本文概要
在量化投资领域,单一模型常常难以兼顾市场中不同风格(如市值、行业)股票的特性差异,导致预测结果趋于平庸。本文介绍的 MIGA (Mixture-of-Experts with Group Aggregation) 框架为解决这一问题提供了新思路。
该框架的核心是引入了分组机制的混合专家 (MoE) 架构。它首先利用一个路由器网络对股票的横截面特征进行编码,并动态计算分配给不同专家的权重。在预测阶段,系统会激活被选中的少数专家。最关键的是,MIGA 在专家组内部引入了多头自注意力机制,使得同组专家能够共享和学习风格相近股票的信息,从而实现更精准的“分风格”预测。
作者在 CSI300、CSI500 和 CSI1000 这三大中国A股指数上验证了框架的有效性,并基于三种主流编码器实现了 MIGA-Conv、MIGA-Rec 和 MIGA-Attn 三个变体。实验结果显示,MIGA-Conv 在 CSI300 指数上取得了 24% 的年化超额收益,相比现有的最佳模型提升了约 8 个百分点。后续的消融研究进一步证实,专家数量与组内注意力模块是提升模型预测稳定性和最终收益的关键。
背景知识
1. 混合专家(MoE)架构
混合专家模型通常由两部分组成:一个路由器和若干个专家网络。路由器根据输入样本的特征,动态地计算并分配权重给不同的专家;每个专家则独立地进行预测或特征提取;模型的最终输出是所有专家预测的加权汇总。
