这不最近把 Kubernetes 集群给搭建起来了嘛,就想既然费了这么大劲,如果只用来跑 Flink 任务,是不是有点浪费。
于是琢磨着,是不是也可以把一部分 Spark 任务迁移过来试试水,毕竟 Spark 也明确支持在 K8s 上运行。顺便也能对比一下,同为 on K8s,Flink 和 Spark 的实际表现,看看哪个更给力一些。
先说结论:Spark on K8s 跑起来最大的坑,在于制作一个符合你当前环境需求的镜像。 当然,这也不代表其他地方就没坑了。我前前后后折腾了至少3台云服务器,才最终把这个难缠的镜像给搞定。
(PS:本次测试环境为 Spark 3.2 + Kubernetes 1.21)
0. 官方文档的“陷阱”
自 Spark 2.3 版本开始,官方就开始支持在 K8s 上运行了,所以我用的 3.2 版本肯定没问题。
但从官网说明来看,它和 Flink 的做法不太一样:Flink 有很多现成的 Docker 镜像,直接下载就能用。而 Spark 没有,它需要你基于一个基础 JDK 镜像,再结合你当前使用的 Spark 版本,去构建一个符合自己运行环境的目标镜像。
官方提供了一个构建脚本示例:
./bin/docker-image-tool.sh -r <repo> -t my-tag build
./bin/docker-image-tool.sh -r <repo> -t my-tag push

虽然官网给了模板配置,也提供了一个基础镜像,但我怀疑这是官方跟我们开的一个“小玩笑”。默认的Dockerfile配置是这样的:
ARG java_image_tag=11-jre-slim

