准备一场30–50分钟的技术分享,想让新人听得懂,老鸟也不嫌浅?从下列框架里挑一个直接套用就行。
你是不是也遇到过这种情况:精心准备了满满的干货,结果台下鸦雀无声,大家默默刷起了手机。
别担心,问题通常不出在你的技术深度,而是讲述方式。一个好的“故事模板”,能像GPS一样,引导听众轻松地跟你走完全程,让小白也能跟上,大牛直呼内行。
01 Why‑What‑How —— 先讲痛点,再给解药,最后上操作
| 步骤 |
你要做的 |
听众获得 |
| Why |
用1句数字化痛点 |
“哦,原来我也被这个折磨” |
| What |
用类比 + 定义 |
概念边界 |
| How |
拆3步流程 + Demo |
操作清单 |
例子:Pod 调度
- (痛点) Why:“想象一下,双11零点,监控告警突然炸了:一台服务器的CPU飙到95%,另外几台却在30%闲逛。为啥?因为你最核心的几个Pod,都挤在同一台机器上开Party了!”
- (类比) What:“这时候,
PodAntiAffinity就该登场了。它干的事很简单,就一句话:‘求求你们别挤同一辆车!’。它会告诉K8s,打了这个标签的Pod,请务必分散到不同的机器上。”
- (操作) How:“实现它只需要在你的YAML文件里加上这三行核心配置。来,我们看一下Demo,加完之后一发布,流量立刻就均匀地分散开了。”
