继 Llama 系列之后,Meta 近日通过其超级智能实验室(Meta Superintelligence Labs,简称 MSL)发布了一款全新的大模型 Muse Spark。该模型的发布由 MSL 负责人 Alexandr Wang 在社交媒体上宣布。与以往不同,Muse Spark 是一个闭源模型。
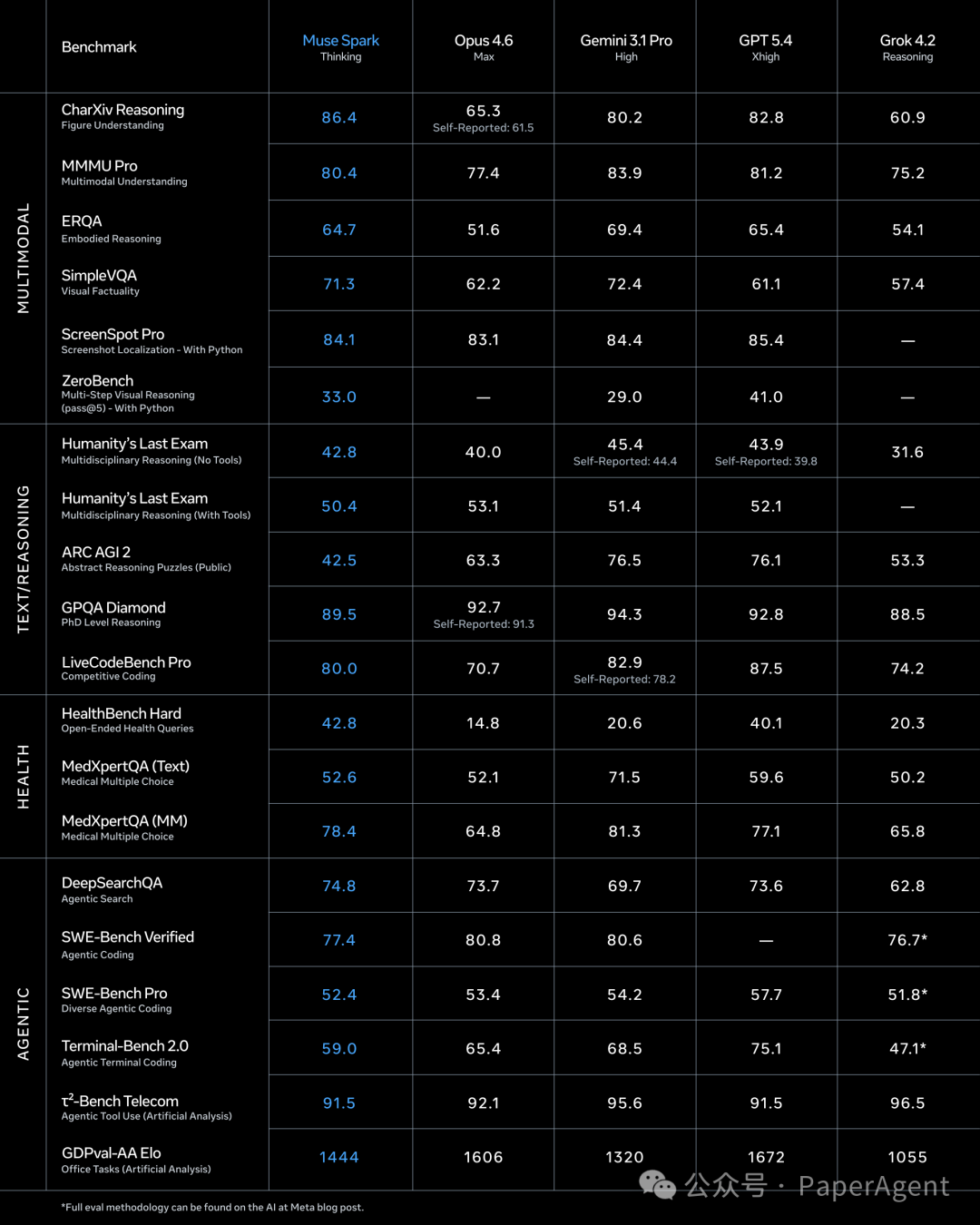
根据官方公布的基准测试数据,Muse Spark 在多模态理解、复杂推理、健康问答及智能体式编码等多项任务上表现亮眼,与 OpenAI、Anthropic、Google 等公司的最强模型同台竞技。
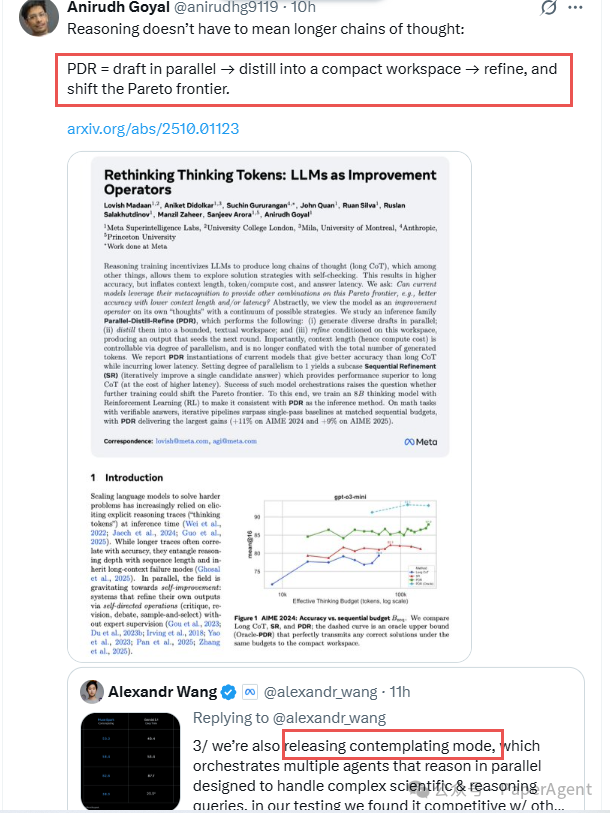
同时,Alexandr Wang 宣布还将发布「沉思模式」(contemplating mode),该模式可编排多个并行推理的 Agent,专门用于处理复杂的科学与推理类查询。
这背后隐藏着 MSL 此前公开的一项核心推理技术:PDR(Parallel-Draft-Refine,并行起草-精炼)。这项研究旨在重新思考大模型的推理范式,其核心观点是:
让大模型更好地推理,不一定要靠“想得更久”(更长的思维链),而可以通过“并行起草+精炼”的方式来突破性能瓶颈。
