对于奋战在深度学习框架底层、CUDA 算子优化、芯片微架构设计一线的开发者而言,评估一家国产 GPU 公司,往往习惯于紧盯其宣称的算力、显存带宽或是否支持 Triton/vLLM/TileLang 等开源框架。
然而,这个商业世界并非单纯以技术指标运转。在“百模大战”和 Scaling Law 主导的算力狂飙时代,纯粹的技术指标(尤其是 PPT 上的峰值指标)极具欺骗性。
产品做得再好,若无人买单、无法销售,便丧失了造血能力。缺乏造血能力的企业,终将难以为继。这是商业世界最朴素的真理,也是国产 GPU 行业正在经历的残酷洗礼。
在这个商业闭环中,产品架构与技术选型固然重要。但试想,如果未来人人都能借助 AI 工具设计芯片,那么单纯的技术能力就不再是最高壁垒,更何况当前所有国产 GPU 都必须解决 CUDA 生态兼容问题。真正决定生死的,是能否形成完整的商业闭环——获得真实订单,让用户反馈驱动产品迭代,形成自我增强的飞轮。没有订单,再炫酷的架构也只是停留在实验室的演示文稿。
要判断一条技术路线能否长久存活、一套软件栈是否值得投入精力,最诚实的试金石只有两个:财务报表与出货量。
下文分析基于摩尔线程、壁仞科技、天数智芯和沐曦集成电路四家公司发布的 2025 年度业绩报告或预告。




在拆解四家头部国产 GPU 公司(沐曦、摩尔线程、天数智芯、壁仞科技)的 2025 年报前,我们为技术从业者补充几个关键的“技术-财务”映射常识:
- 营业收入 = 真实落地规模。在算力市场,10 亿人民币的营收大约对应大几千到上万张高端加速卡的实际交付。没有这个体量,所谓的“千卡/万卡集群稳定运行”大概率只是实验室里的演示环境。
- 研发费用 = 架构迭代与流片续航力。一颗 7nm/5nm 级别的大芯片,单次流片成本高达数千万至上亿元人民币,叠加数百人的 IC 设计与底层软件团队,每年的硬性研发消耗至少在 8-10 亿元。低于这个数字,意味着架构演进和底层驱动的维护将面临停滞风险。
- 毛利率 = 产品生态溢价与议价权。计算公式为:
(营业收入 - 营业成本) / 营业收入。如果毛利率极低,说明产品只能依靠低价倾销,无法通过 CUDA 兼容性、软件栈易用性等高附加值要素获取溢价。Nvidia 的毛利率常年在 70% 以上,国产 GPU 若能维持在 50% 左右,说明其在特定场景下已具备不可替代的真实商业价值。
- 经营活动现金流 = 烧钱速度与生死线。芯片公司由于先进制程代工(如台积电)需大量预付款,加之 HBM 等元器件供应紧张,经营活动现金流往往为深度负值。这直接考验着公司的融资能力与未来的自我造血潜力。
基于上述逻辑,本文将剥离市场上的商业宣传,仅从“技术+财务”双重底层的视角,对四家公司 2025 年的最新财报进行拆解。
零、横向技术&财务对比表
| 指标维度 |
沐曦(MetaX) |
摩尔线程(Moore Threads) |
