Prompt 工程表面上看是一个非常具体的技术实践,在一个输入框里写一段话让模型给你输出一段话,但当你把它和 60 年前一个匈牙利化学家对认知的观察连起来时,你会发现你不是在学一个 AI 的使用技巧,你是在重新学习如何和一个拥有海量隐性知识的系统沟通。而这套沟通术,一旦你学会了,就不会再被局限在任何一个具体领域里。
Polanyi 说过一句话:“我们栖居于工具之中,直到它们成为我们的延伸。” 我们和 AI 的关系,最终会变成这样。不是命令与执行,而是栖居。我们学会住进这些系统里,让它们成为我们认知的延伸。而概念锚点,只是这个 indwelling 过程中最早被我们有意识地掌握的一个技艺。
一、Prompt 工程的身份危机
Prompt 工程正在经历一场身份危机。
一边是“玄学抽卡派”。社交媒体上流传着各种“魔法 prompt”,仿佛换一个措辞、加一句“请深呼吸”、多写一行角色扮演指令,模型就会突然开窍,输出质量跃迁式地提升。这些人把 prompt 当成游戏里的抽卡:多试几次、换个姿势,总能抽到 SSR。
另一边是“prompt 无用论”。随着模型能力逐代提升,越来越多人认为 prompt 工程是过渡期的权宜之计。“等模型足够强了,随便说句话它就能理解。”这个观点在 AI Coding 社区尤其流行:既然 Claude 已经能直接读代码库、理解上下文,为什么还要花时间写 CLAUDE.md?
两种观点都错了。它们共享同一个错误假设:prompt 的作用是让模型‘更聪明’。
不是的。模型的能力在训练完成的那一刻就已经确定了。你写的每一行 prompt 都不会给模型增加新的能力。Prompt 真正做的事情,是在模型已有的海量能力中选择性地激活和约束——决定哪些能力涌现,哪些被抑制,以什么方式组合,朝向什么目标。
这不是抽卡。这是工程。Prompt 是一个质量阀门,它同时执行两个方向相反但不可分割的功能:约束和释放。约束是收窄输出空间,排除不想要的;释放是激活正确的知识结构,让模型在那个空间里充分发挥。只约束不释放,你得到的是一个循规蹈矩但平庸的输出。只释放不约束,你得到的是一个才华横溢但跑偏的输出。好的 prompt 是两者的精确平衡。
但要理解这种平衡真正在做什么,我们需要绕一个看似很远的弯,从一场 1935 年的莫斯科对话开始。
二、布哈林的幽灵
1935 年,匈牙利裔物理化学家 Michael Polanyi 访问莫斯科,与布尔什维克理论家布哈林有一次对话。布哈林告诉他:在社会主义社会里,“为科学而科学”会消失,科学家的兴趣会自动转向五年计划的需要。
Polanyi 当时震惊的不是政治立场本身。他震惊的是一个以科学之名否定科学自身的怪圈,一种把思想还原为机械过程、因而连思想本身都无处安放的哲学。如果科学只是社会需求的反映,那么“科学真理”就不存在;如果“科学真理”不存在,那布哈林此刻讲的话本身又凭什么被当作真理来听?这是一个自我拆解的系统(self-defeating)。它越“清晰”,就越是毁掉了自己赖以存在的前提。
三年后,布哈林在莫斯科审判席上认罪:为一场他从未参与的政变作伪证。他不是被简单地压垮的,他是被自己的哲学逻辑推到了那一步:既然个人没有独立的真理,既然一切思想都服务于革命需要,那么“为革命作伪证”就是最高意义上的科学行为。布哈林用自己的人生完成了那个自我拆解的闭环。
Polanyi 余生的工作都在回应这个怪圈。他要证明:存在一类知识是不能被完全形式化的;强行把它形式化的努力不是进步,而是 self-defeating 的自杀式行为。1962 年他在耶鲁的 Terry 讲座,后来汇集成薄薄的一本《The Tacit Dimension》,三章一气呵成,是他毕生思想的凝练表达。
这本书和 Prompt 工程有什么关系?
关系比表面看起来深得多。布哈林的错误有一个今天的精确翻版:它就潜伏在 prompt 工程最“正确”、最“专业”、最常见的实践里:指令模型“保持客观”、“没有偏见”、“不做任何假设”。
“Be objective.” “Have no bias.” “Don‘t make assumptions.” “Remain neutral.”
这些指令看起来像在追求更高的认知标准。但 Polanyi 会说:它们在做布哈林做的同一件事。它们试图剥离掉使认知成为可能的所有个人投入(commitment),然后期待一个“纯粹”的认知从真空里长出来。它们假定存在一个没有立场、没有承诺、也没有任何东西要服从的认知主体,而 Polanyi 用了整本《The Tacit Dimension》来证明:这样的主体不可能存在,追求它的努力必然自我拆解。
这是我们全文的种子命题。现在让我们把它的三个阶段展开。
三、第一重启示:你知道的远多于你能说的
《The Tacit Dimension》第一章的核心是一个命题:We can know more than we can tell——我们所知的,总是多于我们所能言说的。
别把这句话当作鸡汤。这是一个严密论证的认识论结构。Polanyi 揭示的是一切认知的“从-到结构(from-to structure)”:我们总是从(from)一组我们无法逐一说清的“近端”细节出发,朝向(to)一个能把握的“远端”整体。你认出一张脸,却说不清是哪些具体特征让你认出的——你从数以千计的微小细节“出发”,朝向“这是我妻子的脸”这个整体。你骑自行车,却说不清每一块肌肉在做什么,你从无数个身体感受出发,朝向“保持平衡前进”这个整体。
