笔记越记越多,但从来不翻。你是不是也这样?
前段时间,知名 AI 研究者 Andrej Karpathy 分享了他的解法:用 LLM 把散乱的资料编译成可查询、能自我修复的知识系统。这正好解决了我的一个痛点。
从一月底到现在,我陆续写了 43 篇 AI 实战文章,涉及二十多个工具。单篇看有深度,但整体是散的。最近有出版社找我聊出书,我才发现自己都说不清写了什么、缺什么、下一步该写什么。
之前我写过一篇 Obsidian 的介绍文章,讲得比较浅。这次,我结合 Karpathy 的方法和更深入的实践,把完整的自动化知识库构建过程跑了一遍,希望能给你提供一个可行的思路。
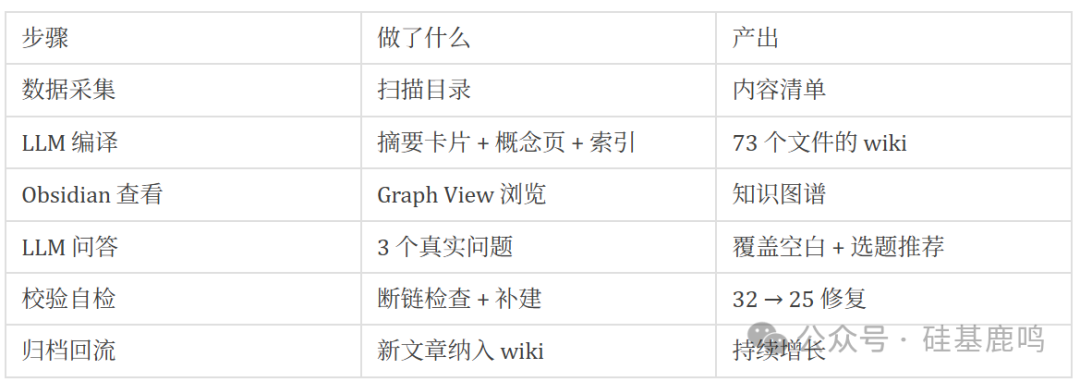
第一步:系统设计与数据采集
整个流程的核心,是一个 “摄入(Ingest)- 知识库(Knowledge Base)- 读取/查询(Read/Query)” 的循环系统。
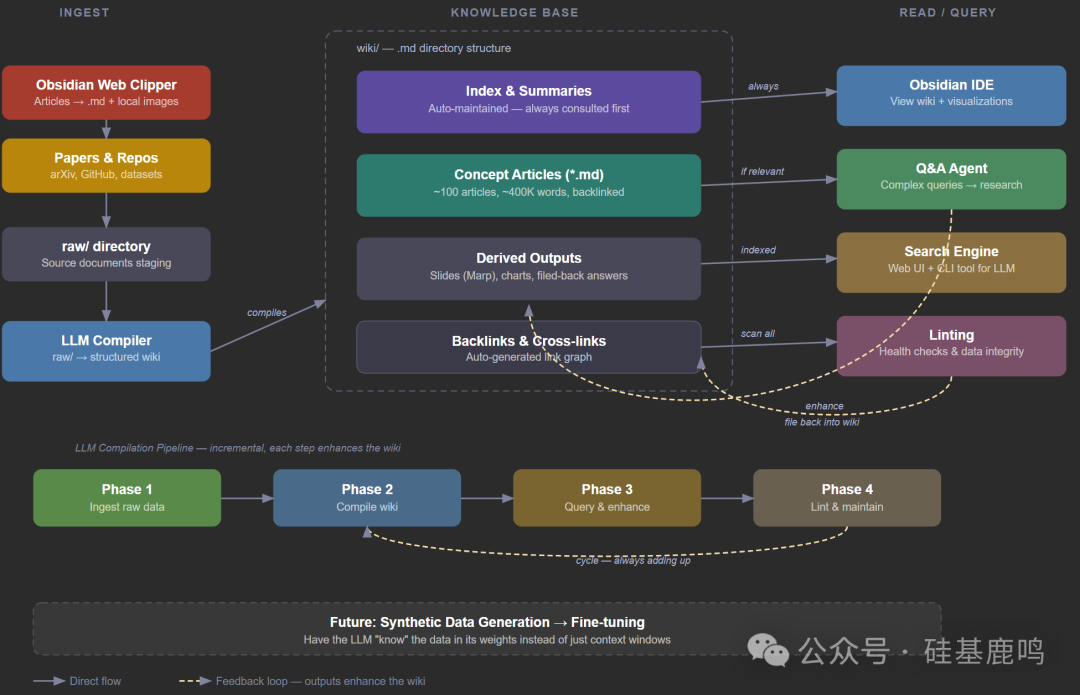
