由于其非线性和高度复杂的特性,准确预测股票市场一直是个极具挑战性的问题。尽管存在不少关于股市预测的综述,但它们大多聚焦于传统的机器学习方法,对近年来占据主导地位的深度学习技术关注不足。
为了填补这一空白,本文对2011年至2022年间94篇高质量论文进行了结构化梳理,旨在提供一份以深度学习技术为核心的、全面而深入的股市预测研究概览。我们不仅系统性地总结了最新的深度神经网络模型,还详细分析了常用的数据集与评估指标,并分享了关于该领域未来发展方向的前瞻性思考。
本文的主要贡献
- 全面的任务定义与论文统计:首次明确了股市预测的四个核心子任务(股票走势预测、股价预测、投资组合管理与交易策略),并基于此对94篇相关论文进行了详尽的统计分析。
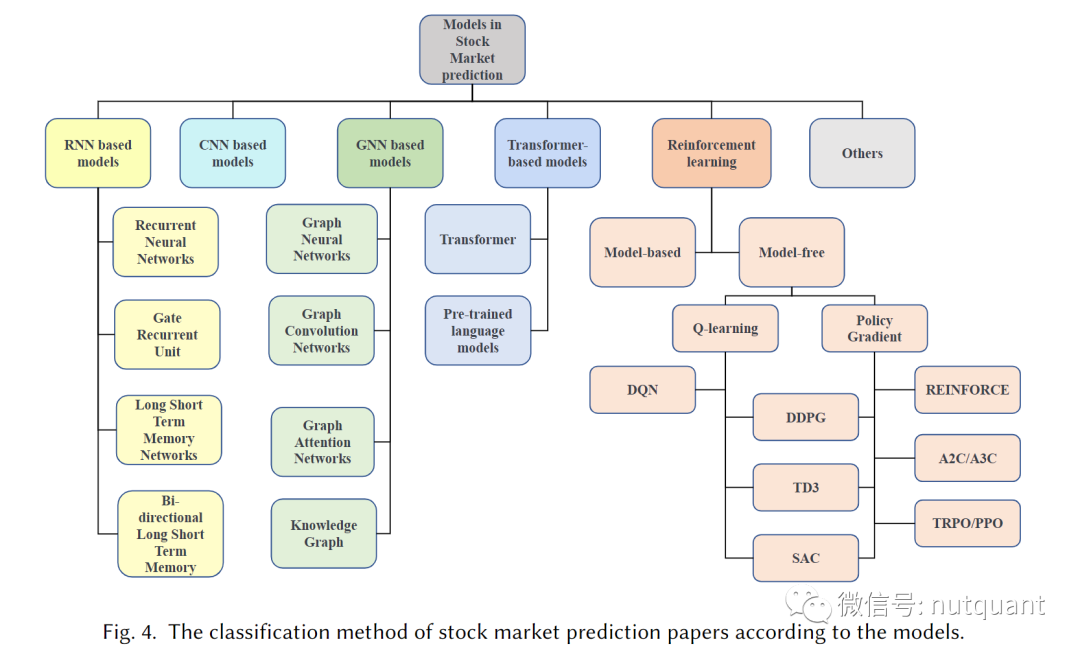
- 清晰的深度学习模型分类法:提出了一种新的深度学习模型分类体系,涵盖了基于RNN、CNN、GNN、Transformer以及强化学习(RL)的各类模型,并总结了它们的输入数据与评估方法。
- 对开放性问题与未来方向的深度探讨:不仅梳理了现有成果,更指出了当前研究中的若干尚未解决的关键问题,并为该领域的未来发展提供了有价值的思考方向。
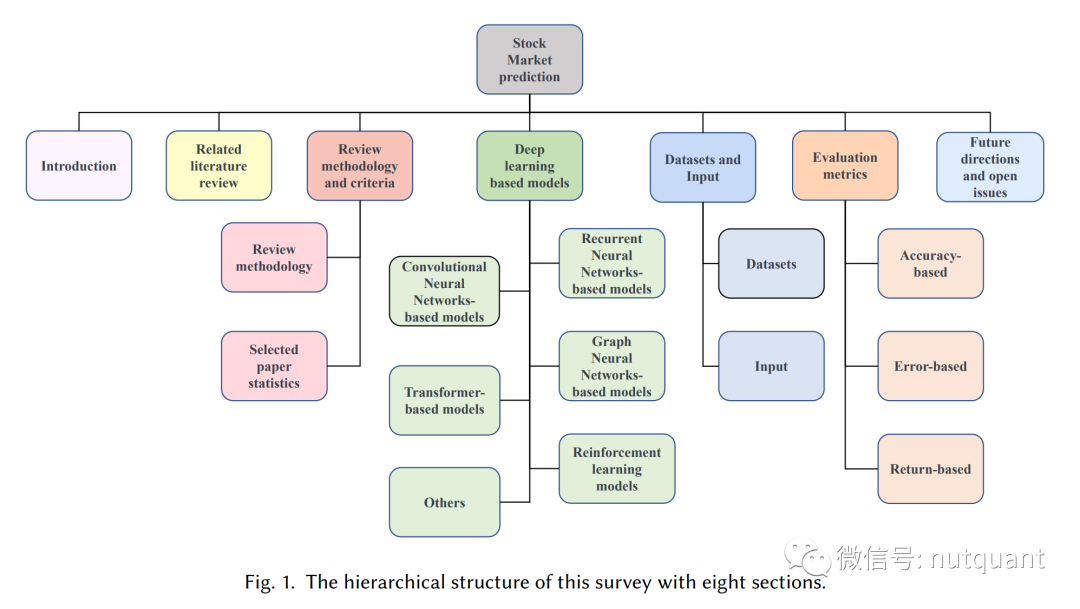
