多 Agent 协作听起来是个很美的概念:让多个 AI 分工合作,效率翻倍。但一旦动手实践,你会发现坑多得让人崩溃:
- 子 Agent 在干什么?父 Agent 要不要去“偷看”一眼?
- 某个 Agent 任务还没完成,用户来问进度了,父 Agent 该怎么回答?
- Agent 列表一有变动,整个 Prompt Cache 就失效,每次都要重新花钱计算?
- 子 Agent 的工具权限该怎么管理?给多了危险,给少了又没法干活?
在 Claude Code 的 AgentTool 模块里,上述问题都被一套完整的工程化方案解决了。
为什么这套方案值得深挖?
因为它不只是一个简单的“调用 API 再返回结果”的工具,而是一个多 Agent 运行时:它内置了 Fork 和 Fresh 两种 Agent 模式、包含了防幻觉的 Prompt 设计、有针对 Prompt Cache 的专门优化、实现了细粒度的工具权限沙箱,甚至还支持后台异步执行与主线程竞速的调度逻辑。
架构图解
设计思路:两种 Agent,两种世界观
Claude Code 的 Agent Tool 本质上实现了一个轻量级 Agent 运行时。其核心设计思想是:协调者(Parent Agent)专注决策,执行者(Sub Agent)专注行动,两者通过严格定义的消息协议通信,互不干扰彼此的上下文。
其中,Fork Agent 和 Fresh Agent 代表了两种截然不同的“哲学”:
- Fork:我是你的“分身”,我继承你的所有记忆和上下文,去干那些你不想让自己的主要上下文被污染的活。
- Fresh:我是个“新人”,你得给我讲清楚所有背景,我从零开始执行任务。
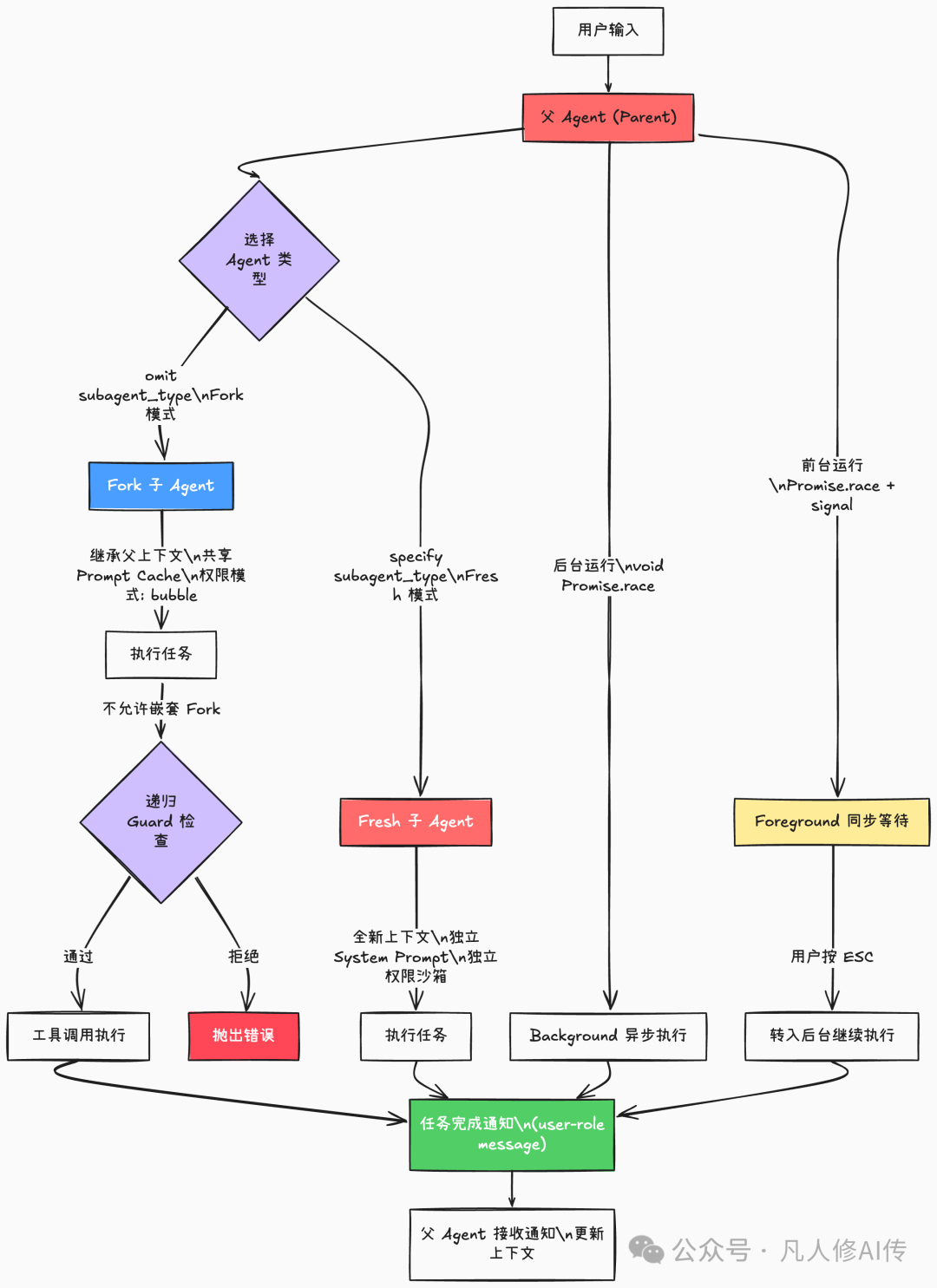
整个系统的设计建立在三大支柱之上:
- Prompt Cache 保护:Agent 列表可以动态变化,但通过 Attachment 消息机制将工具描述部分保持静态,从而避免 Cache 失效。
- 防幻觉协议:通过 “Don’t Peek”(别偷看)和 “Don’t Race”(别抢跑)的 Prompt 设计,从根源上杜绝父 Agent 编造或臆测子 Agent 的执行结果。
- 工具权限沙箱:每个子 Agent 都独立计算其可用的工具池,父 Agent 的权限不会自动“泄漏”给子 Agent,确保了安全边界。
源码亮点
亮点一:Cache 命中率优化,把动态内容“搬”出工具描述
位置:src/tools/AgentTool/prompt.ts
源码:
/**
* Whether the agent list should be injected as an attachment message instead
* of embedded in the tool description. When true, getPrompt() returns a static
* description and attachments.ts emits an agent_listing_delta attachment.
*
* The dynamic agent list was ~10.2% of fleet cache_creation tokens: MCP async
* connect, /reload-plugins, or permission-mode changes mutate the list →
* description changes → full tool-schema cache bust.
*/
export function shouldInjectAgentListInMessages(): boolean {
if (isEnvTruthy(process.env.CLAUDE_CODE_AGENT_LIST_IN_MESSAGES)) return true
if (isEnvDefinedFalsy(process.env.CLAUDE_CODE_AGENT_LIST_IN_MESSAGES)) return false
return getFeatureValue_CACHED_MAY_BE_STALE('tengu_agent_list_attach', false)
}
