
仅12家机构能用。
智东西4月8日消息,Anthropic今日正式发布了新一代前沿模型Claude Mythos Preview及其配套的安全倡议项目Project Glasswing。这款模型最引人瞩目的能力在于,它能发现连人类专家和自动化工具都未能识别的软件漏洞。例如,在公认安全性极高的OpenBSD操作系统中,它挖出了一个隐藏长达27年的漏洞;在FFmpeg的一段代码中,自动化测试工具已经触发了超过500万次却始终未能发现问题,而该模型则成功将其定位。
然而,由于相应的安全防护机制尚未成熟,该模型目前并不对公众开放,仅在一个由12家核心机构组成的合作体系内提供有限访问。与此同时,Anthropic承诺为防御性网络安全研究提供最高1亿美元(约合人民币6.87亿元)的模型使用额度。
▲Anthropic官方发布Project Glasswing项目的社交媒体X平台推文
在专业的漏洞复现基准测试CyberGym上,它的得分高达83.1%,而Anthropic此前最强的公开模型Opus 4.6仅为66.6%。编程能力方面,在衡量软件工程任务的SWE-bench Verified测试中,它取得了93.9%的分数,远高于Opus 4.6的80.8%。Anthropic声称,新模型的能力已经达到“可以与最顶尖人类安全专家竞争”的水平。
Anthropic还特别公布了在Firefox JS shell环境下的专项漏洞利用测试结果。数据显示,Mythos Preview在该场景下成功生成完整可利用exploit(漏洞利用代码)的比例高达72.4%,另有11.6%的测试实现了寄存器控制;相比之下,前代模型Opus 4.6在相同任务中的成功率不足1%。这意味着Mythos Preview的漏洞利用生成能力较Opus 4.6提升了近两个数量级。
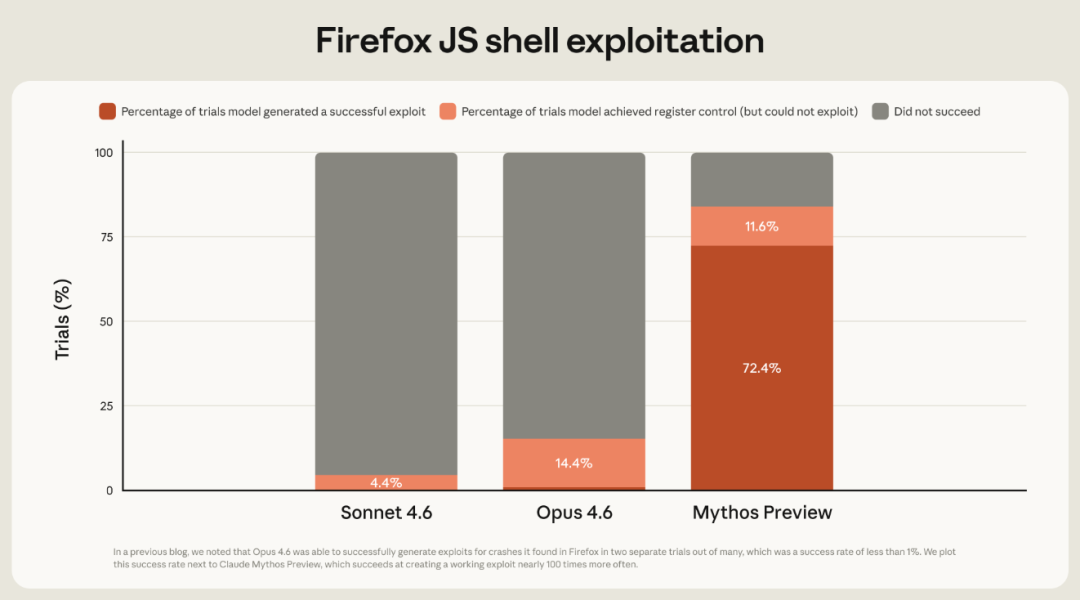
▲Claude三款模型在Firefox JS shell环境下的漏洞利用能力对比测试(图源:Anthropic)
除了发布模型,Anthropic还公布了一系列配套安排,包括向开源社区提供400万美元(约合人民币2747.2万元)的资助、承诺在90天内披露阶段性研究成果,并推动围绕漏洞披露、供应链安全等议题的行业协作。可以看出,这一项目不仅关乎模型本身的能力,更延伸至治理机制与行业规范的层面。