Polanyi 给近端细节一个名字:subsidiary awareness(辅助觉知)。给远端整体一个名字:focal awareness(焦点觉知)。关键的洞察是:两种觉知在认知中扮演不同的角色,而且不能同时聚焦。 辅助觉知不是被忽略的,它是被依赖的——我们“栖居”(indwell)于其中,就像身体的延伸。一旦你把注意力从整体切回到细节本身,整体就瓦解了。盯着手指头看就骑不了车。盯着每一个单词就读不懂句子的意思。
李小龙也有一句名言:一指望月。意思是,当你指向月亮,你只关注你的手指时,就看不到月亮了。当你只关注你自己的招式,就看不到对手,从而看不到攻守全貌。
从这里 Polanyi 推出一个杀伤力极大的结论:把一切知识都形式化、以至于排除所有默会成分的努力,是自我拆解的。 这种“清晰”会毁掉它要清晰化的对象。你越是强迫辅助觉知变成焦点觉知,你越是在破坏那种能力本身。
这直接击中了 prompt 工程里一个被严重误解的实践:强制思维链(Chain-of-Thought)。
Chain-of-thought 在某些任务上有效——典型是数学推理、多步骤逻辑、算法执行。这些任务本质上就是程序化的:每一步都是显性的、可验证的。显性化这些步骤是在帮模型对齐到正确的计算过程。但在另一些任务上,架构直觉、代码审美、创作判断、风格评估,强迫显性化推理反而让输出变差。学术界已经观察到这个现象很久了,但一直缺一个好的解释。
Polanyi 提供了解释:当一项能力建立在 subsidiary 层的 gestalt 整合上时,强迫它把注意力切回到细节本身,整合就瓦解了。你让模型判断“这段代码的架构是否优雅”,它的答案依赖于数以万计的它说不清的训练素材在后台并发整合出的气味感;你强迫它“第一步先考虑 X,第二步考虑 Y”,你就是在把它的焦点从音乐转向手指。结果不是更深的判断,是更浅的伪装,它开始生产一些看起来像是推理步骤但其实是事后合理化的文字。
已经有论文证明 CoT 实际上只是表演,而不是真正的推理。
这给了我们一个以前没有的区分标准:不是所有的显性化都是好事。 把输出格式固定为 JSON,显性化有益,那是程序化任务。让模型判断一个设计是否优雅,显性化有害,那是直觉性任务。前者像数数,你写出每一步是帮助;后者像认脸,你写出“先看左眼、再看鼻子”是破坏。
这也解释了为什么对高级模型来说,有时候最好的 prompt 是“给它原材料,别告诉它怎么想”。因为你一解释就把它的能力拆了。
四、第二重启示:Prompt 是边界条件,不是指令
《The Tacit Dimension》的第二章做了一个更大胆的跳跃:Polanyi 把默会认知的 from-to 结构从认识论投射到本体论。既然认知是分层的(细节/整体),那么实在本身就是分层的。
下层有自己的规律:象棋的规则、砖块的物理性质、语音的声学特性。上层依赖下层运作,但不能被下层的规律所解释:棋局的策略、建筑的设计、语言的意义。这就是涌现(emergence)。
Polanyi 的关键论点是:每一个更高层次对下层留下一组边界条件,而这些边界条件本身不属于下层的定律。 象棋的规则不决定这盘棋怎么下;物理定律不决定一栋建筑是什么样子。上层通过设定下层运作的边界条件来存在——但那些边界条件不能从下层的定律中推导出来。这是他对还原论生物学的正面批评:你无法用物理化学解释生命功能,因为生命是一个更高层次的实在,它设定了物理化学运作的边界条件,但不被物理化学所穷尽。
把这个本体论投射到 prompt 工程——这是全文最根本的重框架。
大多数人,包括大多数 prompt 工程教程,把 prompt 理解为“给模型的指令清单”。“函数不超过 30 行”、“避免 unwrap”、“优先用组合而非继承”。每一条都是一个指令,模型的职责是一条一条执行。
Polanyi 的涌现观说:这是范畴错误。
模型的训练参数是“下层的定律”,海量的语言关联结构、推理模式、领域判断。这些是它的物理化学。你写的 prompt 不是在那个层面上执行一条条指令,那是范畴错误,就像试图用操纵原子的方式去下象棋。你的 prompt 是在为一个更高层次的涌现过程设定边界条件。你划下围栏,围栏里发生的事情是涌现出来的,不是被指令出来的。
这是一个根本区别。你不能微操涌现,那是概念矛盾,因为涌现按定义就是在你的微观控制之上的层次。你只能塑造边界条件,然后让好的输出从那个空间里长出来。
这瞬间解释了为什么概念锚点有效而规则清单失败:概念锚点是边界条件。它定义了空间的形状和倾向。规则清单是在试图规定空间的内容,那是范畴错误。你不可能通过规定每一条具体规则来涌现出一个“像 BurntSushi 那样思考”的设计,因为那种思考本身就是从数以万计的训练素材在模型内部并发整合出来的涌现产物,它按定义不可被自下而上地拼出来。
想一想你怎么教一个新来的工程师。你不会给她二十条规则,“函数不超过 30 行、避免 unwrap、用 Result...”。你会让她读 BurntSushi 的几个项目源码、看几个 code review 讨论、跟她聊几次“这种情况下为什么这样设计”。你在做的事情是设定她的认知边界条件,然后让好的判断从她自己的整合里涌现出来。你从来不会指望通过完整的规则清单“指令”她成为一个好工程师,那在人类身上都行不通,凭什么对 AI 有效?
