没有记忆的AI Agent就像一条“七秒记忆”的鱼,每次对话都是全新的开始,根本无法积累经验或了解用户。这正是记忆系统需要解决的核心问题:让Agent既能记住当前任务的每一步,也能记住跨任务的重要信息。本文将从实现层面详细拆解Agent的短期记忆与长期记忆系统,探讨如何让AI真正“记住”并“成长”。
Agent为何需要记忆?
让我们先看看一个没有记忆的Agent会多让人“抓狂”。
今天你告诉它:“帮我优化这段Python代码,风格要简洁一点,变量命名用英文。”它出色地完成了任务。
明天你又说:“帮我写一个爬虫脚本。”结果它输出了一段满是中文变量名、风格冗长的代码。
你困惑了,昨天不是说好了吗?对它而言,昨天的对话已不复存在。它不记得你的偏好,不记得任何约定,每次交互都是从零开始。这种“失忆”在单次问答中或许能容忍,但对于一个旨在持续为你服务的智能体来说,是致命的缺陷——它无法积累对你的了解,也无法在任务间建立连贯性。
记忆系统的存在,正是为了赋予Agent这种连续性和个性化能力。
短期记忆:任务执行的“工作台”
短期记忆本质上就是大语言模型(LLM)的上下文窗口(Context Window)。你可以将其想象成LLM的“工作台”,上面摆放着当前任务的所有相关材料:用户指令、LLM的思考过程、工具调用结果以及每一步的中间状态。LLM正是通过阅读这个工作台上的所有内容,才知道“我正在做什么、做到哪一步了、之前发现了什么”。
实现上,短期记忆通常通过维护一个消息列表来实现。
class ShortTermMemory:
def __init__(self):
# messages 列表就是 LLM 的工作台
# 每条消息有 role(谁说的)和 content(说了什么)
self.messages = []
def add(self, role: str, content: str):
# role 有三种:user(用户输入)、assistant(LLM 输出)、tool(工具返回结果)
# 每一步的内容都要追加进来,保持完整的任务状态
self.messages.append({"role": role, "content": content})
def get_context(self):
# 调 LLM 时把完整的 messages 传进去
# LLM 会读取这份完整历史来理解当前状态
return self.messages
def clear(self):
# 任务结束后清空,准备迎接下一个任务
# 清空意味着这次任务的所有中间状态都消失了
self.messages = []
# 一次任务执行的示例
memory = ShortTermMemory()
memory.add("user", "帮我分析这几家竞品的核心功能差异")
memory.add("assistant", "好的,我先搜索一下竞品 A 的信息")
memory.add("tool", "搜索结果:竞品 A 的核心功能是实时协作编辑,支持最多 50 人同时在线……")
memory.add("assistant", "已拿到竞品 A 的信息,再搜竞品 B")