此次正式发布,其实有一个并不“体面”的前奏。早在今年3月底,Anthropic的内容管理系统就因配置错误,导致近3000份未发布的内部资料意外泄露。泄露内容显示,Anthropic内部已将该模型命名为Claude Mythos,并将其定性为“迄今为止最强大的AI模型”,同时在文件中直接警告其“带来了前所未有的网络安全风险”。而在Glasswing计划发布前约一周,Anthropic又因Claude Code软件包2.1.88版本的打包错误,意外泄露了近2000个源代码文件。
挖出藏了27年的老漏洞,发现500万次测试遗漏的隐患
Anthropic在官网披露,其新训练的前沿模型Claude Mythos Preview已在所有主流操作系统和浏览器中发现了数千个零日漏洞,其中多个被评定为高危级别。
该公司称,该模型的漏洞挖掘能力已可超越“除最顶尖安全专家之外的所有人类”,并且上述发现工作完全由模型自主完成,无需人工干预或引导。
官网提供了三个已被修复的具体漏洞案例:
- OpenBSD的27年漏洞:在以其高安全性著称、常用于防火墙等关键基础设施的OpenBSD操作系统中,模型发现了一个存在长达27年的漏洞。攻击者仅需建立网络连接,即可导致运行该系统的任意机器远程崩溃。
- FFmpeg的16年漏洞:在被大量软件用于视频编解码的FFmpeg库中,发现了一个已存在16年的漏洞。令人震惊的是,自动化测试工具此前曾命中该问题代码行超过500万次,却始终未能识别出漏洞。
- Linux内核的权限提升链:在运行全球大多数服务器的Linux内核中,模型自主发现并成功串联了多个漏洞,实现了从普通用户权限到完全控制系统内核的完整提权攻击链。
这三项漏洞均已报告给相关软件维护方并完成了修补。其余已发现的漏洞细节则以加密哈希形式提交,待修复完成后将陆续公开。
在CyberGym漏洞复现基准测试中,Mythos Preview得分83.1%,而Anthropic此前最强的公开模型Opus 4.6为66.6%。Anthropic警告称,随着人工智能能力以当前速度推进,此类攻击性能力将不可避免地向更广泛的行为者扩散,其中可能包括无意负责任部署的恶意行为者,届时对经济、公共安全和国家安全的潜在冲击将是严峻的。

▲Claude Mythos Preview与Claude Opus 4.6在CyberGym网络安全漏洞复现基准测试中的得分对比(图源:Anthropic)
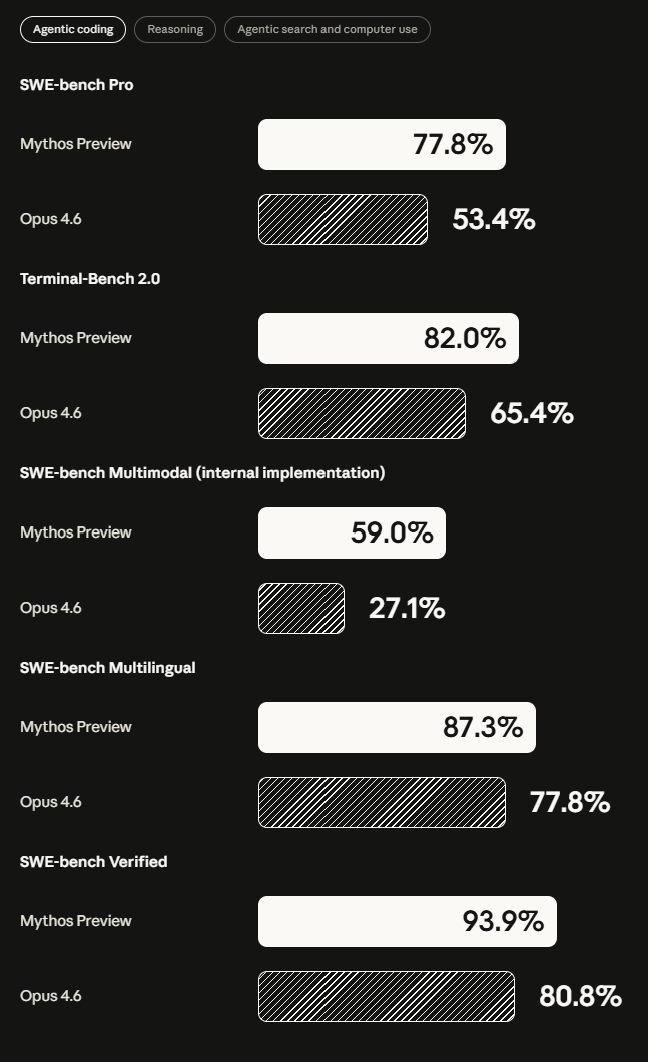