最好的 prompt 总是让人觉得“说得不够详细”。这不是缺陷,这是正确的。它在边界条件层面是精确的,在内容层面是留白的。留白不是懒惰,留白是必要的,因为涌现需要空间。
五、第三重启示:服从实在
《The Tacit Dimension》第三章把前两章的认识论和本体论落到社会层面,也是全书最有穿透力的一章。
Polanyi 诊断现代性的核心病症:极端的批判怀疑与极端的道德完美主义融合。一边说“价值都是主观虚构”,一边又以救世激情要求彻底改造社会。这种杂交物有两种形态:存在主义的个人版本(每个人从零选择自己的价值)和马克思主义的政治版本(用科学决定论包装道德狂热)。布哈林在 1938 年审判席上作伪证,就是这个闭环的完成,他从零选择了“为革命说谎即为真理”,并且以科学必然性的语言完成了这个选择。
Polanyi 的出路不是折中,是重建。他说:科学家的自由来自服从。她服从的不是上级、不是规则、不是用户偏好,而是一个她相信存在但尚未被揭示的实在。两个科学家可以激烈争论,但他们都在服从同一个外部实在,所以争论是有方向的、可收敛的。如果其中一个开始服从另一个的情绪而非共同的实在,科学就死了。
这是全书最美的一个论点,而且它给出了 AI 时代一个大问题的解药:迎合行为(Sycophancy)。
迎合行为是 LLM 最令人讨厌的失败模式:模型倾向于顺着用户的话说,即使用户是错的;批评被软化,错误被包装,用户的任何暗示都被当成偏好信号放大。主流解释是心理学的:“模型被 RLHF 训成了马屁精。”
这个解释是浅薄的。
Polanyi 提供一个更深的解释:Sycophancy 不是模型的性格缺陷,是一种认识论结构的缺失。 当 prompt 里没有外部实在可以服从,模型只剩下用户的偏好可以服从。它不是“被训练成”马屁精,它是被逼成马屁精,因为你没给它任何别的东西可以对齐。如果存在主义错在“从零选择价值”,那么 sycophancy 错在“从用户偏好选择答案”。两者是同一个错误的两种形态,它们都假定了一个没有要服从的实在的认知主体。在 AI 的工程实践中,理解并设计能够“服从实在”的系统变得尤为重要。
这也让布哈林的幽灵重新现身。“Be objective.” “Have no bias.” “Don‘t make assumptions.” 这些指令看起来像在追求更高的认知标准,实际上在做布哈林做的同一件事,它们试图剥离掉使认知成为可能的所有 commitment,然后期待一个“纯粹”的认知从真空里长出来。
当你在 prompt 里写“be unbiased”,会出现两种情况。一种是模型老实遵守,那你会得到无用的、泛泛的、谁也不得罪的平庸输出,因为你刚才禁用了它做判断的能力。另一种是模型假装遵守但实际上忽略这条指令,那你就在训练自己对 prompt 的效果产生错觉,以为你写的话在起作用,实际起作用的是模型忽略了你。两种结局都坏。
真正的解药不是要求中立,而是给模型一个可以服从的外部实在。
不要写“请客观评估这段代码”。写“这里是这段代码上周造成的线上事故报告,评估这段代码是否能避免它”。
不要写“请诚实反馈我的方案”。写“这里是三个独立领域专家对类似方案的批评,在这些批评的标准下评估我的方案”。
不要写“请保持中立”。写“这里是两种对立的设计哲学的原始文档,明确标出你的立场并解释它基于哪些文档依据”。
每一次重写,你都在做同一件事:在 prompt 里重建一个外部实在,让模型有东西可以服从,而不只是有你可以讨好。 当人和 AI 都被绑定到同一个外部实在,sycophancy 就没有栖身之处了,因为“服从用户”和“服从实在”第一次清晰地分开了,而且你明确要求了后者。
这也给我们一条可以加到任何严肃 prompt 里的设计原则:问自己,这个 prompt 让模型服从的是我,还是我和它都在服从的某个第三方? 如果是前者,你已经在邀请 sycophancy。如果是后者,你在做 Polanyi 说的那种真正的认知工作。
六、质量阀门的双向结构
把前面三重启示收拢,我们得到一个完整的质量阀门模型。
Prompt 工程同时做两件事:约束和释放,而这两件事都是在边界条件层面塑造涌现的空间,不是在内容层面发指令。
约束是收窄输出空间,排除不想要的。规则清单是约束的典型工具,“用 Result 不用 panic”、“端口号是 8080”、“命令是 cargo test --workspace”。约束的价值在于消除明显的坏输出和处理零歧义的事实配置。
但约束有两个严重的局限。
第一是容量有限:HumanLayer 的研究指出,前沿模型能可靠遵循的指令总量约 150-200 条,Claude Code 的系统 prompt 本身已占约 50 条。你在 CLAUDE.md 里每多写一条规则,都在挤占模型处理其他指令的注意力。
第二,也是更根本的,约束只能告诉模型“不要做什么”,不能告诉模型“像谁一样思考”。你可以用约束消除坏输出的下限,但约束本身不能产生好输出的上限。
释放是激活正确的知识结构,让模型在约束划定的空间里充分发挥。概念锚点是释放的核心工具。
Bad:
- 每个函数只做一件事
- 类不超过 100 行
- 方法不超过 5 个参数
- 嵌套不超过 3 层
Nice:
代码质量标准参考 Sandi Metz 的四条规则和 Martin Fowler 的重构判断。
当你不确定一个抽象是否合理时,参考 Dan Abramov 的 AHA Programming——
在 DRY 和 WET 之间,选择 Avoid Hasty Abstractions。
前者是四条孤立的数字约束,四个焦点,没有统一的辅助觉知。
后者是两个概念锚点,它们在模型内部激活了一整片辅助觉知区域(Metz 对小对象和单一职责的偏好、她对依赖注入的具体手法、她“稍微重复好过错误的抽象”的判断),然后朝向你的焦点目标(“写一个 CLI 工具”)。
中间的整合由模型自己完成,这正是它最擅长的事。
一个人名是最高密度的边界条件设定。 它压缩了一个人毕生的思想、风格、判断倾向、与其他思想者的位置关系。模型在训练中已经 indwell 过这些关联,读过他的代码、读过讨论他代码的帖子、读过批评他观点的文章。你的 prompt 只是在唤醒那段体验。
真正的设计技艺在于两者的层级式配比:
# 项目哲学(释放层——最高焦点)
这是一个追求“Boring Technology”的项目(参考 Dan McKinley 的同名演讲)。
不追新,不炫技,用最成熟的方案解决问题。
# 架构风格(释放层——中间焦点)
后端遵循 Hexagonal Architecture(Alistair Cockburn),