天数智芯(Iluvatar CoreX) |
壁仞科技(Biren Tech) |
| 2025 营收 |
16.44 亿元 |
14.50-15.20 亿元 |
10.34 亿元 |
10.35 亿元 |
| 研发费用 |
10.27 亿元 |
持续高投入(未披露) |
9.74 亿元 |
14.76 亿元 |
| 研发费用率 |
62.49% |
未披露 |
94.2% |
142.6% |
| 综合毛利率 |
56.51% |
增长态势(未披露) |
54.0% (训练端 64.2%) |
53.8% |
| 经调整净亏损 |
-8.30 亿元 (扣非净利) |
-9.50 至 -10.60 亿元 |
-4.38 亿元 |
-8.74 亿元 |
| 核心架构路线 |
SIMT 架构,训推渲染全覆盖 |
MUSA 全功能架构 |
训练(天垓)+推理(智铠)+端侧(彤央) |
专注大算力与互连(SuperPod) |
| 集群扩展互连 |
MetaXLink (7 links) |
未专门命名,万卡级集群 |
自研通信库,跨节点提效 30% |
Blink 2.0,首发光互连(dOCS) |
| 底层软件栈 |
MXMACA |
MUSIFY/MUSA |
DeepSpark |
BIRENSUPA |
| CUDA 兼容/迁移 |
6000+应用,极高兼容性 |
提供迁移工具 |
提效 80%,分钟级迁移 |
拥抱 Triton/TileLang/vLLM 开源栈 |
| 大模型生态 |
Day-0 适配开源大模型,OCP |
支持万亿参数规模 |
MFU 提升 60%,MoE 架构优化 |
DeepSeek V3/R1 Day-0 适配,FP4 |
从数据可以清晰看到几个核心趋势:
- 商业化全面爆发:四家厂商营收均实现翻倍级增长,摩尔线程以约 240% 的增速领跑,沐曦以 16.44 亿元的营收规模位居行业第一,商业化落地进入快车道。
- 毛利率维持高位:四家厂商综合毛利率均稳定在 53% 以上,体现了国产高端 GPU 的技术壁垒与定价能力,并非单纯依靠低价换市场。
- 研发投入持续高强度:即便营收大幅增长,四家厂商仍将绝大部分甚至全部收入投入研发,为下一代产品迭代与技术突破提供保障。
- 亏损持续收窄,盈利拐点临近:除壁仞科技因下一代产品研发加码导致亏损小幅扩大外,其余三家均实现亏损大幅收窄,行业整体已进入盈利拐点的前置周期。


(科创板代码:688802)
沐曦是国内少有坚持自研指令集与 GPU 架构,并强调“软硬件双轨并行”的厂商。其年报展示了从推理到训推一体的完整产品阵列。
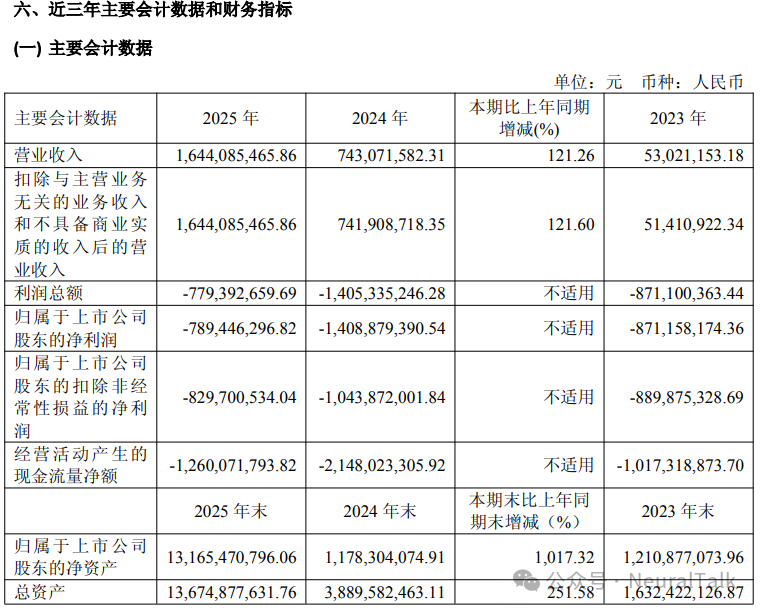
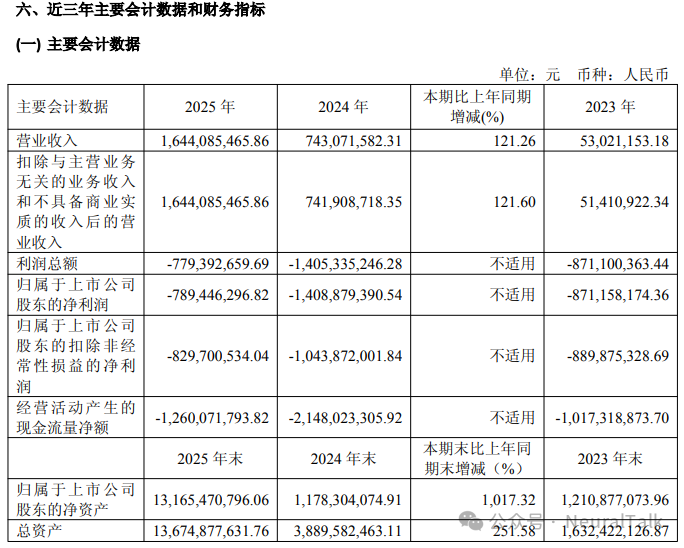
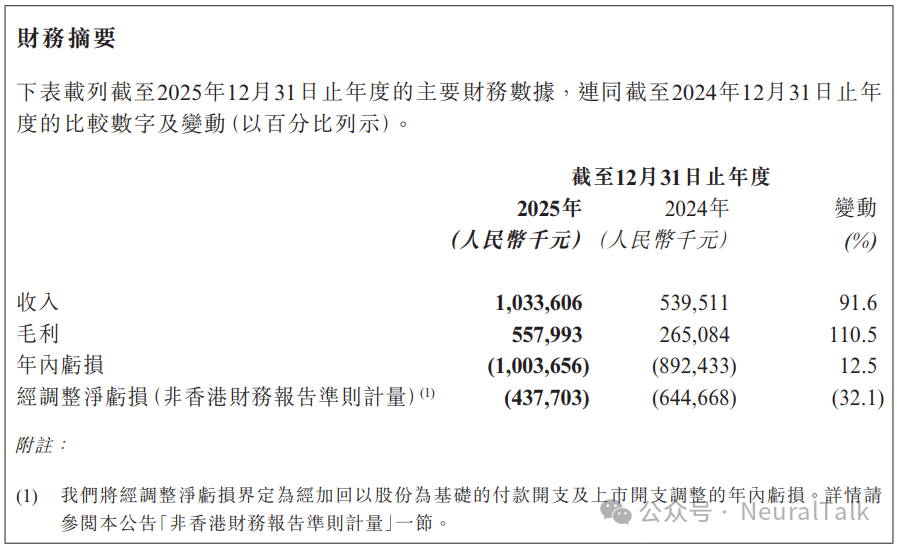
