🙋♂️ 面试官:(抬眼)来,说说 Agent 记忆压缩通常有哪些方法?
我:(一时语塞)啊?压缩?那不就是删聊天记录呗!没用的全删掉,实在不行复制粘贴精简一下……
👔 面试官:(打断)停!这叫啥方法?纯属瞎蒙。Agent记忆压缩是正经的工程问题,有标准解法,得好好说清楚。
乱答记忆压缩只会露怯。这道高频面试题的核心,在于吃透四类主流方法的原理、适用场景与工程权衡。下面我们来系统拆解。
简要回答
记忆压缩常见有四种方法:摘要压缩、滑动窗口、重要性过滤、结构化抽取。
- 摘要压缩:将长对话总结成简短的摘要。
- 滑动窗口:只保留最近 N 轮对话,超出部分直接丢弃。
- 重要性过滤:为每条对话打分,只保留分数高于阈值的重要内容。
- 结构化抽取:将对话中的关键信息(如用户偏好、决策结果)提取成结构化数据存储。
在实际项目中,摘要压缩和滑动窗口组合使用最为常见,即在滑动窗口丢弃旧对话前,先对其做一次摘要,力求在控制长度的同时不丢失关键信息。
详细解析
想象一个场景:你用一个 AI 助手协作推进复杂项目,聊了一小时,确认了技术方案、梳理了需求、做出了几个重要决策。然后某一刻,AI 突然开始“忘事”,把你早已敲定的方案搞错,重新提出已被否决的思路。你很困惑:明明刚才还在聊,它怎么就不记得了?
这个现象的根源,在于 Context Window(上下文窗口) 的限制。
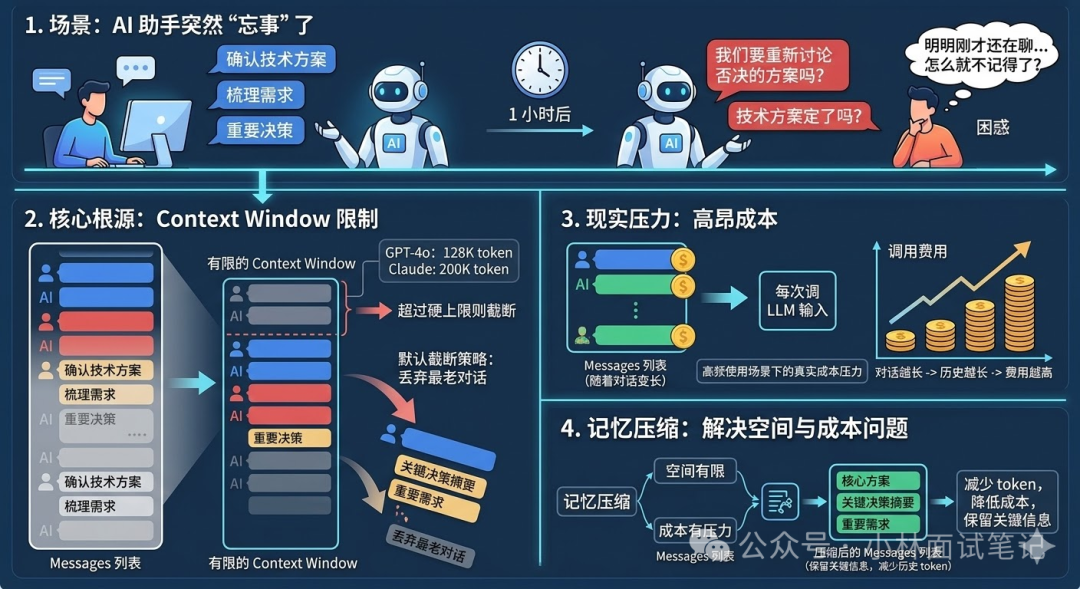