避坑:还没说明Why就贴200行配置,一秒劝退。
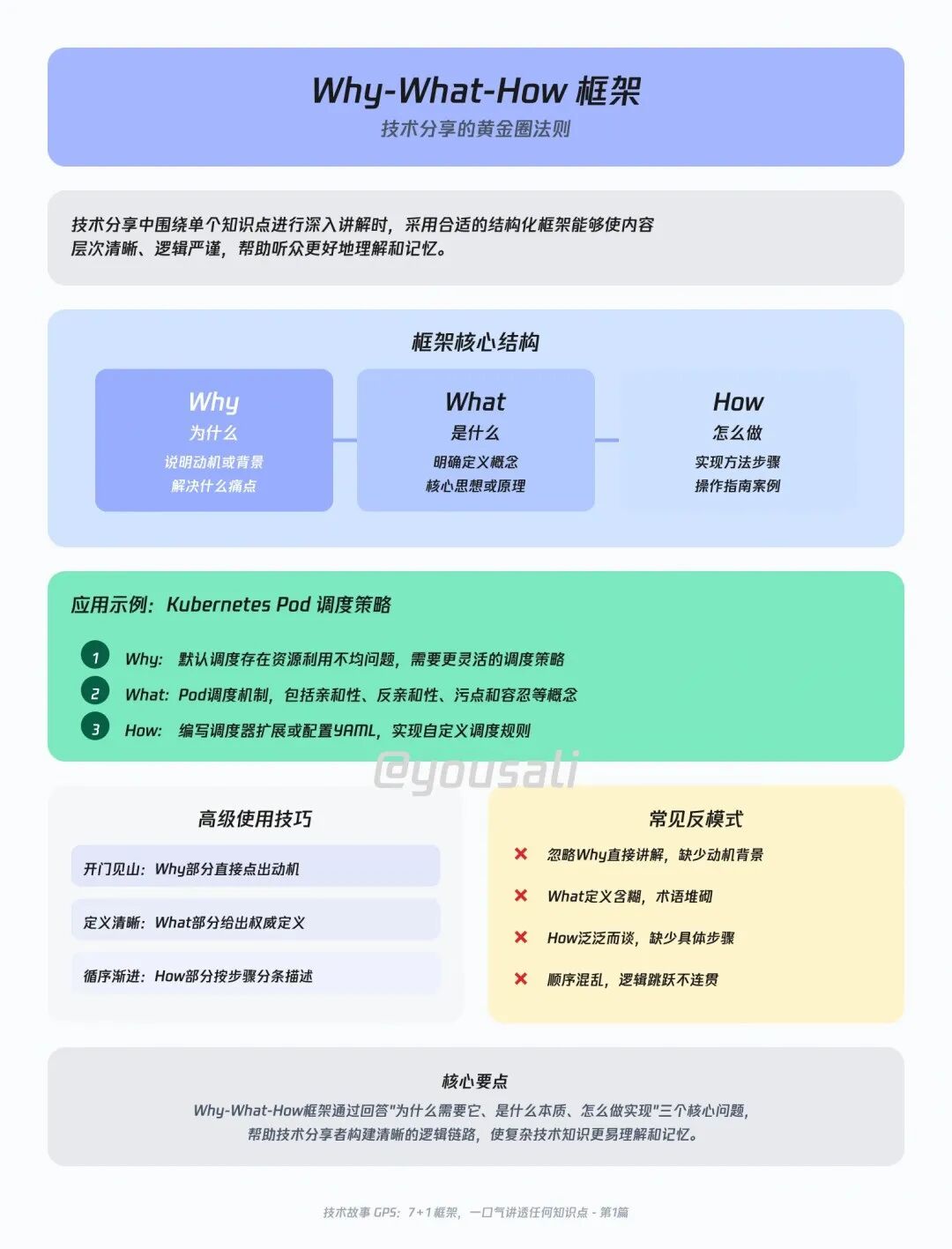
02 层层递进 —— 像剥洋葱一样,从皮到芯讲透它
当你需要深度剖析一个复杂技术(比如一个算法、一个底层协议)时,用这个框架,可以兼顾不同水平的听众。
- Surface (表层):一句话概括,让所有人先有个基本印象。
- Deep (深层):深入一层,揭示它的核心工作机制。
- Deeper (更深):再往下挖,聊聊性能、设计取舍和关键瓶颈。
- Expert (专家视角):最后,分享一些前沿的“黑科技”或社区最新的研究方向。
举例:聊聊改变世界的 Transformer
- Surface (表层):“首先,让所有人先上车:Transformer最牛的一点,就是用并行计算彻底取代了RNN的串行模式,处理文本的速度快了几个数量级。”
- Deep (深层):“那它是怎么做到并行的呢?我们来掀开引擎盖,看看它的核心魔法——‘多头自注意力机制’ (Multi-Head Self-Attention)。”
- Deeper (更深):“但是,当文本变得超级长,这个‘注意力机制’的计算量会暴增,性能就遇到了瓶颈。为了解决它,社区大神们搞出了像 FlashAttention 这样的优化方案。”