# 每次调 LLM 都传完整历史,它才能知道自己做到哪一步了
response = llm.chat(messages=memory.get_context())
关键点在于,每次调用LLM传入的是完整的消息历史,而不仅仅是最后一条。这就是短期记忆的实质——将整个任务状态“背在身上”。
当然,其代价是消息列表会越来越长。当超出上下文窗口限制时,早期的内容会被截断,Agent便开始“遗忘”任务早期的信息。并且,一旦任务结束,短期记忆会被清空,一切归零。若想实现跨会话的记忆,就必须依赖长期记忆。
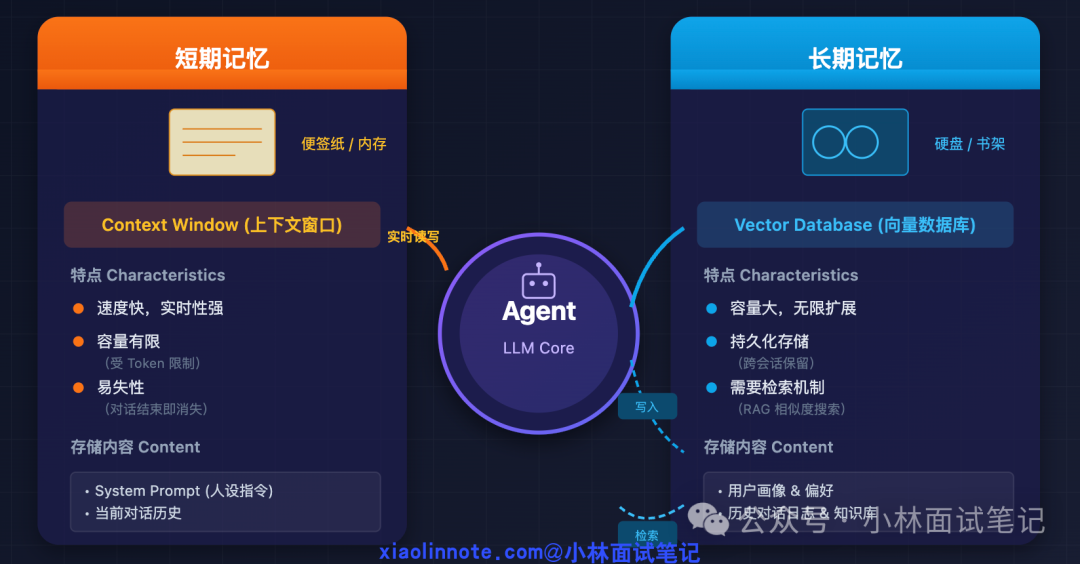
长期记忆:基于向量数据库的“档案馆”
长期记忆的核心技术是Embedding(向量化)与向量数据库(Vector Database)。这二者共同构成了一个基于语义的、可扩展的记忆存储与检索系统。
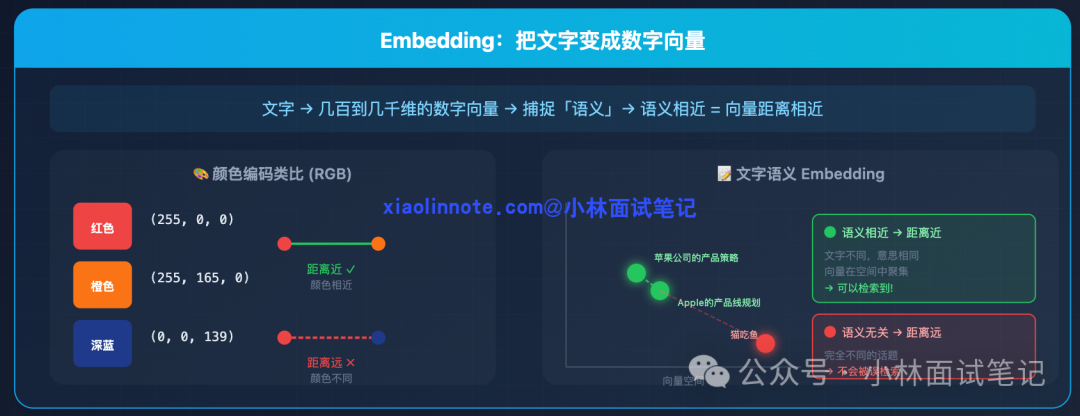
1. Embedding:将文字转化为语义向量
Embedding是将一段文本转换为一组数字向量(通常几百到几千维)的过程。这组向量能够捕捉文本的“语义”,语义相近的文本,其向量在空间中的距离也越近。
可以类比颜色编码(RGB):红色是(255, 0, 0),橙色是(255, 165, 0),它们在向量空间中距离很近,因为颜色相似。深蓝色(0, 0, 139)与红色则相距甚远。Embedding对文字做的正是同样的事——“苹果公司的产品策略”和“Apple的产品线规划”语义相近,向量距离就近;“苹果公司”和“猫吃鱼”语义无关,向量距离就远。
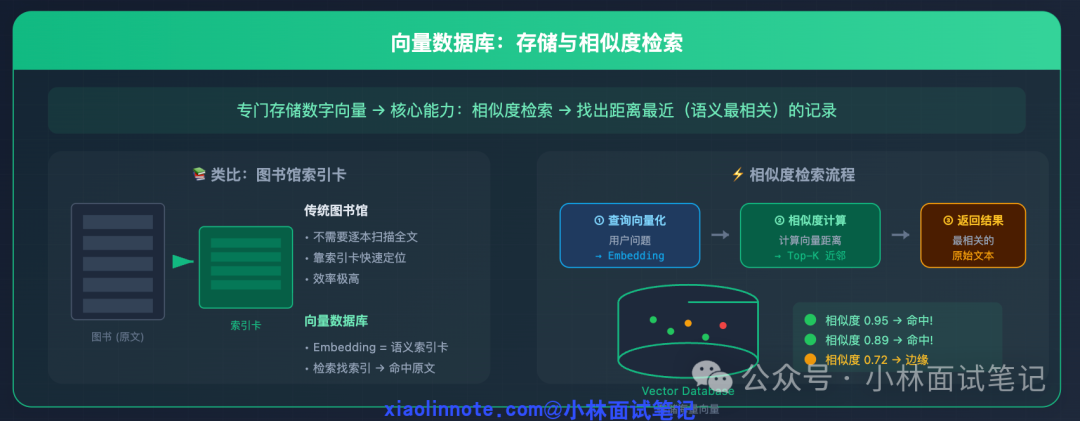
2. 向量数据库:专为相似度检索而生
向量数据库是专门存储和检索这些高维向量的数据库。其核心能力是“相似度检索”:给定一个查询向量,快速找出库中与之最相似的几条记录。
这类似于图书馆的索引卡系统。你不需要翻阅每一本书,而是通过索引卡快速定位相关书籍。在这里,Embedding向量就是“语义索引卡”,检索时先找到最相关的索引(向量),再返回对应的原始文本,效率极高。
结合两者,长期记忆的运作流程就清晰了:
- 存储:将重要信息通过
Embedding模型转化为向量,与原文一同存入向量数据库。
- 检索:当需要记忆时,将当前问题或上下文也转化为向量,在
向量数据库中执行相似度搜索,找出最相关的几条记忆。
下面是使用OpenAI Embedding和ChromaDB(一个轻量级向量数据库)的示例代码:
from openai import OpenAI
import chromadb
client = OpenAI()
# ChromaDB 是一个轻量的向量数据库,适合本地开发使用
db = chromadb.Client()
# 创建一个「集合」,类似于关系数据库里的表,用来存 Agent 的长期记忆
collection = db.get_or_create_collection("agent_memory")
def save_to_long_term(content: str, metadata: dict):