股市预测的核心任务与通用流程
在深入算法细节之前,我们首先界定四个主要的股市预测任务:
- 股票价格预测:旨在预测未来某一时间点的具体股票价格,属于回归问题。
- 股票趋势预测:将未来走势分类为上涨、下跌或横盘,属于分类问题。
- 投资组合管理:核心是资产配置,旨在给定风险水平下最大化投资组合的整体回报。
- 交易策略:制定系统化的买入/卖出规则,通常基于技术指标、基本面分析或市场情绪。
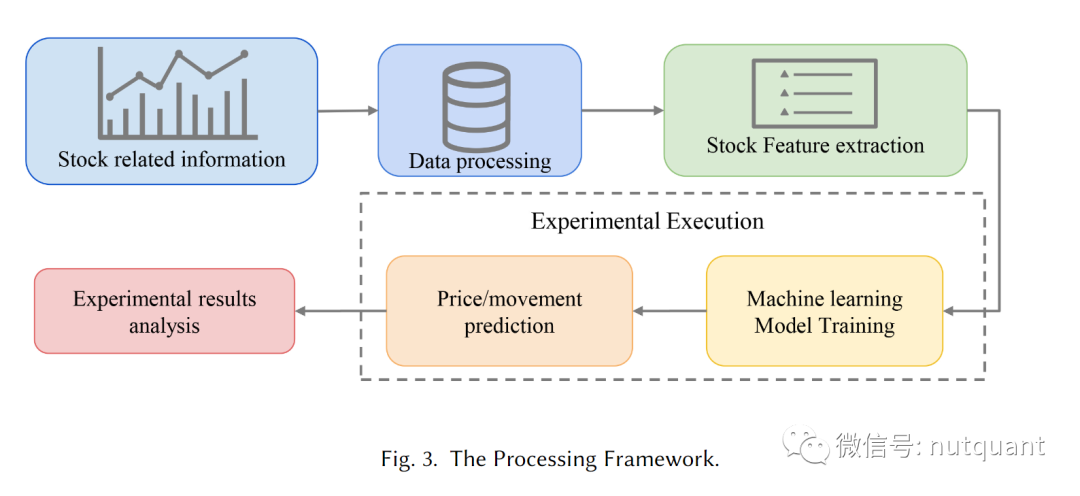
基于深度学习的股市预测通常遵循一个通用流程,如下图所示:
深度学习模型架构全景图
我们根据模型类型对所综述的论文进行了分类,主要涵盖以下五大类及一些其他创新方法。下图清晰地展示了这些模型类别及其细分:
为了更直观地理解,下图展示了这五类核心模型的通用架构草图:
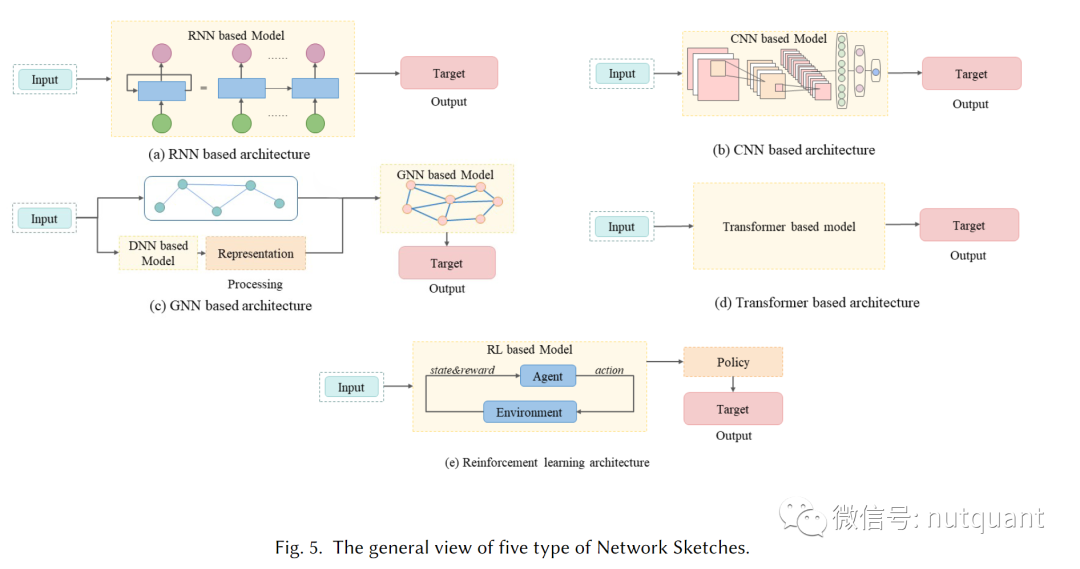
1. 递归神经网络(RNN)
RNN因其处理序列数据的天然能力,在股价时间序列预测中被广泛应用。为了克服标准RNN在处理长期依赖时的梯度消失问题,LSTM、GRU及其变体成为了主流。研究通常有两种思路:一是仅使用历史价格数据;二是融合价格与新闻等文本数据。例如,有工作提出了结合RNN、指数平滑和ARMA的混合预测模型,并使用遗传算法优化权重;还有研究利用状态频率记忆(SFM)来捕捉股价背后的多频交易模式。
