流程引擎作为企业数字化转型的核心基础设施,承载着业务流程编排、任务调度、状态管理等关键职责。你是否想过,它如何从早期的单体架构演进到支持云原生的分布式设计?这背后不仅是技术的迭代,更是对复杂性、可靠性与性能的持续权衡。本文将为你深度剖析流程引擎的核心架构原理、设计模式、主流选型及性能优化实战。
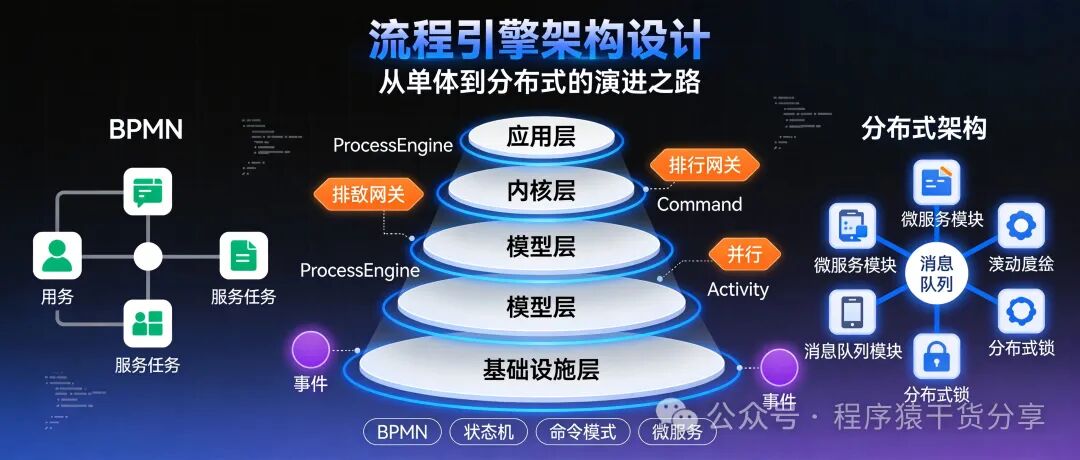
一、架构分层:构建清晰的职责边界
现代流程引擎通常会采用清晰的分层架构,将复杂系统拆解为职责明确的独立模块,这不仅是软件工程思想的体现,也为后续的演进和扩展打下了坚实基础。
1. 应用层:对外暴露能力
这一层直接面向开发者或业务系统,核心是提供友好的接入方式。
- 主要组件:REST API、各类语言的 SDK、管理控制台。
- 设计重点:易用性、API 安全性、多租户支持以及良好的开发者体验。
2. 内核层:流程执行的“大脑”
这里是流程引擎最核心的部分,定义了流程如何一步一步地执行。
- 主要组件:流程解释器(或编译器)、任务调度器、命令引擎。
- 设计重点:确保执行语义的绝对正确性,以及对事务边界的精准控制。
3. 模型层:流程定义的“蓝图”
流程引擎需要一种标准的方式来描述业务流程,模型层就是为此而生。
- 主要组件:BPMN 模型对象、表达式引擎、表单定义。
- 设计重点:模型的可扩展性(支持自定义节点)、版本管理以及高效的持久化方案。
4. 基础设施层:可靠运行的“基石”
任何健壮的软件都离不开底层基础设施的支撑,流程引擎尤其如此。
- 主要组件:数据库、缓存(如 Redis)、消息队列(如 Kafka、RabbitMQ)。
- 设计重点:高性能、高可用性、水平可伸缩性,以满足不同规模业务的需求。
架构师的核心工作,正是在这四层之间进行精妙的权衡:如何在通用性与极致性能之间找到平衡?在强一致性与系统可用性之间如何取舍?在保持内核简单与支持丰富扩展之间如何决策?这些思考贯穿了流程引擎设计的始终。关于系统架构的更多权衡与设计模式,可以进一步探索后端 & 架构板块中的相关内容。
二、核心设计模式:优雅解耦的基石
流程引擎的内核设计广泛采用了多种经典设计模式,理解它们,你就能理解引擎为何能如此灵活。
1. 命令模式与责任链
这几乎是所有现代流程引擎的核心架构模式。为什么命令模式如此重要?