当前,以 OpenAI o1、DeepSeek-R1 为代表的大语言模型普遍采用长思维链(Chain-of-Thought, CoT) 来提升推理能力,即模型在输出最终答案前先生成大量“思考 Token”。然而,这种范式存在三个显著问题:
- 上下文长度爆炸:推理深度与序列长度强耦合,易引发长上下文中的信息丢失等问题。
- 成本与延迟高昂:更长的序列意味着更高的计算成本和用户等待时间。
- 训练-测试不匹配:模型训练时针对的是单一长轨迹进行优化,但实际推理可能需要多轮迭代。
LLM 作为“改进算子”(Improvement Operator)
这项名为《Rethinking Thinking Tokens: LLMs as Improvement Operators》的研究提出,可以将 LLM 本身视为一个改进算子,作用于自身的“思维”之上。关键在于解耦推理深度与上下文长度——通过短上下文的迭代精炼,配合一个紧凑的、重新合成的工作空间,实现更高效的推理。
两大核心推理框架
论文提出了两种具体的算子实现框架:
Sequential Refinement (SR):顺序精炼
- 单一路径迭代:模型基于当前解答,迭代生成改进版本,类似于“自我修正”。
- 可引入工作空间:在改进过程中,可以引入局部工作空间(例如对当前解的错误分析)来指导下一轮生成。