2. 卷积神经网络(CNN)
虽然CNN最初为图像处理设计,但其在提取局部特征上的优势也被用于金融时间序列和文本分析。例如,有研究者使用CNN从历史事件嵌入中提取代表性特征。更多的研究将CNN与LSTM结合,用CNN捕捉空间或局部特征,再用LSTM建模时间依赖,如CNN-LSTM、CNN-BiLSTM等混合模型,在股价预测中表现出色。
3. 图神经网络(GNN)
股票市场中,公司之间存在着复杂的关联(如供应链、股权关系)。GNN非常适合对这种图结构数据进行建模。输入的图数据可以来自知识图谱(表示公司实体关系)、社交网络或直接构建的股票关联图。例如,有研究利用知识图谱整合公司信息,通过GNN进行预测;还有工作设计了层次图神经网络(HGNN)来处理股票价格限制问题。
凭借其强大的自注意力机制,Transformer在捕捉长序列依赖关系方面表现卓越。在股市预测中,它不仅用于处理价格序列,更在融合多模态信息(如文本新闻、社交媒体情绪甚至音频数据)方面展现出潜力。例如,有研究提出了多Transformer模型来提升股价波动率预测的稳定性;还有工作利用Transformer编码器同时处理历史文本和价格数据,以挖掘隐藏信息。
5. 强化学习(RL)
