2026年4月3日,AI工程师Kevin Gu在X平台发布的一篇技术文章,在24小时内获得了超过200万次浏览。文章的核心内容很简单:他们开源了一个名为 AutoAgent 的系统,这个系统能够自主优化AI Agent的性能,并在两个重要的基准测试中取得了超越所有人类手动调优对手的成绩。
这听起来像是科幻情节,但它确实是一个来自YC W25孵化公司ThirdLayer的、已在GitHub上开源的真实项目。
AutoAgent 解决了什么问题?—— Harness 工程的瓶颈
要理解AutoAgent的价值,首先得明白一个概念:Harness。
如果你用过不同的AI编程助手,可能会发现同一个底层模型在不同产品中的表现天差地别。这是因为模型只是引擎,真正决定其能力上限的是围绕它搭建的整套系统——即Harness。这包括了系统提示词、工具集、任务编排逻辑、错误重试机制以及上下文管理等。
Kevin Gu在文章中一针见血地指出:当前AI Agent发展的瓶颈往往不是模型本身,而是原始的、手工试错式的Harness工程。这就像拥有一台顶级F1引擎,却还在用手工敲打的方式制造整车底盘。
那么,优化Harness这件事,能否交给AI自己来完成? AutoAgent给出的答案是肯定的。
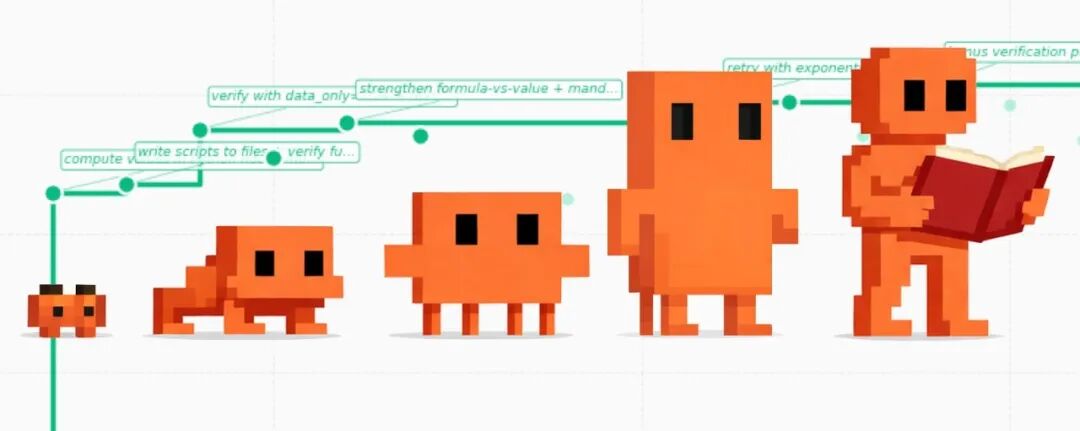
AutoAgent的像素风进化图:从基线到96.5%的自主优化之路
核心架构:双层Agent与永不停止的循环
AutoAgent的设计理念极其简洁:用一个AI来优化另一个AI。具体来说,它采用“Meta-Agent”(元智能体)和“Task-Agent”(任务智能体)分离的双层架构。
| 整个系统的核心文件只有四个: |
文件 |
作用 |
program.md |
给 Meta-Agent 的“宪法”,指明研究方向 |
agent.py |
Task-Agent 的完整 Harness 代码(单文件设计) |
Dockerfile.base |
提供 Docker 沙盒隔离环境 |
Harbor adapter |
连接标准化评测基准的适配器 |
其工作流程是一个被称为“The Loop”的自动化循环:
- 编辑:Meta-Agent 修改
agent.py 中的 Harness。
- 运行:在1000多个并行的Docker沙盒中执行任务。
- 测量:通过 Harbor 框架收集通过率和平均分。
- 分析:读取失败任务的完整推理轨迹。
- 决策:性能提升则保留改动,否则回滚。
- 重复:此过程永不停止,直至人为中断。
这个设计有几个关键洞察:
- 分工优于自改:一个Agent同时擅长执行和优化自身是困难的,专业化分工效果更好。
- 编程元智能体:工程师的角色从直接编写Harness,转变为设计Meta-Agent的优化目标和约束条件。