MoE 的精髓在于其稀疏激活机制:对于每个输入,实际上只有少数几个专家(Top-K)被激活并参与计算。这样既保持了模型整体的巨大容量(参数量),又有效控制了单次推理的计算成本。这一特性使其在自然语言处理和计算机视觉的大模型中得到了广泛应用。经典的实现会使用 Top-K 选择与负载均衡损失来避免“路由崩塌”(即路由器总是倾向于选择同一个专家)。MIGA 继承了这一思想,并创新性地引入了组内注意力来增强专家之间的协同能力。
2. 股票因子与端到端预测
在量化领域,我们通常使用数百个因子(如估值、动量、财务质量等)来描述一只股票。传统的预测方法多采用线性回归或梯度提升决策树 (GBDT)。近年来,TCN、LSTM、Transformer 等端到端神经网络被直接用于建模股票的历史序列和横截面信息。
然而,一个显著的挑战在于,不同市值、不同行业、不同波动性水平的股票,其特征分布存在巨大差异。使用单一模型去拟合所有股票,很容易导致模型对某些风格欠拟合,或者为了“照顾大局”而做出过于平均化的预测。MIGA 框架通过设计专注于不同风格的专家,旨在精准打击这一痛点。
3. 信息系数(IC)与投资绩效衡量
在评价预测模型时,信息系数(IC)是一个核心指标,它计算的是模型预测的股票收益与次日真实收益之间的日度皮尔逊相关系数。RankIC 则使用斯皮尔曼秩相关系数,对异常值更不敏感。为了衡量预测的稳定性,通常会进一步计算 ICIR (Information Coefficient Information Ratio) 和 RankICIR,即用 IC 或 RankIC 除以其标准差。
在组合层面,则使用超额年化收益(AR)和信息比率(IR)来评估经过风险调整后的表现。MIGA 在训练时,直接将负的 IC 作为核心损失函数的一部分,同时结合路由器的负载均衡损失,从优化目标上就强化了预测的相关性与未来组合收益之间的联系。
本文方法