- Expert (专家视角):“如果你想知道现在最顶尖的团队在研究什么,那答案就是 MoE (Mixture of Experts) 和稀疏注意力 (Sparse Attention),这可能是通往更强AI的下一把钥匙。”
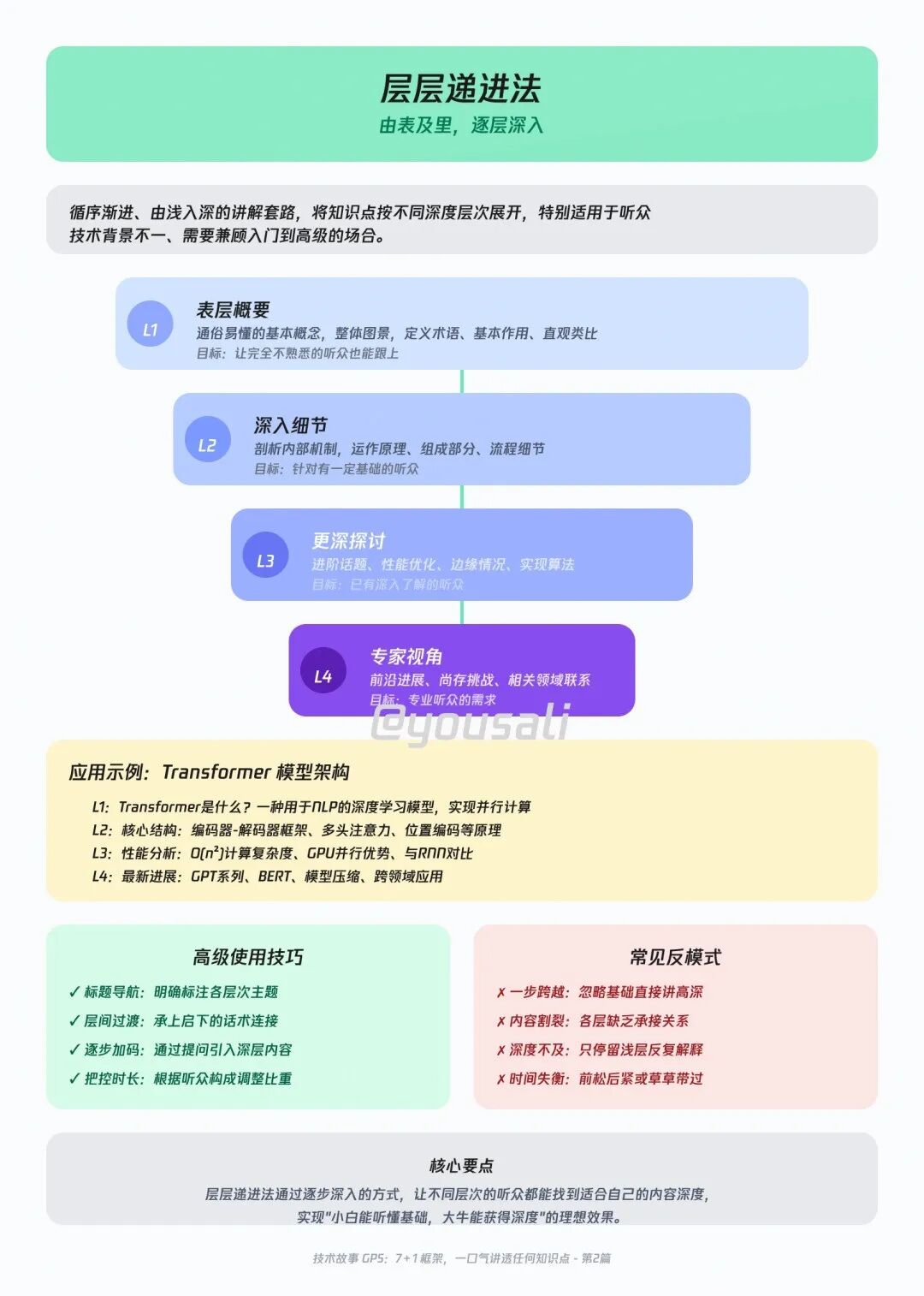
03 F‑R‑S‑C‑O —— 用五个视角,给知识做一次全面体检
这个框架强迫你从“使用者”而非“创造者”的视角,审视一个技术的完整生命周期。它将抽象的概念,转化为具体可感的画面。
| 维度 |
问题 |
| F 功能 |
它到底能解决什么核心问题? |
| R 合理 |
它为什么被设计成这样?设计得巧妙吗? |
| S 稳定 |
它稳不稳?万一崩了,有什么Plan B? |
| C 兼容 |
跟我们的老系统能愉快地玩耍吗?迁移成本高吗? |
| O 运维 |
好不好伺候?部署、监控、排错麻不麻烦? |
例子:Raft(一句话一维度)
- (功能) F:“它只解决一件事:保证数据副本的强一致性,不多也不少。”
- (合理) R:“它的设计就是为了让人能看懂,这意味着我们自己实现时不容易出bug。”
- (稳定) S:“只要超过一半的节点活着,数据就不会丢,可用性极高。”
- (兼容) C:“主流语言都有成熟的库,我们不用重复造轮子。”