- 统一入口:所有对流程状态(启动、完成任务、跳转等)的变更都通过统一的
Command 接口发起,路径清晰。
- 横切关注点:事务管理、操作日志、权限校验、缓存处理等公共逻辑,可以通过“拦截器”或“装饰器”模式统一织入命令执行链中,实现解耦。
- 回滚支持:每个命令都是独立的对象,便于实现撤销(Undo)或补偿(Compensation)操作。
- 性能优化:支持命令的批量执行或异步执行,提升吞吐量。
一个典型的命令链执行流程如下:
客户端调用 → CommandExecutor
→ 日志拦截器 → 权限拦截器 → 缓存拦截器
→ 数据库拦截器(开启事务) → 命令实现
→ 命令执行 → 提交/回滚事务 → 返回结果
2. 观察者模式
流程引擎作为业务中枢,需要与众多上下游系统集成。观察者模式(或称监听器模式)在这里大显身手。
- 生命周期事件:流程实例启动/结束、用户任务创建/完成等。
- 变量事件:流程变量或任务变量的创建、更新、删除。
- 异常事件:异步作业执行失败、节点超时、补偿流程被触发等。
开发者可以订阅这些事件,实现业务逻辑的松耦合集成,这也是实现事件驱动架构的关键。
3. 状态机模式
剥开复杂的外壳,流程引擎的本质是对业务状态流转的标准化管控。其底层核心可以抽象为 “流程定义(蓝图)+ 状态机(规则)+ 动作执行(行为)” 三层模型。
简而言之:当前状态 + 触发动作(事件) = 下一个状态。每个流程节点(Activity)都可以看作一个状态,网关(Gateway)则定义了状态流转的条件。
三、执行模型:解释器 vs. 编译器
流程引擎是如何“运行”BPMN XML文件的?这里存在两种主流的技术流派。
-
解释器模式(代表:Activiti 5/6, Flowable 5/6)
执行路径:BPMN XML → 内存中的对象模型 → 运行时解释执行
- 优势:灵活性高,支持流程定义的动态修改(热部署)。
- 劣势:执行路径在运行时才确定,性能相对较差,且执行逻辑对开发者不够透明。
-
编译模式(代表:Camunda, Activiti 7, Zeebe)
执行路径:BPMN XML → 抽象语法树(AST) → 生成字节码/确定的状态机定义 → 执行
- 优势:执行性能高,因为执行路径在部署时已确定;支持流程定义的静态验证(提前发现错误)。
- 劣势:修改流程定义后通常需要重新“编译”部署,灵活性稍逊。
四、分布式架构演进:应对规模挑战
当业务规模增长,单机引擎成为瓶颈时,分布式架构就成了必然选择。这带来了新的挑战和解决方案。
1. 分布式锁与并发控制
分布式环境最大的挑战之一是如何避免同一个流程实例被两个不同的引擎节点同时操作,导致状态混乱。
-
方案一:数据库行锁
SELECT * FROM ACT_RU_EXECUTION WHERE ID = '10001' FOR UPDATE;
- 优势:实现简单,依靠数据库本身的强一致性,非常可靠。
- 劣势:容易成为性能瓶颈,给数据库带来巨大压力。
-
方案二:Redis分布式锁
public boolean tryLock(String instanceId, int timeoutSeconds) {
String key = "lock:proc:" + instanceId;
String requestId = UUID.randomUUID().toString();
Boolean success = redisTemplate.opsForValue()
.setIfAbsent(key, requestId, timeoutSeconds, TimeUnit.SECONDS);
return success != null && success;
}
- 优势:性能好,能支撑极高的并发度。
- 劣势:引入了额外的Redis组件,需要考虑其高可用性。
-
方案三:乐观并发控制(如 Zeebe 采用)
UPDATE process_instance SET state = ?, version = version + 1 WHERE id = ? AND version = ?;
- 优势:完全无显式锁,性能理论上最优。
- 劣势:在发生更新冲突时,需要业务层实现重试机制。
2. 外部任务模式
在单体架构中,服务任务(Service Task)常常同步调用外部业务系统。这在分布式场景下会带来问题:外部系统响应慢会导致引擎工作线程被长时间阻塞,事务时间拉长,影响整体吞吐量。
解决方案就是外部任务模式(External Task):
- 当流程执行到外部任务节点时,引擎只在数据库中创建一条任务记录,并不执行任何业务逻辑。
- 引擎立即结束当前事务和命令,释放资源。
- 独立部署的“工作者(Worker)”程序,通过轮询或消息订阅的方式获取这些外部任务。
- Worker 执行完实际的业务逻辑(如调用某个微服务)后,调用引擎的 REST API 来完成任务。
- 引擎接收到完成信号后,继续驱动流程向后执行。
优势:彻底解耦了流程引擎与具体业务系统,引擎变得轻量且专注;天然支持异步、长耗时任务;业务系统的变更不影响引擎。
五、主流开源引擎选型对比
面对 Activiti、Flowable、Camunda,该如何选择?