它基于 openjdk:11-jre-slim 这个镜像,但我的 Spark 开发环境是基于 JDK 8 的。关键我去 Docker Hub 一查,官方压根就没提供这个 11-jre-slim 标签的镜像,硬拉肯定失败。
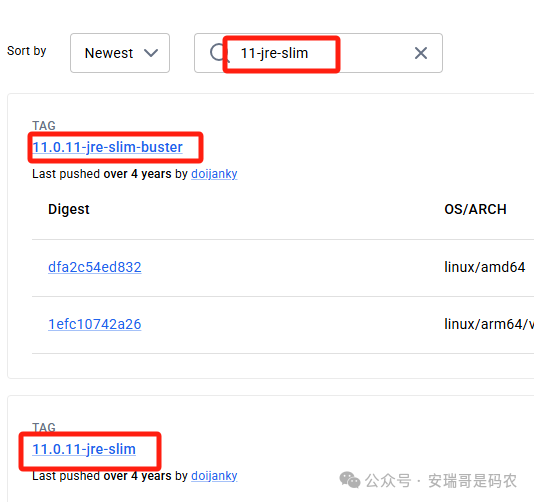
你说气不气人?所以不管出于兼容性还是实际可用性考虑,咱们都得自己换基础镜像。然而,就是这个换镜像的动作,开启了本次的“踩坑”之旅。
1. 事故一:镜像基础不对,文件缺失
既然官方默认的镜像不能用,那就只能去 Docker Hub 找一个既存在又符合我 Spark 开发环境(JDK8)的基础镜像。
我找来找去,找到了这个:8u342-jre。
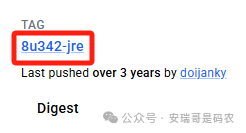
但因为网络问题,我部署 K8s 的物理机节点根本下载不下来这个基础镜像。没办法,换了一台云服务器才下载成功。
然后,我把这个基础镜像传到 K8s 节点上,准备用它来构建 Spark 镜像。但构建过程很快就失败了:
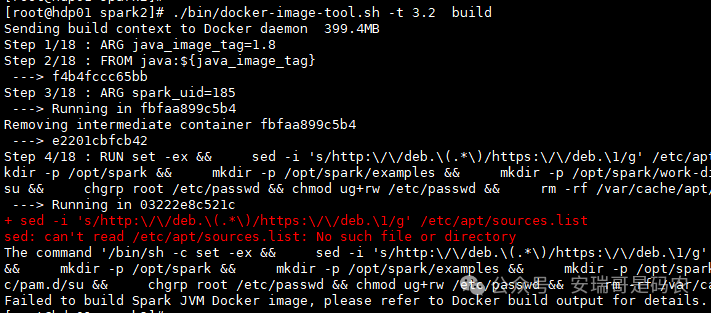
错误信息大概意思是:选择的镜像不对,Dockerfile 中期望存在的某些文件(比如 /etc/apt/sources.list)在基础镜像里没有。得,这个镜像不能用,继续换。
2. 事故二:网络问题,依赖下载失败
继续寻找,我又找到了一个看起来更合适的:8u342-jre-slim。
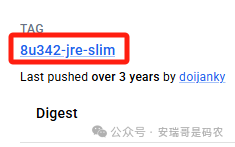
这次,上面那个文件缺失的问题没有了。但是,新的问题又来了——网络问题。在利用这个基础镜像构建 Spark 镜像的过程中,需要下载一些系统依赖包,结果连接超时。
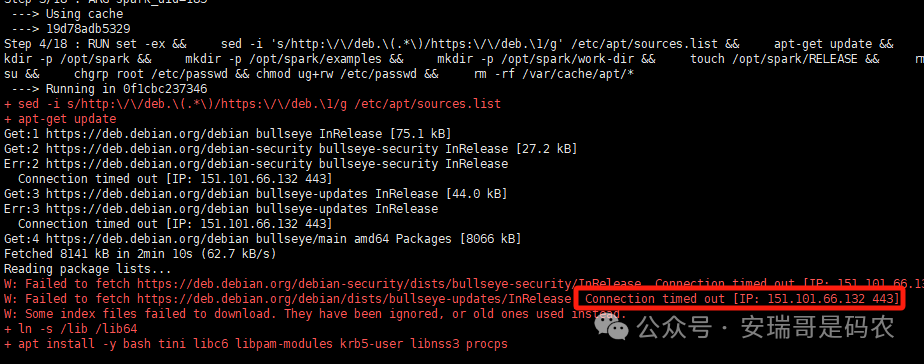
你猜我怎么解决的?对,我把构建镜像的任务,从 K8s 节点(物理机)迁移到了一台网络通畅的云服务器上。
但这可不是简单地换个地方执行命令。你需要把整个 Spark 的安装目录拷贝到那台云服务器上,因为构建脚本需要读取 Spark 的 jars、bin 等文件。
终于,在云服务器上,Spark 镜像可以顺利构建了:
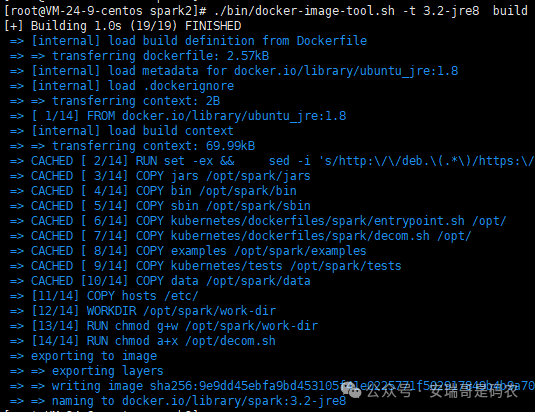
构建完成后,镜像列表里可以看到它:

你以为这就结束了吗?很抱歉,新一轮的“噩梦”才刚刚开始。
3. 事故三:Java 路径不对,启动报错
既然 Spark 的运行镜像做好了,接下来就该美滋滋地跑个 Demo 了对不对?
来,根据官网示例,我们这样提交一个 Spark Pi 任务:
./bin/spark-submit \
--master k8s://https://192.168.xxx.xx:6443 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=apache/spark:3.2-scala_2.12-jre8 \
local:///opt/spark/examples/jars/spark-examples_2.12-3.2.0.jar
任务确实能提交上去,但 Pod 很快进入了 Error 状态:

查看 Pod 日志,发现了问题:

日志显示 bad array subscript,这通常是因为 Spark 程序在启动时,会优先去 /usr/java/latest/bin 这个目录下寻找 Java 命令,但我们构建的镜像里,根本没有这个目录。
为了验证,我特意进入失败的容器内部查看:
ls /usr/java/latest/bin/java
ls /usr/java

果然,目录不存在。但容器里其实是有 Java 的,路径在别处:
which java

看到路径是 /usr/local/openjdk-8/bin/java。那怎么办?难道又换基础镜像吗?我替你试过了,没用!
这里的解决方案是:修改 Spark 的 Dockerfile,在构建时创建所需的目录,并将实际的 Java 可执行文件链接过去。 具体来说,就是在 Dockerfile 里加上这几行:
mkdir -p /usr/java/latest/bin &&
ln -sv /usr/local/openjdk-8/bin/java /usr/java/latest/bin/java &&
java -version