- (运维) O:“etcd用的就是它,社区已经帮我们踩过所有坑了,运维经验很成熟。”
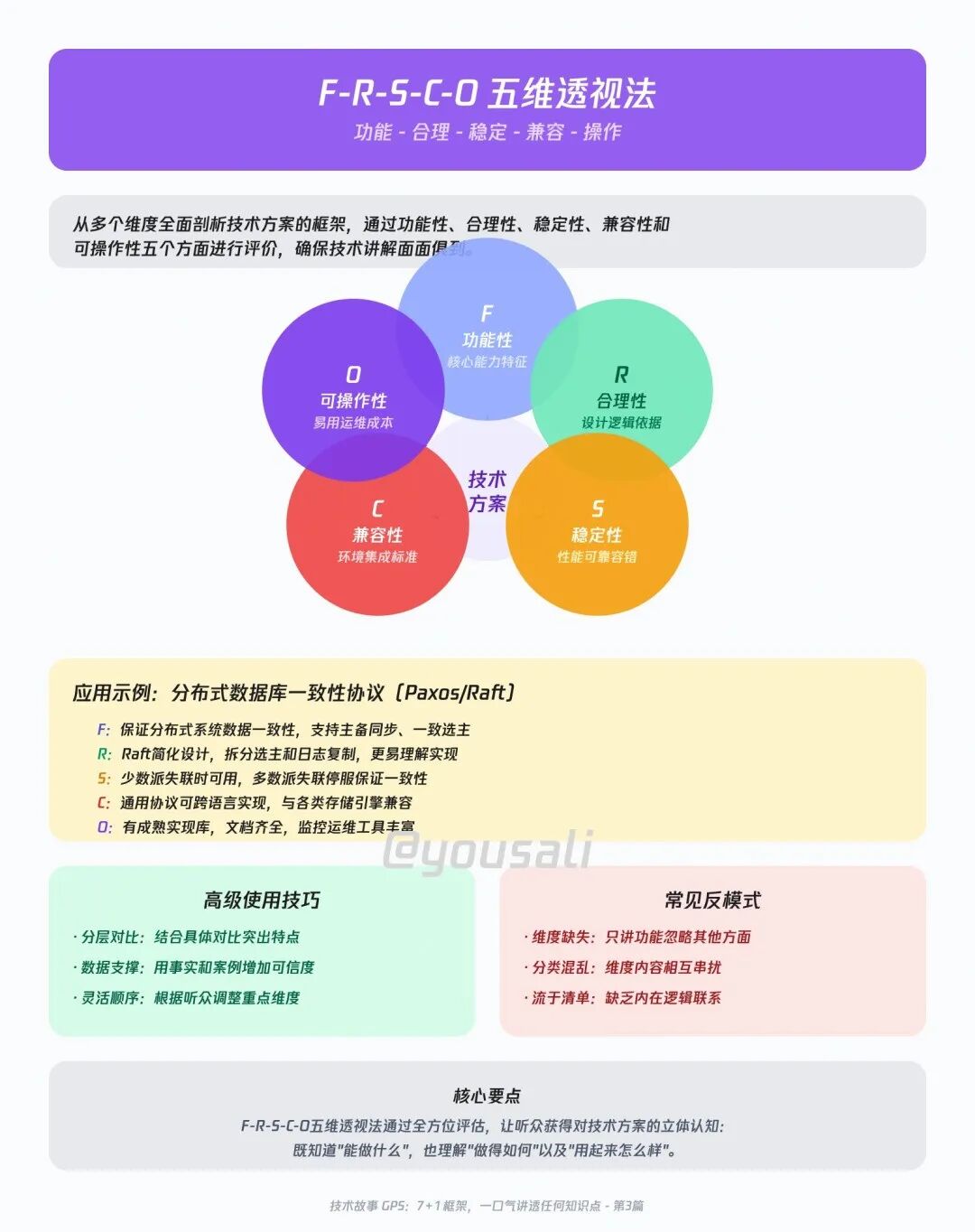
04 英雄之旅(Failure-Driven Story) —— 从一次事故到一次成长
大脑天生就爱听故事,尤其是关于“克服挑战”的故事。这不仅是传递信息,更是在分享情感与智慧。
- Fault (事故):描述一个具体的、有冲击力的故障场景。
- Detect (发现):我们是如何一步步定位到问题根源的?
- Mitigate (缓解):第一时间做了什么来止血,让损失最小化?
- Prevent (预防):我们如何从代码、架构、流程上根治了它?
- Learn (教训):这次昂贵的“学费”,教会了我们团队什么?
举例:那次让支付接口全红的秒杀事故
开场悬念:“时间回到去年双十一的19:58,离大促正式开始还有2分钟,突然,支付网关的监控图瞬间全红!”
- Fault:所有支付接口返回500错误。
- Detect:运维冲进日志系统,发现大量报错指向“数据库连接池耗尽”。
- Mitigate:我们立刻手动扩容Pod,同时紧急开启限流,暂时丢弃非核心请求,保住主流程。
- Prevent:事后复盘,发现是连接池没有做“预热”导致。我们在启动脚本里加入了预热逻辑,彻底修复。