# 第一步:把文字内容转成 embedding 向量
# text-embedding-3-small 是 OpenAI 的 embedding 模型,把文字变成数字向量
embedding = client.embeddings.create(
input=content,
model="text-embedding-3-small"
).data[0].embedding # 得到一个几百维的浮点数列表
# 第二步:把向量、原文、元信息一起存进向量数据库
collection.add(
embeddings=[embedding], # 这是「索引」,用于相似度检索
documents=[content], # 这是原文,检索命中后返回给 LLM 直接使用
metadatas=[metadata], # 附加信息,比如存入时间、任务类型、重要程度
ids=[f"mem_{hash(content)}"]
)
def retrieve_memory(query: str, top_k: int = 3) -> list[str]:
# 第一步:把当前查询也转成 embedding 向量
# 和存储时用的是同一个 embedding 模型,这样「语义距离」才有可比性
query_embedding = client.embeddings.create(
input=query,
model="text-embedding-3-small"
).data[0].embedding
# 第二步:在向量数据库里找「向量距离最近」的几条记录
# 向量距离近 = 语义相近 = 内容最相关
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k # 只取前 top_k 条,避免检索出太多噪音
)
# 返回的是原文文本列表,LLM 可以直接读取这些记忆内容
return results["documents"][0]
长期记忆的粒度:存多少才合适?
存储长期记忆时,“一次存多少内容”的粒度问题至关重要,直接决定了检索效果。
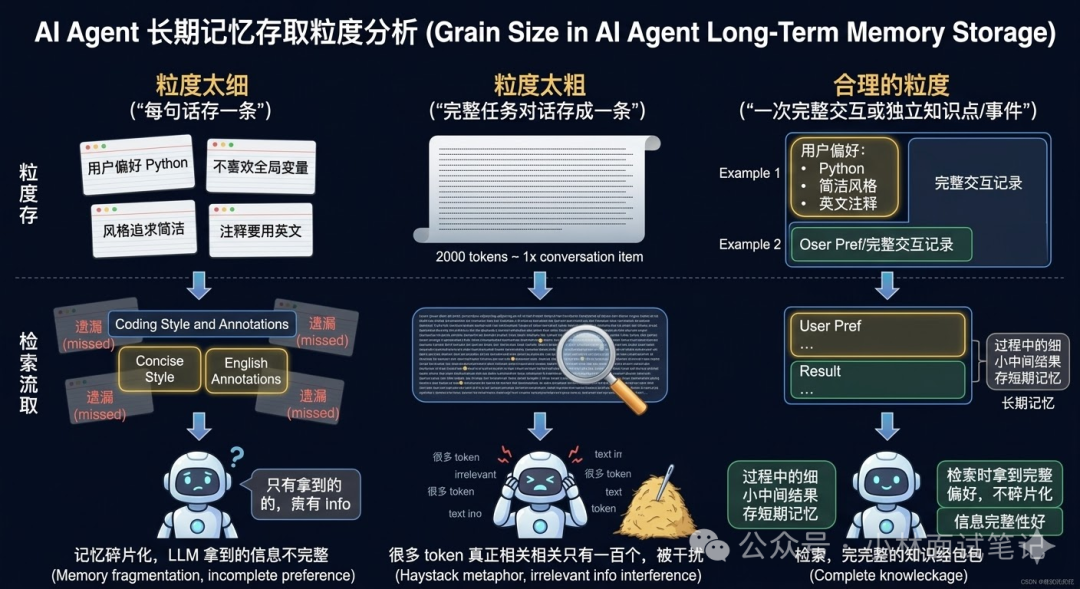
- 粒度太细(如每句话存一条):假设将用户偏好“喜欢Python、讨厌全局变量、追求简洁风格、注释用英文”拆成四条独立记忆。检索时可能只命中其中一两条,导致LLM拿到的是碎片化、不完整的用户画像。
- 粒度太粗(如整个对话存一条):假设一次长达2000个token的对话被存为一条记录。检索命中后,LLM需要从这2000个token中寻找可能仅有100个token相关的核心信息,极易被大量无关内容干扰。
合理的粒度通常介于两者之间:
- 按“一次完整交互”存储:包含用户请求和Agent最终处理结果的一个完整闭环。信息上下文完整。
- 按“一个独立知识点/事件”存储:将结构化的信息打包,例如将上述用户偏好打包为一条记录“用户编码偏好:Python,简洁风格,英文注释”。检索时一次性获得完整信息。
任务过程中的细小中间结果,通常无需存入长期记忆,留在短期记忆中即可。
双记忆系统协同工作流程