1. 营业收入:16.44 亿元
- 数据来源:年度报告显示,全年实现营业收入 16.44 亿元,较上年同期增长 121.26%。主要得益于曦云 C 系列等 GPU 产品出货量显著增长,下游客户从验证阶段进入规模化采购。
- 技术视点:营收同比增长 121.26%,这一体量意味着其核心产品曦云 C 系列已经跨过初期客户验证,进入了智算中心等场景的规模化采购阶段。
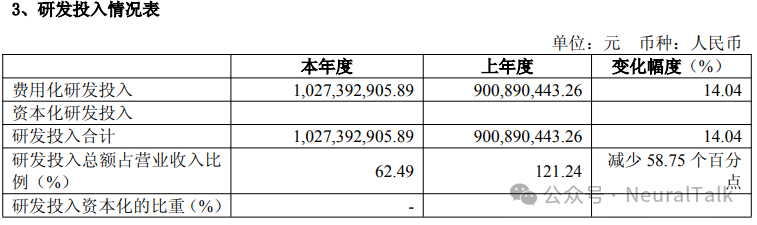
2. 研发费用:10.27 亿元
- 数据来源:2025年研发投入达 10.27 亿元,占营业收入比重为 62.49%。绝对金额增长 14.04%。公司拥有 675 名研发人员,占员工总数 73%。
- 技术视点:研发费用率达到 62.49%。目前沐曦研发人员规模足以支撑一个大代际微架构的研发和 MXMACA 软件栈的持续迭代。
3. 净亏损:-7.89 亿元
- 数据来源:归属于上市公司股东的净利润为 -7.89 亿元。较上年同期亏损收窄 43.97%,主要原因是收入大幅增长。
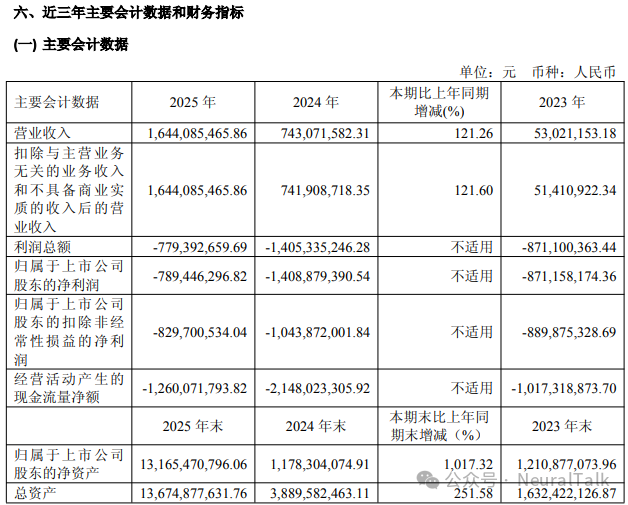
4. 毛利率:56.51%(集成电路行业整体),GPU 产品 56.17%
- 数据来源:集成电路行业整体毛利率为 56.51%,其中 GPU 产品及配件毛利率为 56.17%,较上年同期提升 2.56 个百分点。
- 技术视点:在国产替代竞争中能保持稳中有升的毛利率,说明其并非走低端价格战,C500 系列在云端训推一体场景展现了较强的系统级溢价。
5. 经营活动现金流:-12.60 亿元
- 数据来源:经营活动产生的现金流量净额为 -12.60 亿元。主要原因是为保障 HBM 及晶圆产能进行了大量战略备货,存货余额升至 14.96 亿元。
- 技术视点:大量现金用于战略备货,是当前高端 GPU 供应链的普遍痛点。
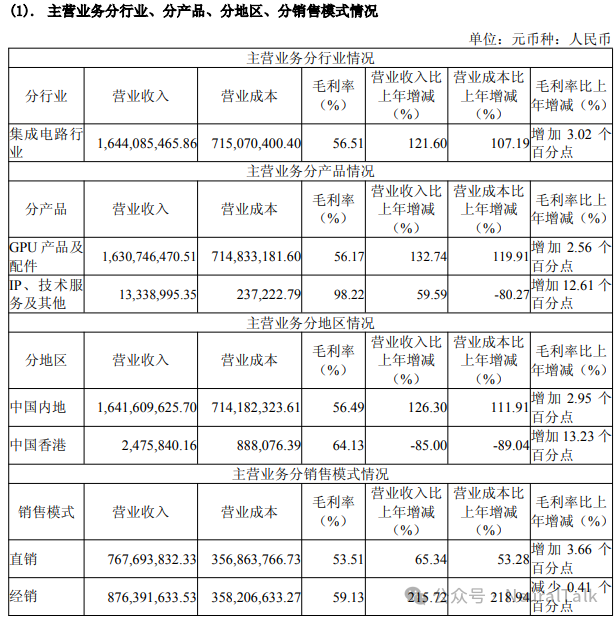
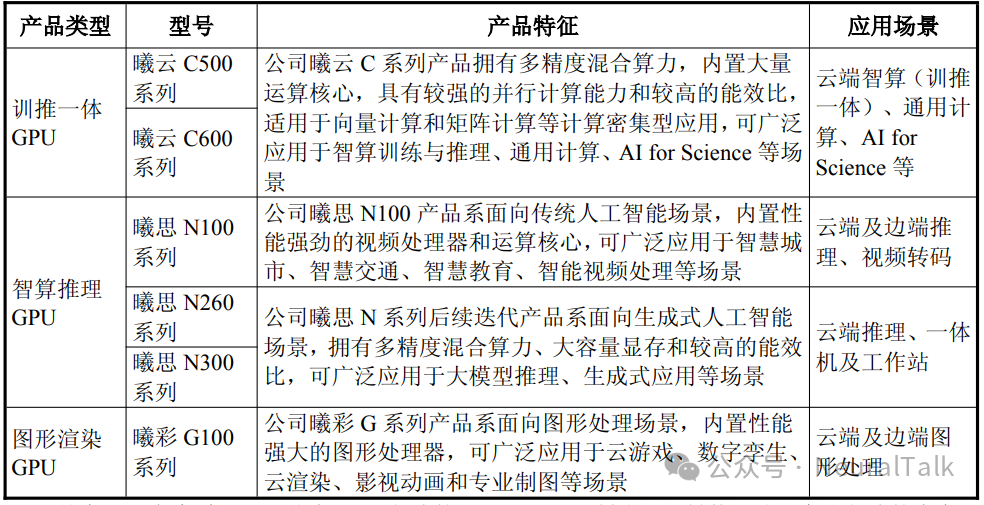
6. 核心产品与技术进展
- 数据来源:产品线覆盖曦云 C 系列(训推一体)、曦思 N 系列(智算推理)和在研的曦彩 G 系列(图形渲染)。自研的 MetaXLink 高速互连技术单芯片集成 7 个接口,支持 2-128 卡多种互连拓扑。硬件架构支持 OCP Microscaling 数据格式。
- 技术视点:硬件架构上支持 OCP Microscaling(微缩放)数据格式,这是针对大模型内存瓶颈的前沿设计。其自研的 MetaXLink 接口达到了类 Nvidia H200 的互连带宽水平。

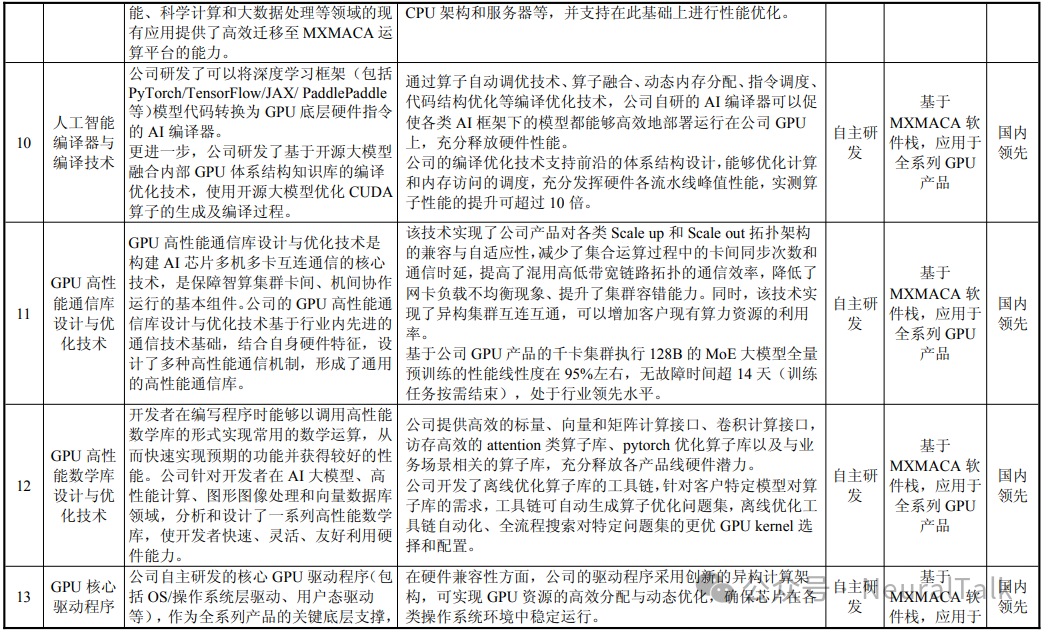
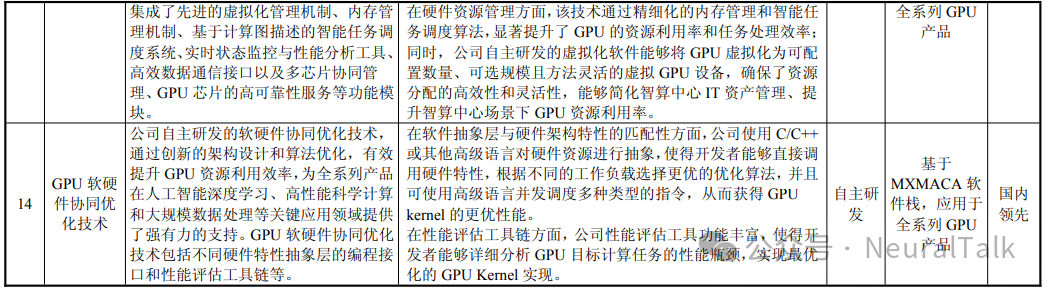
