
当前,大模型训练需要同时兼顾多个领域能力,包括Agentic能力、数学推理和代码生成等。如何训练一个能够在多个领域同时达到专家水平的通用模型,已成为一项关键挑战。尤其是在强化学习(RL)阶段,如何通过合理的训练机制与超参数配置,缓解多领域训练中的能力冲突与兼容问题,对于模型最终性能的提升至关重要。为此,三星研究院联合北京大学,发布了技术报告《R2Mixer(To Mix or To Merge: Toward Multi-Domain Reinforcement Learning for Large Language Models)》,系统分析了多领域RL的训练机理,通过系统级调优,显著提升了多领域RL后的模型效果。

结合去年10月份的相关报道,三星已向英伟达采购5万张 GPU 用于构建大规模AI基础设施。此举或许标志着三星在大模型领域正大幅加大投入,意在打造自主可控的基础模型体系,为未来在手机、智能终端、自动化工厂等场景中部署通用AI能力提供底层支撑。
关键痛点
在人工智能的浪潮中,LLM正以前所未有的速度席卷Agent、数学推理、代码生成、科学问题求解等关键领域。目前学界存在两种主流的RL后训练范式:
- 混合多任务范式:同时学习来自不同领域的数据和奖励;
- 专家融合范式:分别训练各领域专家,再通过权重合并或蒸馏技术融合。
两大路线各有优劣,DeepSeek-R1、Qwen3、GLM-4.5、MiMo-V2等明星模型亦选择不同路径,但学界对这两种范式的系统性对比和内在机制的分析仍然缺乏。面对构建通用多领域专家模型,存在以下几个核心痛点:
- 训练效率与性能的两难:不同领域的强化学习是否会产生梯度干扰,导致整体性能下降?混合多任务训练的计算成本是否低于分别训练后合并?
- 领域知识的迁移与干扰:不同领域的强化学习是否存在知识迁移效应?还是会产生互相干扰?这种关系在不同类型的任务之间是否有差异?
- 模型合并的内在机制:模型合并后的性能增益从何而来?不同合并方法之间有何优劣?如何选择最优的合并策略?
- 自我评判能力的演化:RLVR训练是否能够使模型获得自我评判能力?这种能力在不同训练范式下如何变化?
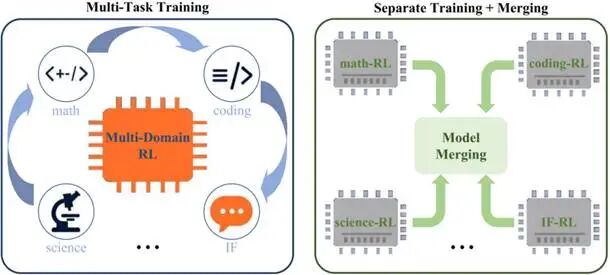
研究团队基于开源数据集进行完整的SFT+RL后训练过程,以实现可控的实验比较,进而深入分析其内在机制。
M2RL:系统性研究与实验设计
三星研究院开展了M2RL研究项目(Mixed multi-task training or separate training followed by model Merging for Reinforcement Learning),对多域强化学习进行了系统性的研究和分析。
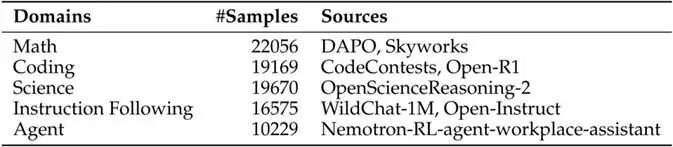
研究团队基于Nemotron 3 Nano技术报告中开源的SFT或RL数据进行实验,选择了五个常见的RLVR域:数学、编程、科学、指令跟随以及Agent。初始模型选用Qwen3-4B-Base,RL算法选用GRPO。
- 有监督微调(SFT):研究团队遵循Nemotron 3 Nano技术报告中的数据配比,将其开源数据进行合理组合。对于数量较多的开源数据集进行随机采样,对于数量较少的则重复使用(最多10次),最终获得~14M的数据用于有监督微调,详细配比如下:

- 强化学习训练:研究团队同样使用Nemotron 3 Nano开源的RL训练数据,其数据配比及来源总结如下:
- 模型融合方法:研究团队考虑了广泛使用的weight merging(对模型权重加权平均)和multi-teacher on-policy-distillation技术。其中,weight merging包括average merging, task arithmetic merging, Ties-merging以及SCE merging,同时也考察了这些方法与DARE的组合使用效果。对于MT-OPD,他们使用来自5个域的专家模型作为teacher蒸馏有监督微调后的模型,并设计相应的teacher路由策略。
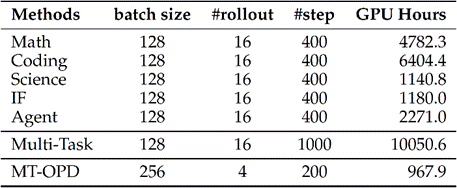
所有实验在相同型号显卡上运行,详细的训练设置及GPU Hours如下:
M2RL:评测结果及机制分析
1. 评测结果
研究团队在跨越5个域的9个benchmark上对模型进行评估:数学(AIME’24和AIME’25)、代码(LiveCodeBench v5和v6)、科学(HLE和GPQA-Diamond)、指令跟随(IFEval和IFBench)以及Agent(BFCL v3):
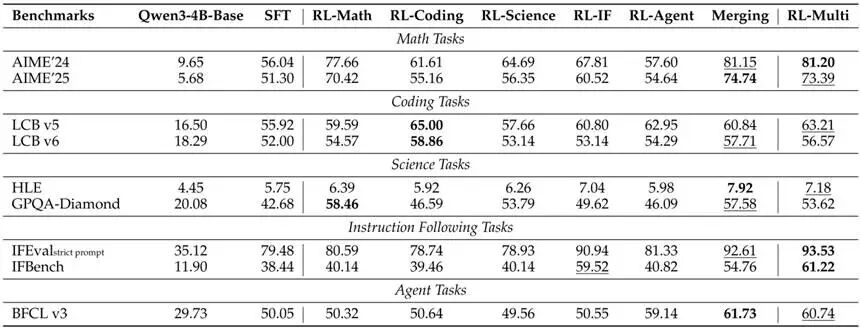
其中model merging报告的是Ties-merging的结果,其表现最佳;详细对比如下:

从上述结果可以看出:
[1] 就5个独立RL模型而言,math, coding, instruction following和agent域的RL模型都在对应域的benchmark上获得了最佳表现。有趣的是,math域的RL模型比science域的RL模型在science benchmark上获得了更好的表现,这可能是因为这两个science benchmark需要更多的逻辑推理和数学计算而非科学知识。
[2] 混合的多任务RL可以用约63.7%的GPU Hours获得与单独RL再融合相当的效果。不同域之间的干扰并不明显,甚至有增益。例如,三个推理相关的域(math, coding和science)的RL就互有增益,Instruction Following域也有助于这三个域的评估。有趣的是,所有其他域都对agent域没有增益,可能单轮的逻辑推理对于多轮的工具调用和环境交互价值有限,但仍然未观察到互相干扰现象。
[3] weight merging这类training-free的融合方法效果意外的很好,不仅继承了原始模型的绝大部分性能,甚至在AIME’24, AIME’25, HLE, IFEval和BFCL v3数据集比对应专家模型还要强,再次印证了不同域的互相增益效果。此外,weight merging无需额外的GPU Hours即可达到稍微优于MT-OPD的效果。
除了最终表现,研究团队还给出了不同域RL训练过程中模型在不同域的benchmark上的表现。具体地,选择AIME’24, LiveCodeBench v5, GPQA-Diamond, IFEval和BFCL v3分别作为math, coding, science, instruction following和agent域的代表,结果如下:
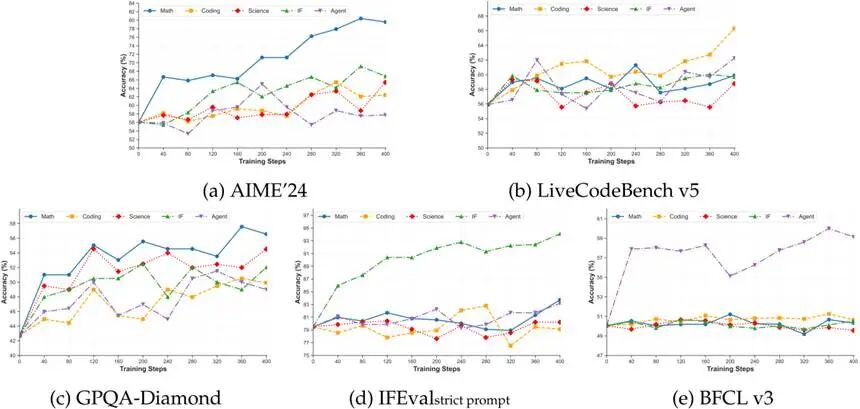
可以看到,三个推理域(math, coding和science)的RL过程可以稳定提升彼此的表现。此外,instruction following和agent域的任务只有对应域的RL能稳步提升表现,推理域RL对其并无增益。反之,instruction following和agent域的RL却可以或多或少的提升推理域的能力表现,说明推理为基本能力,各种域的学习都需要。
研究团队仅用开源数据,从Qwen3-4B-Base开始训练便获得了和官方的Qwen3-4B可比的结果,证明其工程实现的有效性:

除了上述评测结果之外,研究团队还从信息约束、模型预测行为和自我验证等角度深入分析多域强化学习的工作机理。更多分析内容详见论文。
总结与展望
三星研究院针对大模型后训练范式进行了系统的对比。研究通过严谨的受控实验,深入剖析了“混合多任务RL”与“专家模型融合”在多域能力构建中的性能边界。针对梯度干扰、领域知识迁移、模型合并机制及自我评判能力演化等行业核心痛点,该研究不仅揭示了多域强化学习的内在作用机理,更在训练效率与性能平衡上提供了关键保障,有效支撑了千亿、万亿等更大参数模型的模型训练。
这项研究为大模型训练提供了一种更高效的多领域能力构建思路,对于希望在有限算力下最大化模型通用性的团队具有重要参考价值。对这类前沿技术实践和讨论感兴趣的朋友,欢迎持续关注云栈社区的相关技术动态。
 发表于 2026-3-14 07:13:44
|
查看: 125|
回复: 0
发表于 2026-3-14 07:13:44
|
查看: 125|
回复: 0
