁超市的 “库存系统”——
- 每个门店(Agent 节点)卖货后,都要把库存变动(检查点)上报到总部数据库(PostgreSQL 主库);
- 总部会同步一份数据到备用机房(从库),防止总部服务器故障;
- 新开门店(扩容节点)可以直接查总部数据库,知道当前库存(状态),不用从头盘点。
核心方法实现:保存与读取检查点
生产级的PostgresSaver必须实现put(保存)和get(读取)方法,这是对接 LangGraph 框架的核心接口:
import json
from datetime import datetime
from typing import List, Optional
def put(self, config: Dict[str, str], state: Dict[str, Any]) -> str:
"""保存检查点到 PostgreSQL"""
# 生成唯一 checkpoint_id(可基于 UUID + 时间戳)
checkpoint_id = f"cp_{datetime.now().strftime('%Y%m%d%H%M%S')}_{config['thread_id']}"
parent_checkpoint_id = config.get("parent_checkpoint_id")
thread_id = config["thread_id"]
# 序列化状态(Pydantic 模型转 JSON)
serialized_state = json.dumps(state)
serialized_metadata = json.dumps(config.get("metadata", {}))
# 插入 SQL(使用参数化查询防止注入)
insert_sql = f"""
INSERT INTO {self.table_name} (
checkpoint_id, thread_id, state, metadata,
parent_checkpoint_id, checkpoint_version
) VALUES (%s, %s, %s, %s, %s, %s)
"""
try:
with self.conn.cursor() as cur:
# 获取当前 thread_id 的最新版本号
cur.execute(f"""
SELECT COALESCE(MAX(checkpoint_version), 0) + 1
FROM {self.table_name} WHERE thread_id = %s
""", (thread_id,))
version = cur.fetchone()[0]
# 执行插入
cur.execute(
insert_sql,
(checkpoint_id, thread_id, serialized_state,
serialized_metadata, parent_checkpoint_id, version)
)
self.conn.commit()
return checkpoint_id
except Exception as e:
self.conn.rollback()
raise ValueError(f"保存检查点失败:{str(e)}")
def get(self, config: Dict[str, str]) -> Optional[Checkpoint]:
"""从 PostgreSQL 读取最新检查点"""
thread_id = config["thread_id"]
# 查询指定 thread_id 的最新版本检查点
select_sql = f"""
SELECT * FROM {self.table_name}
WHERE thread_id = %s
ORDER BY checkpoint_version DESC LIMIT 1
"""
with self.conn.cursor() as cur:
cur.execute(select_sql, (thread_id,))
row = cur.fetchone()
if not row:
return None
# 解析为 Checkpoint 对象
return Checkpoint(
checkpoint_id=row[0],
thread_id=row[1],
state=json.loads(row[2]),
created_at=row[3],
metadata=json.loads(row[4]),
parent_checkpoint_id=row[5],
checkpoint_version=row[6]
)
关键生产级特性:
(1) 参数化查询:避免 SQL 注入,生产环境安全第一;
(2) 版本号自动递增:按 thread_id 维护版本,防止并发写入覆盖;
(3) 事务回滚:保存失败时回滚,避免脏数据;
(4) COALESCE 函数:处理 “无历史版本” 的情况,版本号从 1 开始;
(5) JSON 序列化:兼容 Pydantic 模型的 model_dump() 结果,保证状态完整性。
核心优势:为什么分布式场景选 PostgreSQL?