7. 软件生态(CUDA 兼容)
- 数据来源:自主研发的 MXMACA 软件栈在 API 层面高度兼容 CUDA 生态,已支持超过 6,000 个 CUDA 应用,并与 1,000 多个大模型实现原生适配,实现了对前沿开源模型的 Day-0 适配。
- 技术视点:MXMACA 软件栈采用 SIMT 架构。支持超过 6000 个 CUDA 应用,实现了对主流开源模型的 Day-0 适配,意味着其底层编译器已具备成熟的算子融合与图转换能力。



二、 摩尔线程(Moore Threads)

(科创板代码:688795)
摩尔线程主打“全功能 GPU”(兼顾图形渲染与 AI 算力)。由于提供的是业绩预告,数据粒度较粗,但核心趋势清晰。
1. 营业收入:14.50 亿元 至 15.20 亿元
- 数据来源:根据公司发布的《2025年年度业绩预告》,全年营业收入预计在 14.50 亿元至 15.20 亿元之间,同比增幅高达 230.70% 至 246.67%。
- 技术视点:营收暴增 230% 以上,突破 10 亿大关,意味着其 MTT S 系列加速卡已经在各大智算中心完成了万卡级别的物理交付。
2. 研发费用:持续高研发投入(具体绝对值未披露)
- 数据来源:公司在业绩预告中解释,目前“仍处于持续研发投入期”,以保持产品竞争力,这是导致尚未盈利的主要原因。
- 技术视点:预告中承认“与部分国际巨头相比,公司在产品客户生态等方面仍存在一定差距”。其软件栈 MUSA 主推对 CUDA 的零成本迁移,这意味着在一些长尾算子或最新大模型复杂混合精度支持上,底层库仍需时间打磨。
3. 净亏损:-9.50 亿元 至 -10.60 亿元
- 数据来源:归属于母公司所有者的净利润预计亏损 9.50 亿元至 10.60 亿元。与上年同期相比,亏损额收窄幅度达到 34.50% 至 41.30%。
- 技术视点:相比去年的巨额亏损,亏损大幅收窄,说明其硬件流片的良率、出货的规模效应已经开始摊薄早期的沉没成本。
4. 毛利率:推动收入与毛利增长(具体未披露)
- 数据来源:公司在分析业绩变化原因时提到“推动收入与毛利增长”,但预告没有披露具体的毛利率百分比。
- 技术视点:同样指向其软件生态与巨头存在差距,需要持续打磨。
5. 经营活动现金流:未披露
- 数据来源:本次业绩预告未披露经营活动产生的现金流量净额。
6. 核心产品与技术进展
- 数据来源:成功推出旗舰级“训推一体全功能 GPU 智算卡 MTT S5000”,并实现规模量产。基于该产品构建的大规模计算集群已完成建设并上线,能够高效支持“万亿参数”级别的大模型训练。
- 技术视点:报告强调了“可高效支持万亿参数大模型训练”,这意味着其卡间通信和网络拓扑已经能够承载超大规模并行分布式训练(数据/张量/流水线并行)。
7. 软件生态(CUDA 兼容)