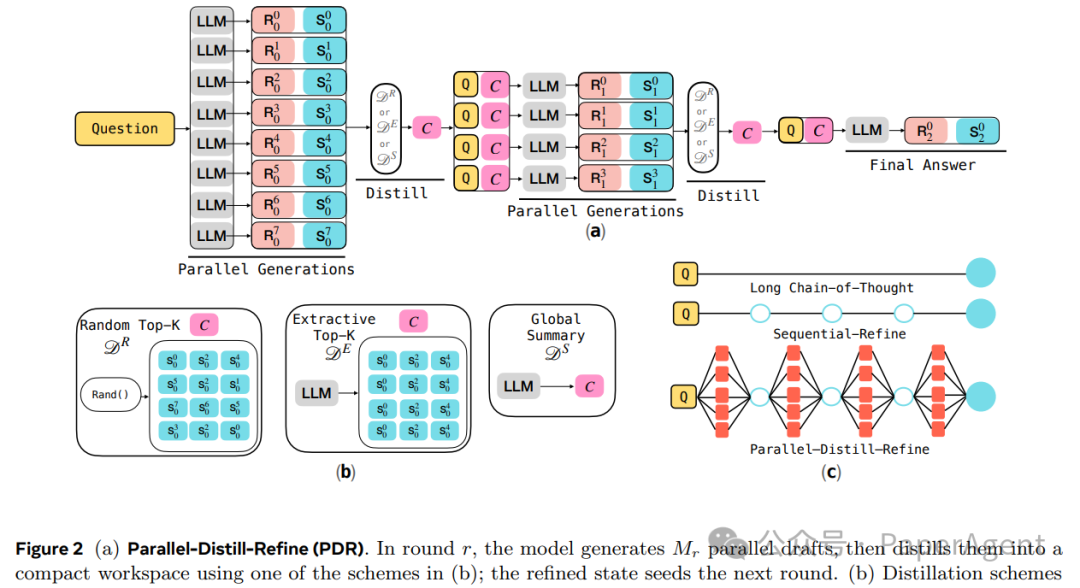
Parallel-Distill-Refine (PDR):并行-蒸馏-精炼
- 并行(Parallel):在每一轮推理中,并行生成多个(
M_r 个)独立的思维草稿,以引入多样性。
- 蒸馏(Distill):将这些并行的草稿“压缩”或“提炼”成一个紧凑的文本工作空间(
C)。
- 精炼(Refine):基于这个合成的工作空间,生成下一轮的输入,进行进一步优化。
精确定义预算:控制成本与延迟
为了公平比较不同方法,论文定义了两个关键的预算指标:
B_seq(顺序预算):最终被采纳的答案路径上所消耗的 Token 总数。这直接对应于用户体验的延迟(Latency)。B_total(总预算):所有并行调用(包括最终被丢弃的分支)所消耗的 Token 总数。这直接对应于计算成本。
PDR 的核心优势在于:它可以通过增加并行度(从而增加 B_total)来提升准确率,同时保持 B_seq 基本不变,这意味着在不增加延迟的情况下获得了性能提升。
短上下文迭代 vs 长思维链:效能对决
研究在 AIME 2024 和 AIME 2025 数学竞赛题目上,对 Gemini-2.5-flash 和 GPT-o3-mini 模型进行了测试。
PDR vs 长CoT:准确率与效率的双赢