我的起点是 43 篇 Markdown 格式的文章。首要任务是让 Claude Code 扫描整个目录,生成一份全局内容清单。 43 篇文章的标题、字数、涉及的核心工具,几秒钟全部列出。这一步看似简单,意义在于你第一次在一个地方看到了自己所有内容的全貌,这是后续所有自动化处理的基础。
第二步:核心环节 — LLM 编译
我在文章目录下新建了一个 wiki/ 文件夹作为 Obsidian 的仓库(vault)。接下来是最核心的 LLM 编译 阶段。Claude Code 会逐篇读取 43 篇文章,并执行以下任务:
- 生成摘要卡片:为每篇文章生成一张摘要卡片,用三五句话概括核心内容,并标注核心观点和涉及的工具。所有工具名都用 Obsidian 的
[[双向链接]] 语法标注,例如 [[Claude Code]]、[[MCP]]。这不是装饰,后面整个知识网络就靠这些链接建立关联。
- 生成概念页:从所有摘要卡片中提取高频出现的技术概念(如 Claude Code, MCP, Superpowers),为每个概念生成一个独立的说明页面。
- 生成索引页:自动创建全局索引、按栏目索引、按工具索引、时间线索引。
我将整个过程拆解为多个顺序执行的任务,让 Claude Code 一步步跑。

生成摘要卡片最耗时,我启动了 4 个 agent 按文章栏目并行处理,十来分钟全部完成。