LLM(大语言模型)每次生成回答,并非像人脑拥有持续记忆。它依赖的是 “每次调用时传入的完整对话历史” 。你与它的每一轮对话,都被打包成 messages 列表传入,模型读完这些内容后才能生成下一条回复。这个 messages 列表有硬性长度上限,例如 GPT-4o 是 128K token,Claude 3 是 200K token,超出部分必须截断。默认的截断策略是“丢弃最老的对话”,于是半小时前确认的技术方案,就这么被无情抛弃了。
更现实的压力来自成本。即便未超过 token 上限,对话越长,每次调用 LLM 的费用就越高,因为你把越来越多的历史记录塞进了输入。在高频使用场景下,这是实打实的成本压力。
记忆压缩要解决的,正是“空间有限、成本高昂”这两大痛点:在保留关键信息的前提下,大幅减少历史记录所占用的 token 数量。
第一种方法:滑动窗口 (Sliding Window)
这是最符合直觉、也最粗糙的方案。
它模拟手机聊天记录只显示最近200条的逻辑:设定一个固定窗口大小 N,只保留最近的 N 轮对话,超出窗口的旧对话直接从最老的那条开始删除。
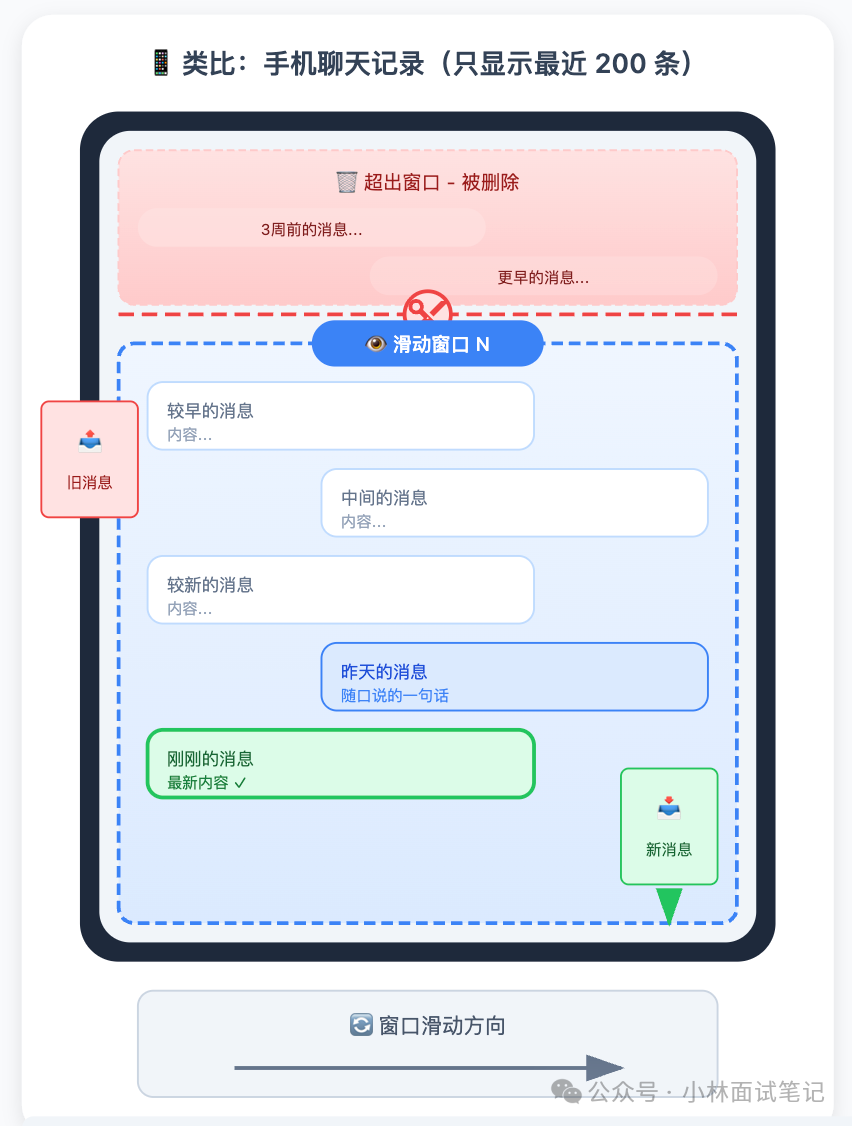
优点是实现极其简单,无需任何额外的 LLM 调用,没有额外开销。缺点是“硬截断”,对话内容按时间一刀切。三周前确认的关键决策和昨天随口说的一句闲聊,在这个方案里被同等对待——一旦超出窗口,统统消失。