强化学习通过与环境的交互来学习最优策略,非常适合于交易策略制定和投资组合管理这类决策问题。在金融交易场景中,市场被视为环境,交易算法是智能体(Agent),交易动作(买/卖/持有)是行动(Action),损益是奖励(Reward)。
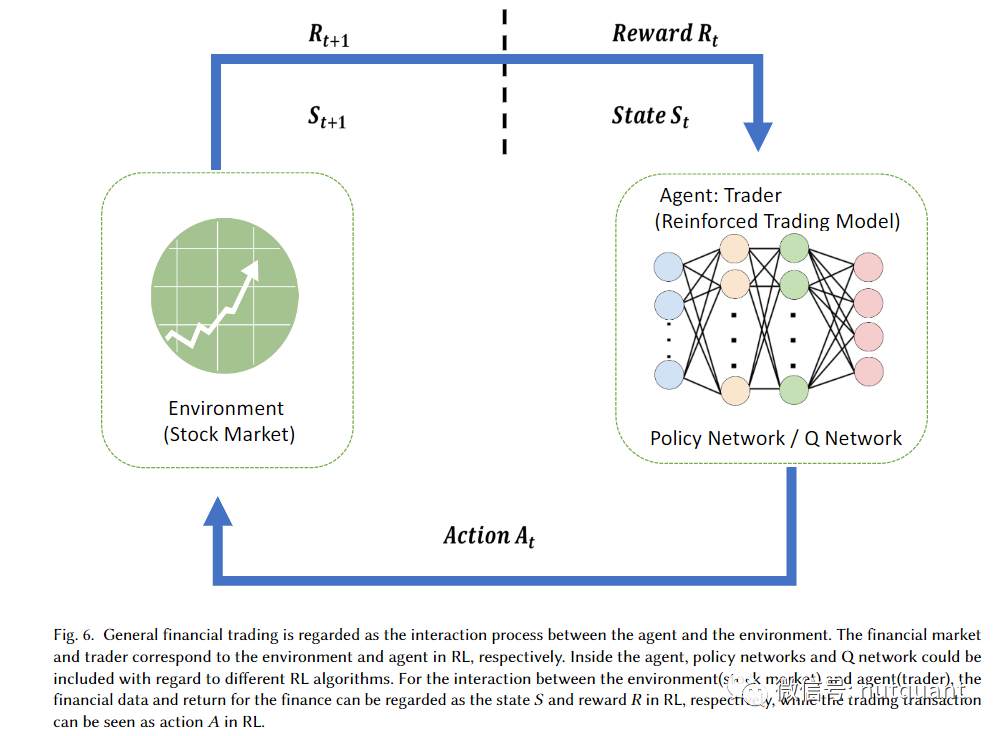
研究探索了多种RL算法,包括策略梯度方法(如REINFORCE)、演员-评论家方法(如A2C/A3C、DDPG)以及值函数方法(如DQN)。例如,有研究对比了DDPG、PPO和REINFORCE在对抗性训练中的表现;还有工作开发了基于确定性策略梯度(DPG)的框架,结合CNN/RNN进行投资组合管理,并在加密货币市场上验证了有效性。近年来,旨在实现金融场景中深度强化学习算法快速原型的FinRL等库也推动了该领域的发展。
数据集与模型输入
常用数据集
研究使用的数据可分为两大类:
- 内部数据:直接从市场获取,如历史价格、成交量、技术指标(均线、RSI等)。
- 外部数据:包括宏观经济数据(GDP、CPI)、公司基本面、新闻文本、社交媒体舆情、行业知识图谱等。
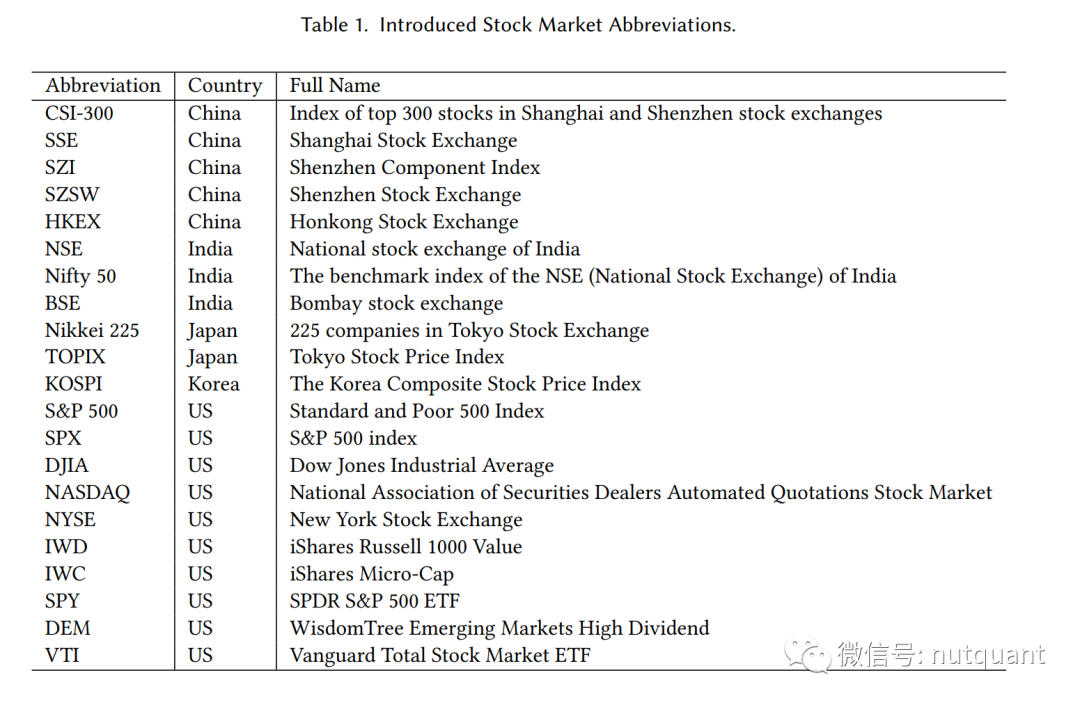
数据集的时间跨度从数月到十年不等,覆盖全球多个主要股票市场。下表列出了一些常见的股票市场缩写:
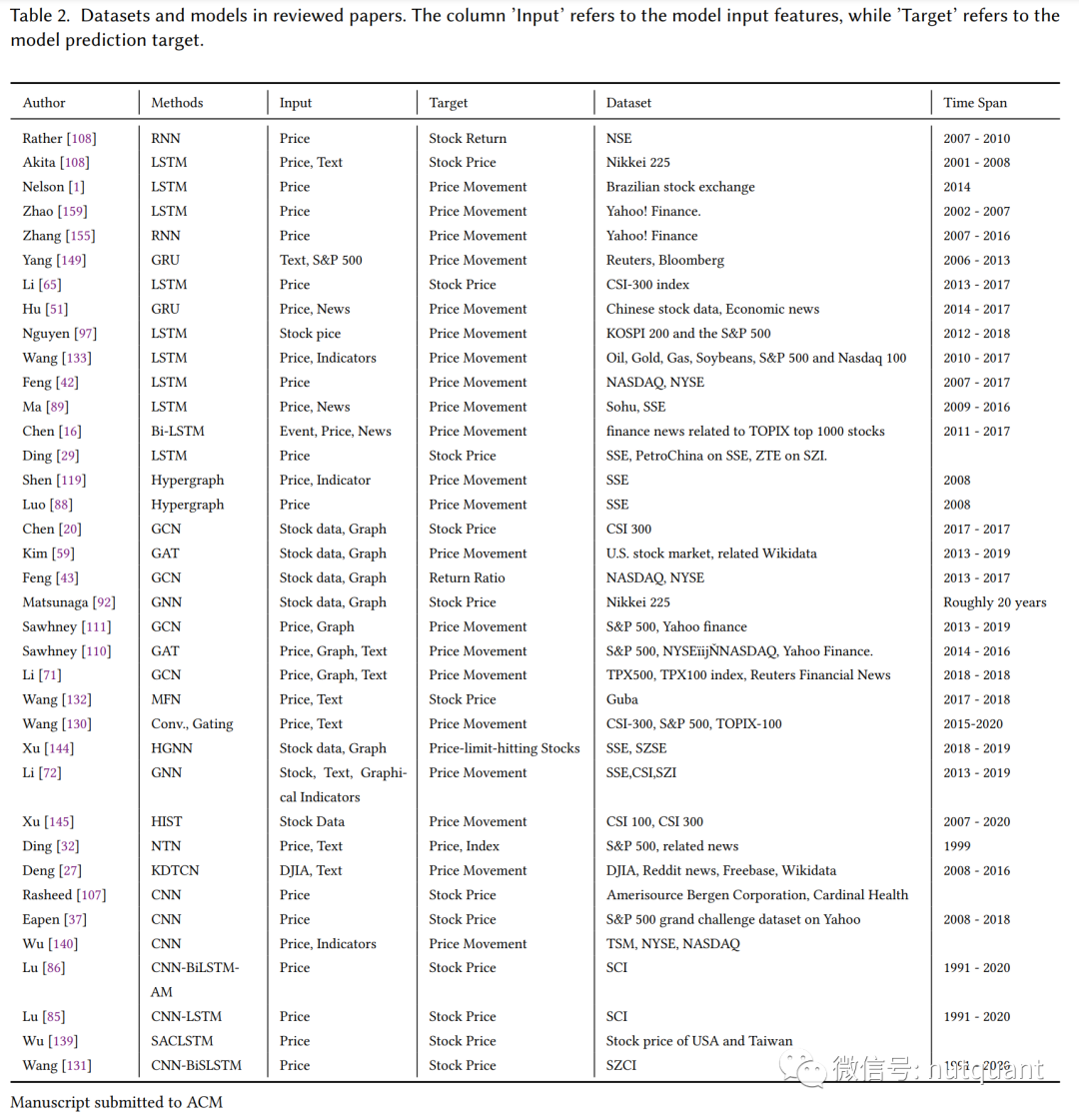
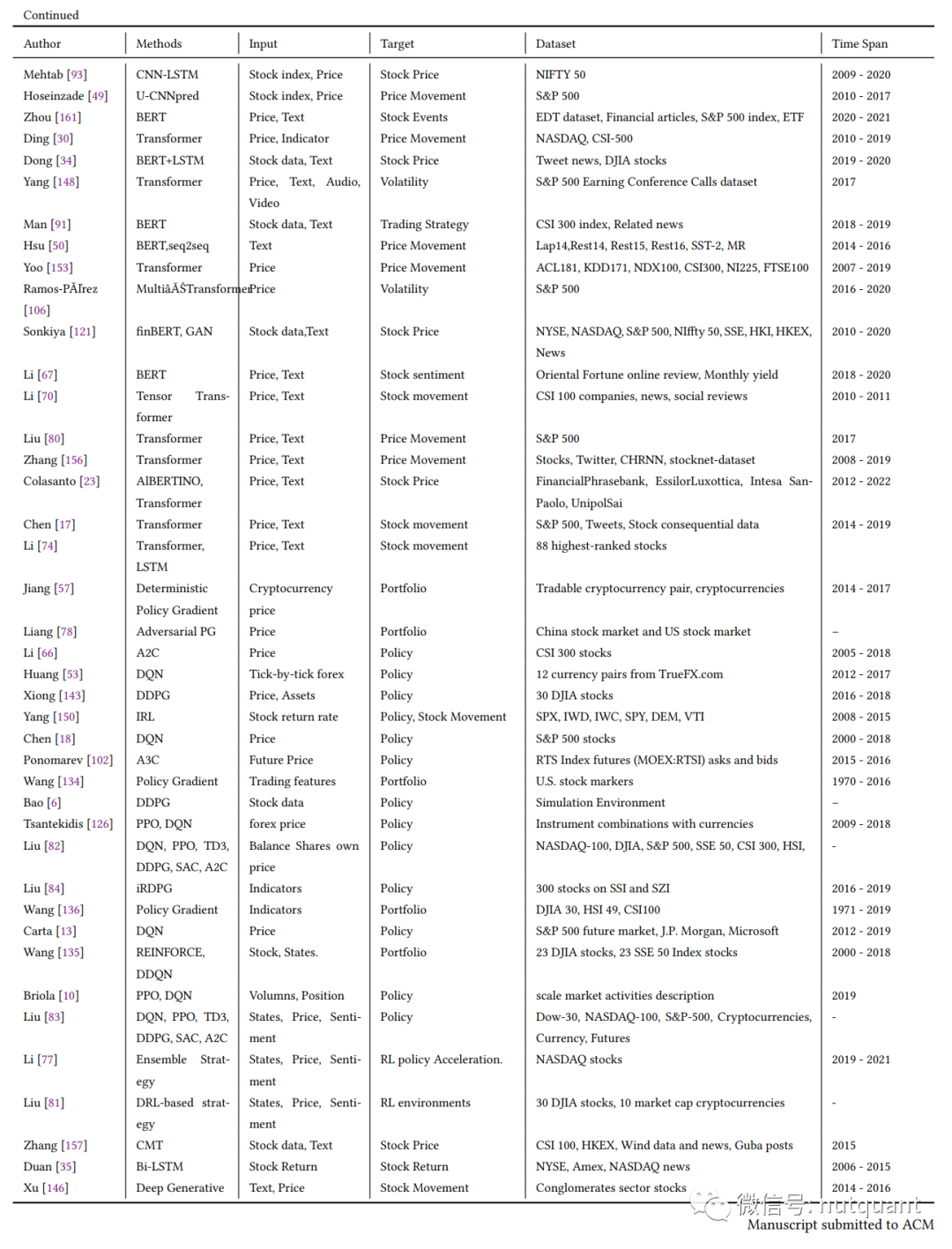
详细的论文模型、输入、目标及所用数据集信息可参见以下综合表格:
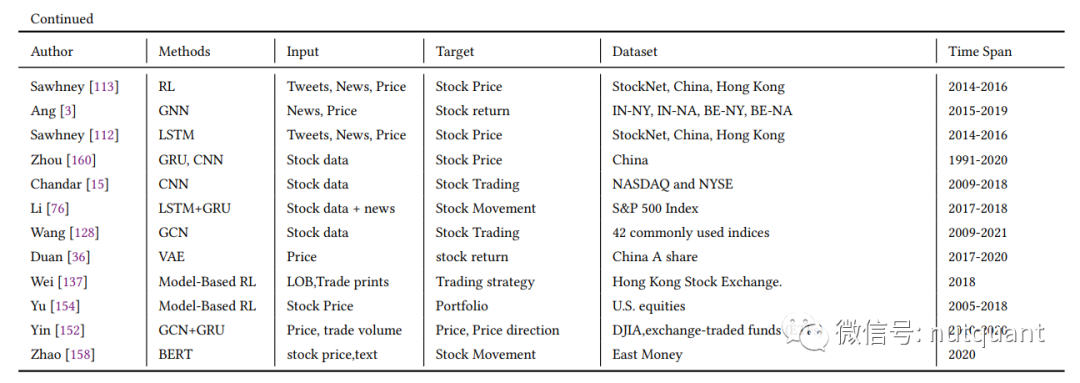
模型输入类型
根据数据形式,模型输入主要分为:
- 时间序列:最主流的输入形式,用于直接建模价格走势。
- 文本:需经过预处理(如情感分析)转化为结构化特征。
- 图:以节点和边表示实体及其关系。
- 其他:如图像(K线图)、音频(财报电话会议)等新兴多模态数据。
模型评估指标
选择合适的评估指标至关重要。本文将常用指标分为三类:
- 基于准确性的指标:主要用于分类任务(如趋势预测)。
- 基于误差的指标:主要用于回归任务(如价格预测)。
- 基于收益的指标:更贴近实际金融绩效的评估。
下表汇总了采用不同评估方法的典型论文:
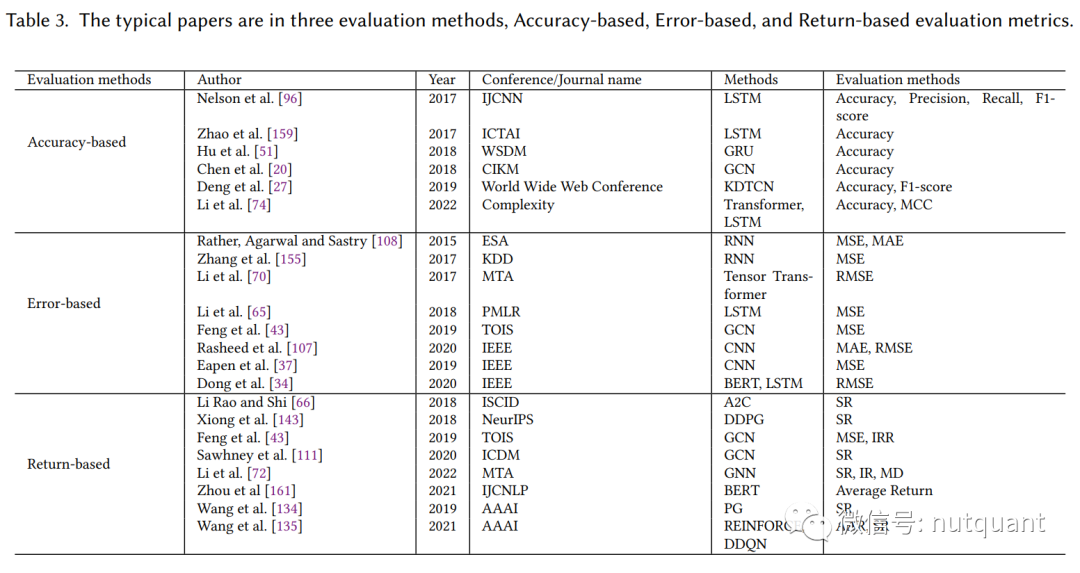
1. 基于准确性的评估指标
-
准确率(Accuracy):正确预测样本占总样本的比例。
$Accuracy = \frac{TP + TN}{TP + TN + FP + FN}$
其中TP、TN、FP、FN含义见混淆矩阵:
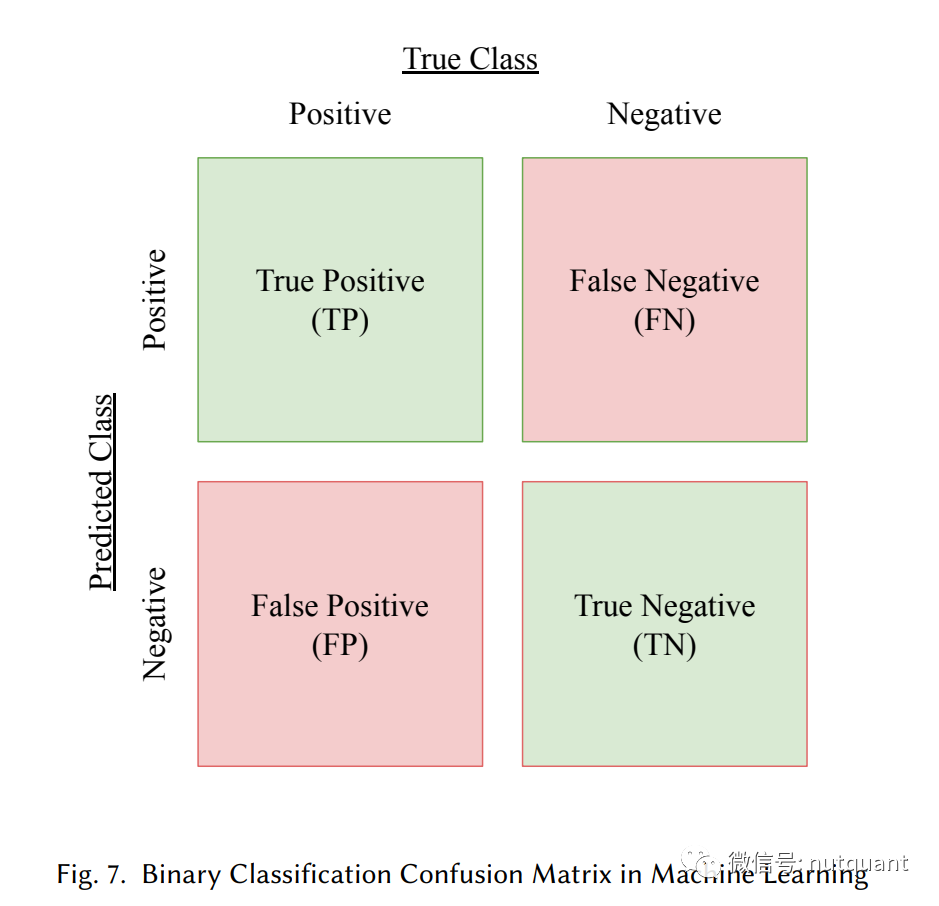
-
精确率(Precision)、召回率(Recall)与F1分数:针对不平衡数据集更有效的指标。
$Precision = \frac{TP}{TP + FP}$
$Recall = \frac{TP}{TP + FN}$
$F1 = \frac{2 \times Precision \times Recall}{Precision + Recall} = \frac{2 \times TP}{2 \times TP + FP + FN}$
-
马修斯相关系数(MCC):对类别不平衡鲁棒性更好的综合指标,其值在-1到1之间。
$MCC = \frac{TP \times TN - FP \times FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}$
2. 基于误差的评估指标
- 平均绝对误差(MAE):
$MAE = \frac{1}{n}\sum_{i=1}^{n} |y_i - \hat{y}_i|$
- 均方误差(MSE):
$MSE = \frac{1}{n}\sum_{i=1}^{n} (y_i - \hat{y}_i)^2$
- 均方根误差(RMSE):
$RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}$
- 平均绝对百分比误差(MAPE):
$MAPE = \frac{100\%}{n}\sum_{i=1}^{n} \left| \frac{y_i - \hat{y}_i}{y_i} \right|$
3. 基于收益率的评估指标
- 回报率(Return Ratio):
$Return_{ratio} = \frac{p_t - p_{t-1}}{p_{t-1}} \times 100\%$
- 夏普比率(Sharpe Ratio):衡量风险调整后的收益。
$Sharpe_{ratio} = \frac{R_p - R_f}{\sigma_p} \times 100\%$
其中,$R_p$是投资组合收益率,$R_f$是无风险利率,$\sigma_p$是投资组合收益率的标准差。
未来研究方向与开放性问题
尽管深度学习已在股市预测中取得显著进展,但仍有诸多挑战亟待解决:
- 提升模型泛化能力:许多模型在训练集上表现良好,但在真实市场或未知数据上泛化能力不足。结合自监督学习等新技术以提升模型的泛化和抗过拟合能力是一个重要方向。
- 结合在线学习:市场瞬息万变,能够根据新数据流实时更新模型的在线学习框架,对于适应市场波动和突发变化具有巨大实用价值。
- 统一评估标准与基准数据集:当前研究使用的评估指标和数据集千差万别,缺乏统一的、面向实际盈利能力的基准(如年化收益率、最大回撤等),这严重阻碍了领域的公平比较与快速发展。
- 改进时间序列异常检测:有效识别市场中的异常波动或结构性突变,有助于风险管理和抓住交易时机。将鲁棒的异常检测机制集成到预测模型中是未来的一个重点。
- 探索持续学习:金融市场环境持续变化,要求模型能不断学习新任务而不遗忘旧知识。持续学习技术有望让同一个模型适应多个预测任务并随时间进化。
- 深化强化学习应用:探索值分布强化学习等新方法,以更好地刻画收益分布和风险管理。同时,将金融交易更准确地建模为部分可观测马尔可夫决策过程(POMDP),并开发相应的基于模型的RL算法,是极具潜力的前沿。
结语
本次综述系统性地回顾了基于深度学习的股市预测研究现状,从任务定义、模型架构、数据输入到评估指标进行了全面梳理。随着数据科学与计算能力的进步,尤其是多模态融合、强化学习与自适应学习技术的发展,股市预测领域正朝着更智能、更稳健、更实用的方向演进。希望这份综述能为相关领域的研究者和实践者提供有价值的参考。
 发表于 2026-4-7 01:55:41
|
查看: 140|
回复: 0
发表于 2026-4-7 01:55:41
|
查看: 140|
回复: 0