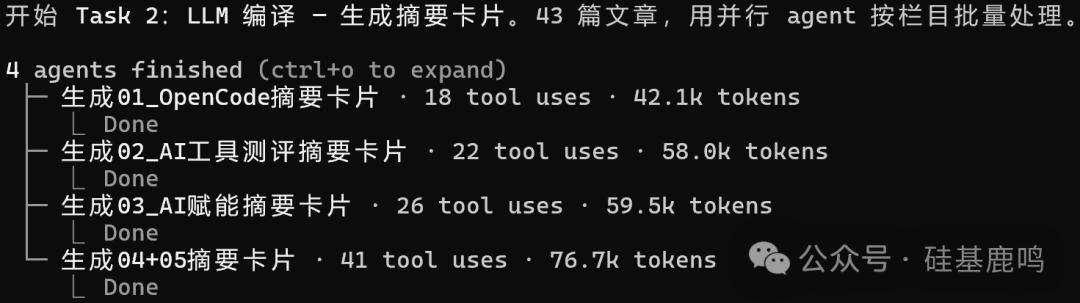
43 张卡片生成后,Claude Code 自动提取出 18 个高频概念,并让两个 agent 并行生成上下两批概念页。

最终,wiki/ 文件夹里生成了 73 个 .md 文件:43 张文章卡片、25 个概念页、5 张索引。这不是简单的复制粘贴,而是 LLM 理解后重新组织的结构化产物。
打开一张文章摘要卡片,结构清晰,信息密度高:

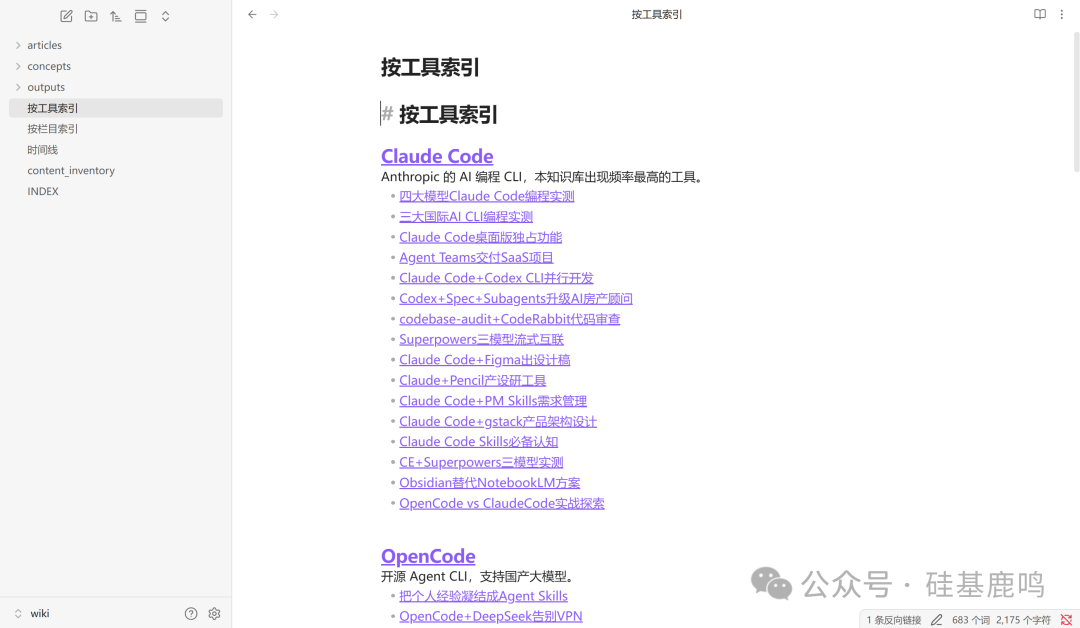
打开按工具索引页,每个工具下关联了所有相关文章,一目了然:
为什么强调“编译”? 直接让 Claude Code 每次会话读 43 篇原文(约30万字)也能回答问题,但每次都要重新解析、推导关系,效率低且不一致。而编译后的 wiki 是知识密度更高的产物,摘要浓缩到约 5 万字,概念关系已“物化”为具体的链接文件,查询时无需重复计算。
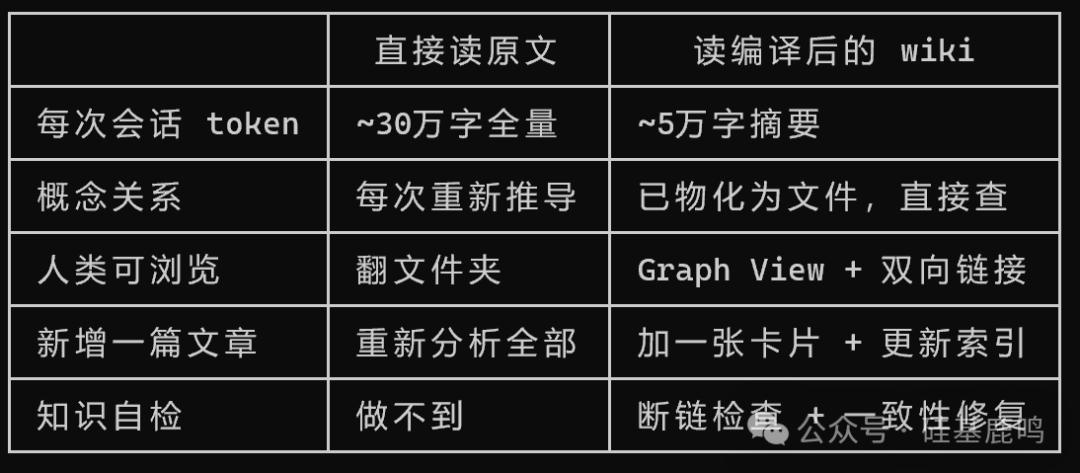
这就好比运行程序是直接执行编译后的二进制文件,而不是每次从源代码重新解释。知识管理同理,编译一次,后续即可高效、稳定地反复查询。