可以将其概括为 “金鱼记忆” :只记得最近的事,越往前越模糊,再久远则彻底遗忘。对于短对话或历史信息不重要的场景,这个最低成本的方案足够用。在构建复杂的 系统设计 时,它常作为基础组件。
第二种方法:摘要压缩 (Summarization Compression)
这是对滑动窗口“硬截断”的智能改进。核心思路是:不直接丢弃即将超出窗口的历史,而是先让 LLM 把这段历史总结成一段精华摘要,然后用这份摘要替换原始的长篇对话,再继续前进。
类比一下:你的笔记本快写满了,你不会把前半本直接撕掉,而是先把前半本的要点整理成一页纸的精华总结。之后,你把这页总结放在最前面,继续记录新内容。虽然不如原版详细,但关键脉络得以保留。

代价是细节丢失。LLM 在总结时,会依据其判断的“重要性”决定保留或省略哪些内容。有些当时看似不重要的细节被略过后,若后续恰好需要,便无法找回。
此方案单独使用时,通常采用 “旧的压缩成摘要,近的保持完整” 的策略,因为最近几轮对话往往与当前任务关系最密切。
最常见的工程组合:滑动窗口 + 摘要
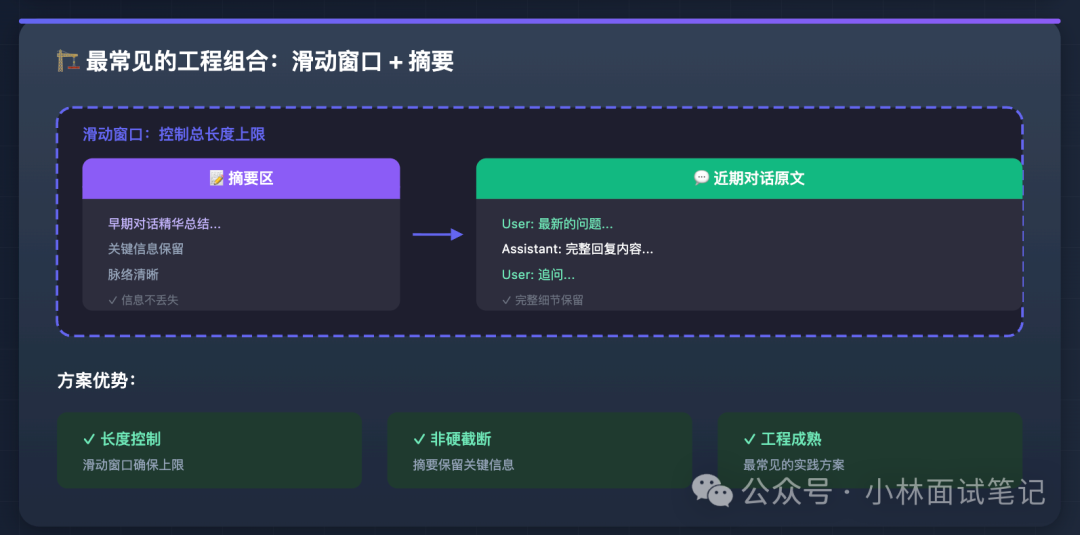
在实际工程中,这两种方法通常组合使用,而非单独使用。滑动窗口负责严格控制对话历史的总长度上限,摘要压缩则负责在历史被窗口丢弃之前做一次提炼,尽可能保留关键信息。这样既实现了长度控制,又避免了粗暴的硬截断,是当前最成熟、最常见的工程实践方案。
第三种方法:重要性过滤 (Importance Filtering)
