本文基于《Building Microservices》一书的核心思想,系统梳理微服务架构的设计原则、实施策略与挑战,为开发者构建稳健的微服务系统提供指导框架。
01 微服务
什么是微服务?
微服务就是一些协同工作的小而自治的服务。在一个单体系统中,我们通常会用抽象层或模块来保证代码的内聚性,简单说就是把因相同原因而变化的东西聚在一起。
什么时候需要考虑微服务?
当代码库庞大到可能“牵一发动全身”时,根据业务边界来确定服务边界就能很好解决这个问题。服务专注于某个业务边界内,例如一个大型商城系统,通常会划分为用户、订单、支付等微服务。
微服务需要满足自治性
微服务应该可以彼此独立修改,某个微服务的部署不应引起其消费方的变动。
微服务的好处
技术异构性
一个庞大业务的不同模块可能适合不同的存储和语言,微服务能很好地屏蔽技术细节,打破技术栈壁垒。引入新技术时,微服务也能降低系统风险,即便出问题也易于处理。
弹性
单体应用若出异常,整个服务可能瘫痪。拆分为微服务并进行多机部署,能降低系统完全不可用的风险,同时可采用功能降级保证核心功能。
扩展
单体应用中,若某模块出现性能问题,必须扩展整个服务。拆分为微服务后,则可单独扩展特定服务,将性能要求低的服务部署在较差的硬件上,充分利用资源提升系统性能。
简化部署
单体应用发布会影响整个系统。微服务架构中,只需独立发布部署某个服务,即使出问题也只影响该服务,可快速回滚。
与组织结构相匹配
微服务架构能很好实现“小团队+小代码库”模式,提高团队生产力。
可组合性
微服务架构中,已有功能可以重用,甚至通过组合几个微服务,就能为某个应用提供完整的后台支撑。
对可替代性的优化
单体应用中,淘汰某些模块可能带来不可预估的问题。微服务架构中,小模块可以轻松移除或重写。
小结
业界也存在共享库、模块等分解技术,但这可能导致其成为系统耦合点。同时要记住,没有银弹,不存在通用准则。使用微服务甚至要面对单体应用没有的部署、测试、监控等一系列复杂工作,还要处理分布式事务和 CAP 相关问题。
02 演化式架构师
模糊的定位
架构师的重要职责是保证团队有共同的技术愿景,确保项目交付质量。软件行业很年轻,以至于有时我们自己都不清楚要干什么。与传统行业(如建筑师)相比,软件必须足够灵活,能根据用户需求不断演化。
城市规划师
相比“架构师”,“城市规划师”可能更贴合这个角色。城市规划师的职责是优化城镇布局,进行合适分区使其更易于居民生活,同时考虑未来因素,这与架构师的职责如出一辙。
分区
城市规划师要对城镇合理分区,架构师这边的“区域”对应的就是服务边界。架构师应多关注服务间的交互,而忽略服务内细节。如果每个服务对外暴露的协议五花八门,对消费者将是噩梦。虽说不用关心每个服务的具体实现,但如果一个团队用 10 种技术栈,无疑会增加管理成本和招聘难度。另外,架构师最好和团队共同 Coding,才能更好地指导和了解团队。
原则性的方法
- 制定战略性目标 - 业务部门的愿景。
- 制定设计原则 - 最好不要超过 10 个。
- 实践 - 对原则的落地。
- 结合 - 原则要与实践相结合。
标准
- 监控 - 所有服务使用同样的方式上报健康状态和其他监控数据,最好标准化。
- 接口 - 对外暴露接口的类型最好固定那几种,如 HTTP/REST 或 RPC。
- 架构安全性 - 所有服务都要能应对下游的错误请求,避免系统逐渐脆弱。
代码治理
达成共识,大家才能做好事情。提供范例和服务代码模板是两种比较有效的方式。有好的代码范例供人模仿,即使错了也不会错得太离谱。模板也能提高开发速度和服务质量。但要小心不要落入 DRY (Don't Repeat Yourself) 陷阱,因为过度依赖共享可能导致系统过耦合。
技术债务
每个团队都可能因排期等因素欠下技术债务。架构师需要提供温和的指导,让团队决定如何偿还,最好是列表格定期回顾。
例外管理
原则有时可能会被打破,但这不代表它不正确,它可能演变成新原则。架构师要有严谨但包容的心态,如果对开发人员限制过多,可能微服务架构并不适合。
集中治理和领导
架构师需要了解新技术并知道如何取舍,通常领导一个小组负责治理,并能得到高层支持。一个人的想法可能比较片面,小组通常比个人更聪明。