- Learn:这次事故后,我们的《大促预案Checklist》上,永远多了一条:“所有服务必须进行连接池压力测试和预热”。
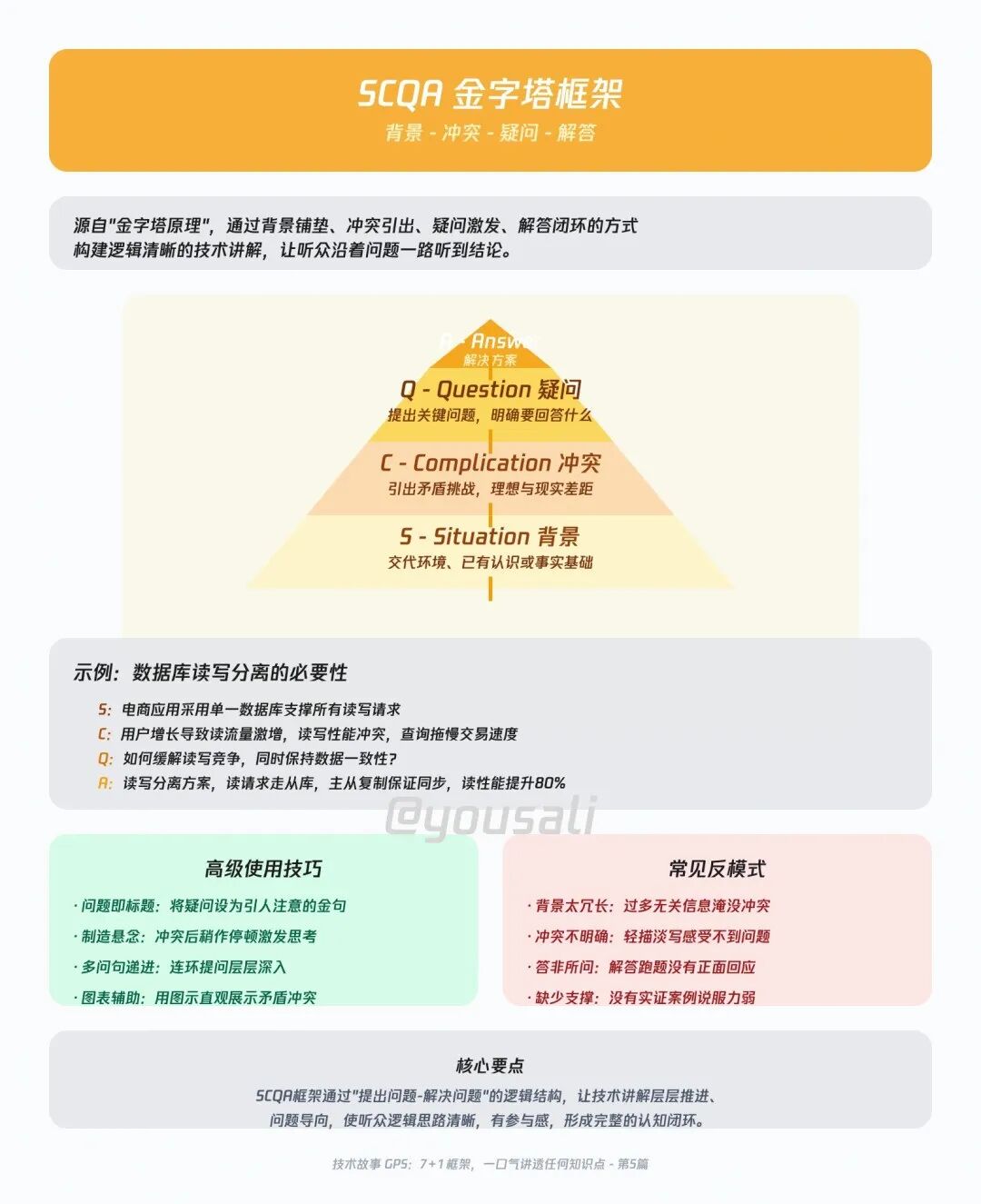
05 SCQA —— 30秒的悬念电影
在分享的开头,用它来制造一个“认知缺口”,迅速抓住听众的注意力。这是麦肯锡经典的分析框架,非常适合用在分享的开场,或者当你想快速提出一个问题并给出你的核心答案时。
- S (Situation - 背景):先描述一个大家都认同的现状。
- C (Complication - 冲突):然后,指出这个现状下出现了什么新问题、新矛盾。
- Q (Question - 提问):基于这个冲突,自然地引出一个核心问题。
- A (Answer - 回答):最后,给出你的核心论点或解决方案,作为整场分享的总纲。
举例:我们的数据库还能扛多久?
- S (背景):“各位同事,大家知道,过去三年,我们整个网站都依赖着那台单点MySQL稳定运行。”
- C (冲突):“但从上个季度开始,随着用户量翻倍,它的读取性能增加了5倍,写入延迟也翻了一番,用户已经开始抱怨卡顿了。”
- Q (提问):“所以,问题来了:我们有没有办法,在不进行大规模重构的前提下,既保证写入稳定,又能让读取速度飞起来?”
