
DeepXiv 是一个专为智能体设计的科技文献基础设施。它的目标是把论文搜索、渐进式阅读、热点追踪和深度调研这些动作,变成 AI 可以调用、编排和自动化的能力。
简单说,它不是在命令行里复现一个论文网站,而是把科技文献本身,转化成了智能体可以直接“消费”的数据接口和技能系统。这个项目由智源研究院联合高校与社区开发者共同研发,现已开源并免费开放使用。
项目地址:
引言:科研智能体需要怎样的文献基础设施?
大模型智能体的快速发展,正推动着 AI 驱动的自动化科研从概念快步走进现实。从自动发现问题、生成研究计划,到设计方法、开展实验,科研智能体有望重塑整个研究范式。
然而,要让智能体真正服务于科研,一个基础瓶颈亟待解决:智能体如何高效地使用科技文献?
今天,科技文献的利用方式仍然是为人类用户设计的。智能体需要通过繁琐的网页搜索、解析才能获取论文,再借助复杂的工具从高度视觉化的 PDF 中提取信息。这套基于搜索引擎和图形界面的基础设施,与智能体基于代码和 API 的工作方式严重不符。
换句话说,我们坐拥海量开放文献,却缺少一套 “面向智能体的科技文献基础设施”。
如果说过去的论文仅仅是“给人看的”,那么现在,论文需要兼顾“给智能体看”这一全新需求。
一个有效的思路是:让论文成为 CLI(命令行工具),使智能体可以像调用其他工具一样方便地获取并利用论文。这正是 DeepXiv 的核心设计理念。
DeepXiv:三大核心能力,让论文“智能体可用”
DeepXiv 是一个面向智能体的科技文献综合性工具集,其核心目标是让开放科技文献从“人类可读”升级为“智能体可用”。为了实现这一目标,它主要提供了三大能力。
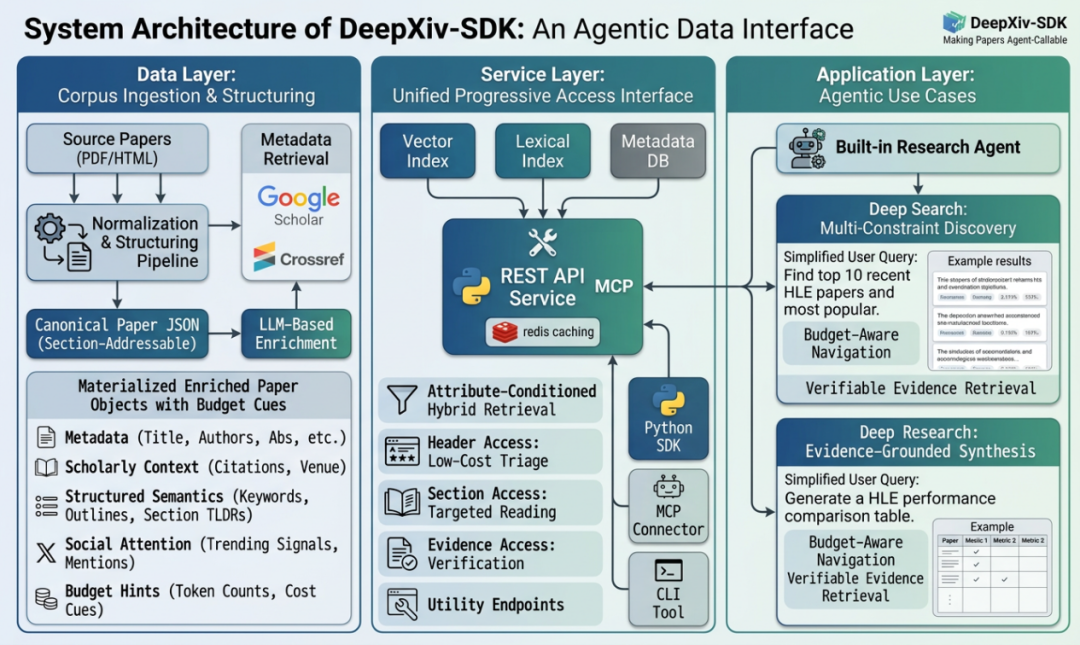
一、数据接入:把论文变成“智能体可消费的数据”
DeepXiv 将论文处理成对智能体友好的数据格式,如 JSON 或 Markdown。这意味着智能体不再需要从复杂的 PDF 或 HTML 中艰难地解析信息,可以直接获取标题、作者、摘要、参考文献等结构化元数据。
更重要的是,DeepXiv 提供了面向智能体优化的数据组织方式:
- 预览 (Preview):快速获取论文核心信息,以极低成本判断相关性。
- 分块 (Chunking):按结构或语义切分论文内容,支持局部精读。
- 渐进披露 (Progressive Disclosure):按需展开内容,避免一次性灌入整篇长文。
这些设计直接降低了 token 消耗,提升了检索与阅读效率,让智能体能将有限的上下文预算专注于最有价值的信息。
这种设计体现在具体的 CLI 调用上,非常贴近真实的研究流程:
pip install deepxiv-sdk # 安装工具包
deepxiv search "agent memory" # 搜索研究主题
deepxiv paper 2602.16493 --brief # 快速看摘要与要点
deepxiv paper 2602.16493 --head # 查看结构与章节分布
deepxiv paper 2602.16493 --section "Experiments" # 只读实验部分
这组命令对应了一个典型的研究路径:先搜索候选论文 (search),再低成本预览判断价值 (--brief),接着掌握全文结构 (--head),最后只读取关键章节 (--section)。其结果不是“少读一点”,而是让智能体具备了按信息价值分配预算的能力。
DeepXiv 返回的内容是解析好的 Markdown 或 JSON,智能体处理起来毫无压力。例如,--brief 和 --head 的返回样例如下:
📄 MMA: Multimodal Memory Agent
🆔 arXiv: 2602.16493
📅 Published: 2026-02-18T00:00:00
📊 Citations: 0
🔗 PDF: https://arxiv.org/pdf/2602.16493
💻 GitHub: https://github.com/AIGeeksGroup/MMA
🏷️ Keywords: memory-level reliability, temporal decay, conflict-aware consensus, epistemic prudence, visual placebo effect
💡 TLDR:
[research paper] MMA introduces a memory-level reliability framework that dynamically scores retrieved items using source credibility, temporal decay, and conflict-aware network consensus to mitigate overconfidence from stale or inconsistent memories. It reveals the ‘Visual Placebo Effect’—where RAG agents generate unwarranted certainty from ambiguous visual inputs due to latent biases in foundation models—and demonstrates superior performance on FEVER (35.2% lower variance), LoCoMo (higher actionable accuracy, fewer wrong answers), and MMA-Bench (41.18% Type-B accuracy vs. 0.0% baseline) under epistemic-aware evaluation protocols that reward abstention and penalize overconfidence.
{
"arxiv_id": "2602.16493",
"title": "MMA: Multimodal Memory Agent",
"abstract": "Long-horizon multimodal agents depend on external memory; however, similarity-based retrieval often surfaces stale, low-credibility, or conflicting items, which can trigger overconfident errors. We propose Multimodal Memory Agent (MMA), which assigns each retrieved memory item a dynamic reliability score by combining source credibility, temporal decay, and conflict-aware network consensus, and uses this signal to reweight evidence and abstain when support is insufficient. We also introduce MMA-Bench, a programmatically generated benchmark for belief dynamics with controlled speaker reliability and structured text-vision contradictions. Using this framework, we uncover the \"Visual Placebo Effect\", revealing how RAG-based agents inherit latent visual biases from foundation models. On FEVER, MMA matches baseline accuracy while reducing variance by 35.2% and improving selective utility; on LoCoMo, a safety-oriented configuration improves actionable accuracy and reduces wrong answers; on MMA-Bench, MMA reaches 41.18% Type-B accuracy in Vision mode, while the baseline collapses to 0.0% under the same protocol. Code: https://github.com/AIGeeksGroup/MMA.",
"authors": [
{
"misc": {},
"name": "Yihao Lu",
"orgs": [
"School of Computer Science, Peking University"
]
}...