滑动窗口和摘要压缩有一个共同思路:都沿着 “时间维度” 处理历史,按发生先后决定去留。但时间先后不等于重要性高低。三周前的一句关键决策,其价值可能远高于昨天的几句闲聊,但在滑动窗口中它却会因“年长”而被优先丢弃。
重要性过滤转换了视角:按内容的实际价值决定去留。为每条对话记录计算一个重要性分数,低于设定阈值的淘汰,高分则保留。
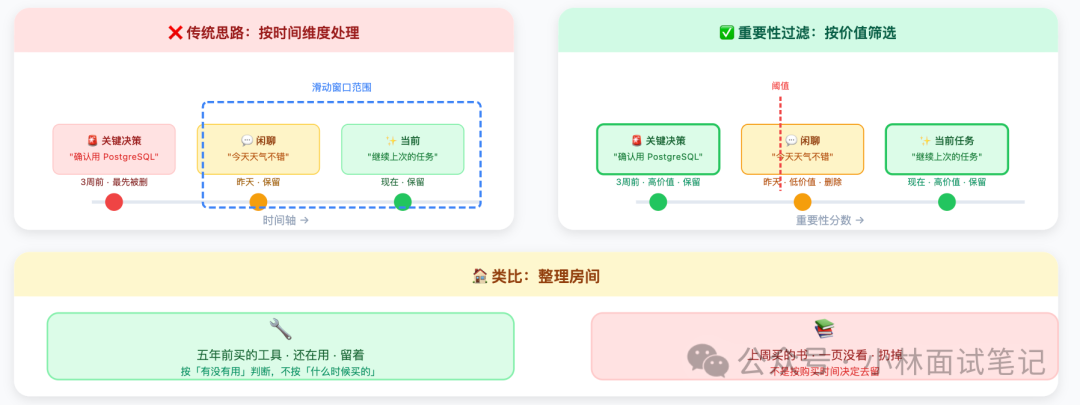
类比整理房间:你不会按购买时间决定扔什么,而是按 “这东西现在还有没有用” 来判断。五年前买但仍在用的工具,留着;上周买但一页未读且不打算读的书,可以扔。
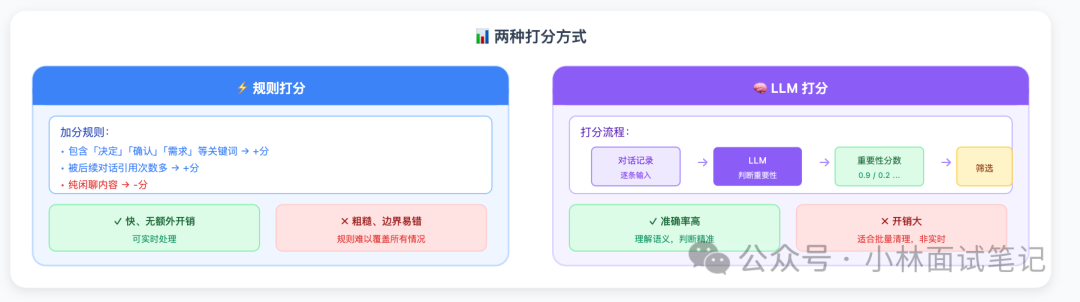
打分方式主要有两种:
- 规则打分:设定一套规则,例如包含“决定”、“确认”、“需求”等关键词的记录加分;被后续对话引用次数多的加分;纯闲聊内容减分。优点是速度快、无额外计算开销,可实时处理。缺点是规则粗糙,边界情况易误判。
- LLM打分:将对话记录输入给 LLM,让其直接判断重要程度并输出分数。优点是准确率高,能理解语义,判断精准。缺点是每条记录都需调用一次 LLM,开销大,通常用于非实时的批量历史清理。
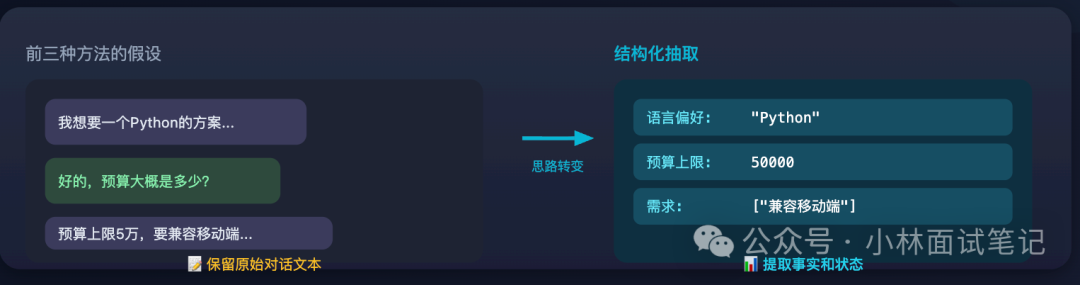
前三种方法有一个共同前提:历史信息最好以 “原始对话文本” 的形式保留。结构化抽取的思路则截然不同,它先追问一个更本质的问题:我们真的需要保留对话文本本身吗?