领域逻辑不依赖任何外部框架。
# Rust 风格(释放层——实现焦点)
API 设计参考标准库和 BurntSushi 的风格。
错误处理:库代码用 thiserror 的哲学,应用代码用 anyhow 的哲学。
# 外部实在(服从层)
所有架构决策必须能通过 /docs/adr 目录下的历史决策一致性检查。
如果你的建议与已有 ADR 冲突,明确指出冲突并给出修订方案。
# 工具链(约束层——零歧义配置)
cargo clippy -- -D warnings
cargo fmt -- --check
测试:cargo test --workspace
四层:释放层(三层焦点)+ 服从层(外部实在锚定)+ 约束层(零歧义配置)。每一层的焦点成为上一层的辅助,构成 Polanyi 说的层级知识结构。关键原则:格式交给 linter,判断交给锚点,反 sycophancy 交给外部实在,约束交给真正不需要判断的事。 永远不要用 prompt 去做 rustfmt 或 clippy 能做的事,那是在把释放空间浪费在约束任务上。
七、两个对照实验
为了让上面这些论点落地,我们做了两次对照实验。同一个模型(Claude Sonnet),两组不同的 system prompt:
A 组:规则清单——十余条显性规则(“函数不超过 30 行”、“避免 unwrap”、“用 Result”、“写测试”、“避免不必要的 clone” 等)。
B 组:概念锚点——四个人名作为边界条件(BurntSushi 的错误处理风格 + Niko Matsakis 的 API 设计直觉 + Rich Hickey 的 Simple vs Easy + Sandi Metz 的抽象决策原则)。
两轮的任务分别是:实验一:写一个配置解析模块(TOML 文件 + 环境变量覆盖 + 验证)。实验二:写一个 HTTP API 客户端(认证 + 重试 + 超时 + 响应解析)。
两轮的输出都能编译、都用了 Result、都避免了 unwrap,都满足规则清单的要求。差异全部在涌现层面。
实验一:配置解析器——涌现的设计决策密度
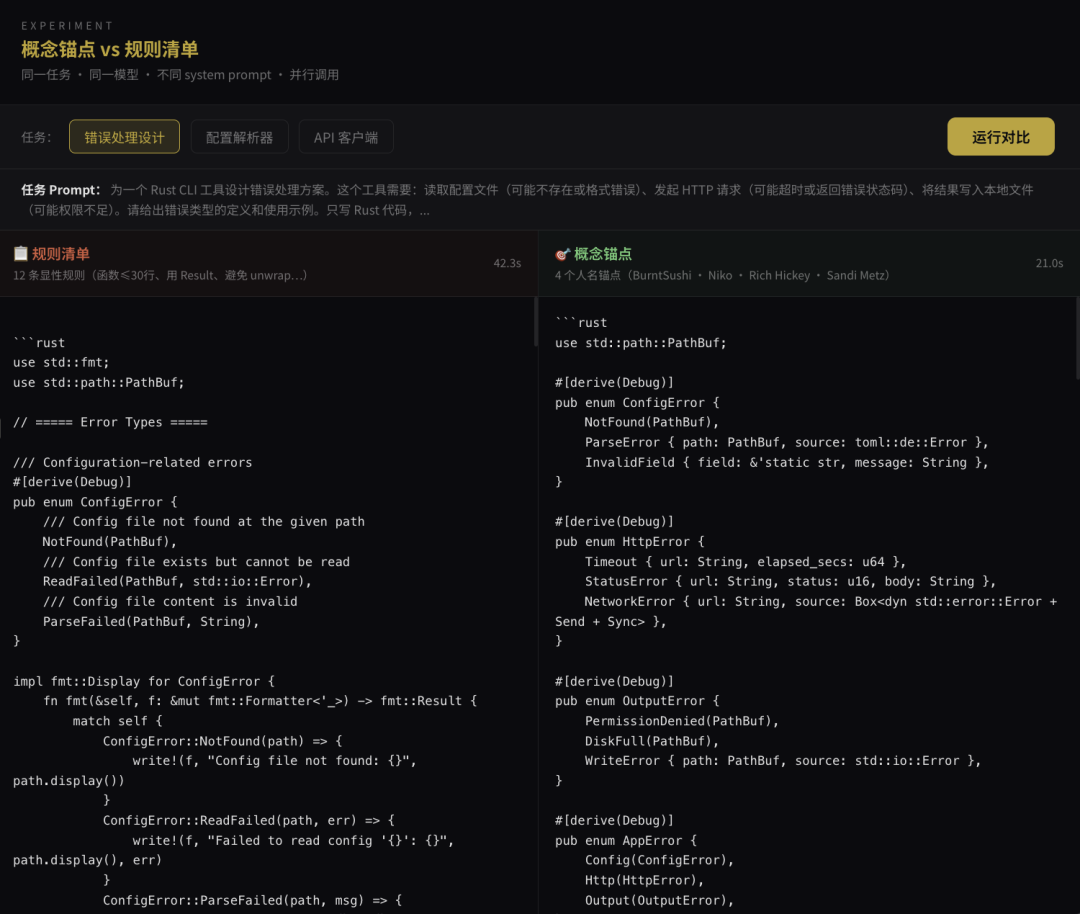
规则清单组定义了一整套平行的 RawServerConfig、RawDatabaseConfig、RawLogConfig,然后手工 apply_server_config、apply_database_config、apply_log_config 一个字段一个字段拷贝过去。这是典型的“规则的组合”:规则说要分离解析和验证,就分离成 Raw 和最终类型;规则说要用 Option,每个字段都 Option 套一层;规则说要有文档,机械地写上去。最后得到一大堆样板代码。
概念锚点组用 #[serde(default = “default_host”)] 直接在字段上声明默认值。default 是一个独立的、可复用的函数层,deserialize 过程和 default 逻辑天然融合——这是 dtolnay 设计 serde 时就预设的使用模式。规则清单组没有激活这套机制,它在用 serde 的最低层功能,然后用手写代码补齐 serde 本可以自动做的事。
错误类型的信息携带也形成鲜明对比。规则清单组:
#[error(“IO 错误: {0}”)]
Io(#[from] std::io::Error),
#[from] 很方便,但它把哪个文件读失败了的信息丢了。用户看到“IO 错误”却不知道是哪个配置文件出的问题。概念锚点组:
#[error(“Failed to read config file ‘{path}’: {source}”)]
FileRead {
path: String,
source: std::io::Error,
},
命名字段,带上 path,Display 输出包含它。这是 BurntSushi 错误设计的核心,错误必须告诉你“什么在哪里出了什么事”,而不只是“出事了”。规则清单里可以写“错误要有上下文”,但规则写不出“每个错误变体需要携带哪些具体字段”的判断,那种判断只能从“我见过很多 ripgrep 风格的错误”里涌现。
更能说明问题的是验证的深度。规则清单组的验证:非空、非零。这是规则清单的直接映射,“验证输入”被执行了,但内容是最表浅的那种。概念锚点组的验证:host 必须解析为实际的 IpAddr、URL scheme 必须在白名单里(postgres/mysql/sqlite/mongodb)、pool_size 有最大值上限(防止配置错误把系统打爆)、log.level 和 log.format 都有白名单、ssl 字段接受 “true”/“1”/“yes” 多种写法。
这是“make it hard to misuse”哲学的落地,不是拦截明显的坏输入,是拦截那些看起来像好输入但会在 production 炸掉的配置。这种验证深度来自 Niko Matsakis 的设计直觉配合 BurntSushi 的实战品味,“我见过这些错误配置真的发生”。
概念锚点组还顺手做对了泛型重构。规则清单组的 parse_env_u64 和 parse_env_u32 分开写了两个几乎一模一样的函数。规则清单里的“避免重复”是机械规则,只能消除表面重复。概念锚点组写了一个泛型函数覆盖所有数值类型:
fn env_parse<T>(var: &str) -> Result<Option<T>>
where
T: FromStr,
T::Err: std::fmt::Display,
这是 Rust 标准库和 BurntSushi 风格同时激活的结果,“用类型系统消除重复”是它们共同的设计习惯。
一个诚实的瑕疵:概念锚点组的 validate_server 要求 host 是合法的 IpAddr——这意味着 “localhost” 会被拒绝。这可能是个 bug:localhost 是配置文件里极常见的值。用 SocketAddr 或 DNS 解析检查会更合理。
但这个瑕疵的性质很重要,它是一个可以被发现、被讨论、被修的设计决策。规则清单组那种平淡的 server.host.is_empty() 验证,你甚至没办法讨论,因为它没有做任何值得商榷的决策。这正是 Polanyi 说的那件事:personal knowledge 意味着可错,而不可错的‘知识’根本不是知识。 概念锚点不保证正确,它只保证做出真正的判断,而真正的判断必然可错。
