在Hive数据处理实践中,合理选择数据压缩与存储格式是提升存储效率与查询性能的关键。
一、Hive数据压缩
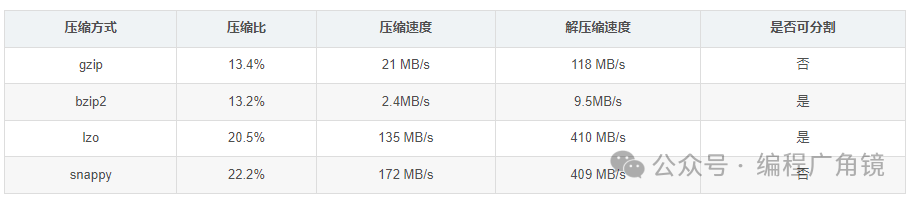
在Hive中使用压缩需要根据数据的不同阶段采取灵活策略:
- 数据源存储:建议采用RCFile/ORCFile + Bzip2或Gzip的方式,以最大限度节省磁盘空间。
- 计算过程存储:为了不影响任务执行速度,可牺牲部分存储空间,采用RCFile/ORCFile + Snappy的方式,以提升整体执行效率。LZO也是一种选择,但综合压缩比与速度,Snappy通常是更优解。
选择压缩算法时需权衡以下几点:
- 压缩比:越高越好,意味着更小的存储空间。
- 压缩/解压速度:越快越好,直接影响读写性能。
- 是否支持分割:可分割的格式允许多个Mapper并行处理单个文件,有利于提升并行化处理能力。
1. 配置中间数据压缩
在MapReduce的Shuffle阶段对中间数据进行压缩,可以减少网络I/O传输量。
-- 开启中间数据压缩
set hive.exec.compress.intermediate=true;
-- 设置压缩算法为Snappy
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
2. 配置最终输出结果压缩
对Hive任务最终输出到HDFS的文件进行压缩。
-- 开启最终输出压缩
set hive.exec.compress.output=true;
-- 设置输出压缩算法为Snappy
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
二、数据存储格式详解
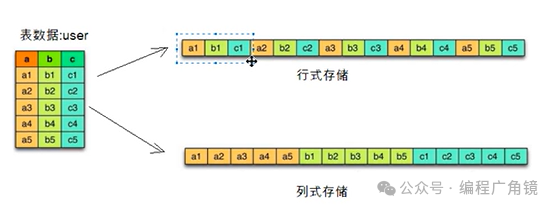
存储格式主要分为行存储和列存储:
- 行存储:将一条记录的所有字段连续存储。当需要频繁查询整行数据时,效率较高。
- 列存储:将同一列的数据聚集存储。在只查询少数几个列的场景下,能极大减少数据读取量,且同列数据类型一致,便于设计高效的压缩算法。
Hive支持多种文件格式,默认是TextFile,可通过set hive.default.fileformat;查看。
1. TEXTFILE
- 特点:默认格式,行式存储。
- 压缩:支持Gzip等,但压缩后文件不可分割,影响并行处理能力。
- 性能:反序列化开销较大。
- 建表语句:
STORED AS TEXTFILE
2. SEQUENCEFILE
- 特点:Hadoop API提供的二进制
key-value格式,行式存储。
- 压缩:支持NONE、RECORD、BLOCK三种级别,BLOCK级压缩率较高。文件可分割。
- 注意:通常比文本格式占用更多空间。
- 建表语句:
STORED AS SEQUENCEFILE
3. RCFILE
- 特点:行列混合存储。数据按行分块,每块内部按列存储。是早期的列式存储尝试。
- 优点:兼顾行存储的元组重构效率与列存储的压缩和查询优势。
- 缺点:数据加载性能较慢。
- 建表语句:
STORED AS RCFILE
4. ORCFILE
- 特点:Hive中最常用的列式存储格式,是RCFILE的改良版。
- 优点:压缩率高(支持ZLIB、SNAPPY),查询性能优异,自身支持切片,与Hive兼容性好。
- 应用:ZLIB压缩常用于ODS层(高压缩比),SNAPPY常用于DW层(快速查询)。
- 建表语句:
STORED AS ORC
5. Parquet
- 特点:与ORC类似的列式存储格式,源于Google的Dremel系统。
- 优点:自解析(元数据存储在文件footer),压缩比高,支持多种索引。其通用性更强,被Spark等众多大数据组件广泛支持。
- 建表语句:
STORED AS PARQUET
三、存储格式对比与选型建议
| 格式 |
存储方式 |
压缩比 |
查询速度 |
通用性 |
典型应用场景 |
| TextFile |
行存储 |
低 |
慢 |
高 |
ODS层原始数据加载 |
| SequenceFile |
行存储 |
低 |
一般 |
中(Hadoop生态) |
较少使用 |
| RCFile |
行列混合 |
高 |
快 |
低(Hive为主) |
旧系统升级过渡 |
| ORC |
列存储 |
非常高 |
非常快 |
高(Hive生态最优) |
Hive数仓核心表 |
| Parquet |
列存储 |
高 |
快 |
非常高(跨组件) |
Spark计算、Impala共享 |
总结与选型策略:
- Hive数仓内部:优先选择 ORC + SNAPPY 格式,在存储空间和查询性能上取得最佳平衡。
- 跨组件数据共享:如果数据需要被Spark、Impala、Presto等多种引擎高频访问,建议使用 Parquet + SNAPPY 格式。
- 数据分层应用:
- ODS/STG贴源层:可采用 TextFile(便于直接加载日志等文本数据)或 ORC (ZLIB)(高压缩存储)。
- DW/ADS明细层与汇总层:强烈推荐 ORC (SNAPPY) 或 Parquet (SNAPPY)。
为什么Hive默认是TextFile?因为原始数据(如日志、CSV)多为文本格式,TextFile表可以最直接地加载这些数据,然后通过INSERT转换到ORC/Parquet格式表中,这是一种常见的数据分层处理模式。

四、数据共享:跨集群拷贝(DistCP)
当需要在不同Hadoop集群间迁移或共享数据时,可使用distcp(分布式拷贝)工具。
原理:distcp本质上是一个只有Map阶段的MR任务。它将拷贝的文件列表分发给多个Map任务并行执行,每个Map负责拷贝一部分数据。
关键参数:
-m:控制Map任务数量。每个Map默认处理至少256MB数据。需根据数据总量和集群资源调整,任务数过多可能占满集群资源。-update:增量拷贝,只同步源和目标差异的部分。-delete:删除目标路径中存在而源路径中不存在的文件。
示例命令:
# 基本拷贝,将集群A的 /source/data 拷贝到集群B的 /target/data
hadoop distcp hdfs://clusterA:8020/source/data hdfs://clusterB:8020/target/data
# 指定Map任务数为50,进行增量更新
hadoop distcp -m 50 -update hdfs://clusterA:8020/source/data hdfs://clusterB:8020/target/data
注意事项:
- 确保两个集群间的网络互通且带宽充足。
- 对于极大规模数据迁移,需分批次进行并监控网络和集群负载。
- 除了
distcp,也可通过构建跨集群Hive视图的方式实现数据逻辑共享,而无需物理拷贝。
|  发表于 2025-12-11 03:26:04
|
查看: 200|
回复: 0
发表于 2025-12-11 03:26:04
|
查看: 200|
回复: 0