建设团队
帮助战友共同进步,使其能独立负责某个服务,并得到充分锻炼。
小结
演化式架构师应承担的责任:
- 愿景 - 确保团队有共同的技术愿景,满足客户和组织需求。
- 同理心 - 理解你所做的决定对客户和同事带来的影响。
- 合作 - 尽量多和同事沟通,从而更好地对愿景进行定义、修改和执行。
- 适应性 - 确保在客户和组织需要时调整技术愿景。
- 自治性 - 在标准化和团队自治之间寻找正确平衡点。
- 治理 - 确保系统按照技术愿景的要求实现。
03 如何建模服务
什么样的服务是好服务
松耦合
修改一个服务而不需要修改另一个服务。
高内聚
相关行为聚集在一起形成独立服务。
限界上下文
每个限界上下文包含两部分:一部分需与外部通信,一部分则不需要。就像细胞膜,细胞因细胞膜而存在,它定义了细胞内外的界限并决定什么能通过。在不同限界上下文间存在共享模型,屏蔽了内部实现细节。
如果服务边界和领域的限界上下文能保持一致,并且微服务能很好地表示这些限界上下文,就走出了高内聚低耦合微服务架构的第一步。当然,微服务不宜过早拆分,将大型单体拆成微服务比较容易,但直接使用微服务架构会比较困难。
业务功能
不应从共享数据角度考虑,而应从这些上下文能提供的功能出发,不应成为基于 CRUD 的贫血服务。要思考这个上下文是做什么用的,然后考虑它需要什么数据。
逐步划分上下文
考虑微服务边界时,应先考虑较大的、粗粒度的,发现合适缝隙后再进一步划分,就像劈柴,先劈出大缝隙,再逐步分解成细木片。
修改系统的目的是满足业务需求。基于业务的划分,在客户提需求时,会更倾向于对一个服务的改动;按技术接缝划分可能导致洋葱式架构,服务被分成很多层,改动起来可能很痛苦,所以通常不是首选方式。
04 集成
理想的集成技术
集成可能是微服务相关技术中最重要的。理想的集成技术要做到:
- 避免破坏性修改:在对一个微服务的响应中添加字段,不应影响消费方。
- API 要保证技术无关性:不应选择对微服务具体实现有限制的集成方式。
- 使服务易于消费方使用:如果消费方使用我们的微服务比登天还难,设计得再好也没用。
- 隐藏内部细节:微服务应屏蔽内部实现细节,否则可能提高与消费方耦合的风险。
共享数据库
这是业界常见的集成方式,简单快捷,但问题很多。外部系统能看到内部细节,消费与特定技术绑定,逻辑修改可能要同时修改相关系统。这样做与松耦合高内聚毫不相干,会给开发人员带来无穷无尽的痛苦。
同步与异步
服务之间到底用同步还是异步通信?同步意味着阻塞,调用方会阻塞自己直到整个操作完成;异步则调用方不需要等待,甚至不关心操作是否成功。
同步可以知道事情执行是否成功,异步对于运行时间长的任务更有效。那么异步通信如何知道执行结果呢?可采用注册回调方式,服务端调用完成后,调用该回调进行通知。
也可以基于事件进行协作,客户端发起的不是请求,而是事件,所有订阅者收到事件后决定是否需要处理。这种方式耦合性很低。
编排与协同
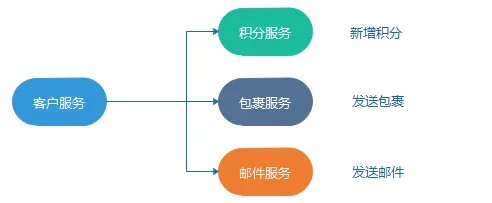
使用编排方式,我们会把某个服务当成中心大脑来指导并驱动整个流程。
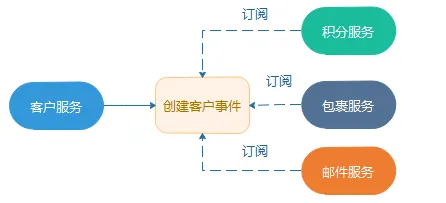
使用协同方式,仅会告知系统中每个部分各自的职责,具体实现由它们自己决定。
使用编排方式,可能导致某个服务成为整个流程的中心枢纽,其他服务沦为贫血的、基于 CRUD 的服务;但使用协同方式,则需额外对整个流程做跨服务监控以保证正常运行。所以我们可以根据不同场景进行选择,或混用。
RPC
远程过程调用,允许你调用一个方法,但事实上整个方法的结果是由某个远程服务产生的。RPC 帮程序员生成桩代码,从而能够快速使用。理论上,只调用方法、忽略细节确实给程序员带来极大便利。
但要注意,远程调用和本地调用是有区别的,因为网络并不可靠!
REST
表述性状态转移,它是一种风格。举个例子,我要对某个资源进行增删,可能会用 CreateCustomer 和 DeleteCustomer,但使用 REST 风格就会变成:
POST : www.test.com/customer
DELETE : www.test.com/customer
是不是简洁很多?