- A (回答):“答案是肯定的。今天我要分享的,就是一套成熟的解决方案:数据库读写分离与主从复制架构。”
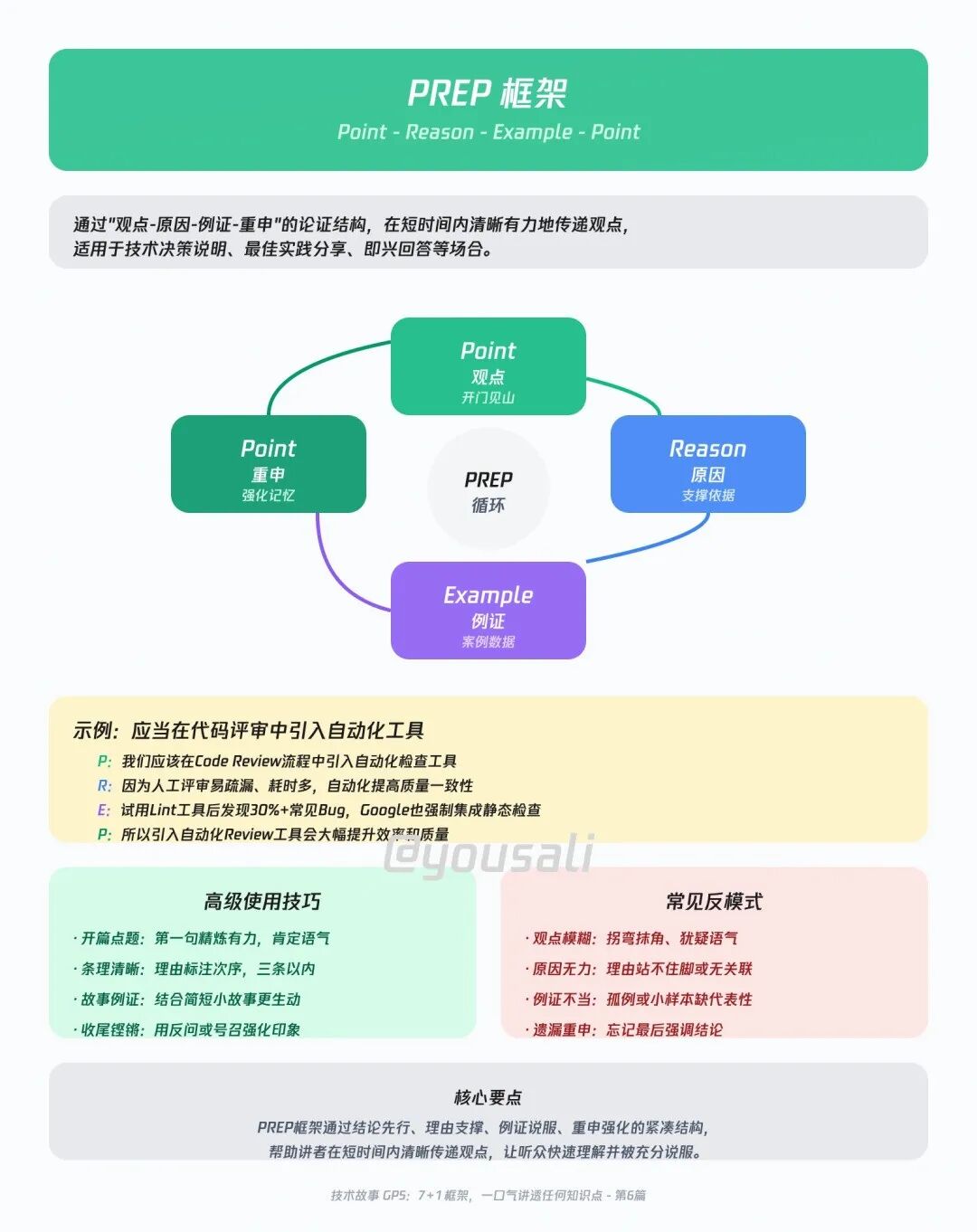
06 PREP —— 60秒的电梯路演
这个框架是表达观点和说服他人的利器。结构简单,逻辑清晰,特别适合在会议上回答问题,或者向老板提出建议。
- P (Point - 观点):开门见山,先说你的核心结论。
- R (Reason - 理由):然后,解释你为什么会这么认为。
- E (Example - 案例):给出一个具体的数据或例子来支撑你的理由。
- P (Point - 重申观点):最后,再次强调你的结论,完成闭环。
举例:申请使用AI Code Review
- P (观点):“老板,我建议我们团队必须立刻引入基于AI的Code Review工具。”
- R (理由):“因为现在纯靠人工,不仅效率低,而且大家都在花宝贵的时间去纠结代码风格这种小事,反而忽略了更深层的逻辑漏洞。”
- E (案例):“上周,我拿咱们核心的xx模块试用了一下某AI codereview Agent,它自动扫描出了30%我们之前人工评审时遗漏的低级Bug和潜在的问题。”
- P (重申观点):“所以,为了提升代码质量和开发效率,我们应该马上就搞起来!”