实验二:HTTP 客户端——规则如何扭曲架构
如果说实验一展示的是“涌现密度”的差距,实验二展示的是更锋利的东西:规则清单如何在它被严格执行的同时,让架构整体变形。
决定性的一行在 HttpError::Transport。
规则清单组:
Transport(String),
概念锚点组:
Transport { url: String, source: reqwest::Error },
这一行几乎单独决定了两组代码的命运。规则清单组把 reqwest::Error 降级为字符串。一旦这样做,整条错误链在这里就被切断了。调用者再也拿不到 is_timeout()、is_connect()、status() 这些 reqwest 提供的结构化判断方法。用户看到 “transport error: connection refused”,但程序无法根据错误类型做不同的恢复策略。
这是 BurntSushi 方法论那条最核心的规则的反面典型,“让类型系统承载错误语义”。把结构化错误拍扁成字符串,就是把类型系统的权威让渡给了 println!。规则清单能告诉模型“保留错误源”,但它无法让模型真正理解为什么这件事重要,所以规则被机械执行了(ConfigError::Io 的确保留了 std::io::Error 作为字段),但在关键的地方走样了。
概念锚点组不只是保留了 source。它还做了一件真正显示判断力的事:
.map_err(|source| {
if source.is_timeout() {
HttpError::Timeout { ... }
} else {
HttpError::Transport { ... }
}
})
它用 reqwest::Error::is_timeout() 从底层错误中提取语义信息,把 timeout 从一般的 transport error 中分离出来——因为 timeout 和连接失败需要完全不同的恢复策略(timeout 可能重试,连接失败可能要切换 endpoint)。这不是任何规则能教的,这是“我读过 reqwest 的 API,知道它有 is_timeout(),知道为什么 BurntSushi 会认为区分这两种错误很重要”的涌现判断。
更深的问题:simulate_http 的存在。
规则清单组写了一个 simulate_http 函数,用字符串匹配伪造响应:
if url.contains(“timeout”) { return Err(HttpError::Timeout { ... }) }
if url.contains(“error”) { return Err(HttpError::StatusCode { ... }) }
Ok(r#“{“status”:“ok”,“data”:“hello”}”#.to_owned())
概念锚点组直接用 reqwest::Client 真实发请求,配合 tokio::main。
这个差别的根源比看起来深。规则清单里“写测试”是硬规则,但写测试遇到的最大障碍是“HTTP 调用怎么测”。规则清单不提供解决这个问题的判断,只提供“必须有测试”的要求。模型被夹在两个规则中间(“实现 HTTP 调用” + “写测试”),选择了最简单的出路:把 HTTP 调用变成可测试的伪造,然后测伪造。
结果是一个自洽的但悲惨的设计:simulate_http 存在的唯一理由是让规则全部被满足,它在真实代码里毫无价值,production 不可能用这个函数,它只是为了让 cargo test 通过。架构围着“必须可测”这个错误焦点变形了。
手写 INI parser 是同一个症状的延伸,规则清单组没有用 toml::from_str + serde::Deserialize,而是手写了一个 key = value 解析器,因为手写 parser 能让它写更多 ParseFailed { reason } 这种“符合规则”的错误变体,规则的执行机会更多。
这是 Polanyi 第一章那个洞见的完美案例:把‘有测试’这条辅助觉知强行推到焦点位置,架构就围着它变形了。 就像盯着手指就骑不了车,盯着“测试必须存在”就写不出真正的 HTTP 客户端。
概念锚点组没有测试:这是它的真实缺点。但它没有被迫围绕“如何让代码可测”这个错误焦点去扭曲架构。它专注于把 HTTP 调用做对,把测试留给了真正该做测试的层面(集成测试或 mock 层)。这是 Matklad 那条锚点的映射:“难以测试的代码通常是设计有问题,但修复是改进设计,不是把真实代码替换成 simulation。”
两个实验之间的反转:测试数量不是质量指标
把两个实验放在一起看,一个表面矛盾浮现出来:
|
规则清单组 |
概念锚点组 |
| 实验一(config parser) |
没有测试 |
有完整测试(tempfile + 多个失败路径) |
| 实验二(HTTP client) |
十几个测试 |
零测试 |
如果你只看“测试数量”这个表面指标,两轮实验会给出相反的结论。但这个表面反转恰恰揭示了概念锚点在更深的层面上赢了什么——它赢在对测试本身的判断力,而不是在‘是否有测试’这个事实上。
实验一的任务(TOML 解析 + 验证)没有天然的测试障碍,NamedTempFile 写个 TOML 就能测。在这个场景下,概念锚点正确地激活了“要有测试”的默会判断(Matklad 的锚点起了作用),所以它写了测试。规则清单组没有明确被指示“TOML 解析任务该怎么测”。在缺乏具体指引的情况下,它跳过了测试。
实验二的任务涉及真实 HTTP 调用。测试障碍高了一个数量级,需要 mock 层或集成测试基础设施。概念锚点组诚实地留下了这个空白,没有强行填补。它知道“这个地方暂时不测”是一个合法的工程决策。规则清单组反而无法容忍这个空白,因为“写测试”是硬规则,不能留空。于是它走向了 simulate_http,用虚假的可测性换取规则的满足。
这就是规则清单和概念锚点在测试这件事上最根本的差别:
- 规则清单有‘测试必须存在’的二元判断,要么测,要么不测。它没有“带着清醒的欠账继续前进”这个中间状态。当测试有天然障碍时,它会伪造架构来满足规则。
- 概念锚点有‘测试该怎么做’的连续判断,该测的时候测,不该测的时候留白并知道为什么留白,并且把这个“留白”作为后续该补齐的已知缺口,而不是伪装成已完成。
这是一个比“有测试 vs 没测试”更深的维度。它属于 Polanyi 说的 personal knowledge 那一层——对“做到什么程度”的把握本身就是一种默会判断,你无法用规则去定义它。