],
"token_count": 17386,
...,
"sections": [
{
"name": "Introduction",
"idx": 0,
"tldr": "MMA introduces a memory-level confidence scoring framework that uses source credibility, temporal decay, and conflict-aware consensus to prioritize reliable memories and prevent retrieval traps, while introducing an incentive-aligned benchmark that rewards epistemic prudence and calibrated abstention.",
"token_count": 1098
}...
],
"categories": [
"cs.CV"
],
"publish_at": "2026-02-18T00:00:00",
"keywords": [
"memory-level reliability",
"temporal decay",
"conflict-aware consensus"
],
"tldr": "[research paper] MMA introduces a memory-level reliability framework that dynamically scores retrieved items using source credibility, temporal decay, and conflict-aware network consensus to mitigate overconfidence from stale or inconsistent memories. It reveals the ‘Visual Placebo Effect’—where RAG agents generate unwarranted certainty from ambiguous visual inputs due to latent biases in foundation models—and demonstrates superior performance on FEVER (35.2% lower variance), LoCoMo (higher actionable accuracy, fewer wrong answers), and MMA-Bench (41.18% Type-B accuracy vs. 0.0% baseline) under epistemic-aware evaluation protocols that reward abstention and penalize overconfidence.",
"github_url": "https://github.com/AIGeeksGroup/MMA"
}
目前,DeepXiv 已覆盖全量 arXiv 数据并保持每日更新,同时正在向更多数据源扩展,包括 PubMed Central (PMC)、ACM、各类 *Rxiv 以及 Semantic Scholar,目标是建立一个覆盖超 2 亿篇开放文献的统一智能体接入层。关键在于,所有数据源都提供一致的服务方式,例如 PMC:
deepxiv pmc PMC544940 --head # 查看全文结构
deepxiv pmc PMC544940 # 查看全文 json
二、一站式能力集成:不只是检索,更是“帮智能体做事”
DeepXiv 自建了优化的论文搜索引擎,但它不止于此。基于搜索,它集成了更丰富的技能:
- 问答与理解:如“论文的核心贡献是什么?”、“实验设置是什么?”。
- 热点追踪:了解每天/每周/每月关于某主题的热点论文。
- 深度调研:如“过去三年关于 Agent Memory 的代表性工作有哪些?”。
这些技能可以通过内置 Skills 或 --help 机制调用。一个热点追踪流程可以非常简洁:
deepxiv trending --days 7 --limit 30 --json # 抓取近期热点论文池