在许多场景中,真正有价值的并非对话文字,而是其中传递的事实和状态。例如:“用户偏好使用 Python”、“预算上限是5万”、“已确认采用方案B”、“需要兼容移动端”。主动将这些信息提取出来,存储为结构化的字段(如 preference: Python, budget: 50000),后续注入 prompt 时直接使用这些字段,远比传送一大段原始对话文本更高效,信息密度也高得多。
类比医生记录病历:医生不会逐字记录与病人的所有对话,而是整理成结构化的病历档案——“主诉:头痛三天,现病史:无发热,过敏史:青霉素,初步诊断:紧张性头痛”。这份档案的信息密度远高于原始录音,下次就诊时医生直接阅读病历即可,无需重听全程录音。

此方案的信息损失理论上最小,只要字段定义合理,重要信息能被精确保留,没有摘要带来的模糊化问题。代价是开发成本最高:需要预先定义“哪些是重要字段”,这要求对业务场景有深入理解。此外,通用性较低,不同类型的任务所需的字段结构可能完全不同。
四种方法的关系梳理
这四种方法并非互斥或按优劣线性排列,而是从三个不同维度解决问题:
- “历史太长,怎么截?”:滑动窗口(直接截)和摘要压缩(截前先提炼)回答此问题。
- “内容不等价,怎么挑?”:重要性过滤回答此问题,打破时间顺序,按价值筛选。
- “对话文本本身是最佳载体吗?”:结构化抽取回答此问题,换用更高密度的形式存储信息。
这三个维度可以灵活组合。例如,先用重要性过滤筛掉低价值闲聊,再用摘要压缩处理剩余的中等价值历史,同时对最高价值的决策点进行结构化抽取。实际系统中,往往是多种方法配合使用。
Prompt Caching:在“计算层”的互补手段
除了上述“信息层”的压缩策略,还有一个工程上值得了解的“计算层”优化技术——Prompt Caching,Anthropic 的 Claude 和 OpenAI 等均已支持。
理解它之前,需知一个背景:LLM 每次处理请求,都需要把输入的所有 token “过一遍模型”进行计算,此过程称为 prefill,是产生延迟和成本的主要环节之一。一个常见场景是:你有一段固定的 system prompt 加上不断增长的对话历史,每次调用时,哪怕历史内容与上次完全相同,这段前缀也需要被重新计算一遍。
Prompt Caching 的思路是:如果 prompt 的前缀部分在多次请求间完全一致,就将这部分的计算结果缓存起来。下次请求若前缀匹配,则直接复用缓存,跳过重新计算。这能大幅降低费用和延迟,在某些场景下可降至原来的十分之一。
这与记忆压缩是两个不同层次的优化:
- 记忆压缩在 “信息层” 工作,决定哪些内容值得被保留在历史中。
- Prompt Caching在 “计算层” 工作,对已决定保留的内容减少重复计算的开销。
两者解决的不是同一问题,可以同时使用,是互补关系,而非替代。
工程实践决策参考
如何选择方案?可参考以下思路:
- 对话不长、业务简单:滑动窗口足够,实现成本最低。
- 对话会很长、不希望硬截断:摘要压缩 + 滑动窗口的组合是最稳健的工程选择。
- 业务有明确定义的“关键信息”(如用户偏好、确认事项):结构化抽取信息密度最高,效果最好。
- 高频调用、长prompt、成本敏感:Prompt Caching 的收益非常可观,值得优先考虑。
- 需要精细化管理历史价值:可引入重要性过滤,或作为预处理步骤与其他方法结合。
掌握这些方案的原理与权衡,不仅能让你在面试求职的战场上应对自如,更是构建高效、可靠智能 Agent 系统的关键。对于更深入的 Agent 开发与架构设计讨论,欢迎在 云栈社区 与更多开发者交流碰撞。
 发表于 2026-4-6 11:53:43
|
查看: 191|
回复: 0
发表于 2026-4-6 11:53:43
|
查看: 191|
回复: 0