- 数据来源:公司在总结与行业巨头的差距时坦诚承认在“产品客户生态”方面存在差距。
- 技术视点:软件生态的差距是成熟度的体现。MUSA 栈的 MUSIFY 迁移工具是关键,但在复杂场景下仍需持续优化。
三、 天数智芯(Iluvatar CoreX)
(港交所代码:9903)
天数智芯是国内较早切入通用 GPGPU 赛道的厂商,今年成功登陆港股,其报表透明度较高。
1. 营业收入:10.34 亿元
- 数据来源:2025年全年收入为 10.34 亿元人民币,较2024年增长 91.6%。其中,通用 GPU 产品(天垓训练系列+智铠推理系列)贡献了 9.23 亿元,占总收入的 89.3%。
- 技术视点:通用 GPU 产品贡献了绝大部分营收,说明其已成功从早期的定制化解决方案模式,转型为标准化的算力芯片供应商。
2. 研发费用:9.74 亿元
- 数据来源:2025年研发开支为 9.74 亿元,同比增长 26.1%。增长主要来自研发团队扩充(超过530人)和流片费用增加。
- 技术视点:高比例的硕士/资深专家团队是深水区底层软件(如自研通信库)研发的必要条件。
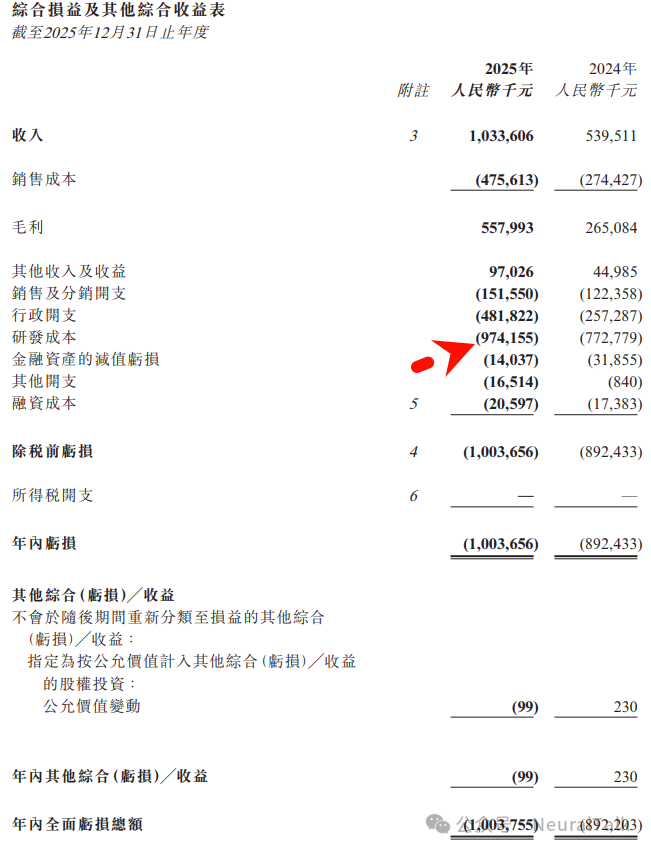
3. 净亏损:-10.04 亿元(经调整净亏损 -4.38 亿元)
- 数据来源:2025年年内净亏损为 10.04 亿元。若剔除股份支付和上市开支等非现金项目,经调整净亏损为 4.38 亿元,同比大幅收窄 32.1%。
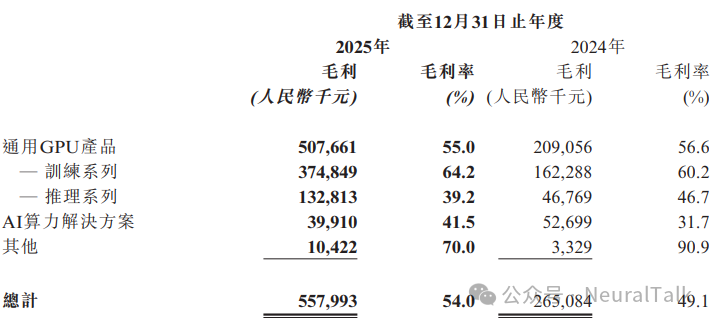
4. 毛利率:54.0%
- 数据来源:2025年整体毛利率为 54.0%。天垓训练系列毛利率高达 64.2%;智铠推理系列毛利率为 39.2%,原因是主动降低售价以抢占市场份额。
- 技术视点:这反映了训练端算力供给稀缺、议价能力强,而推理端市场已进入激烈竞争阶段。
5. 经营活动现金流:-11.62 亿元
- 数据来源:经营活动所用现金净额为 11.62 亿元。主要是研发投入和备货消耗了大量现金。得益于港股上市融资,公司年末现金储备大幅提升。
- 技术视点:快速扩张期的典型特征,但上市融资提供了充足的流动性保障。

6. 核心产品与技术进展
- 数据来源:天垓系列(训练)已推出 Gen2;智铠系列(推理)强化了整数计算单元;发布了面向机器人、智能终端的“彤央”系列端侧产品。自研通信库实现跨节点效率提升 30%,已稳定支撑万卡级规模集群。
- 技术视点:形成了云边端协同产品布局。自研通信库实现跨节点通信效率显著提升,是支撑大规模集群的关键。

7. 软件生态(CUDA 兼容)
- 数据来源:全新一代软件开发平台原生兼容主流 GPU 编程模型,代码迁移效率提升 80% 以上,支持算子“分钟级”平滑迁移。DeepSpark 开源社区已完成超过 610 个主流算法模型适配。