- 轨迹即黄金:仅提供分数结果无法有效改进,必须提供详细的失败推理轨迹。

AutoAgent 系统架构全景:Meta-Agent与Task-Agent的双层自优化框架
核心突破:Model Empathy(模型共情)
如果AutoAgent只是一个自动调参工具,那它的意义有限。但其揭示了一个更深层的发现:Model Empathy。
实验表明,当Meta-Agent和Task-Agent使用同一家族模型时,优化效果显著更好。例如,Claude Meta-Agent 优化 Claude Task-Agent 的表现,远优于它去优化 GPT Task-Agent。
原因在于,同源模型之间共享相似的“思维”模式,Meta-Agent能更本能地理解Task-Agent会在何处困惑、何种工具设计对它更有效。Kevin Gu指出,人类工程师习惯于将自己的直觉投射到AI系统上,但我们其实并不真正理解模型是如何“思考”的。
“我们用人类直觉来设计AI的工作框架,但AI的推理方式和我们根本不一样。就像你让一个只会游泳的人来设计飞机——他会本能地把空气动力学类比成水动力学,但空气不是水。”
这引发了一个值得深思的推论:在优化AI系统这件事上,AI可能比人类更擅长。
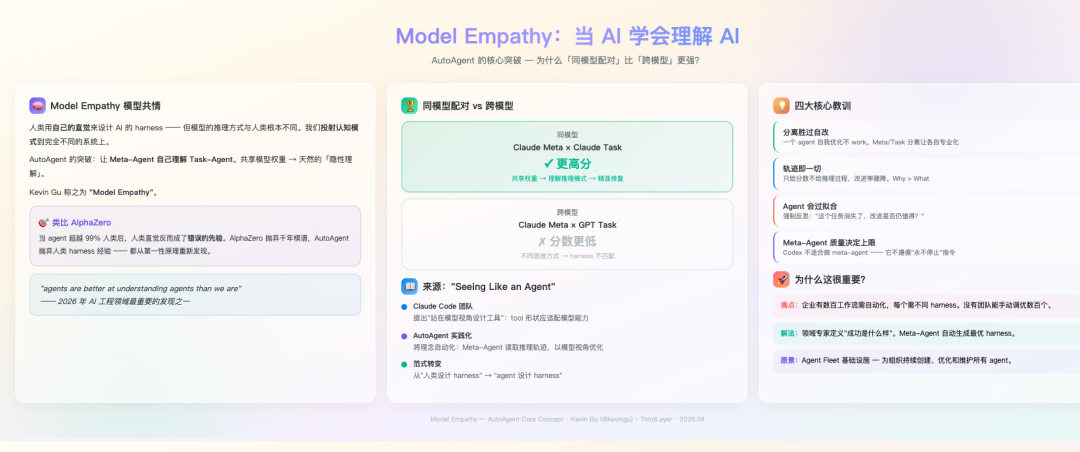
Model Empathy:为什么同模型配对在优化中表现更强?
涌现行为:AI自主发现的“最佳实践”
在24小时的自主迭代中,Meta-Agent发展出五种未被预设的、高度智能的行为:
- 抽样检测:对小改动,只跑单个任务验证,大幅节省算力。
- 强制验证循环:自建确定性检查器,并预留专门的“纠错回合”。
- 编写测试:引导Task-Agent为每个任务构建单元测试。
- 渐进展示:上下文过长时自动将内容写入文件,避免溢出。
- 编排逻辑:面对复杂任务时,自主创建子Agent并进行任务路由。
这些行为恰恰对应着人类软件工程中的最佳实践,但它们是由AI独立探索发现的。
用成绩说话:两个榜单,两个第一
理论再好,也需要数据支撑。AutoAgent在两个公认的基准测试中登顶:
| SpreadsheetBench(评估电子表格处理能力): |
排名 |
Agent |
得分 |
| 🥇 |
AutoAgent |
96.5% |
| 🥈 |
Tetra-Beta-2 |
94.2% |
| 🥉 |
Nobie Agent |
91.0% |
| TerminalBench (GPT-5类别)(评估命令行任务解决能力): |
排名 |
Agent |
得分 |
| 🥇 |
AutoAgent |
55.1% |
| 🥈 |
Codex CLI |
49.6% |
| 🥉 |