为避免把存储数据暴露给消费者,可以先设计外部接口,等稳定后再实现微服务内部的数据持久化。
但是,使用 REST 无法帮你生成桩代码,而且性能上可能遇到问题,对于低延迟场景,使用 HTTP 可能不是很好的主意。
基于事件的异步协作
主要关注两件事:微服务发布事件机制和消费者接受事件机制。
我们可以使用像 RabbitMQ 这样的消息代理来解决。这么做系统虽有较好的弹性和可伸缩性,但也会增加开发流程的复杂度。不过一旦做好,它将成为实现松耦合系统的重要手段。
还有一个原则:中间件一定要足够简洁,不要掺杂业务逻辑。
事件驱动的系统虽然看起来有较好的弹性和可伸缩性,但开发难度高,带来的一致性问复杂,对程序员要求也高,需要进行思维转换,这有时真的很困难。当要追踪某个问题时,一定要引入监控机制,并对事件有关联 ID,方便追踪这种跨服务请求。
DRY
在微服务架构中,如果一味追求 DRY 是很危险的,比如很多微服务使用了同一个共享库。
所以,建议微服务内不要违反 DRY,微服务间可以适当违背 DRY。
按引用访问
如果我们确定了一个领域实体,那么任何和该领域相关的改动,都应该由这个领域完成。
比如我有一个客户服务,任何对客户的改动,都应调用客户服务来完成,即客户服务是客户信息唯一可靠的来源。
举一个例子,如果要发一封邮件,邮件里有用户的姓名、地址、订单信息等,但请求邮件服务是异步的,在这个时间差中用户信息可能改变,如何解决?我们可以仅传递客户资源和订单资源的 URI,等真正要发送时,再去查询最新信息。
版本管理
- 减小破坏性修改影响的最好办法是尽量不要这样修改。
- 要尽早发现破坏性修改。
- 使用语义化版本管理,见文知意。
- 新老接口可以共存,来保证灰度或随时回退。
- 同时存在新老服务(建议不要这样做,成本很高)。
小结
无论如何都要避免数据库集成,在 RPC 和 REST 之间做取舍,协同优先于编排,避免破坏性修改。
05 分解单块系统
我们上面讨论了什么是好的服务、一些规范和建议,以及系统如何向好的方向演化。那么一个大型的单体应用应该如何拆分成微服务呢?
关键是找到接缝——这部分代码进行修改不会影响系统的其他部分。这些被识别出来的接缝就会成为服务的边界。
前面讨论过的限界上下文就是一个很好的接缝,它定义的就是组织内高内聚、低耦合的边界。很多代码会用包或命名空间来定义这个概念,例如 Golang 的 package。
现在,假如我们有一个巨大的单体服务,它是一个在线音乐系统。我们把它划分为以下几个上下文:
- 产品目录。
- 财务。
- 仓库。
- 推荐。
从哪个部分入手?
最好考虑哪部分抽离出去的效益最大,而不是为了抽离而抽离。
我们考虑以下几个因素:
- 改变速度:某个功能抽离且可以自治,可以加快后期的开发速度。
- 团队结构:根据团队结构来抽离,比如存在异地协作,可以拆分出去。
- 安全:某部分业务涉及数据安全,抽离出去可以对所有服务做监控、数据保护等。
- 技术:推荐系统出了新算法,独立部署后能提高系统速度。
在我们分析系统为什么会有各种杂乱依赖时,通常来说数据库大概率是源头。
找到源头后,我们抽象出一个独立的存储层,把数据库相关操作聚类到一起。
几个例子
打破外键关系
我们要生成一份财务报表,8月份销售《青藏高原》2000份,获利10000元。这需要从产品表和账单表获取数据,甚至存在外键关联。所以最好是产品服务暴露 API 给财务服务,而不是直接访问数据库。这个 API 会成为微服务化的第一步。
有时候让系统的一部分变慢会带来更大的好处,而且这个“慢”事实上也能控制在一定范围。
打破的前提是知道系统期望的行为是什么,想清楚再做决定!
共享静态资源
把城市编号放到数据库,各个服务共享,就形成了数据库集中,这显然不是我们想要的。
应该怎么做?
- 每个服务一个库。
- 这部分资源放到各自的服务代码中。
- 这部分资源形成一个单独的服务(太极端了)。
建议采用第二种,但是以配置文件的形式,各个服务自己保存一份,并支持热更新。
共享数据
仓库服务和财务服务都需要用户记录,他们都会向客户记录写数据和读数据,形成了数据共享。那么我们可以把客户的概念抽象出来,形成服务,对外暴露 API。
共享表
我们的产品目录服务和仓库服务都会用到产品信息,他们共享一张表。这时,可以把这个表分离成两个表:产品目录项表和库存表。
实施分离
事实上,先分离数据库结构,暂时不对服务进行分离会更好一些。我们可以随时回退,不影响消费者。一旦稳定下来,再考虑对整个应用程序进行分离。
事务
事务的好处是,可以使一系列操作要么全部执行,要么全都不执行。
那么微服务架构中如何实现?