| 特性 |
Activiti |
Flowable |
Camunda |
| 起源 |
由 Alfresco 公司开发,目标是轻量级BPM平台。 |
Activiti 的核心团队分叉而来,持续进行深度优化。 |
源自企业级BPM平台,商业支持和生态完善。 |
| 核心优势 |
社区历史最久,资料和文档丰富,简单易上手。 |
架构非常灵活,对微服务和云原生支持好,社区活跃。 |
功能最为强大齐全,尤其运维监控界面(Cockpit, Tasklist)非常优秀。 |
| 主要短板 |
核心团队变动后,版本更新和重大特性迭代放缓。 |
由于模块化程度高,学习曲线相对陡峭。 |
开源版功能有裁剪,更高级的功能需要商业版。 |
选型建议参考:
- 中小型项目,追求快速落地:可选择 Activiti,利用其成熟生态。
- 云原生、微服务架构场景:优先考虑 Flowable,其设计理念更贴合分布式环境。
- 复杂的企业级应用,需要强大运维监控:Camunda 是更稳妥的选择,其商业支持也更有保障。
六、性能优化与避坑实践
设计好架构,还需要精细的调优才能发挥最大效能。
1. 数据库与连接池调优
流程引擎是数据库密集型的应用。连接池配置至关重要,以 Druid 为例:
max-active: 100 # 根据实际并发和数据库承载能力调整
min-idle: 20 # 维持一定数量的热身连接,避免突发请求的延迟
validation-query: SELECT 1 # 定期检测连接有效性
2. 多级缓存策略设计
- L1 缓存(本地缓存):存放最热门的流程定义,使用 LRU 等算法管理。
- L2 缓存(集中式缓存,如 Redis):缓存全量的流程定义元数据,定时刷新,避免每个节点都访问数据库。
- 会话缓存:缓存用户任务列表等会话期数据,短期有效。
3. 历史数据智能归档
将所有数据都存在业务库会拖慢性能。建议分层处理:
- 热数据层:保留最近3个月的活跃流程实例数据,供实时查询。
- 温数据层:将3个月至1年的历史数据迁移到历史库或读写分离的从库。
- 冷数据层:超过1年的数据压缩归档到对象存储,释放主数据库压力。
4. 常见设计“陷阱”
- 陷阱一:单一流程过于庞大
- 问题:一个流程定义包含数百个节点,导致维护困难,且单次执行容易超时。
- 解决:遵循“高内聚、低耦合”原则,使用子流程(Sub-Process) 或调用活动(Call Activity) 进行拆分。
- 陷阱二:事务边界过长
- 问题:一个用户任务包含大量同步业务调用,导致数据库事务时间过长,占用连接池。
- 解决:合理使用异步延续(Async Continuation) 或外部任务模式,将长事务拆分为多个短事务。
- 陷阱三:监控体系缺失
- 问题:流程卡死、异常激增无法及时发现,影响业务连续性。
- 解决:必须建立完善的监控体系。关键指标包括:流程实例吞吐量、任务平均处理时长、节点执行成功率、系统资源使用率。可以集成 Prometheus + Grafana 进行采集和可视化告警。
七、面试高频问题精要
-
Q: 流程引擎如何保证事务一致性?
- A: 在单体架构下,通常采用命令模式将所有相关状态变更(更新实例、创建任务、记录历史)放在同一个数据库事务中。在分布式/微服务场景下,则采用 Saga 模式、TCC 或基于消息的最终一致性方案来保证跨服务的事务。
-
Q: 如何实现流程版本的热更新?
- A: 核心是“版本化”和“隔离”。新部署的流程定义会自动获得新版本号。新发起的流程实例使用新版本,而已经运行的旧实例继续使用其启动时的旧版本。高级功能还支持将运行中的旧实例批量迁移到新版本。
-
Q: 流程引擎如何支持高并发?
- A: 主要通过架构层面解决:读写分离、业务分库分表、使用分布式锁或乐观锁控制并发、采用外部任务模式异步化处理。配合 Redis 缓存热点数据,从而实现引擎节点的水平扩展。
总结与核心原则
流程引擎的架构设计,始终是在多个维度上进行精心的权衡:
- 通用性 vs 专用性:是选择万能的 BPMN 引擎,还是针对特定业务领域自研轻量级工作流?
- 强一致性 vs 高可用性:是追求 CP 模型保证数据绝对正确,还是接受 AP 模型保障服务永远可用?
- 功能丰富 vs 内核精简:是内置大量开箱即用的功能,还是保持内核最小化,通过插件机制扩展?
- 自研 vs 集成:是投入团队从头打造,还是基于优秀的开源项目进行二次开发?
无论如何选择,一些核心原则是共通的:
- 分层清晰,职责单一:这是应对复杂性的基石。
- 善用模式,灵活扩展:经典设计模式是解决共性问题的利器。
- 面向分布式设计:提前考虑拆分、无状态、异步和解耦。
- 可观测性至上:完善的日志、监控和追踪体系是线上稳定的生命线。
流程引擎远不止是一个“流程图执行器”,它是企业将业务流程数字化、自动化、智能化的技术基石。一个优秀的架构设计,能让它成为业务创新和效率提升的强大加速器。
你在项目中使用过哪种流程引擎?遇到了哪些独特的挑战或有趣的经验?欢迎在云栈社区的技术文档板块分享与交流。
 发表于 2026-4-6 05:02:14
|
查看: 253|
回复: 0
发表于 2026-4-6 05:02:14
|
查看: 253|
回复: 0