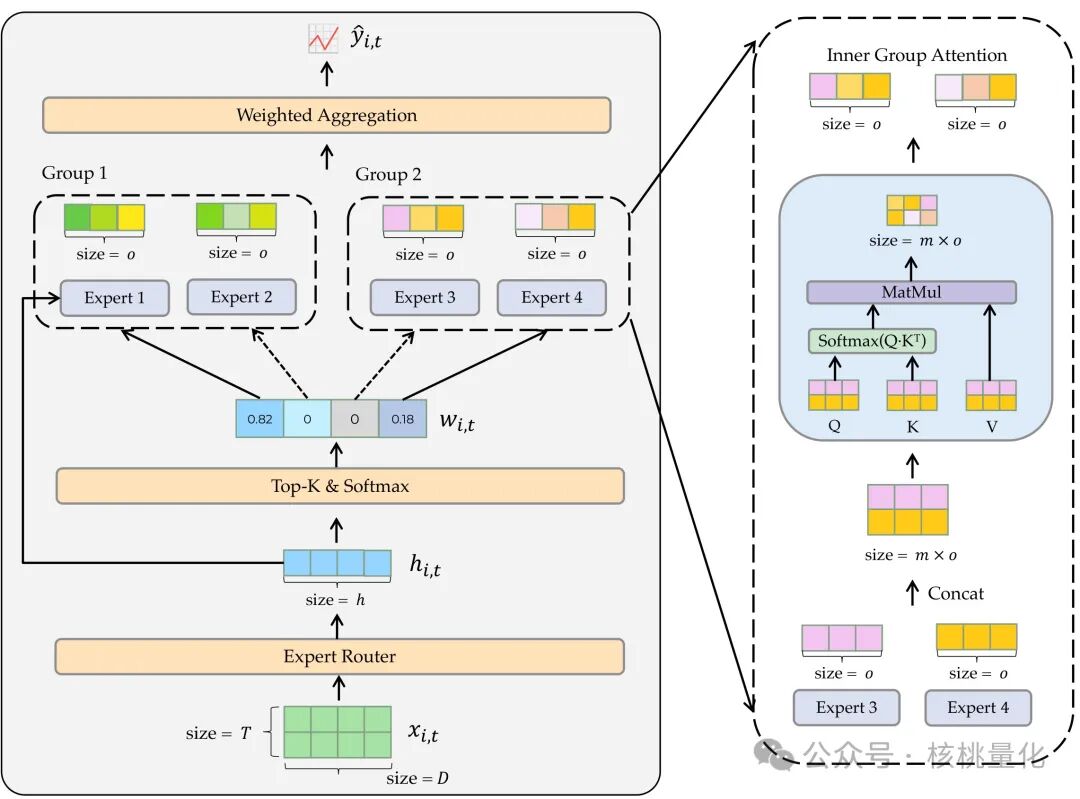
3.1 总体架构
MIGA 采用清晰的“两阶段”流程:
-
路由阶段:一个端到端的编码器(可以是 TCN、LSTM 或 Transformer)对长度为 $T$ 的股票特征序列 $x_{i,t}$ 进行时空建模,输出一个隐藏表示 $h_{i,t}$。随后,该表示经过一个线性变换层,并通过 Top‑k 函数甄选出权重最大的 $k$ 个专家,最终通过 Softmax 得到归一化的专家权重 $w_{i,t} = \text{softmax}(\text{TopK}(h_{i,t}))$。
-
专家阶段:模型包含 $|G|$ 个专家组,每个组内有 $|E|$ 个专家(均为线性层)。对于被选中的专家,其输出为 $o_{i,t} = \text{Expert}(h_{i,t})$。紧接着,组内多头自注意力模块开始工作:将同组内所有被激活专家的输出进行拼接,并作为 Query (Q), Key (K), Value (V) 输入:
$\bar{O}_{i,t} = \text{MHSA}(Q_{i,t}, K_{i,t}, V_{i,t})$
经过注意力机制的信息融合后,模型的最终预测是所有激活专家输出的加权和:
$\hat{y}_{i,t} = \sum_{j=1}^{|G|} \sum_{k=1}^{|E|} w_{j,k}^{i,t} \cdot \bar{o}_{j,k}^{i,t}$
3.2 损失函数
MIGA 的损失函数由两部分组成:
-
专家损失:以最小化负的信息系数为目标,直接优化预测相关性。