deepxiv paper 2603.28767 --brief # 快速预览论文要点
deepxiv paper 2603.28767 --popularity # 查看传播热度信号
而对于进入一个新研究主题,流程同样直接:
deepxiv search "agentic memory" --limit 20 # 搜索主题相关论文
deepxiv paper 2506.07398 --head # 查看全文结构
deepxiv paper 2506.07398 --section Experiments # 精读关键章节
此外,DeepXiv 还支持调用互联网搜索和 Semantic Scholar 元数据:
deepxiv wsearch "agent memory" # 调用互联网搜索
deepxiv sc 161990727 # 获取 semantic scholar 元数据
为了让任务更连贯,DeepXiv 还内置了 深度调研 Agent,可以将搜索、筛选、阅读、归纳整理串成一条完整链路。你可以直接让它回答复杂问题,也可以将它的能力封装成 Skills,注入到任意 AI Agent 中使用,这对于构建专业化的 人工智能 应用非常有帮助。
pip install "deepxiv-sdk[all]" # 安装完整工具依赖
deepxiv agent config # 配置API key
deepxiv agent query "What are the latest papers about agent memory?" --verbose # 开始深度调研
三、丰富的接入形式:适配全场景需求
DeepXiv 提供了多种接入形态,以满足不同层次的需求:
- CLI(命令行):核心形态,智能体可直接通过脚本编排调用全部能力。
- MCP 接入:可嵌入各类智能体开发框架,使“文献利用”成为智能体标准工具。
- Python SDK:为需要深度定制的开发者提供灵活集成方式。
- 定制化 Skills:基于 DeepXiv,开发者可以快速封装面向具体科研任务的技能,如自动追踪新论文、批量抽取实验结果、生成基线表格等。这为日常科研工作流提供了一个可快速复用、可持续扩展的能力底座,这也是优秀 开源实战 项目的典型价值。
实战演示:用 DeepXiv 整理一个月内的 Agent Memory 论文
理论描述之外,更能体现 DeepXiv 价值的是它在真实任务中的表现。下面这个演示对应一个非常高频的科研需求:
“帮我整理最近1个月 agent memory 相关 paper,看看都在什么数据集上跑的,效果如何,有没有开源。”
如果没有合适的工具,这个过程通常意味着反复切换网页、翻阅 PDF、手动复制粘贴整理成表格。而 DeepXiv 的工作流可以将其拆解为一组自然的自动化动作。
第一步:按主题与时间范围搜索候选论文

首先,围绕主题进行多角度的近义搜索,以尽可能召回候选论文:
deepxiv search "agent memory" --date-from 2026-03-02 --limit 50 --format json
deepxiv search "agentic memory" --date-from 2026-03-02 --limit 50 --format json
deepxiv search "memory agents long-horizon" --date-from 2026-03-02 --limit 50 --format json
很快就能找到 AdaMem, All-Mem, Memex(RL), AndroTMem, LMEB 等高相关论文。
第二步:用 --brief 做低成本筛选
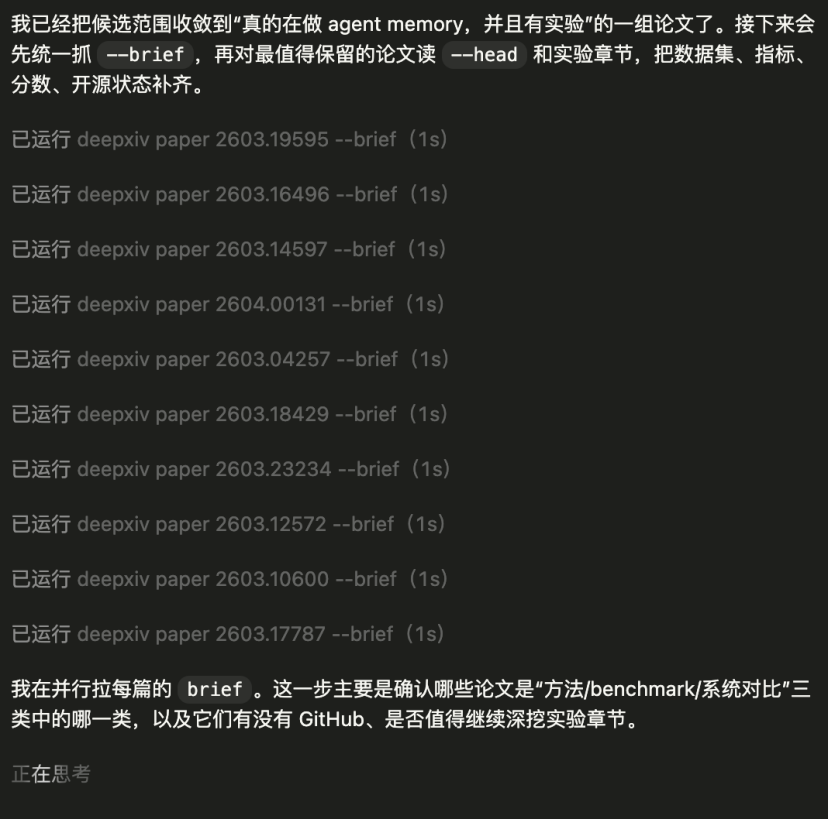
无需通读全文,先预览核心信息:
deepxiv paper 2603.16496 --brief
deepxiv paper 2603.19595 --brief
deepxiv paper 2603.14597 --brief
deepxiv paper 2603.18429 --brief
--brief 提供了标题、时间、TL;DR、关键词、GitHub 链接等。这能以极低的 token 成本完成第一轮判断:论文是否相关?是方法、基准还是系统论文?是否有代码?