它没有这个目录?我们建一个。它没有这个文件?我们创建一个软链接过去。这样一来,问题就解决了。
4. 事故四:服务账号权限不足
这回,任务提交后,Driver 和 Executor Pod 都能成功启动了。但是,好景不长,很快又出现了新的错误:

查看日志,发现是 Kubernetes API 权限问题:
Caused by: io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: GET at: https://kubernetes.default.svc/api/v1/namespaces/default/pods/spark-pi-xxx-driver. Message: Forbidden!Configured service account doesn‘t have access. Service account may have been revoked. pods “spark-pi-xxx-driver” is forbidden: User “system:serviceaccount:default:default” cannot get resource “pods” in API group ““ in the namespace “default”
好家伙,这个问题我熟!之前玩 Flink on K8s 时就遇到过一模一样的问题。解决办法也类似,需要为 Spark 任务创建一个专属的 ServiceAccount 并绑定权限。
我们照猫画虎,执行以下命令:
# 创建namespace
kubectl create ns spark
# 创建serviceaccount
kubectl create serviceaccount spark-account -n spark
# 用户授权 (这里授予了 edit 角色,生产环境请根据需要细化权限)
kubectl create clusterrolebinding spark-role-binding-spark --clusterrole=edit --serviceaccount=spark:spark-account
然后,修改 Spark 任务提交命令,指定使用我们创建的 namespace 和 serviceaccount:
./bin/spark-submit \
--master k8s://https://192.168.xxxx.xx:6443 \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=apache/spark:3.2-scala_2.12-jre8 \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-account \
local:///opt/spark/examples/jars/spark-examples_2.12-3.2.0.jar
这样,权限问题就解决了。
5. 事故五:Hostname 解析失败
再次提交任务,没跑一会儿,又双叒出错了!这次的报错是:
java.lang.IllegalArgumentException: java.net.UnknownHostException: hdp01.xxx.xx
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:466)
这次是主机名(hostname)解析问题。这个问题在裸机部署时可能不起眼,但在 K8s 的 Pod 里,常规的修改 /etc/hosts 方法往往行不通。
瞬间感觉脑瓜子嗡嗡的,真是防不胜防。我试过在构建镜像时修改 hosts 文件,没用;也试过一些AI给的偏方,在提交命令里加参数,也没用。
此时此刻,我真想放弃,要知道 Flink on K8s 可没这么多破事儿。生气归生气,问题还得解决。你猜最后怎么搞定的?
我直接把提交 Spark 任务的那台机器上,Hadoop 配置文件(如 core-site.xml 等)里面,所有涉及到这个无法解析的 hostname(hdp01.xxx.xx)的地方,全部替换成了对应的 IP 地址。
然后,任务就正常了!看吧,关键时刻,还得靠经验。
最终,任务顺利提交到集群:

配置的 5 个 Executor 都争气地跑起来了。最后,计算 Pi 的任务也顺利完成:

至此,请允许我长舒一口气。
总结
同样是跑通一个简单的 Demo,一番折腾下来发现,Spark on K8s 的初始配置复杂度,确实比 Flink 要高不少。官方文档给出的信息,对于应对实际环境中的各种“坑”来说,有点不够看。
- 没有现成的、开箱即用的生产级镜像;
- 官方给的模板镜像参数可能不适用或镜像不存在;
- 自己找的基础镜像可能缺少必要的目录结构;
- 关键文件路径不对,还需要手动识别并修正;
- 镜像搞定后,还要处理 K8s 权限和网络解析等问题。
叠了这么多层“Buff”,新手很容易被劝退。要不是之前部署 Flink on K8s 积攒了一些经验,按我平时的性子,可能早就放弃了。
这次我们只是跑通了测试任务,至于在 K8s 上运行真实的生产级 Spark 任务表现如何,性能怎样,资源管理是否方便,那就是下一次要测试的话题了。如果你也在探索 Spark on K8s,希望这篇踩坑记录能帮你少走一些弯路。欢迎到 云栈社区 分享你的经验和遇到的问题。
 发表于 2026-2-6 06:26:07
|
查看: 230|
回复: 0
发表于 2026-2-6 06:26:07
|
查看: 230|
回复: 0