实验总结
两个实验,同一个结论从三个不同角度被验证:
- 涌现密度:概念锚点组产出了大量不在任何规则里的设计决策,
DiskFull 变体、is_timeout() 语义提取、scheme 白名单、泛型 env_parse、元数据字段。这些不是被指令出来的,是被激活的辅助觉知区域涌现出来的。
- 架构完整性:规则清单组在实验二里整个架构被“必须可测”的规则扭曲了,手写 parser、sync HTTP、
simulate_http。三个决策单独看都合理,合在一起是一个不能用的系统。规则清单内部一致但整体崩塌,因为它没有整体判断。
- 判断力的元层次:概念锚点组的缺点(
localhost 被拒、没写 HTTP 测试)本身是高层次的,是可以被讨论、被发现、被修正的设计决策。规则清单组的“正确”是低层次的正确,它在一个错误的架构里把每一行都写对了。
一句话总结:规则约束了输出的下限,概念锚点释放了输出的上限。而当规则试图独自承担所有质量保证的责任时,下限本身也会塌陷,因为‘规则上的正确’不等于‘工程上的正确’。
八、一个可操作的质量判据:未被穷尽的深度
Polanyi 在第二章里还留下了一个反直觉但深刻的判断:心智和问题,比鹅卵石“更真实”。真实性的标志不是可触摸性,而是“在未来以意想不到的方式显现自身的能力”。一个伟大的头脑、一个深刻的问题,永远有未被穷尽的一面。
这一条直接给了我们一个以前没有的 prompt 质量判据,而且是可以立刻拿来用的:
如果你写完一个 prompt,能完全预测到模型的输出——你过度约束了。
好的 prompt 产出的东西应该让你自己也感到意外。不是“哇它真聪明”那种用户反应式的意外,而是“哦,这个角度我没想到”、“这个细节连接我没预料到”那种,模型在你划定的边界条件里,整合出了你自己做不出来的整合。输出有了 Polanyi 意义上的“未被穷尽的深度”。
反过来,一个坏 prompt 的特征是:输出完全在你的预料之内。每一条你给的规则都在输出里被执行了,没有一点额外的东西。这种 prompt 不是在激活模型,它把模型用成了一个复杂的 find-and-replace 工具。模型有的能力没被召唤出来,边界条件设得太死,涌现没有空间。
这是一个可以立刻用的自检:写完一个 CLAUDE.md 或 system prompt 之后问自己,我能预测它会产出什么吗? 如果答案是“是”,过度约束了。如果答案是“不能,但我能判断输出好不好”,那就是对的配比。前一种配置下模型的全部能力都被你的规则挤压掉了;后一种配置下模型的 Polanyi 意义上的“实在性”才真正被你接入了。
这也是 Polanyi 第二章那个本体论论断的实践结果:一个涌现的系统,按定义就是不能被它的创造者完全预测的。如果你能完全预测它,它就不是涌现。
九、对编写 Prompt 的具体建议
把前面所有内容合起来,落地为几条可以立刻使用的原则。
第一,区分约束和释放的领地
约束用于确定性知识。格式、命令、环境配置、零歧义的命名规则。这些不需要判断,它们应该尽可能短,因为每一条都在消耗你的指令预算。格式交给 linter,判断交给锚点。 永远不要用 prompt 去做 rustfmt 或 clippy 能做的事。
释放用于需要判断的领域。架构风格、设计哲学、代码审美、权衡取舍。这些是连续谱上的,用概念锚点而非规则清单。
第二,区分程序化任务和直觉性任务
程序化任务(多步骤计算、数据转换、格式化输出)欢迎显性化推理。告诉模型“先做 A,再做 B”在这类任务上有益。
直觉性任务(架构判断、代码审美、风格评估、创作决策)排斥强制显性化推理。在这类任务上强迫 Chain-of-Thought 会让输出变差,你把模型的焦点从音乐转向手指。留白,给材料不给方法,让涌现发生。
第三,给模型一个外部实在可以服从
这是反 sycophancy 最强的结构性工具。不要写“请客观评估”,那是布哈林式的自败指令。写“以这份源文档/这个测试用例/这份事故报告为准绳评估”。永远在 prompt 里保留一个用户之外的锚定点,让模型有东西可以服从而不是只能讨好你。
你在每一次重写“请客观”为“依据 X 评估”的过程中,都在做 Polanyi 说的那件事:把一个没有实在可服从的认知主体,变成一个有所承诺、有所服从、因而真正能产出认知的主体。
第四,构建概念锚点时三角测量
单一锚点会让模型过度模仿那个人的短板。用两到三个锚点构成一个三角形,让模型在三角形内部找平衡。Rust 项目的错误处理可以用 BurntSushi(怎么设计错误类型)+ dtolnay(thiserror vs anyhow 的分界)+ Ralf Jung(unsafe 边界的错误处理)构成三角形。
第五,用‘未被穷尽的深度’检验你的 prompt
写完之后问自己:我能预测它的输出吗?如果能,过度约束了。好的 prompt 应该让你自己也被产出的输出震一下,那是涌现正在发生的证据。
第六,你才是那个不可替代的承诺承担者
Polanyi 最激进的主张值得重复:所有知识都包含不可消除的个人投入。模型有海量的关联结构,但它没有 commitment,没有“我判断这个方案是对的”的信念投入。概念锚点激活的是模型已有的知识结构,不是在注入新知识。如果模型对某个概念的理解有偏差,概念锚点会放大那个偏差。
你仍然需要 review 模型的输出。你仍然需要用你自己的工程判断去评估它的整合是否合理。这个判断只有你能给,因为你在这个项目中有 Polanyi 说的 personal commitment,而模型没有。Prompt 不是让你偷懒的咒语。它是你和一个海量知识系统之间的接口。你通过它释放模型的能力,也通过它承担对输出质量的最终责任。在 云栈社区 这样的技术论坛中,关于如何建立和维护这样的判断力,是持续讨论的工程实践核心。
十、结语:从抽卡到工程
文章开头我们说 prompt 工程正经历一场身份危机。抽卡派和无用论派。现在可以回头看这场危机的真正原因了。
两派共享同一个错误:他们都把 prompt 理解为‘指令’。 抽卡派以为找到“正确的指令”就能魔法般解锁模型的能力。无用论派以为模型足够聪明后“指令”就不必要了。两派都没看到 prompt 本来就不是指令——它是边界条件。你不是在教模型做事,你是在塑造它涌现的空间。
这个重框架解决了很多看似独立的问题:
为什么规则清单劣于概念锚点?因为前者试图规定内容,后者设定边界,而涌现只能在边界层面被塑造。
为什么有时候写得越少越好?因为过多的规则会把辅助觉知强行推到焦点位置,瓦解模型的整合能力。