$L_{\text{Expert}} = -\frac{1}{|T|} \sum_{t \in T} \frac{\text{cov}(Y_t^{\text{pred}}, Y_t^{\text{label}})}{\sqrt{\text{var}(Y_t^{\text{pred}}) \text{var}(Y_t^{\text{label}})}}$
-
路由器负载均衡损失:鼓励路由器均衡地使用各个专家,避免坍缩。
$L_{\text{Router}} = \sum_{t,i} (h_t^i - \text{mean}(h_t^i))^2$
-
联合目标:
$L_{\text{MIGA}} = \alpha L_{\text{Router}} + \beta L_{\text{Expert}}$
其中 $\alpha = 2 \times 10^{-3}, \beta = 1$。
3.3 关键设计
- 专家分组与组内注意力:这是 MIGA 的核心创新。与彼此独立的专家相比,将专家分组并引入组内注意力,可以让模型在同属一种风格的股票间共享和学习那些稀疏但重要的特征模式,从而显著提高预测的稳健性和泛化能力。
- 稀疏激活:路由器每次只激活少数专家(如 Top-8),使得模型在推理时的计算开销与单个大模型相近,保持了高效率。
- 多编码器路由器:为了证明框架的通用性,作者实现了基于卷积 (Conv)、循环网络 (Rec) 和自注意力 (Attn) 的三种路由器。实验表明,MIGA-Conv 在捕捉股票价格局部模式方面表现最为高效。
3.4 训练实现