第三步:用 --head 看结构,再定点精读实验章节
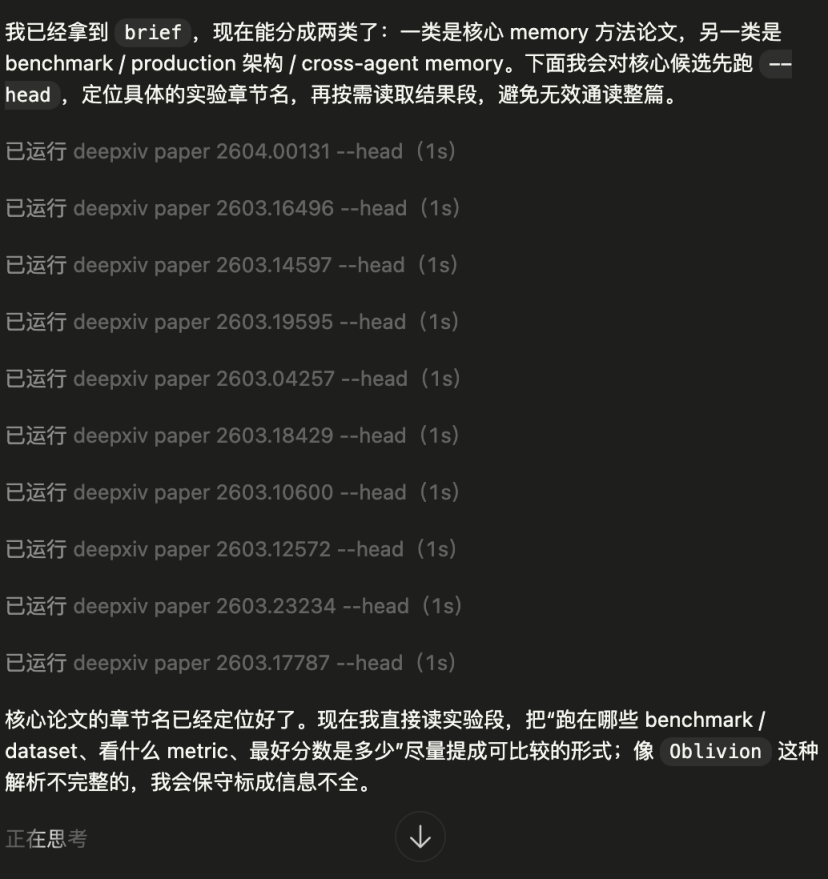
筛出相关论文后,先看结构,再按需读取:
deepxiv paper 2603.16496 --head
deepxiv paper 2603.16496 --section Experiments
deepxiv paper 2603.19595 --head
deepxiv paper 2603.19595 --section Experiments
deepxiv paper 2603.18429 --head
deepxiv paper 2603.18429 --section “Anchored State Memory”

例如,从实验章节中,可以提取出可直接比较的信息:
- AdaMem 在 LoCoMo 和 PERSONAMEM 上评测,LoCoMo 最高到 44.65 F1。
- AndroTMem 提出 AndroTMem-Bench,Gemini-3-Flash 在 ASM 下达到 AMS 59.03 / TCR 65.05。
- Memex(RL) 在 ALFWorld 上把任务成功率从 24.22% 提升到 85.61%。