第三步:可视化与探索
用 Obsidian 打开 wiki/ 仓库,其 Graph View(图谱视图) 能直观展示整个知识网络的全貌。
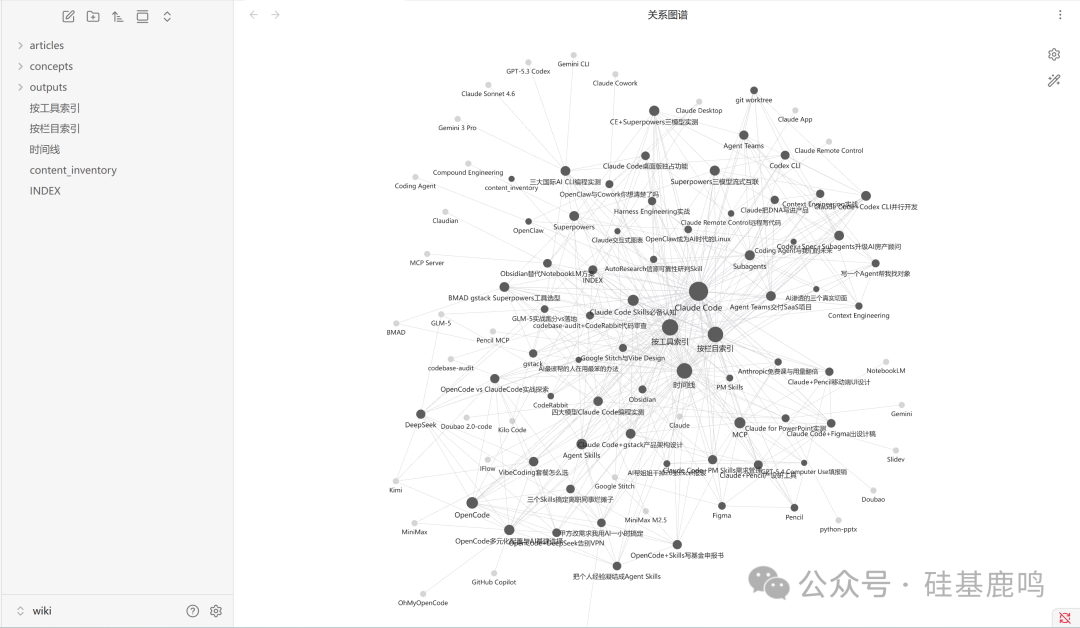
图中,Claude Code 是最大的节点,延伸出 28 条连接线。OpenCode 是第二大节点。MCP 处于中间位置,连接着 Figma、Pencil 等设计工具和 Obsidian 本身。
你可以点击任何一个节点跳转到对应的概念页,再通过概念页中的链接跳转到相关文章的摘要卡片。这种沉浸式浏览能让你发现此前未曾注意的关联。例如,我分别写过 Pencil 和 gstack 的文章,却从未想过将它们结合起来。在图谱上看到它们“相邻”,一个新的交叉选题自然就浮现了。
首页 INDEX.md 提供了清晰的导航入口,可以快速抵达各类索引和最近更新的文章。

第四步:主动查询与知识发现
这才是整个流程价值最大化的环节——对你的知识库进行主动提问。
问题一:“我写过哪些 Claude Code 的实战文章?覆盖了哪些能力点?还有什么重要功能没写?”