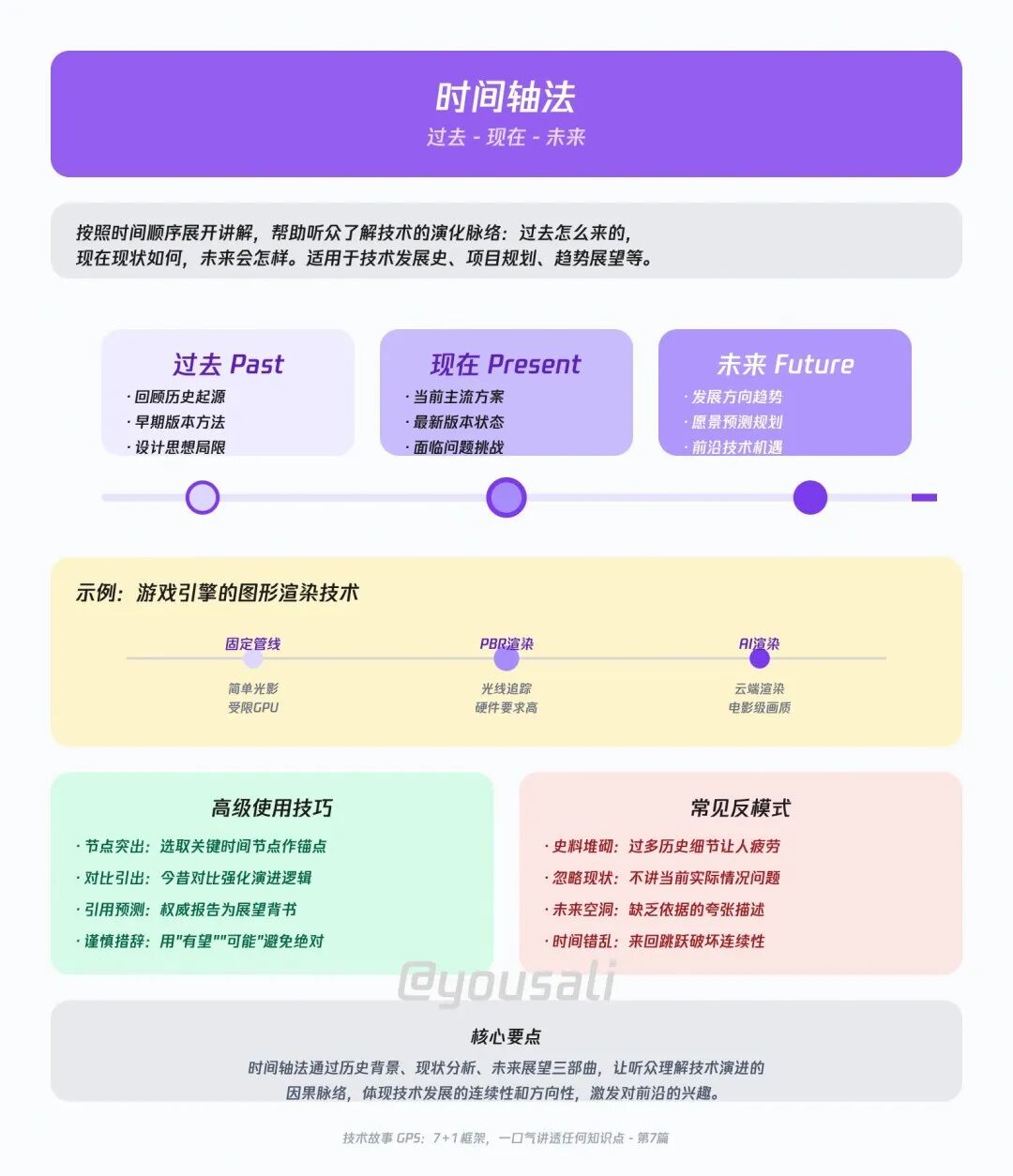
07 时间轴 —— 带着听众穿越技术的“前世今生”
为知识赋予时间的维度,可以揭示其演进的“模式”,让听众理解“为何今天是这样”。
| 过去 |
现在 |
未来 |
| 它最初是为了解决什么问题而诞生的? |
它现在发展成什么样了?主流用法是什么? |
社区正在探索哪些新方向?它可能会变成什么样? |
举例:游戏实时渲染技术的进化之路
- 过去 (Fixed Pipeline):“在游戏开发的早期,图形渲染用的是‘固定管线’,就像一条规定好的流水线,开发者能做的很有限。”
- 现在 (Programmable Shader & Real-time Ray Tracing):“后来,‘可编程着色器’的出现解放了生产力。发展到今天,我们甚至可以在游戏里实现‘实时光线追踪’,模拟真实世界的光影效果。”
- 未来 (AI + Global Illumination):“那明天会怎样?我认为是 AI驱动的渲染(比如DLSS 3)和实时全局光照的结合,最终将彻底模糊游戏和电影CG的界限。”
08 选型矩阵(附录,一页表搞定)
| 框架 |
核心思路 |
侧重解答的问题 |
典型应用场景 |
| Why-What-How |
原因→概念→方法,三段式铺陈 |
为什么需要?是什么?怎么做? |
介绍新技术/工具,讲清动机概念及用法 |
| 层层递进 |
由浅入深,分层次展开 |
初级入门→高级详解 |
全面剖析复杂技术,兼顾不同水平听众 |
| FRSCO 五维透视 |
多维度评价,全面审视 |
功能、合理性、稳定性等五方面 |
技术方案评审、架构选型比较 |
| Failure-Driven Story |
故障驱动,故事化串联 |
发生了什么?如何解决?学到了啥? |
故障复盘分享、可靠性经验传授 |
| SCQA 金字塔 |
背景→冲突→提问→回答 |
问题是什么?如何解决? |
引出问题并给方案,适合问题导向的内容 |
| PREP 论证 |
观点→原因→例证→重申 |
你的观点是什么?凭啥支持? |
发表技术看法、决策说明、问答阐述 |
| 时间轴(过去现在未来) |
按时间演进顺序 |
从哪来?现状?去向何方? |
技术演进史、路线图展望、趋势分析 |
以上框架各有优劣,选择时应结合内容特点和听众需求:如果需要说理就用PREP,如果要讲故事就选Failure-Driven Story,要提炼问题则SCQA,用科普介绍则Why-What-How或层层递进等。
09 5个你最容易踩的坑
- 顺序错乱:还没讲清楚Why(为什么需要),就开始大讲How(如何实现)。
- 砌文字墙:一个段落超过3行,或者一张PPT上超过50个字,观众立刻放弃阅读。
- 概念轰炸:抛出一个技术名词后,不给一个接地气的例子或类比。
- 故事没结尾:讲完惊心动魄的救火过程,却不总结教训(Learn),听众感觉意犹未尽。
- 表格失焦:一个表格里的列数超过5列,信息过载,没人会仔细看。