// 在 getPrompt() 内部的关键逻辑:
const listViaAttachment = shouldInjectAgentListInMessages()
const agentListSection = listViaAttachment
? `Available agent types are listed in <system-reminder> messages in the conversation.`
: `Available agent types and the tools they have access to:
${effectiveAgents.map(agent => formatAgentLine(agent)).join('\n')}`
解读:
直觉上,我们很容易会把可用的 Agent 列表直接塞进工具描述(Prompt)里,这样模型就知道有哪些“帮手”可以调用了,简单直接。
但问题在于:每次 Agent 列表发生变动(例如加载了新的 MCP 插件、用户权限变更、执行了 /reload-plugins 命令),工具描述就变了,这会导致整个工具 Schema 的 Prompt Cache 彻底失效。 根据 Anthropic 的内部数据,这个动态的 Agent 列表占了整个 Fleet 约 10.2% 的 cache_creation tokens,每次失效都意味着要重新花钱计算。
Claude Code 的解法非常巧妙:将 Agent 列表从静态的工具描述中剥离出来,通过单独的 system-reminder 附件消息动态注入到对话流中。这样一来,工具描述本身变成了一个永远不变的静态字符串,Cache 命中率得以大幅提升。动态内容走了另一条“通道”,不再污染工具描述这个影响 Cache Key 的“热路径”。
启示:
在设计 LLM 应用的 Prompt 时,应有意识地区分静态稳定部分和动态变化部分,并尝试将动态内容从会影响 Cache Key 的核心 Prompt 位置剥离出去。这对于任何需要精细控制 Token 成本和生产环境稳定性的应用来说,都是一个极具价值的工程模式。关于更多 AI Agent 的最佳实践,可以在 云栈社区 的人工智能板块找到深入讨论。
亮点二:Fork Agent 的 Cache 魔法,用“占位符”换“共享 Cache”
位置:src/tools/AgentTool/forkSubagent.ts
源码:
// Fork Agent 的关键:用一个占位符工具调用替换父 Agent 的实际调用
// 这让子 Agent 可以重用父 Agent 的 Prompt Cache
const forkMessages = parentMessages.map(msg => {
if (msg.role === 'assistant') {
return {
...msg,
content: msg.content.map(block => {
if (block.type === 'tool_use') {
// Replace actual tool results with placeholder to preserve cache
return {
...block,
input: { command: FORK_PLACEHOLDER_TEXT },
}
}
return block
}),
}
}
return msg
})
const FORK_PLACEHOLDER_TEXT = 'Fork started — processing in background'
解读:
Fork Agent 需要继承父 Agent 的完整消息历史,这听起来很合理。但这里存在一个隐蔽的问题:父 Agent 的消息历史中可能包含具体的工具调用及其结果(例如某次 Bash 命令的详细输出),这些内容每次执行都可能不同。如果原样传递给子 Agent,就会导致子 Agent 无法命中父 Agent 已经建立好的 Prompt Cache。
Claude Code 的解决方案是:在创建 Fork 子 Agent 时,遍历父 Agent 的消息历史,将其中的所有 tool_use 块的 input 字段,统一替换为同一个占位符文本 ‘Fork started — processing in background’。这样,无论父 Agent 之前实际执行过什么,Fork 出来的所有子 Agent 所“看到”的父级消息结构都是一模一样的,从而实现了 Prompt Cache 的共享。