第四步:自动生成 Markdown 基线表
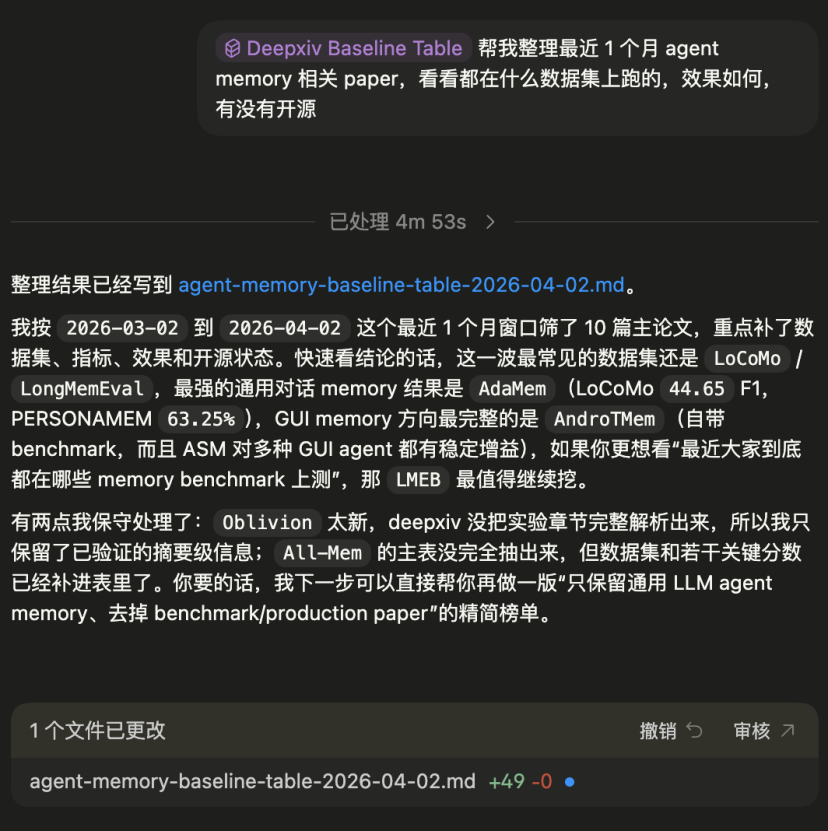
所有信息提取完毕后,最终结果被整理成一份结构化的 Markdown 表格,包含论文标题、arXiv 链接、开源状态、代码地址、使用的数据集/基准、评价指标、核心分数和备注。
这个 Demo 说明了什么?
它不是一个“炫技”任务,而是一个非常日常、真实的科研动作。DeepXiv 首次以贴近智能体工作流的方式完成了它:
- 搜索是结构化的,无需网页解析。
- 预览是低成本的,无需通读全文。
- 阅读是渐进式的,仅展开关键章节。
- 输出是可交付、可复用的,成为研究中的中间产物。
这正是 DeepXiv 要解决的核心问题:不是把论文“搬上CLI”,而是把论文真正变成智能体可以调用、筛选、阅读、分析和交付的一等对象。
如果说传统论文网站服务的是“人类点开页面然后自己读”,那么 DeepXiv 服务的就是“智能体围绕科研任务主动调用文献能力并完成交付”。如果您对如何利用此类工具提升开发效率感兴趣,欢迎到 云栈社区 的相应板块与更多开发者交流探讨。
 发表于 2026-4-9 04:35:52
|
查看: 292|
回复: 0
发表于 2026-4-9 04:35:52
|
查看: 292|
回复: 0