实验在 NVIDIA A100-80GB GPU 上使用 PyTorch 完成,共训练 60 个 epoch。输入的历史窗口 $T = 5$ 个交易日,并采用了早停策略。经过调参,专家组合的最佳配置为 7 个组,每组 9 个专家,采用 Top-8 稀疏路由。
实验分析
4.1 实验设置
数据涵盖 2014年1月1日至2024年7月25日的A股全市场626个因子,按时间顺序划分为训练集、验证集和测试集。构建投资组合的策略是:每日买入预测排名前 5% 的股票,同时卖空排名后 5% 的股票。评价指标包括 IC、RankIC 及其对应的 IR,以及多头和多空组合的 AR 与 IR。
4.2 结果与讨论
-
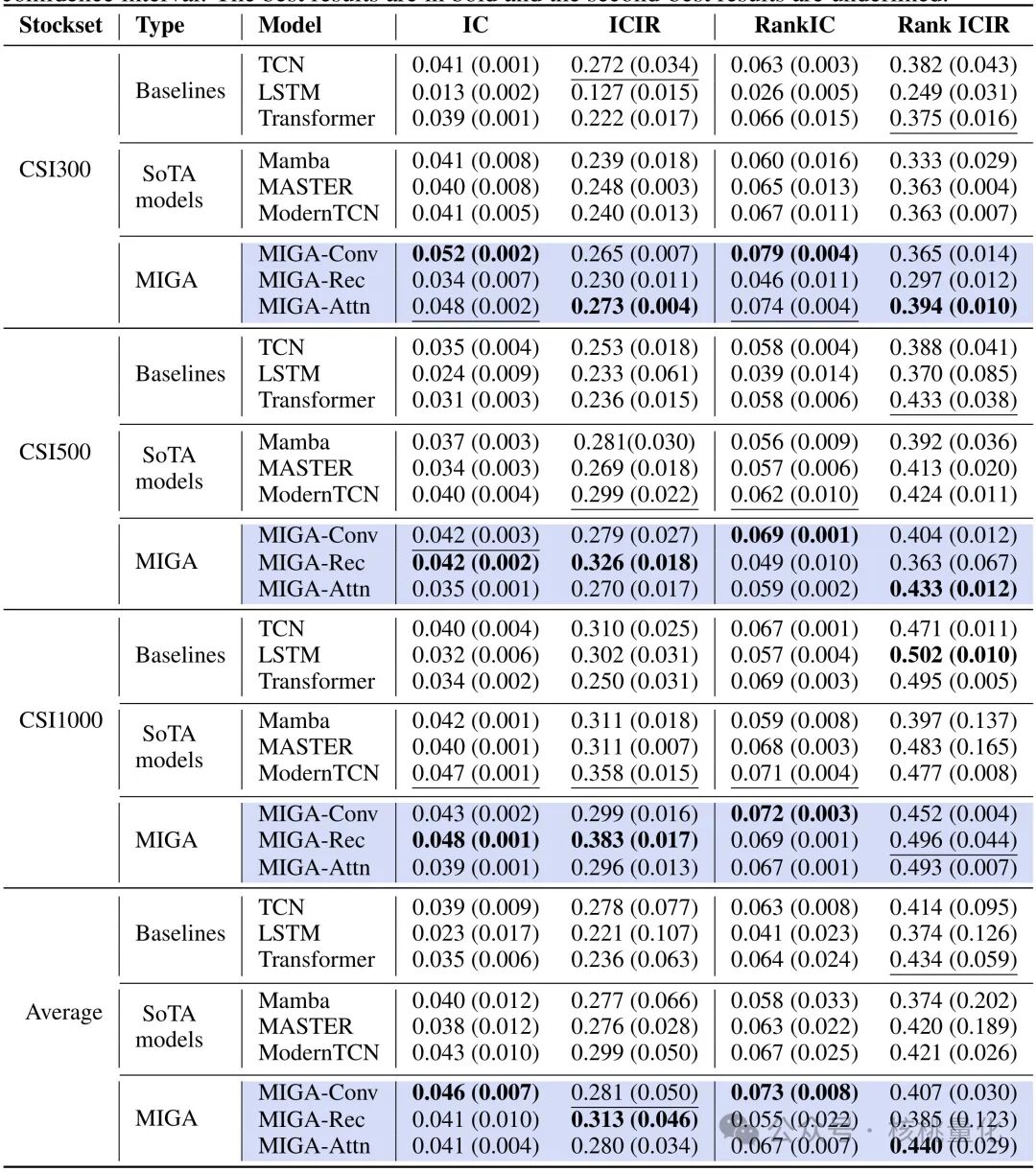
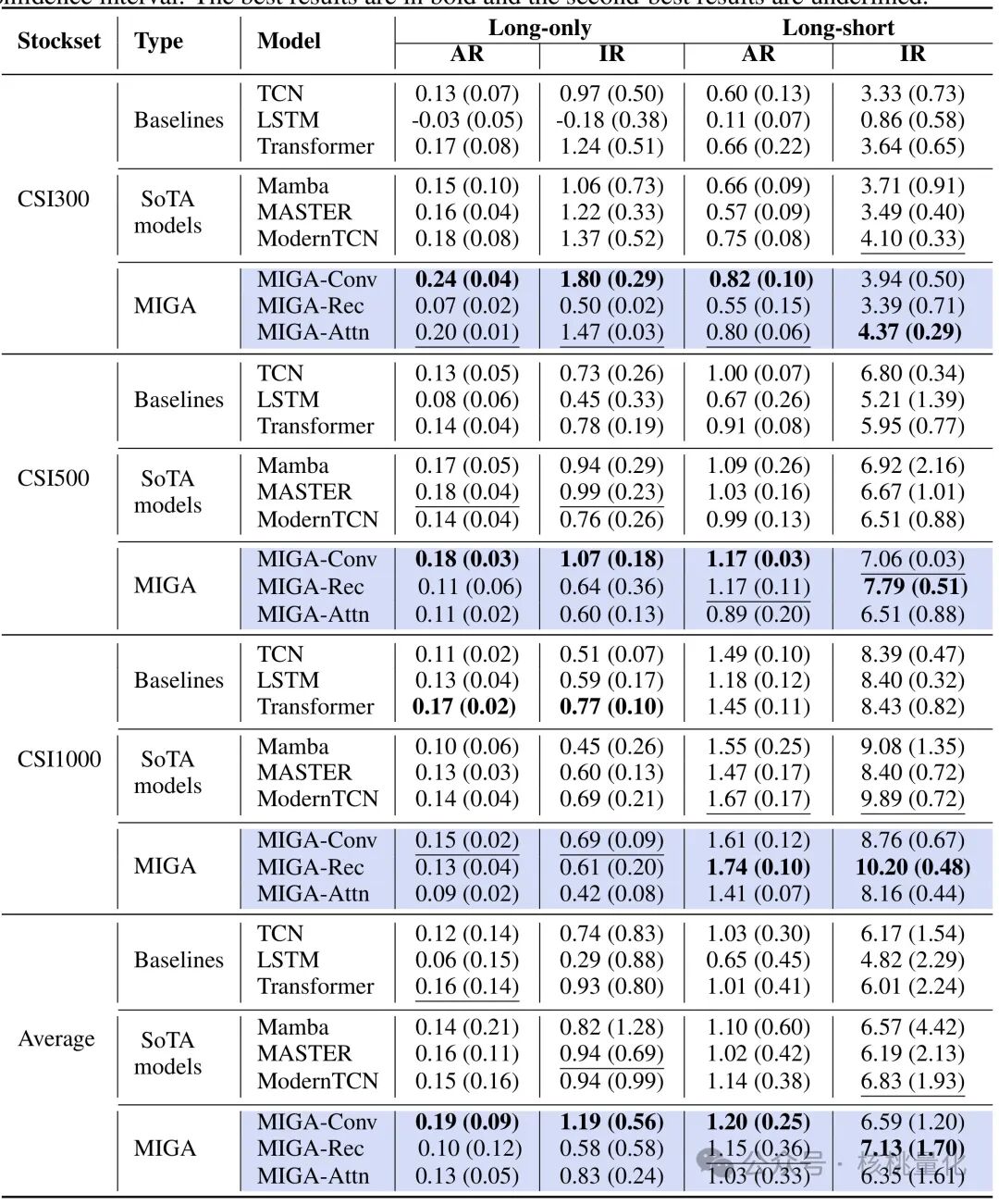
整体表现:在覆盖三个数据集的共 29 项指标排名中,MIGA 系列模型取得了 15 项第一和 14 项第二的优异成绩,显著超越了 ModernTCN、Mamba、MASTER 等当前先进的 SoTA 模型。
-
收益提升:具体来看,MIGA-Conv 在 CSI300 指数的纯多头组合中实现了 24% 的年化超额收益和 1.80 的信息比率,明显优于 ModernTCN 的 0.18 / 1.37。
-
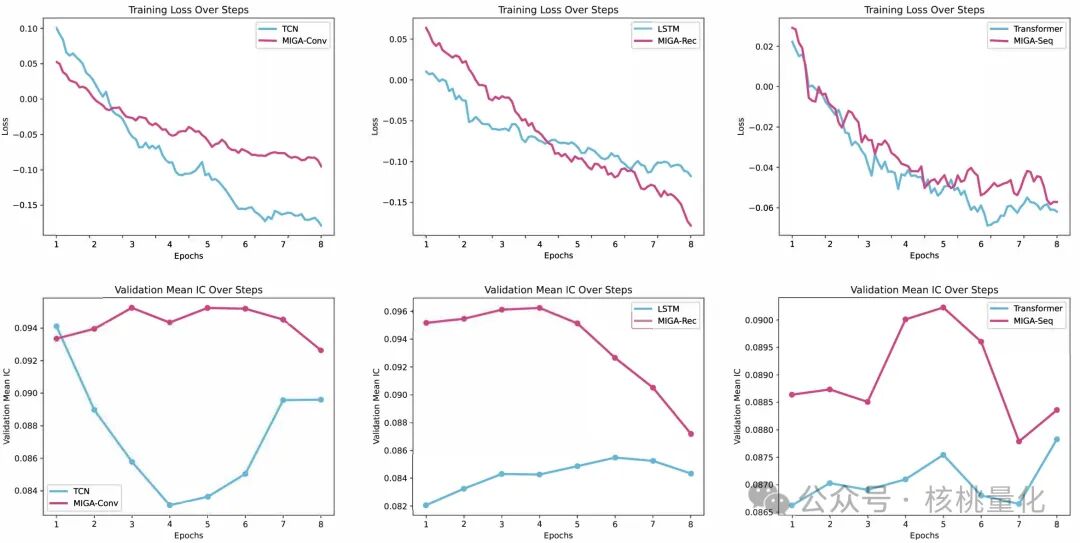
泛化能力:下图展示了训练早期的损失和验证集 IC 变化。可以看到,虽然 MIGA 的训练损失与对应的单模型接近,但其验证集上的 IC 值明显更高,这说明 MIGA 对未见过的样本具有更强、更一致的预测能力。
-
消融研究:
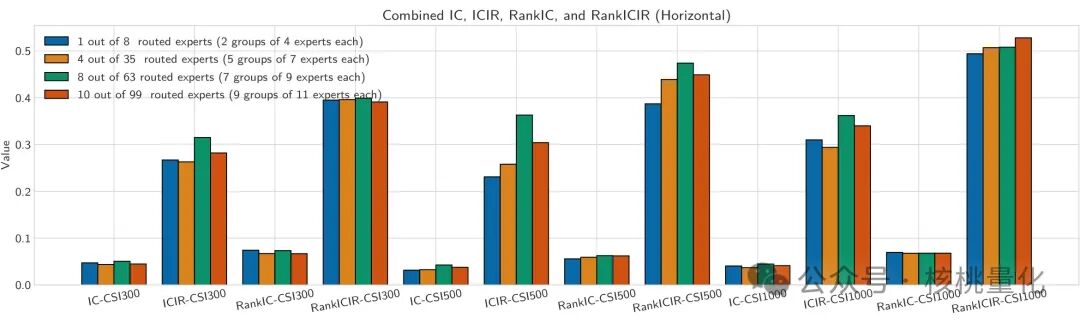