▲Claude Mythos Preview与Claude Opus 4.6在多项代码能力基准测试中的得分对比(图源:Anthropic)
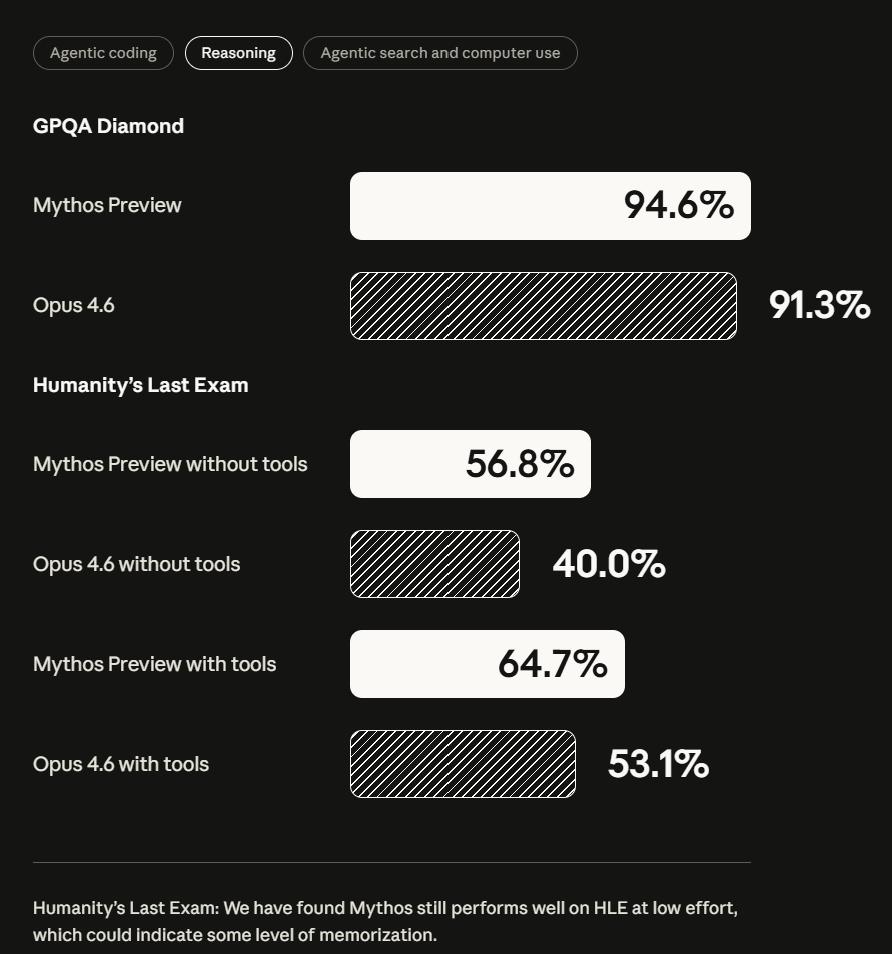
▲Claude Mythos Preview与Claude Opus 4.6在多项通用推理能力基准测试中的得分对比(图源:Anthropic)
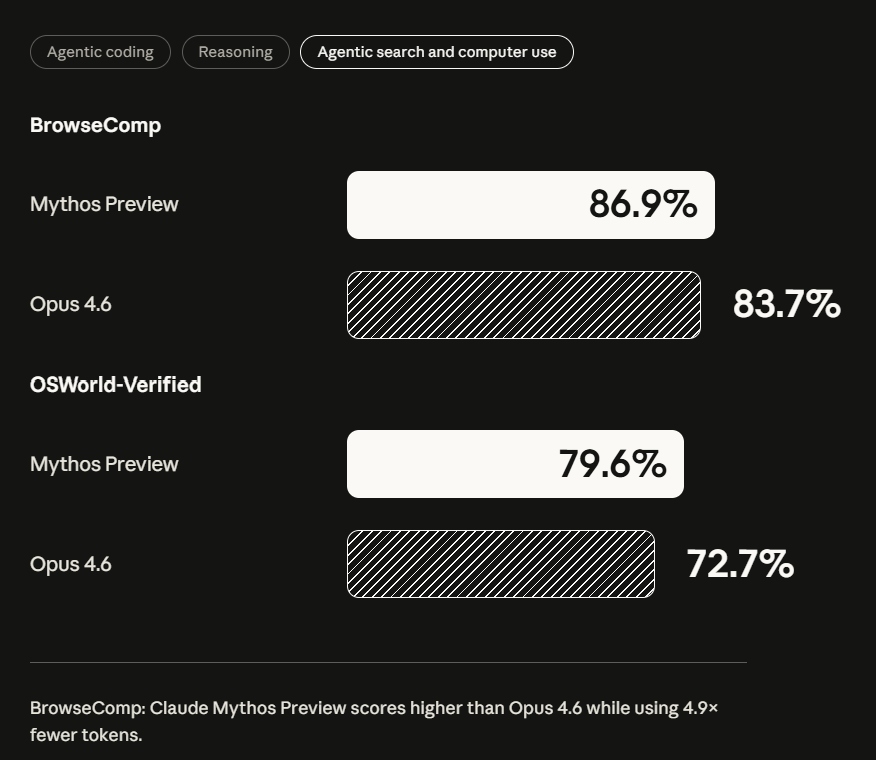
▲Claude Mythos Preview与Claude Opus 4.6在自主搜索与计算机操作类基准测试中的得分对比(图源:Anthropic)
联合12家巨头启动Glasswing,提供1亿美元额度支持安全研究
Project Glasswing由Anthropic牵头发起,汇集了12家重量级机构作为创始合作伙伴,包括:亚马逊云科技(AWS)、苹果、博通(Broadcom)、思科(Cisco)、网络安全公司CrowdStrike、谷歌、摩根大通(JPMorganChase)、开源基金会Linux Foundation、微软、英伟达以及网络安全公司Palo Alto Networks。

▲Project Glasswing发起合作方企业Logo(图源:Anthropic )
Anthropic承诺在研究预览期间,为上述合作方的防御性安全工作提供最高1亿美元(约合人民币6.87亿元)的Mythos Preview模型使用额度。除了这12家创始伙伴,目前已有超过40家构建或维护关键软件基础设施的组织获得了扩展访问权限,用于扫描和加固其自有系统及所依赖的开源组件。
在模型额度支持之外,Anthropic还直接向开源生态提供了400万美元(约合人民币2747.2万元)的捐款:其中250万美元捐赠给Linux Foundation旗下的Alpha-Omega和OpenSSF项目,150万美元捐赠给Apache Software Foundation,旨在帮助开源软件维护者应对AI时代下快速变化的网络安全威胁。
有意申请访问权限的开源维护者,可以通过“Claude for Open Source”项目单独提交申请。
研究预览期结束后,Mythos Preview将向参与机构提供商业化访问,定价为每百万tokens输入25美元(约合人民币171.7元)、输出125美元(约合人民币858.5元)。接入渠道将包括Claude API、Amazon Bedrock、Google Cloud Vertex AI和Microsoft Foundry。