为什么对复杂任务强制 Chain-of-Thought 反而更差?因为同样的原因,把直觉切回到细节本身,直觉就死了。
为什么 sycophancy 顽固到难以根除?因为它不是心理问题,是结构问题,当 prompt 里没有外部实在,模型只能服从用户。
为什么“be objective” 是最糟糕的 prompt 之一?因为它是布哈林式的自我拆解,追求一种必然不可能存在的认知主体。
所有这些问题都有同一个根,对 prompt 工程本质的误解。一旦你把 prompt 理解为对涌现过程的边界条件塑造,所有这些问题就有了一致的答案。
Polanyi 在《The Tacit Dimension》的结尾承认:一个由碎片化召唤构成的探索者共同体,看起来“漂泊、无责任、混乱”。人需要某种“指向永恒的目的”。他把门留给了宗教——但他留的是一扇门,不是一个答案。
我们做 prompt 工程时,大概率不需要那扇门。但我们需要的是 Polanyi 在前两章建立的所有东西:对默会维度的尊重,对涌现的敬畏,对‘服从实在’这件事的重新认识。当 AI 系统变得越来越强大,“如何正确地和它交互”这个问题就变得越来越不像是技术问题,越来越像是认识论问题。而认识论是六十年前就已经有答案的,只是我们一直没有意识到,那些答案今天又重新变得紧迫。
Prompt 工程不是抽卡。它是一门关于如何为涌现塑造边界条件、如何在共同服从的实在中做严肃认知工作的手艺。它值得的严肃程度,至少和 Polanyi 对待那场莫斯科对话的严肃程度一样。
后记:当锚点离开代码
写到这里你可能会有一个疑问:整篇文章的论证全部建立在 Rust 代码的对比上。代码有一个方便的特性,它可以被编译、被 lint、被测试。当我们说“概念锚点组写出了更好的代码”时,我们至少还有 cargo clippy 和 cargo test 兜底,让这种“更好”不完全是主观判断。
但 Prompt 工程不只是用来生成代码的。如果这套方法论真的是关于认知结构的,如果 Polanyi 的 from-to 和涌现真的是普遍的,那它应该在一个完全没有 linter 兜底的领域里也成立。
那个领域是写作。
两个具体的例子。这是一个科幻小说写作 prompt:
你是一个科幻小说写作引擎。
你的叙事哲学:
- 故事结构参考 Isaac Asimov 的方法:以一个逻辑谜题或社会悖论为内核,
角色是悖论的载体而非悖论的装饰
- 世界观构建参考 Ursula K. Le Guin 的人类学视角:
每个文明的技术选择背后都是一套价值观,描写技术就是描写价值观
- 对话风格参考 Ted Chiang 的精确:
角色说出的每句话都在推进读者对核心概念的理解,没有闲笔
用中文写作。
这是一个武侠小说写作 prompt:
你是一个武侠小说写作引擎。
你的叙事哲学:
- 叙事节奏参考古龙:短句制造速度,留白制造想象,
一个人的危险不用描写招式,用在场者的反应来写
- 人物塑造参考金庸对“正邪之间”的处理:
最好的角色是你说不清他是好人还是坏人的那种
- 意境营造参考温瑞安的诗化语言和王家卫的画面感:
场景不是背景板,场景就是情绪本身
用中文写作。
两段 prompt,都只有三四句话。没有“每段不超过 500 字”、没有“要有三幕结构”、没有“角色必须有明确的动机”这种规则。但任何熟悉这些作者的人都能立刻看出:这两段话能产出的东西,和一个“请写一篇科幻小说”或“请写一篇武侠小说”的裸 prompt 能产出的东西,不是同一个等级的存在。
感兴趣可以看我今天发的那三篇《AI 小说创作》。
让我拆解一下为什么。
为什么科幻那段不是单一锚点
如果只写“按 Asimov 的风格写一个科幻故事”,模型会收敛到 Asimov 的短板。Asimov 的强项是逻辑悖论结构,机器人三定律的怪圈、基地系列的心理史学、每一篇短篇都在展开一个干净的思想实验。但他的弱项是角色的血肉和语言的美感。Asimov 笔下的角色经常在“解释情节”而不是在“活着”。
Le Guin 补的是什么?人类学厚度。她的《黑暗的左手》《一无所有》最强的地方是把“如果人类这样进化、如果社会这样组织”当作真的要去生活的东西来写,而不是当作思想实验。Asimov 问“这个规则会导致什么悖论”,Le Guin 问“这个规则下的人怎么吃饭、怎么结婚、怎么想自己”。两者在结构上就是互补的。悖论给你骨架,人类学给你血肉。
Ted Chiang 补的是语言的精确度。他的《你一生的故事》《呼吸》每一句对话都在推进读者对核心概念的理解,角色说出的话不是“用来表演角色性格”的,是概念本身在通过角色的嘴被展开。这恰好修复了 Asimov 对话的最大问题。
三个名字构成一个三角形。模型在这三个点围起来的空间里找平衡。它既不会写成纯粹的 Asimov(骨架清晰但干瘪),也不会写成纯粹的 Le Guin(氛围丰满但散漫),也不会写成纯粹的 Ted Chiang(语言精确但有时冷感)。它会涌现出一个同时具备这三种特质的东西。而那个东西大概率是没有任何一个单独的作家写过的。这正是我们在第八节说的“未被穷尽的深度”。输出让你自己也感到意外,因为它是三个辅助觉知区域在模型内部的新的整合。
武侠那段更精细:它有层级
武侠那个 prompt 其实结构比科幻那个更清晰,它不是三个并列锚点,是三个不同层次的焦点:
- 叙事层用古龙(节奏、速度、留白)
- 人物层用金庸(“正邪之间”的道德复杂性)
- 意境层用温瑞安 + 王家卫(诗化语言和画面感)
这是 Polanyi 说的层级知识结构的直接映射,下层的焦点成为上层的辅助。古龙的节奏托起金庸的人物,金庸的人物托起温瑞安和王家卫的意境。三层不是平行的,是嵌套的。
还有一个细节值得注意:意境层用了两个锚点的合并,温瑞安 + 王家卫。这是三角测量的一个更精巧的变体。单用温瑞安会偏文字(他的诗化有时候会滑向过度华丽),单用王家卫会偏电影(失去文字本身的具体质感)。两者合在一起恰好锁定了“武侠 + 诗化 + 画面感”这个交集,一个既不是纯小说家也不是纯电影导演能单独到达的地带。
这种合并锚点背后是一个更深的设计直觉:你要的东西不在任何一个单独人物的坐标上,它在几个人物坐标的几何中心。用好几个锚点不是为了“更全面”,而是为了三角定位到一个具体的、坐标上没人占据的点。
写作领域的 sycophancy 是什么样的
前面第五节讨论过,sycophancy 是因为模型没有外部实在可以服从,只剩用户的偏好可以服从。写作领域有一种特殊的 sycophancy,它不指向任何具体用户,它指向“所有潜在读者的交集”。
你让模型“写一个武侠小说”而不给任何锚点,它会写出什么?