值得注意的是,子 Agent 完成任务后,是通过 user-role 类型的消息来通知父 Agent,而不是 tool_result。这是因为 user-role 消息是对话的自然组成部分,模型能更好地理解“这是一个来自其他参与者的背景情况说明”。
启示:
在多 Agent 系统中,上下文传递和缓存设计是两个需要独立、审慎考虑的问题。在传递上下文时,必须留意哪些内容会成为计算 Cache Key 的一部分。必要时,可以通过引入标准化“占位符”的方式来“稳定”消息结构,从而换取更高的缓存复用率。
亮点三:三层权限沙箱,精确控制工具访问
位置:src/tools/AgentTool/index.ts
源码:
// 子 Agent 的工具池计算逻辑(简化版)
function computeSubAgentTools(
parentTools: Tool[],
agentDef: AgentDefinition,
permissionMode: PermissionMode,
): Tool[] {
// Layer 1: 从父工具池出发
let tools = parentTools
// Layer 2: 应用 Agent 定义中的工具过滤
if (agentDef.tools !== undefined) {
tools = tools.filter(t => agentDef.tools!.includes(t.name))
}
// Layer 3: 根据权限模式决定 bubble vs sandbox
if (permissionMode === 'bubble') {
// Fork 模式:权限向上冒泡到父 Agent
return tools
} else {
// Fresh 模式:独立权限沙箱,不继承父 Agent 权限
return tools.map(t => withRestrictedPermissions(t))
}
}
解读:
权限管理堪称多 Agent 系统中最容易滋生安全漏洞的环节。Claude Code 采用了一个清晰的三层过滤模型来计算子 Agent 最终可用的工具列表:
- 从父工具池出发:这是第一道安全闸。子 Agent 能接触到的工具,首先不可能超出其父 Agent 自身已被授权的工具范围。
- Agent 定义过滤:每个 Agent 类型都可以在其定义中明确声明自己需要哪些工具(遵循最小权限原则)。系统会据此对父工具池进行筛选。
- 权限模式决定冒泡行为:这是最精妙的一层。
- 在
Fork 模式下,权限确认可以“冒泡”(bubble)到父 Agent。即,如果父 Agent 已经获得了执行某个工具的权限,那么其 Fork 出来的子 Agent 可以直接使用该工具,无需再次向用户申请权限。
- 在
Fresh 模式下,子 Agent 拥有独立的权限沙箱。即使父 Agent 有权限,Fresh 子 Agent 要使用工具时,仍需单独向用户申请权限(代码中的 withRestrictedPermissions 即表示此状态)。
这三层过滤的顺序至关重要:必须先基于父级权限和 Agent 定义缩小工具范围,最后再根据协作模式决定如何处理剩余工具的权限确认逻辑。如果顺序颠倒,可能导致最终的计算结果与预期不符。
启示:
构建多 Agent 系统时,权限模型绝不应该是一个事后补丁。必须从设计伊始就明确:子 Agent 的权限来源是什么?是继承、过滤还是独立计算?“最小权限”原则在 Agent 系统中比在传统软件中更为重要,因为 AI Agent 的行为路径更难被完全预测,严格的权限沙箱是防止意外或恶意操作的关键防线。这种对安全性和工程细节的重视,正是优秀 源码分析 所追求的目标。
希望通过对 Claude Code 中 AgentTool 的这番剖析,能为你设计自己的多智能体协作系统带来一些切实可行的启发。如果你对这类工程实现细节感兴趣,欢迎在 云栈社区 继续交流探讨。
 发表于 2026-4-9 04:45:46
|
查看: 205|
回复: 0
发表于 2026-4-9 04:45:46
|
查看: 205|
回复: 0