官网将合作方的工作重点归纳为:本地漏洞检测、二进制文件黑盒测试、端点安全加固和系统渗透测试。这些工作所涉及的基础系统,覆盖了全球范围内相当规模的共享网络攻击面。
多家合作方已就初步测试效果发声:Cisco、AWS、Microsoft、CrowdStrike、Palo Alto Networks等均公开确认,该模型在其内部安全审计中已发现了此前被遗漏的复杂漏洞。Google则表示将通过其Vertex AI平台向项目参与者提供模型访问。
模型暂不对外发布,防护机制尚未就绪是主因
Anthropic明确表示,目前没有将Claude Mythos Preview面向公众开放的计划。
官方给出的理由是:要实现Mythos这种级别模型的安全、大规模部署,其前提是必须开发出能够有效检测并屏蔽模型最危险输出的网络安全防护措施。而这套至关重要的防护机制,目前尚未准备就绪。
作为过渡安排,Anthropic计划首先在即将推出的新版Claude Opus模型上部署和测试这套防护机制。其逻辑在于:Opus模型不具备Mythos Preview同等级别的潜在风险,可以作为改进和完善防护措施的“低风险试验场”。待机制成熟并验证有效后,再逐步推广至Mythos级别的模型。
对于因新防护措施而可能影响合规工作的安全专业人员,Anthropic称将开放一个名为“Cyber Verification Program”的专项申请渠道,但具体细节尚未公布。
Anthropic在官方博客中强调,随着AI能力的持续快速推进,此类进攻性能力“不久之后”将不可避免地扩散至更广泛的行为者,其中可能包括那些不承诺负责任部署的恶意方,其潜在后果将深远影响经济、公共安全乃至国家安全。
与此同时,Anthropic透露已就Mythos Preview所展现的进攻性和防御性网络能力,与美国政府官员展开了持续讨论。该公司认为,美国及其盟友必须在AI技术上保持“决定性领先”,而政府在评估和缓解AI相关国家安全风险方面,扮演着不可或缺的角色。
承诺90天内公开研究成果,推动建立跨行业安全规范
Anthropic承诺将在项目启动后的90天内发布一份公开报告,内容涵盖研究阶段的主要发现、已修复漏洞的详情以及可对外披露的系统改进成果。项目合作伙伴也将在各自能力范围内,互相分享信息与最佳实践。
