研究背景
近年来,大型视觉语言模型(VLMs)在图像描述、视觉问答等多种多模态任务中表现卓越。这些模型能够有效地融合视觉和文本信息,展现出较强的多模态理解能力。然而,面对需要深度视觉感知与结构化逻辑推理的任务时,其性能仍存在明显瓶颈。一个直观的例子是,在看似简单的图像拼图任务中,现有模型的表现时常接近随机水平,这表明当前的预训练与微调策略未能充分培养出模型稳健的视觉推理能力。
同时,高质量的视觉语言数据对模型性能提升至关重要,但其稀缺性与有限的可扩展性,已成为制约能力突破的关键因素。因此,探索一种能够有效补充数据、并系统性增强模型感知与推理能力的新方法,具有重要的学术价值与应用前景。
研究方法
我们提出了名为AGILE(Agentic Jigsaw Interaction Learning,代理式拼图交互学习)的全新框架。该框架将拼图解决过程建模为一个动态的智能体与环境交互过程。在每一步交互中,模型需要生成可执行的Python代码来执行具体操作(如移动、旋转拼图块),环境则会提供细粒度的视觉反馈(例如拼图块的位置、边缘匹配情况),以指导后续动作。
通过这种“观察-生成代码-执行-获得反馈”的迭代循环,模型得以在探索与反馈中逐步优化其感知与推理策略。AGILE框架具备两大核心优势:
- 任务难度可控:通过调整初始正确拼图块的数量以及拼图的总体规模(如2x2, 3x3),可以精确控制任务的挑战级别。
- 数据可无限扩展:由于拼图任务的真实解是明确的,我们可以轻松合成大规模、多样化的训练数据集,有效解决了高质量多模态数据短缺的问题。这种结合了交互式训练与可扩展数据生成的范式,为提升大型视觉语言模型(VLMs)的底层能力提供了高效且通用的解决方案。
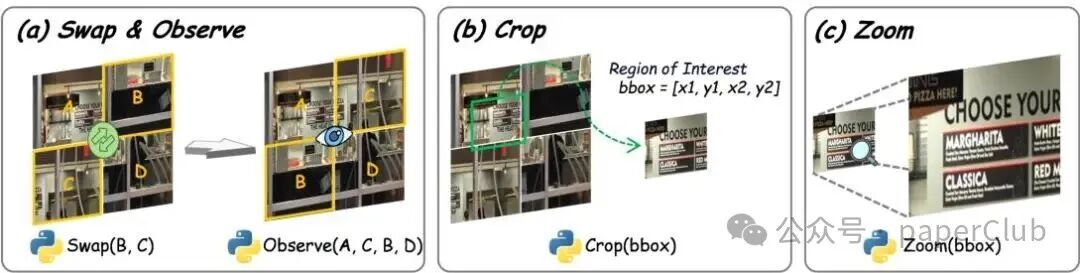 图1: 环境交互过程示意图,展示了拼图操作中的动作空间与反馈机制。
图1: 环境交互过程示意图,展示了拼图操作中的动作空间与反馈机制。
我们通过详尽的实验验证了AGILE的有效性。结果表明,该方法不仅能显著提升模型在不同复杂度拼图任务上的性能(例如,在2x2拼图设置下,准确率从9.5%大幅提升至82.8%),还在9个通用的视觉理解与推理任务上展现出优秀的泛化能力,平均性能提升达到3.1%。这证明,通过拼图这一代理任务进行训练,能够实质性地增强模型的视觉感知与结构化推理能力,为多模态模型的发展提供了新的思路。
研究结果
为全面评估AGILE在拼图任务上的表现,我们构建了一个包含300幅不同场景图像的测试集,每幅图像被分别划分为2x2和3x3的网格拼图。我们根据拼图完成的准确率(所有拼图块均正确放置才计为正确)以及得分(正确块数与总块数的比值)来评估性能。
在基础版本的Qwen2.5-VL-7B模型上,未经训练时其在2x2拼图上的准确率仅为9.5%。而经过我们的互动式训练与强化学习优化后,准确率在2x2设置下跃升至82.8%。在更具挑战性的3x3设置下,模型表现亦有显著改善,准确率从0.4%提升至20.8%,得分从31.1%提升至62.1%。
| 模型 |
2×2 准确率(%) |
3×3 准确率(%) |
|
L0 |
L1 |
L2 |
平均 |
L0 |
L1 |
L2 |
L3 |
L4 |
L5 |
L6 |
平均 |
| 随机 |
4.5 |
3.7 |
4.2 |
4.1 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
| GPT-4o |
38.7 |
37.7 |
47.0 |
41.1 |
1.0 |
1.3 |
2.7 |
3.0 |
3.0 |
7.0 |
13.7 |
4.9 |
| Gemini-2.5-Pro |
43.3 |
46.3 |
49.7 |
46.4 |
7.0 |
8.7 |
9.7 |
10.0 |
11.0 |
15.0 |
23.0 |
14.6 |
| Qwen2.5VL-7B |
6.3 |
6.0 |
16.3 |
9.5 |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
0.7 |
1.3 |
0.4 |
| AGILE + RL |
78.7 |
83.0 |
86.7 |
82.8 |
5.0 |
7.0 |
11.0 |
14.0 |
17.7 |
25.3 |
38.0 |
20.8 |
表1: 不同模型在拼图任务中的表现对比。L0、L1、L2表示拼图初始状态下的正确块数量,平均值为整体准确率。
此外,我们在9个典型的视觉任务上评估了模型的泛化能力。结果显示,AGILE框架通过逐步反馈的交互机制,在捕捉视觉实体关系、提升逻辑推理能力方面表现突出。尤其是在高分辨率图像理解、复杂真实场景分析以及细粒度视觉识别等任务中,模型的整体性能得到了显著提升。
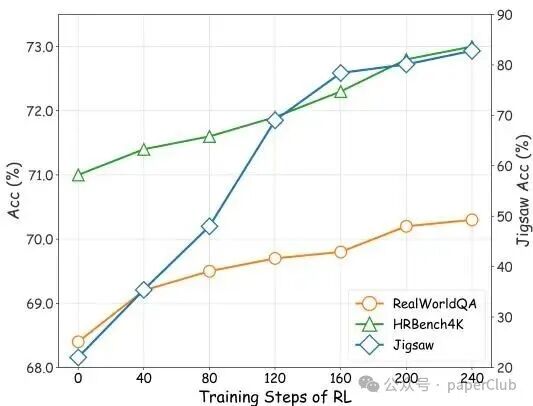 图3: 训练数据规模对拼图任务准确率的影响分析。
图3: 训练数据规模对拼图任务准确率的影响分析。
结论与展望
本研究提出的AGILE框架,通过将拼图解答建模为持续的交互过程,显著提升了大型视觉语言模型的底层视觉感知与结构化推理能力。实验证明,该方法在不同复杂度的拼图任务上取得了突破性性能,并在广泛的视觉任务上展现出强大的泛化能力。我们对数据规模影响的分析,进一步证实了拼图作为视觉感知与推理代理任务的有效性,为解决高质量多模态交互数据稀缺问题提供了一条可扩展的路径。未来的工作将聚焦于进一步提升框架的训练效率,并探索其在更复杂、更具现实意义的视觉推理任务中应用的潜力。
📚 文献信息
|  发表于 2025-12-11 03:34:40
|
查看: 300|
回复: 0
发表于 2025-12-11 03:34:40
|
查看: 300|
回复: 0