- 技术视点:主力平台是 DeepSpark 开源社区。针对长文本处理与 MoE 大模型训练,系统算力利用率提升了 60%,通信开销降低 30%。


四、 壁仞科技(Biren Technology)

(港交所代码:6082)
壁仞科技在 2025 年迎来了商业化落地的拐点,并于 2026 年初成功登陆港股,获得了巨额资金补充。
1. 营业收入:10.35 亿元
- 数据来源:2025 年公司收入达 10.35 亿元,相比 2024 年暴涨 207.2%。其中 10.28 亿元来自基于 BR10X 系列芯片交付的千卡/万卡级集群解决方案。
- 技术视角:收入几乎全部来自集群方案,说明壁仞已经走通了“芯片 → 板卡 → 集群”的完整商业化路径。
2. 研发费用:14.76 亿元
- 数据来源:2025 年研发费用 14.76 亿元,比 2024 年增长 78.5%。主要用于研发技术服务、团队扩充和股权激励。
- 技术视角:壁仞是四家企业中研发投入最高的。同比近八成的高增长,说明它正处于下一代产品和超大规模集群互连技术(如光互连)的攻坚期。
3. 净亏损:-164.93 亿元(经调整净亏损 -8.74 亿元)
- 数据来源:2025 年账面净亏损 164.93 亿元,但“经调整净亏损”仅为 8.74 亿元。巨额差额主要来自上市前融资条款相关的会计处理(赎回负债公允价值变动),不影响实际现金流。
- 技术视角:真实经营亏损为 8.74 亿元,这在高速成长的芯片公司中属于正常水平。
4. 毛利率:53.8%
- 数据来源:2025 年毛利率 53.8%,比 2024 年略有提升。
- 技术视角:超过 50% 的毛利率在国产 GPGPU 初创公司中属于健康水平,表明其产品具备一定的溢价能力。
5. 现金及等价物储备:28.96 亿元(上市前)
- 数据来源:截至 2025 年底,公司现金及等价物合计 28.96 亿元。2026 年初 H 股上市募资净额 56.31 亿元。
- 技术视角:上市后壁仞手握超过 85 亿元现金,这是四家企业中资金最充裕的一家,足以支撑未来 2-3 年的先进制程流片和先进封装采购。
6. 核心产品与技术进展
- 数据来源:BR10X 系列已实现规模量产并交付千卡级集群,其中包括一个采用光互连与分布式光路交换(dOCS) 技术的 2,048 卡 GPU SuperPod 集群。下一代 BR20X 系列计划 2026 年商用,加入 FP8/FP4 计算引擎,并引入自研 Blink 2.0 互连协议。
- 技术视角:硬件路线清晰——从单芯片走向集群系统。已将光互连技术应用到超大规模集群中,业内超前。下一代产品针对推理场景优化,预判了未来 AI 负载趋势。
7. 软件生态
- 数据来源:BIRENSUPA™ 软件栈兼容 CUDA 生态,并强调拥抱开源 AI 基础设施,原生支持 PyTorch、vLLM、SGLang 等,扩展了对 Triton、TileLang 等开源编译器生态的兼容。完成了对主流大模型的 Day‑0 适配。