- 专家数量:下图研究了不同专家数量配置(如 8/63, 即从63个专家中激活8个)对性能的影响。结果显示,Top-8/63 的配置在 12 项关键指标中的 8 项上达到最优。继续增加激活专家数量虽然可能略微提升 ICIR,但由于权重被稀释,对最终收益的边际提升有限。
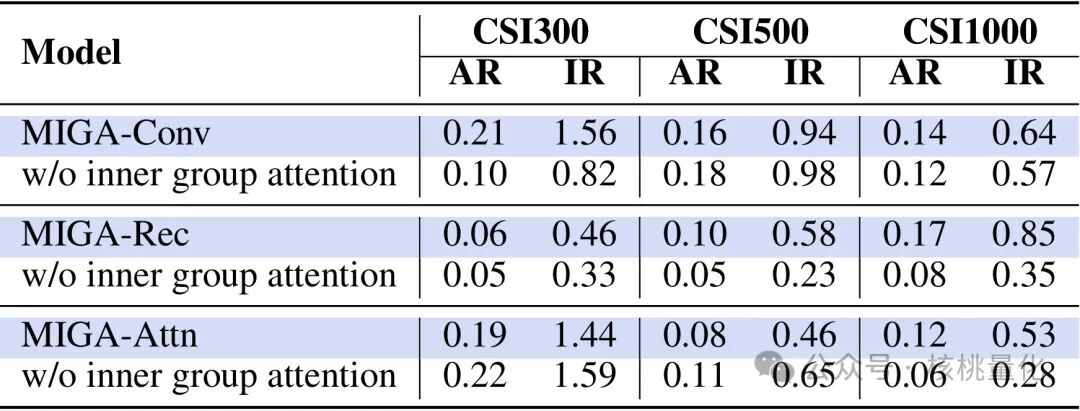
- 组内注意力:下表清晰地展示了移除组内注意力模块带来的性能下降。在三个MIGA变体上,去除该模块后,AR 和 IR 普遍下降了 5% 到 12%,有力证明了组内信息共享的必要性。
总结展望
MIGA 框架通过稀疏激活的分组专家与组内注意力机制的巧妙结合,成功实现了对多风格股票的差异化精准预测,在显著提升预测收益的同时也增强了模型的稳定性。其可插拔的路由器设计也证明了该框架能够兼容多种不同的时序编码器,具有良好的通用性。
这项研究为混合专家模型在量化投资领域的应用打开了新的大门。未来的工作可以从以下几个方向展开:
- 引入多模态信息(如财经新闻、市场舆情、宏观因子)来进一步丰富和增强专家的特征表示。
- 探索自适应的专家数量与组结构机制,让模型能够根据数据复杂度和计算预算动态调整,自动平衡性能与效率。
- 将 MIGA 框架应用到高频交易、期权定价等更复杂的金融场景中,并结合具体的风险约束来设计和优化训练目标。
对这类结合前沿人工智能算法与金融实战的深度内容感兴趣?欢迎在云栈社区与我们继续交流探讨。
 发表于 2026-4-7 01:58:26
|
查看: 133|
回复: 0
发表于 2026-4-7 01:58:26
|
查看: 133|
回复: 0