对比MemorySaver(测试)、SqliteSaver(单机生产),PostgresSaver的核心优势体现在:
| 特性 |
MemorySaver |
SqliteSaver |
PostgresSaver |
| 分布式多节点读写 |
不支持 |
易锁表 |
支持(行级锁) |
| 数据持久化 |
断电丢失 |
单机持久 |
分布式持久 + 容灾 |
| 并发性能 |
极快(内存) |
低(文件锁) |
高(连接池 + 索引) |
| 事务保障 |
无 |
单机事务 |
分布式事务 |
| 状态字段查询 |
无 |
需全表扫 |
JSONB 索引高效查询 |
| 容灾备份 |
无 |
手动备份 |
主从复制 + 定时备份 |
提示:
生产环境中,PostgresSaver通常配合 “连接池工具(如 psycopg2-pool)”+“定时备份”+“主从切换” 使用,确保 99.99% 的可用性 ,这是企业级 LangGraph 生产环境的标配。
总结一句话:
PostgresSaver是 LangGraph 检查点存储的 “分布式主力军”—— 它基于 PostgreSQL 的事务、索引、主从复制能力,解决了大规模分布式 Agent 集群的状态持久化、一致性、容灾问题,是从 “测试” 走向 “生产” 的核心选择。
存储后端选型总结
| 存储类型 |
核心优势 |
适用场景 |
核心痛点 |
| MemorySaver |
读写极快、实现简单 |
本地开发、单元测试、临时任务 |
断电丢失、不支持分布式 |
| SqliteSaver |
轻量级、无需部署服务器 |
单机生产、小流量场景、边缘设备 |
并发低、无容灾、不支持分布式 |
| PostgresSaver |
高并发、事务保障、容灾 |
分布式生产、高流量、企业级应用 |
部署稍复杂、需维护数据库 |
选型原则:
- 开发测试:无脑选 MemorySaver;
- 单机小流量生产:选 SqliteSaver;
- 分布式高并发生产:必选 PostgresSaver;
核心不变的是:所有存储实现都遵循BaseCheckpointSaver接口 —— 业务逻辑不用改,换存储只需要换 “存档管家”,这就是插件化设计的魅力。
掌握了 Checkpoint 的存储逻辑,你就掌握了 LangGraph 构建 “高可靠、可恢复”Agent 工作流的核心 —— 哪怕服务重启、集群扩容,用户的 Agent 会话也能从断点继续,不会丢失任何进度。
2.7 StateManager + Checkpointer 的关系
状态管理(StateManager)是 LangGraph 工作流的 “数据管家”,负责状态的安全更新、合并与清理。
检查点(Checkpointer)就是这个管家的 “保险箱”—— 把管家打理好的 “账本(状态)” 定期存进保险柜,哪怕管家临时离岗(程序重启),回来也能从保险箱里找回完整账本,继续干活。
二者是 LangGraph 保障数据一致性、可恢复性的核心组合,缺一不可
状态机的架构思维 = Pregel 模型 + Reducer + Checkpointer 三位一体
LangGraph 用Pregel 模型做状态安全控制,用Reducer + 不可变状态保证安全更新,用Checkpointer实现持久化,
三位一体,让复杂的 Agent 工作流也能稳定可靠地跑起来。
2.7.1 核心依赖:检查点依赖状态管理的 “规范数据”
检查点的核心是 “保存状态”,但它不会直接修改状态 ——所有状态的修改必须先通过 StateManager 的 update/assign/delete 方法完成,检查点只负责保存 “合规的最终状态”。
举个具体的执行链路:
# 1. 业务逻辑通过 StateManager 修改状态(不可变更新,生成新状态)
new_state = state_manager.update(current_state, {"final_answer": "CPU使用率80%"})
# 2. 检查点只保存这个“修改后的合规状态”,不做任何数据篡改
checkpoint_id = checkpointer.put(config={"thread_id": "user_123"}, state=new_state)
为什么要这样设计?