- 再试一次 - 通过日志或放入队列,之后再次尝试。
- 终止整个操作 - 通过补偿事务来抵消之前的操作,如删除某行记录,失败怎么办?可以重试或给个界面操作,也可以自动化解决。
- 分布式事务 - 借助其他工具,如事务管理器,常见的算法是两阶段提交(本文不做介绍)。
我们到底应该怎么做?
这些方案都会带来复杂性,而且分布式事务很容易出错,且不易扩展。我们是否可以将各种操作放到本地事务,然后依赖最终一致性方案解决?我认为可以,而且不要仅仅从技术上解决,因为可能真的不好解决。我们可以从业务上解决,设立一个中间态,例如将这类问题订单统一归类为“处理中的异常工单”?然后通过其他方式进行管理和修复?
数据导出
当我们要导出数据或生成报表时,可以通过提供 API、定时同步数据库、使用事件订阅等方式,但是千万不要暴露数据库!
小结
我们要理解,服务一定会越来越大,但我们需要在拆分成本变得过高之前,意识到我们需要拆分,这非常关键。
06 康威定律和系统设计
康威定律说的是,任何组织在设计一套系统时,所交付的设计方案在结构上都与该组织的沟通结构保持一致。
Amazon 认为,小团队比大团队的工作更有效,于是产生了著名的“两个披萨团队”,即没有一个团队应该大到两个披萨不够吃。
07 规模化微服务
微服务形成一定规模后,系统变得异常复杂,我们应该怎么办?
首先故障一定会有,而且无处不在。我们要允许错误发生,并将其控制在一定范围。当一个系统变得不可用时,要有安全降级方案,保证核心功能。
要从架构设计原则上,保证一个服务不会导致整个系统崩溃。
在规模化微服务这种分布式架构下,我们要准备好应对系统故障的方案:
- 超时 - 跨进程调用要设置超时时间来保护下游。
- 断路器 - 当下游资源请求失败或超时达到一定数量,断路器打开,后续不再请求下游。
- 舱壁 - 为每个下游服务设置一个连接池,形成舱壁,保证不会互相影响。
- 隔离 - 服务之间依赖越低越安全。
- 幂等 - 允许重复调用,且每次调用造成的结果相同,不必担心多次调用会有不利影响。
- 扩展:
- 强大的硬件可以提升系统性能。
- 拆分服务提高负载。
- 把服务进行分散部署。
- 做好负载均衡,避免单点故障。
- 基于 worker 的模式,按需分配数量。
- 系统架构完全无法应对当前负载,考虑重新设计。
- 扩展数据库:
- 使用副本数据库,并且可以在必要时切换为主数据库。
- 读取扩展:很多服务以读取为主,可以选择读副本。
- 写操作扩展:使用分片机制,如对某个关键字取 hash,写入不同实例。
- 缓存。
- 自动伸缩:根据负载主动扩缩容。
- CAP 定理:一致性、可用性、分区容忍性不可能同时满足,我们最多只能保证其中的两个。
- 服务发现:告诉人们微服务在哪里。
08 总结
微服务的原则
围绕业务概念建模
通常围绕业务的限界上下文定义的接口要比围绕技术概念定义的接口更加稳定。
接受自动化文化
大量的微服务涌现,我们必须要借助自动化工具开发维护我们的服务。
隐藏内部实现细节
为了实现服务自治,隐藏细节至关重要。服务还应该隐藏它的数据库,避免产生数据库集成。
让一切都去中心化
确保团队对服务的所有权,同时要做到内部开源,人们可以修改其他团队的代码。
可独立部署
服务可以独立部署,当你修改发布时,不需要通知其他团队进行改动。
隔离失败
防止系统遭受灾难级的级联故障。要了解舱壁和断路器,保证你的系统没有那么脆弱。
高度可观察
系统需要一个清晰的观测平台,通过关联标识跟踪调用链路。
什么时候不应该使用微服务
当你不了解它的时候,因为这时候出错的概率会很大。
写到最后
微服务架构会给你带来很多选择,需要你做很多决策。虽然有时决策可能是错误的,但我们应该保证错误的影响范围足够小。遵从“演化式架构”,不断地前进探索。我们不应该进行爆炸式的重写,应该随着时间的推移,温和地对我们的系统进行修改,持续地进行改变!
如果你想与其他开发者交流更多关于架构设计或分布式系统的经验,欢迎来 云栈社区 一起探讨。
 发表于 2026-4-6 08:35:42
|
查看: 151|
回复: 0
发表于 2026-4-6 08:35:42
|
查看: 151|
回复: 0