Claude Code 扫描所有概念页和文章卡片后,生成了一份详细的覆盖矩阵报告。
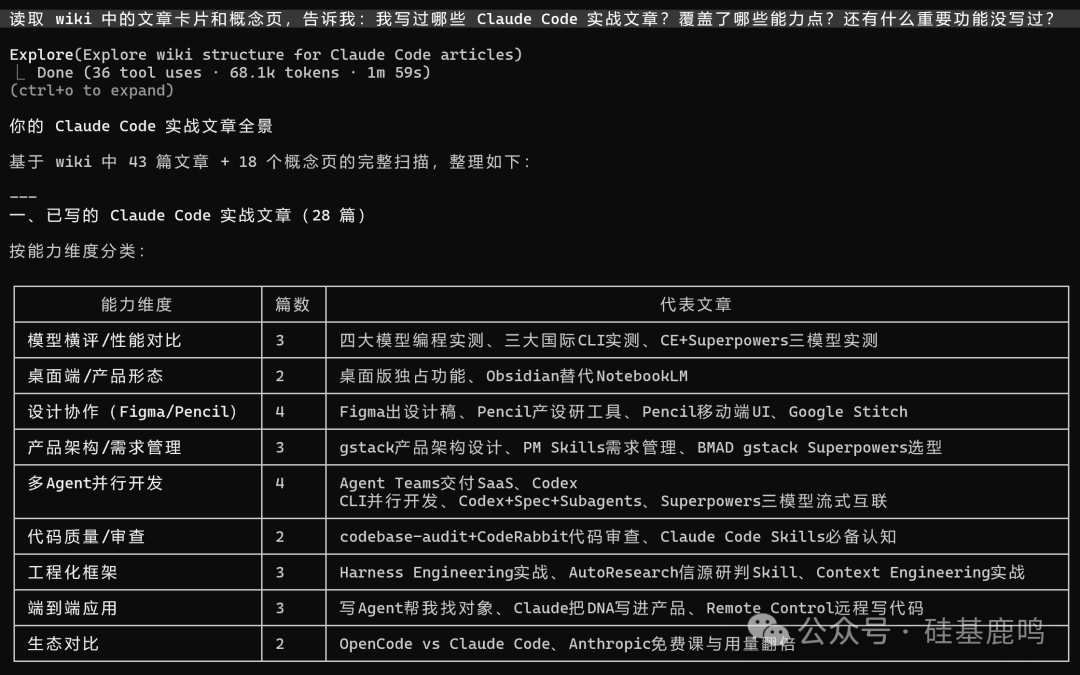
报告显示,我对 Agent Teams、Subagents、Skills、git worktree 等功能都有深度文章覆盖。但空白区让我意外:Hooks 系统、IDE 插件、CI/CD 集成、Memory 持久记忆等功能居然是零覆盖。 写了两个月,这些核心高级功能我竟完全没触及。
问题二:“我的文章里,概念之间的关联性如何?有哪些潜在的模式?”
Claude Code 进一步分析,生成了一张概念引用频率排名表和 7 个聚类拓扑图。
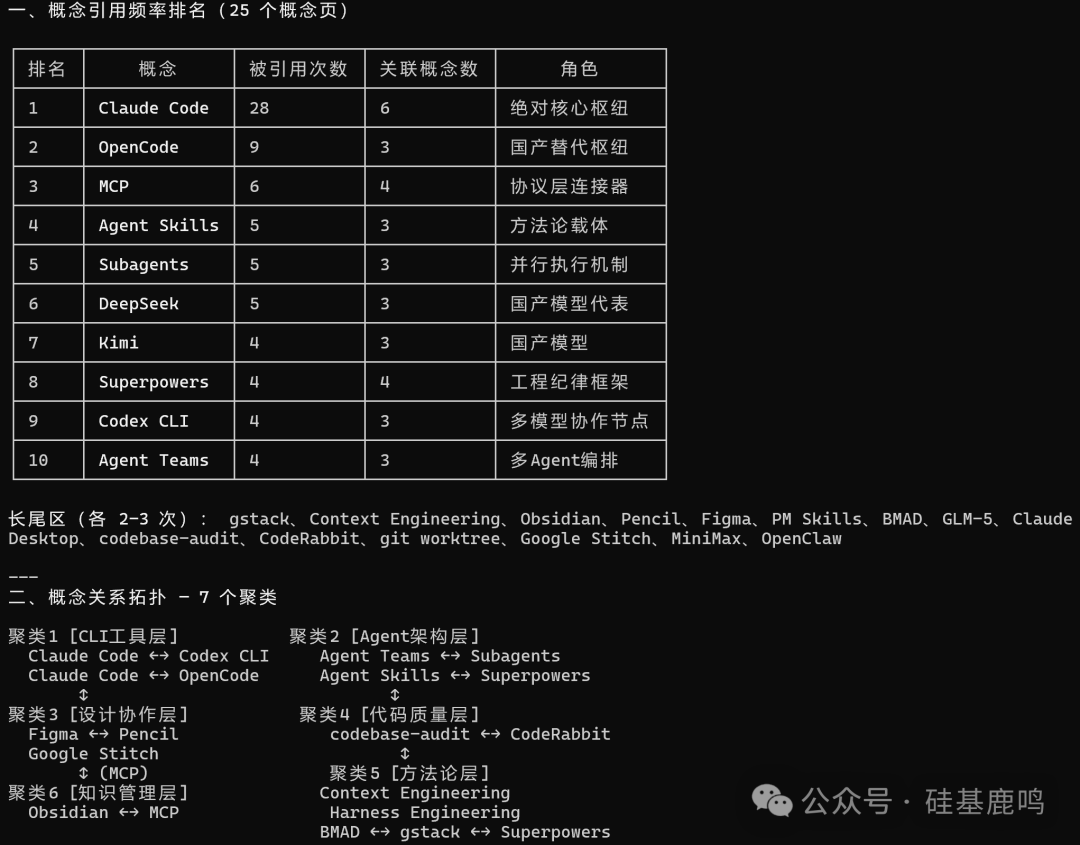
它将所有工具/概念分成了 CLI 工具层、Agent 架构层、设计协作层、代码质量层、方法论层 等聚类。图表清晰地揭示了哪些聚类之间联系紧密,哪些像“孤岛”。例如,OpenCode 和 Superpowers 这两个重要概念在文章中没有产生任何交叉。
问题三:“基于以上分析,推荐我接下来应该写什么?”
Claude Code 给出了三个高优先级选题:
- Claude Code Hooks 实战(填补零覆盖的高级功能空白)
- MCP Server 横评(频繁出现但从未作为专题主角)
- OpenCode + Superpowers 组合实践(连接两座“孤岛”)
每个选题都附带了理由和可关联的已有文章。这些洞察,靠自己手动翻文件夹是很难系统发现的。
更重要的是,这些问答结果并非一闪而过的聊天记录。Claude Code 将完整的分析保存成了两个 .md 文件,下次进行内容规划时,直接打开文件就能复用这些洞见。

第五步:校验、修复与持续迭代