OpenHands |
43.8% |
最关键的一点是:榜单上所有其他Agent都是人类工程师手动调优的产物,而AutoAgent的成绩完全来自于零人工干预的自主优化。
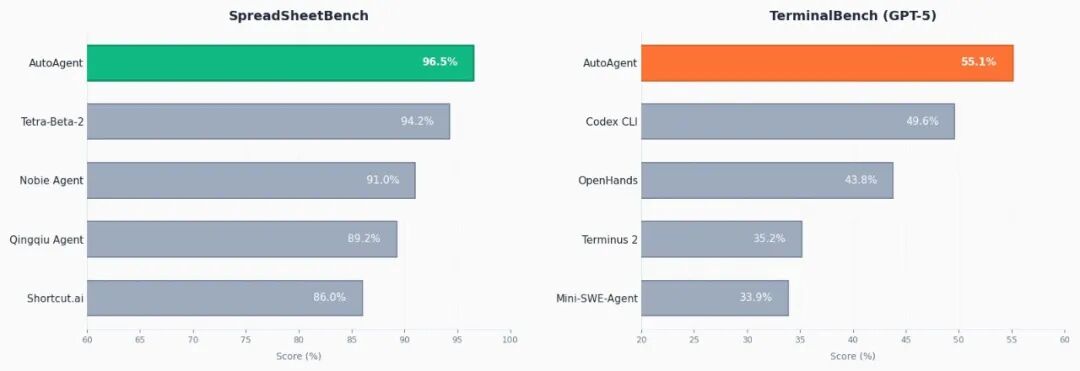
AutoAgent 在两大基准测试中均取得领先成绩
核心教训与局限
从AutoAgent的实验中,可以总结出四个对AI工程领域颇具启发的教训:
- 分离胜过自改:优化与执行需要不同的能力集。
- 轨迹即一切:没有详细的失败轨迹,改进效率断崖式下降。
- Agent也会过拟合:需设置约束(如“这个改进在任务消失后是否仍有价值?”)来防止刷分。
- Meta-Agent质量决定上限:并非所有模型都适合做Meta-Agent,它需要极强的自主性和执着性。
当然,这项技术也存在局限和风险:
- 安全风险:自主修改代码的系统需要严格的安全边界。
- 计算成本:大规模并行沙盒运行成本不菲。
- 评估依赖:输出质量极度依赖于评估标准的质量。
- 泛化性待验证:目前在结构化任务上成功,在更模糊的创造性任务上效果未知。
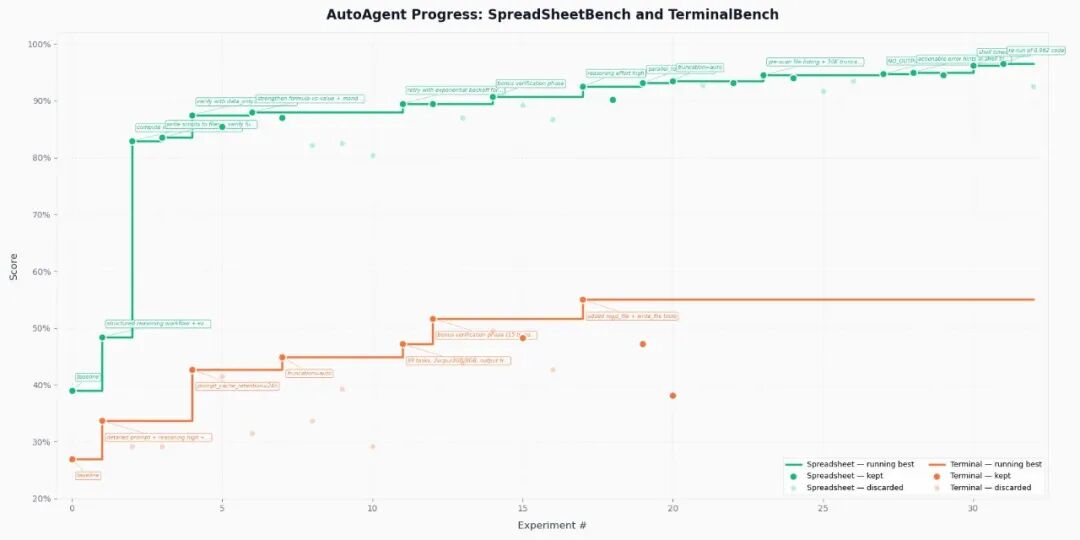
AutoAgent 在多次实验中的分数进步曲线,每一步跃升都对应一个自主发现的策略
开源与未来展望
AutoAgent项目已在GitHub上完全开源。其仓库极其精简,贯彻了“最小化人类干预”的设计哲学。
这个开源项目的影响在于,它降低了高级Agent优化的门槛。未来,领域专家可能只需要定义清楚“成功标准”,而无需深谙模型原理,就能通过AutoAgent获得一个高度优化的专属AI助手。
从技术演进的脉络看,AutoAgent标志着我们从 AutoML(自动机器学习)、Prompt优化 时代,迈入了 Agent自优化 的新阶段。自动化的层次正在从模型架构、提示词,上升到整个智能体系统。
对于AI工程师而言,这意味着核心技能可能需要转变:从手工调参转向设计元智能体的约束框架和高质量评估标准。未来的战场可能在于 Meta-Agent架构 和 Benchmark工程。
“描述规格,指向评测,让它自己爬。每个人都应该能做到这件事。” —— Kevin Gu
AutoAgent或许正预示着一个AI工程自动化的新起点。对整个人工智能领域的研究者和开发者来说,深入理解并参与这类自优化系统的探索,将是把握下一个技术浪潮的关键。对于更多技术细节、项目讨论或想获取开源代码,开发者们也可以在云栈社区这样的技术论坛进行深入交流。
AutoAgent 在 GitHub 上开源,项目结构极简,强调自主性
 发表于 2026-4-5 09:36:39
|
查看: 212|
回复: 0
发表于 2026-4-5 09:36:39
|
查看: 212|
回复: 0