短期记忆和长期记忆并非孤立,它们在一个典型的Agent任务流程中紧密配合:
def run_agent_with_memory(user_request: str, long_term_memory, short_term_memory):
# 第一步:任务开始前,用任务描述检索长期记忆,拿出相关历史
# 这一步让 Agent「想起」和当前任务相关的历史经验和用户偏好
relevant_memories = long_term_memory.retrieve(user_request, top_k=3)
# 第二步:把检索到的长期记忆注入 system prompt
# LLM 会把这些信息当作背景知识,影响它这次任务的处理方式
system_prompt = f"""你是一个智能助手。
以下是用户的相关历史信息,请在处理任务时参考:
{chr(10).join(relevant_memories)}"""
short_term_memory.add("system", system_prompt)
short_term_memory.add("user", user_request)
# 第三步:整个任务执行过程中,靠短期记忆维持状态
# 每一步的中间结果都追加进 messages,LLM 始终知道做到哪里了
result = execute_task_with_short_term_memory(short_term_memory)
# 第四步:任务完成后,把重要结论写入长期记忆
# 这次任务产生的新知识就沉淀下来,下次可以用
if result.is_important:
long_term_memory.save(
content=result.summary,
metadata={"task_type": "coding", "timestamp": now()}
)
return result
场景还原:
- 用户首次请求:“优化我的Python代码。” Agent使用短期记忆完成任务,并将总结出的“用户偏好Python、代码简洁、英文命名”存入长期记忆。
- 几天后,用户请求:“写一个网页爬虫。” Agent在开始前,用“网页爬虫”检索长期记忆,找回了用户偏好信息。
- Agent将该偏好注入系统提示,然后在短期记忆的辅助下执行任务。最终生成的爬虫脚本自然符合用户习惯,用户体验到的是一个“了解自己”的智能助手。
总结
短期记忆是易失性的工作台,在单次任务中维持连贯性,任务结束即重置;长期记忆是持久化的档案馆,利用向量数据库和Embedding技术实现基于语义的跨会话记忆。两者在检索增强生成(RAG) 的范式下协同工作:长期记忆在任务开始时提供相关知识,短期记忆在任务执行中记录状态,任务结束后又有选择地将新知识沉淀回长期记忆。
这种分层设计巧妙地平衡了记忆的实时性、容量和持久性,是构建真正“有记性”、能持续学习的AI Agent的基石。如果你想了解更多关于人工智能或向量数据库的实践技巧,欢迎到云栈社区与更多开发者交流探讨。
 发表于 2026-4-6 11:48:34
|
查看: 131|
回复: 0
发表于 2026-4-6 11:48:34
|
查看: 131|
回复: 0