- 状态管理保证了 “存入检查点的状态是合法的”:预留字段未被篡改、嵌套字典深度合并完成、临时字段已清理;
- 检查点专注 “持久化”,不介入状态修改逻辑,符合 “单一职责” 原则;
- 恢复状态时,从检查点读取的是 “经过 StateManager 校验的完整状态”,避免脏数据流入工作流。
2.7.2 交互流程:状态更新 → 检查点保存 → 状态恢复
状态管理(记账) 和检查点( 存档) 的交互形成一个闭环,覆盖 “更新 - 保存 - 恢复” 全生命周期,
“记账 + 存档” 的完整流程:
(1) 记账:业务节点要修改状态时,必须找 StateManager(管家),管家按规则(深度合并、预留字段校验)生成新账本(新状态);
(2) 存档:当工作流走到关键节点(比如每轮对话结束、工具调用完成),Checkpointer(保险箱)把新账本序列化后存起来,记录存档版本、所属线程等信息;
(3) 取档:程序重启 / 扩容后,Checkpointer 从存储后端取出最新账本,反序列化为 State 对象,交还给 StateManager 继续管理,工作流从断点处继续执行。
2.7.3 核心价值:二者结合实现 “安全 + 可恢复”
| 能力维度 |
状态管理(StateManager)贡献 |
检查点(Checkpointer)贡献 |
| 数据一致性 |
保证状态修改的规则统一(不可变、深度合并) |
保证状态存储的版本统一(版本号、父 ID) |
| 数据安全性 |
防止预留字段篡改、非法字段更新 |
防止状态丢失、并发写入覆盖 |
| 故障恢复 |
恢复后的状态可继续按规则修改 |
提供故障前的最新状态,支持断点续跑 |
| 生产级适配 |
支持状态瘦身、精细化更新 |
支持分布式存储、容灾备份,适配大规模部署 |
2.7.4 源码级交互示例:完整的 “更新 - 保存 - 恢复”
下面用一段整合代码,展示 StateManager 和 Checkpointer 的协同工作:
# 1. 定义状态模型(Pydantic)
from pydantic import BaseModel
class AgentState(BaseModel):
query: str
tool_calls: list = []
final_answer: str = ""
# 2. 初始化状态管理器和 PostgreSQL 检查点
state_manager = StateManager()
import psycopg2
conn = psycopg2.connect(host="localhost", user="postgres", password="123456", dbname="langgraph")
checkpointer = PostgresSaver(conn=conn)
# 3. 初始状态
current_state = AgentState(query="查询订单服务CPU使用率")
# 4. 状态管理:更新状态(不可变)
new_state = state_manager.update(current_state, {
"tool_calls": [{"tool": "prometheus", "params": {"service": "order-service"}}],
"final_answer": "订单服务CPU使用率80%"
})
# 5. 检查点:保存更新后的状态
checkpoint_id = checkpointer.put(
config={"thread_id": "user_123", "parent_checkpoint_id": None},
state=new_state.model_dump() # 序列化 Pydantic 状态为字典
)
# 6. 模拟程序重启
del current_state, new_state
# 7. 检查点:恢复最新状态
restored_checkpoint = checkpointer.get(config={"thread_id": "user_123"})
restored_state = AgentState(**restored_checkpoint.state) # 反序列化为状态对象
# 8. 状态管理:继续修改恢复后的状态
updated_restored_state = state_manager.assign(restored_state, {"final_answer": "订单服务CPU使用率82%"})
print(f"恢复后的状态:{updated_restored_state}")