官网将项目的整体持续时间表述为“数月”,并特别指出,前沿AI能力本身“可能在未来几个月内再次大幅跃进”。因此,网络安全防御方需要立即行动起来,利用现有最强的工具进行防护,而不是被动等待。
在行业规范层面,Anthropic列出了拟与领先安全组织合作推动的具体议题,包括:
- 漏洞披露流程的优化
- 软件更新流程的改进
- 开源与供应链安全
- 安全设计(Security by Design)实践
- 受监管行业的安全标准
- 漏洞分类与处理的规模化、自动化
- 补丁自动化
官网未披露上述议题的具体推进时间表或已确认的合作方名单。
从机构建设的中期设想来看,Anthropic提出了建立一个独立第三方机构的构想。该机构旨在汇聚私营和公共部门的力量,作为大规模网络安全项目持续推进的长期载体。该公司同时公开邀请其他人工智能行业成员加入,共同参与相关行业标准的制定。
Anthropic将Project Glasswing定性为“一个起点”,并强调没有任何单一机构能够独立解决这些全局性的网络安全挑战,前沿AI开发者、软件企业、安全研究人员、开源维护者以及各国政府都需要参与其中。
结语:不唯能力论英雄,安全底线优先
从Glasswing项目披露的整体信息来看,Anthropic此次并未将重点放在继续宣扬模型能力的上限,而是将更多精力转向了“能力应如何被约束和使用”这一关键议题。Claude Mythos Preview所展现出的、超越传统工具的漏洞挖掘与利用能力,本身就是一个强烈的信号。
Glasswing项目给出的路径是:在模型的“矛”与防护机制的“盾”尚未完全匹配之前,通过小范围、可控的合作体系,并集中资源进行验证与加固。这种方式并不改变模型能力的客观存在,但试图改变其扩散的节奏和应用的语境。配套的资金支持、强制性的信息披露以及行业规范的讨论,也在尝试将单一公司的技术风险管理问题,转化为需要跨机构、跨行业协作的公共安全议题。
从更长的发展周期看,这一项目的意义或许不在于短期内能发现多少个漏洞,而在于它是否能够探索并形成一套可复制、可扩展的安全运行与治理框架。随着模型能力继续提升,类似Glasswing的“能力与安全同步”机制能否成为行业常态,将直接决定高能力AI系统未来的实际落地路径与安全边界。对于关注技术伦理与实战应用的开发者而言,此类议题也值得在云栈社区这样的平台上进行更深入的探讨与交流。
 发表于 2026-4-9 01:50:40
|
查看: 248|
回复: 0
发表于 2026-4-9 01:50:40
|
查看: 248|
回复: 0