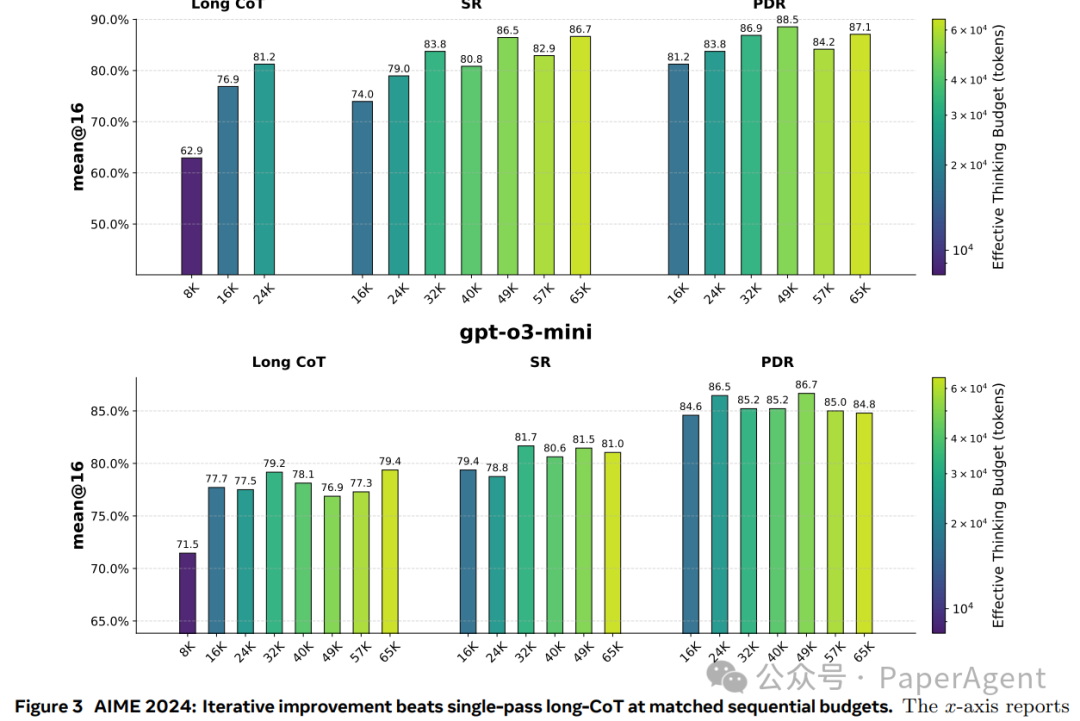
关键数据发现:
- AIME 2024:PDR 相比传统长 CoT 带来高达 +11% 的准确率提升(例如,o3-mini 在约49K总预算下,准确率从76.9%提升至86.7%)。
- AIME 2025:PDR 相比长 CoT 提升约 +9%。
- 形成新帕累托前沿:在
B_seq(延迟)-准确率平面上,PDR 的数据点构成了新的帕累托最优边界,显著优于长 CoT。
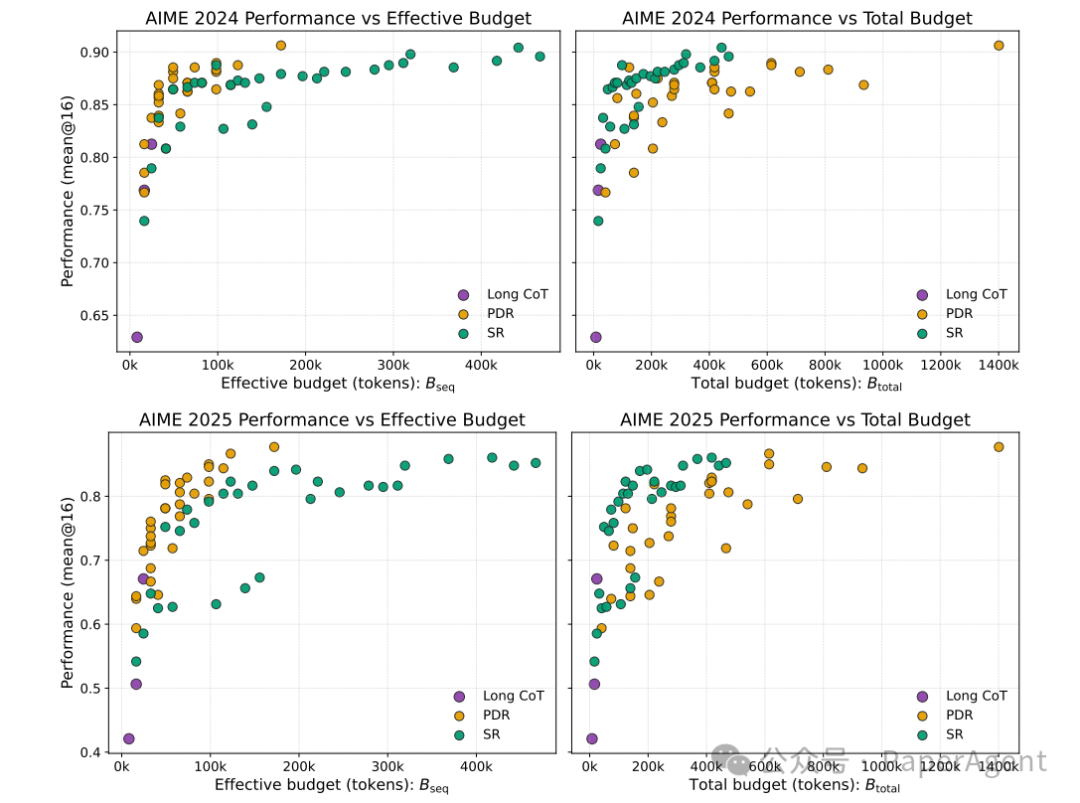
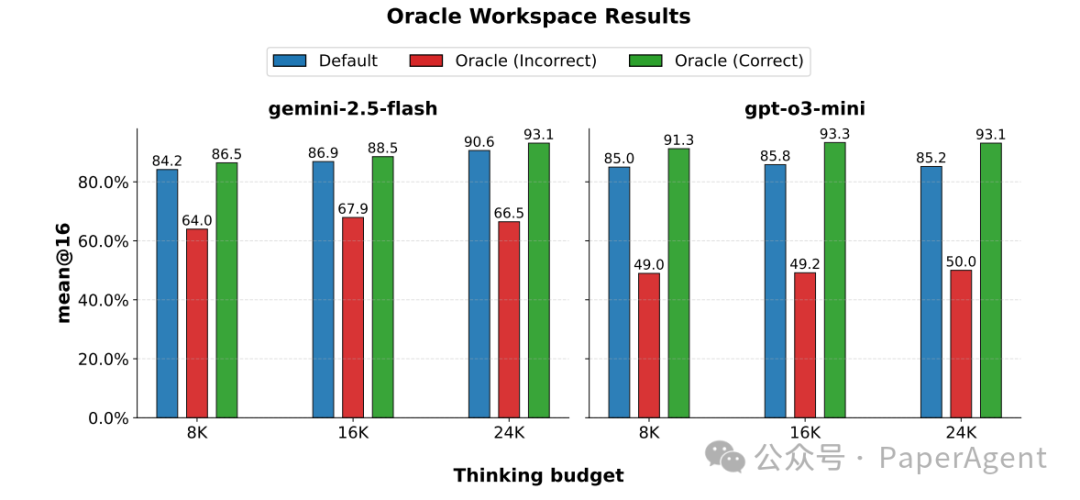
深入分析:模型的元认知能力是关键
PDR 的成功很大程度上依赖于模型自身的元认知能力,包括验证、精炼、信息压缩和多样化生成等。研究者通过“Oracle Workspace”实验验证了这一点:如果提供给模型的工作空间里全是错误答案,性能会大幅下降;反之,如果全是正确答案,性能则会显著提升。
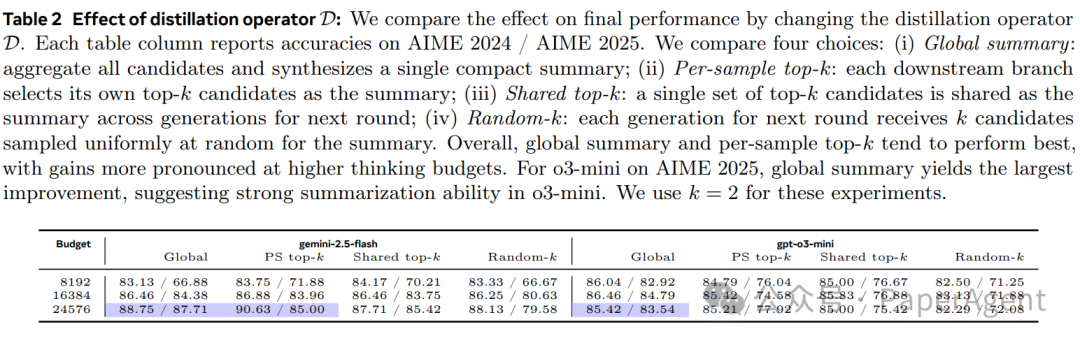
同时,蒸馏策略的选择也至关重要。实验表明,“全局摘要”和“每样本Top-K”这两种策略通常效果最好,说明模型需要有效的信息压缩与合成机制。
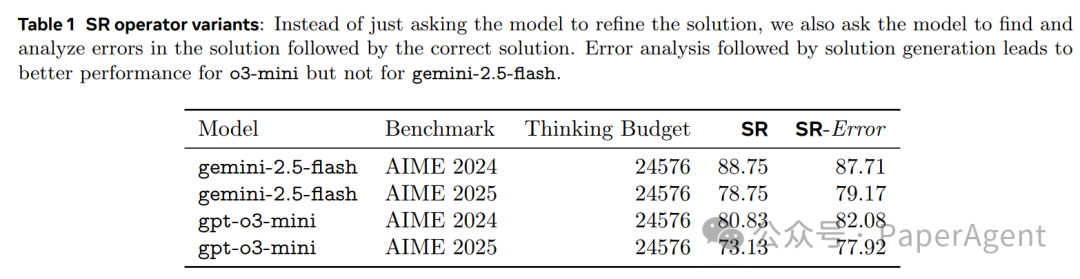
SR的变体:引入错误分析提升效果
对于顺序精炼(SR),研究尝试了让模型先分析当前解答中的错误,再基于此生成修正。这种“SR-Error”变体在 GPT-o3-mini 上带来了显著提升,但在 Gemini-2.5-flash 上效果不明显,这可能揭示了不同模型在自我验证能力上的差异。
总结与资源
PDR 技术为大模型推理提供了一种新范式:通过并行的“头脑风暴”和高效的“会议纪要”(工作空间),在可控的延迟内达成更优的解决方案。这项技术很可能就是 Meta Muse Spark 模型中“沉思模式”乃至其卓越推理表现的基石。对于从事 AI 基础设施与优化的小伙伴来说,这篇论文提供了宝贵的思路。
相关资源链接:
https://arxiv.org/pdf/2510.01123
Rethinking Thinking Tokens: LLMs as Improvement Operators
https://ai.meta.com/blog/introducing-muse-spark-msl/
对这类前沿的模型优化技术与开源实战分析感兴趣?欢迎在云栈社区继续交流探讨。
 发表于 2026-4-10 00:46:40
|
查看: 146|
回复: 0
发表于 2026-4-10 00:46:40
|
查看: 146|
回复: 0