# 输出:query='查询订单服务CPU使用率' tool_calls=[{'tool': 'prometheus', 'params': {'service': 'order-service'}}] final_answer='订单服务CPU使用率82%'
2.7.5 关键注意事项
(1) 序列化兼容性:
Checkpoint 存储的是 “序列化后的状态”(如 JSON 字典),必须和 StateManager 管理的 State 模型兼容(比如 Pydantic 的model_dump()/model_validate());
(2) 存档时机:
不要频繁存档(比如每个微小状态修改都存档),建议在 “节点执行完成”“分支判断前” 等关键节点存档,平衡性能和可恢复性;
(3) 状态清理 + 存档:
存档前建议用 StateManager 的delete方法清理临时字段,减少存档体积(比如删除工具调用的原始返回数据)。
2.7.6 总结:二者是 LangGraph 稳定运行的 “基石组合”
StateManager 解决了 “状态怎么改才安全” 的问题,Checkpointer 解决了 “改好的状态怎么存才不丢” 的问题 ——前者保证了工作流的 “过程安全”,后者保证了工作流的 “结果可恢复”。
掌握这二者的关系,就理解了 LangGraph 从 “本地测试玩具” 升级为 “生产级工作流框架” 的核心逻辑:既保证了复杂状态修改的可控性,又保证了分布式部署下的可靠性,这也是 LangGraph 对比其他 Agent 框架的核心优势之一。
LangGraph 源码圣经的后面第三章、第四章、第五章 目录如下 ,明天发布
- LangGraph 源码圣经(三):节点(Node)与边(Edge)的执行逻辑
- 3.1、节点(Node):工作流的 “逻辑执行单元”
- 3.2、节点的三种定义形式:从简单到复杂的灵活适配
- 第1种形式:函数节点:
- 第2种形式:类节点:
- 第3种形式:子图节点:
- 3.3、节点的执行触发机制:状态驱动的调用逻辑
- 3.4、节点的异步执行:同步 + 异步 结合,让 IO 不再卡住流程
- 3.5、特殊节点:中断节点与分支节点的实现
- 3.6、边(Edge):工作流的 “流转路由规则”
- 3.6.1. 固定路由:简单线性流转
- 3.6.2. 条件路由:动态分支跳转
- 3.6.3. 动态路由:多节点并行+动态跳转
- 3.7、 边的执行链路:从节点输出到下一个节点
- 3.8 、节点与边的协同执行:完整工作流示例
- 定义节点
- 定义边
- 3.9、源码设计亮点: 模块化 + 动态路由 =高扩展
- LangGraph 源码圣经(四):循环与终止机制设计
- 4.1、循环机制:流程怎么“回头再干一遍”?
- 4.1. 1. 显式循环:明明白白地“打转”
- 4.1.2. 隐式循环:用户推动的“多轮对话”
- 4.1.3. 循环节点(Loop Node):把复杂循环打包成“黑盒”
- 创建子图:封装工具调用+重试逻辑
- 主图中使用这个“循环节点”
- 核心流程图:循环机制执行逻辑(Mermaid)
- 4.2、终止机制:流程何时“功成身退”?
- 4.2.1. 固定终止:到站即停
- 4.2.2. 条件终止:看情况再决定走不走
- 4.2.3. 强制终止:紧急制动
- 终止机制流程图(Mermaid)
- 4.3、防死循环策略:别让流程“原地打转”
- 4.3.1. 最大迭代次数限制:兜底保险
- 4.3.2. 状态阈值校验:业务层面的“智能预警”
- 4.3.3. 状态回溯与循环检测:高级“自我诊断”
- 4.3.️ 3防死循环机制流程图
- LangGraph 源码圣经(五):实战场景与架构优化建议
- 5.1、LangGraph军规一 :别把业务逻辑塞进流程里
- 5.1.1. 编排归编排,干活归干活
- 5.1.2. 通用能力一定要抽出来复用
- 所有需要权限校验的流程均可复用该节点
- 路由规则:有权限继续,没权限终止
- 5.2、LangGraph军规二 :一个节点只干一件事
- 5.3、LangGraph军规三 :状态设计 需要 结构化 + 最小化 + 可扩展
- 5.4、LangGraph军规四: 路由设计,别玩嵌套判断
- 5.5、LangGraph军规四:节点执行 异步 + 缓存 设计
- 5.6、LangGraph军规五:状态管理:瘦身 + 快照控制
- 5.7、LangGraph军规七:链路保护加 限流 + 扩缩设计
 发表于 2025-12-11 03:32:49
|
查看: 305|
回复: 0
发表于 2025-12-11 03:32:49
|
查看: 305|
回复: 0