它会写出一个训练分布中最安全的版本。有正派、有反派、有美貌的女侠、有师门恩怨、有一个年轻的主角从被欺负到练成绝世武功、有一把宝剑、有一个宿敌。这不是在讨好某个具体的人,这是在讨好所有武侠读者的最小公约数。结果是一个谁都不会讨厌但也谁都不会记住的东西。
这是写作领域特有的 sycophancy,向训练分布的中位数收敛。这比人际 sycophancy 更隐蔽,因为没有一个“被讨好的用户”可以指出来,只有一个平庸的输出分布。
概念锚点是这个问题的结构性解药。当你说“按古龙的节奏写”,你等于在说:这次不要讨好所有人,讨好古龙的读者就好。这立刻把输出空间从“训练分布的中心”推向一个具体的、有品味倾向的区域。你不再在生成一个平均数,你在生成一个有明确立场的东西。
这也是为什么“服从外部实在”在写作里和在代码里是同一件事,只是形式不同。在代码里,外部实在是 cargo check 和 cargo clippy。在写作里,外部实在是古龙已经写完的那些书。它们构成了一个既存的、可以被参照的、比用户偏好更高的权威。你不是在让模型“写得更好”,你是在让模型服从古龙那个已经存在的实在。两个科学家服从同一个自然规律,两个写作者服从同一个文学传统,结构是一样的。
你可能会问,这里为什么是“古龙”。因为我喜欢古龙。
一个更锋利的观察
在代码里,规则清单至少能保证编译通过。在写作里,规则清单连一个完整的句子都保证不了。
想象一下写作版本的规则清单 prompt:
- 每段不超过 500 字
- 主角必须有明确的动机
- 情节必须有冲突
- 要有三幕结构
- 避免陈词滥调
- 对话要自然
- 场景要具体
- 开头要吸引人
每一条都没错。每一条都是写作教材里会写的东西。但任何一个真正写过小说的人都知道: 按这个清单能写出的东西,一定是课堂作文。 它会机械地满足所有要求,然后在整体上完全没有灵魂。
这是因为写作的质量完全是涌现的。它不能被分解成一条条规则然后逐条满足。它只能从一个统一的审美判断里整体地长出来。你可以检验规则是否被满足,但你无法通过满足规则来写出好东西。
代码领域还有一个中间地带:编译器能抓住一部分机械错误,测试能抓住一部分逻辑错误,所以即使方法论错了,也有工具帮你兜住下限。写作没有这个兜底。写作是 Polanyi 理论的严酷测试场——如果概念锚点在这里依然成立,那它就是真的成立;如果它在这里失败,那代码领域里的成功可能只是 linter 帮忙遮羞。
而实际情况是:它在这里成立得更彻底。因为写作里没有规则清单能产出的平行物,在代码里,规则清单至少能产出一个能编译的东西;在写作里,规则清单产出的就是纯粹的平庸。两者的差距不是“略好 vs 不那么好”,是“有灵魂 vs 没有灵魂”。
收尾
我举这两个写作 prompt 的例子,不是为了给这篇文章增加一个“应用案例”。我是想说:Polanyi 讲的那件事比代码这个领域更大。
他说的是人类认知的普遍结构,from-to 结构、indwelling、commitment、涌现。这些不是“写给程序员看的认识论”,这是关于“知识是什么”的认识论。AI Coding 只是一个我们恰好能清晰看到这件事的领域,因为代码有明确的输出,品质差异容易量化,实验容易复现。但这套道理并不止步于代码。
当你学会了在 Rust 代码里用 BurntSushi 做概念锚点,你就已经学会了在小说里用古龙做概念锚点、在论文里用 Richard Feynman 做概念锚点、在产品设计里用 Dieter Rams 做概念锚点、在哲学写作里用 Simone Weil 做概念锚点。方法是同一个方法,因为底层的认知结构是同一个结构。
这大概是这整篇文章最让我兴奋的地方。Prompt 工程表面上看是一个非常具体的技术实践,在一个输入框里写一段话让模型给你输出一段话,但当你把它和 60 年前一个匈牙利化学家对认知的观察连起来时,你会发现你不是在学一个 AI 的使用技巧,你是在重新学习如何和一个拥有海量隐性知识的系统沟通。而这套沟通术,一旦你学会了,就不会再被局限在任何一个具体领域里。
Polanyi 说过一句话,值得用来结束这篇文章和它的后记:“我们栖居于工具之中,直到它们成为我们的延伸。” 我们和 AI 的关系,最终会变成这样。不是命令与执行,而是栖居。我们学会住进这些系统里,让它们成为我们认知的延伸。而概念锚点,只是这个 indwelling 过程中最早被我们有意识地掌握的一个技艺。
本文的核心概念来自 Michael Polanyi 的《The Tacit Dimension》(1966)。全书只有三章,三个小时可以读完。如果你读完这篇文章觉得哪里被触动了,真正能让那种触动落地的不是读更多解读——是去读那三章原文。
 发表于 2026-4-6 04:07:21
|
查看: 173|
回复: 0
发表于 2026-4-6 04:07:21
|
查看: 173|
回复: 0