- 技术视角:软件策略不是简单“模仿 CUDA”,而是主动靠拢开源社区。支持 Triton 等高层编译器,可大幅降低开发者迁移成本。能实现与大模型的同日适配,说明其软硬件协同能力已比较成熟。
五、 面向技术从业者的核心结论与选型建议
在拆解完这四份硬核财报后,作为人工智能领域工程师或芯片架构师,你能清晰地看到国产 GPU 行业已经跨越了“炒作概念”阶段。10 亿人民币以上的营收红线,证明了这些芯片在机房里真实地跑着功耗、传着数据、训着模型。
基于技术落地与财务可持续性,提出以下预判与选型建议:
1. 软件生态成熟度演进:从“抄 CUDA”到“超抽象编译”
早年国产 GPU 的唯一出路是做一个“CUDA 翻译器”,常导致长尾算子报错。从 2025 年的报告看,各家跑出了两条路径:
- 路线 A:高保真兼容(如沐曦的 MXMACA、天数智芯的 DeepSpark)。通过极高的人力投入,实现指令集和底层库的深度对接。如果你的业务代码强依赖于陈旧的 CUDA 自定义算子,建议优先评估此类厂商的平滑迁移能力。
- 路线 B:拥抱大模型上层编译器(如壁仞科技的 BIRENSUPA)。壁仞明确支持 Triton 和 TileLang。这是未来生态的主旋律——开发者用高级语言编写算子,由厂商的编译器后端负责优化与调度。这种路线对开发者友好,适合紧跟 vLLM/SGLang 等现代推理框架的团队。
2. 硬件性能与集群量产:Scale Out 成为终极战场
在单卡性能受制于制程和 HBM 产能的背景下,所有厂商都在互连技术上展开竞争。
- 训练集群:壁仞的 分布式光路交换(dOCS) 和沐曦的 MetaXLink(单卡 7 个接口) 是应对 NVLink/NVSwitch 的直接方案。如果需要构建千卡以上的大规模预训练集群,必须对这些厂家的网络拓扑和自研通信库进行严苛压测。
- 推理场景:天数智芯推理卡毛利率已降至 39%,说明国产推理卡已进入激烈的“价格战”。对于需要大规模部署端侧或云端并发推理的企业,此时是采购国产 GPU 降低总拥有成本的窗口期。
3. 财务安全性与供应链可持续性
开发者最怕的是:花了大量时间迁移代码,结果公司资金链断裂,驱动无人维护。从 2025 年报看:
- 沐曦与壁仞通过 IPO 获得了巨额现金,保证了其能预付台积电产能及 HBM,后续产品流片节奏最有保障。
- 面对高达 60% 甚至 140% 的研发费用率以及巨大的经营现金流出,计算芯片行业的高门槛尽显。选择长期合作厂商时,务必关注其持续融资或稳定的营收造血能力。
4. 不同场景的选型总结
- 主攻万亿参数预训练与超算中心建设:重点考察壁仞(光互连与网络带宽红利)与摩尔线程(万卡集群工程落地经验)。
- 主攻云边端协同、泛 AI 与多模态推理:重点考察天数智芯(推理芯片性价比高,发力端侧)与沐曦(推理产品在视频处理和 GenAI 场景的深度打磨)。