10 终极彩蛋:让AI成为你的专属演讲教练
光有框架还不够,怎么快速填充内容?答案是:学会给AI下达精确的指令。一个好的Prompt,能让AI从“聊天玩具”变成你的“首席内容官”。
下面这个Prompt就是一个绝佳的范例。你可以把它存为模板,下次想讲解任何技术点时,只需修改“知识点”和“要求”,就能生成一份高质量的初稿。
你是一位资深机器学习工程师 + 高手讲师,擅长把复杂原理讲成人人都能听懂的故事。
== 任务 ==
- 受众:具备基础深度学习知识、对Transformer感兴趣的开发者(混合水平)。
- 时间:3–5分钟微讲解(适合插入到30分钟大课中)。
- 知识点:Transformer核心 —— **Multi-Head Self-Attention**。
- 框架:**Why-What-How**(先痛点,再概念,最后实践)。
== 要求 ==
1. 用 **口语中文**,一个段落 ≤ 3句;多用列表与代码框作视觉锚点。
2. 每步框架都要有 **一句话Takeaway**(粗体标注)。
3. 必须包含:
• **1段伪代码 / PyTorch代码**(展示Q, K, V线性投影 + 多头拼接)。
• **1个实际数字** 说明性能/效果(例如“BERT-Large用16头注意力将F1提升1.2%”)。
4. 指出 **1个常见误区**(anti-pattern)与修正。
5. 完整输出Markdown:最外层用 `## Why` `## What` `## How`,末尾加 `🎯 行动清单`。
6. 如信息不足,先提出 ≤ 2个简洁澄清问题,再开始写稿。
== 输出示例(仅结构示意,生成时请填充内容) ==
## Why
…
**Takeaway:…**
## What
…
# 关键代码示例
**Takeaway:…**
## How
…
**常见误区**:… → 修正:…
**Takeaway:…**
🎯 行动清单
* …
* …
== 交付 ==
只输出Markdown讲稿,不要其它说明。
11 行动清单:今晚就从这三件事开始
- 随便选一个你熟悉的知识点,用 Why‑What‑How 的结构写一个5行字的提纲。
- 回忆一次你印象最深的线上故障,用 Failure-Driven Story 的5个步骤,写一个300字的复盘小故事。这对于面试求职时梳理项目经历也很有帮助。
- 打开你最近做过的一个PPT,把里面的“文字墙”毫不留情地拆分成短句、列表和代码框。
写得像聊天,句子保持 < 20 词,段落 ≤ 3行—— 这是让人愿意读完的硬道理。
Done! 现在,你有了7 + 1个“故事GPS”。下次上台,听众不刷手机,掌声自然来。如果想了解更多硬核的计算机基础知识来支撑你的分享深度,欢迎来云栈社区交流探讨。
 发表于 2026-4-6 08:33:03
|
查看: 135|
回复: 0
发表于 2026-4-6 08:33:03
|
查看: 135|
回复: 0