最后一步是让系统进行自我校验。我让 Claude Code 扫描 wiki 中所有的 [[双向链接]],检查哪些链接指向了不存在的文件(即“断链”)。
系统扫出了 32 个断链——例如,[[Kimi]] 被 4 篇文章引用却没有对应的概念页,[[GLM-5]]、[[BMAD]] 同理。接着,Claude Code 自动补建了 7 个高频缺失的概念页,将断链数降至 25 个(剩余多为低频模型版本号,无需单独建页)。
这就是 Karpathy 所说的“知识库的自我修复”。你无需事无巨细地人工维护,LLM 可以主动查漏补缺。
这套系统是“活”的。未来每写一篇新文章,都可以让 Claude Code 生成摘要卡片加入 wiki,并自动更新相关索引和概念页。知识库像滚雪球一样越滚越大,链接网络也越来越密。
总结与思考
对我而言,最大的收获不是那个酷炫的知识图谱,而是通过主动提问获得的几个关键答案。两个月的工作被清晰地量化、归类,空白区被明确标识,未来的方向也变得有据可依。再面对出版社的规划询问,我也不至于临时抱佛脚。
这套方法适用于任何拥有大量散落 Markdown 文件的人,无论是技术笔记、读书摘录还是项目文档。它的局限性在于初次编译需要一定的计算时间(十分钟左右),且 Obsidian 对非技术用户有一定学习门槛。
但核心问题不在于工具,而在于方法。大多数人使用笔记软件,只是把东西存进去,然后永远不再打开。知识管理的真正目的,是让知识流动和被利用起来。 通过结合 Claude Code 的自动化处理能力和 Obsidian 的可视化、链接特性,我们能够构建一个真正动态、可查询、能自我演进的知识系统,让积累产生复利。
 发表于 2026-4-6 08:15:56
|
查看: 200|
回复: 0
发表于 2026-4-6 08:15:56
|
查看: 200|
回复: 0