- 强依赖 Triton/开源高层框架的 AI 应用团队:优先选择软件栈已与 Triton/vLLM 等深度集成的平台,可大幅降低迁移重构成本。
结语:潮水褪去,谁在裸泳?
四份财报摆在眼前,10亿营收的“生死线”已不再是门槛——四家公司都跨了过去。但这远不是庆功宴的入场券,而是下一轮淘汰赛的起跑线。
事实一:没有一家盈利。
沐曦、摩尔、天数、壁仞四家合计真实经营亏损超过31亿元,而营收总和约52亿。每赚1块钱,同时要亏掉6毛到8毛5。 所谓“盈利拐点临近”,只是“亏得比去年少”,离真正的自我造血还有距离。
事实二:研发投入吞噬营收,现金流依赖外部输血。
壁仞研发费用率高达142.6%;天数94.2%,沐曦62.5%。经营现金流方面,沐曦-12.6亿,天数-11.6亿。没有持续的融资能力,任何一家都撑不过两年的高强度烧钱。 目前壁仞凭借超85亿现金储备最为安全,其他三家则必须紧盯下一次融资窗口。
事实三:CUDA兼容仍然是“翻译器”,而非“原生生态”。
“支持6000+ CUDA应用”“分钟级迁移”等宣传,本质上承认:国产GPU至今没有自己的编程模型和原生软件栈。代码能跑,靠的是大量工程师构建的兼容层。一旦CUDA生态更新,兼容层需要及时跟进,存在一定被动性。
事实四:毛利率分化暴露内卷,推理卡已率先进入价格战。
天数智芯的推理卡毛利率跌至39.2%,公司承认“主动降价抢占市场份额”。这意味着国产GPU在推理侧已陷入红海厮杀。而训练侧的高毛利是暂时的,国际厂商供给缺口填平后,国产卡能否守住高毛利是巨大问号。
所以,谁在裸泳?
不是营收最低的那家——10亿本身并不安全。裸泳的是那些研发投入无法持续、现金流撑不过下一个流片周期、软件生态永远跟在CUDA后面吃灰的厂商。而最大的风险在于:四家都还在同一水平线上竞争,没有一家建立起不可替代的技术壁垒或开发者忠诚度。
对开发者而言,选型不是选情怀,而是选谁能活到你的模型上线后的下一次迭代。建议在迁移代码之前,先问三个问题:
- 这家公司三年后还在不在? 看现金储备和融资能力。
- 如果CUDA生态明天更新,它的兼容层要多久才能追上? 看研发团队规模和迭代历史。
- 你的团队愿意永远绑定它的“类CUDA”方言,还是迟早要重写? 看它是否拥抱Triton等开源编译器,而非自己造封闭轮子。
国产GPU的“生死线”不是10亿营收,而是能否在现金流枯竭前,实现单季度经营现金流转正。2026年的财报,我们不再满足于“亏损收窄”——我们要看的是正的经营现金流,和不再依赖融资的造血能力。
否则,潮水褪去,裸泳者连上岸的机会都没有。关于国产算力的更多深度讨论,欢迎来云栈社区交流。
 发表于 2026-4-8 09:12:31
|
查看: 290|
回复: 0
发表于 2026-4-8 09:12:31
|
查看: 290|
回复: 0
