在社交媒体上,一张来自某大厂员工的月供账单截图火了,月供金额仅为 0.44元。
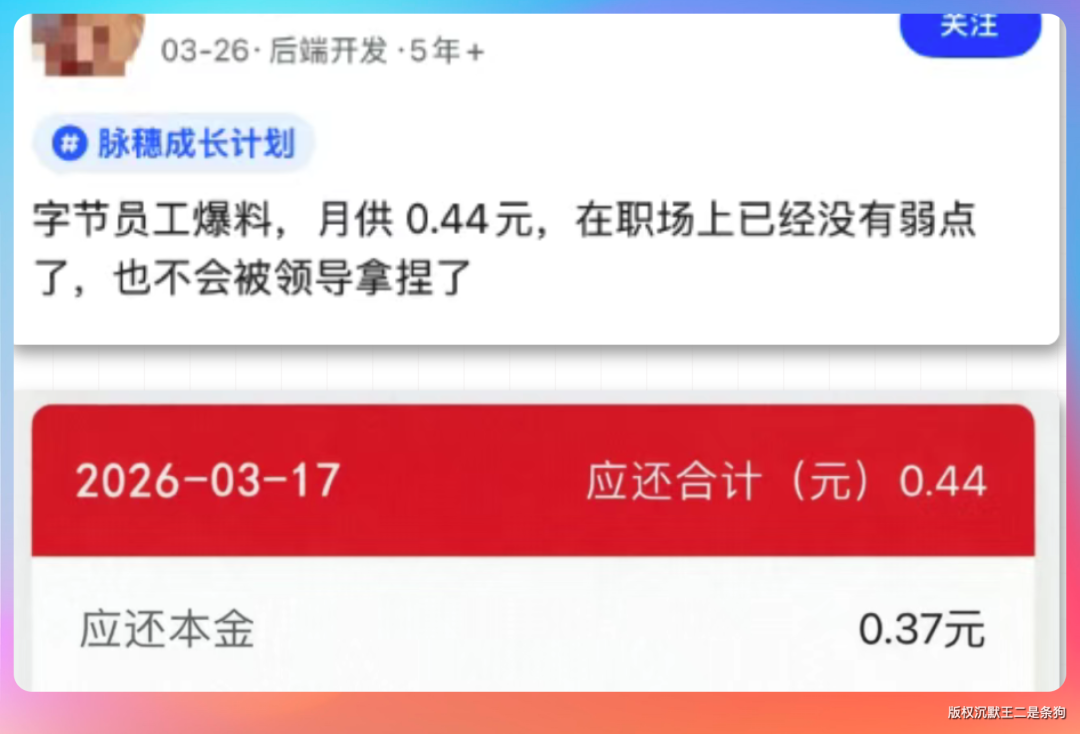
有网友戏称,当你的月供不到一块钱时,在职场上就已经“没有弱点”了,不再是那个会被轻易拿捏的打工人。
玩笑归玩笑,现实是房贷压力确实影响着许多人的职业选择。想要早日还清贷款,进入大厂工作,用更高的收入和公积金来覆盖月供,是不少技术人的选择路径。而近年来的面试,无论你面的是Java后端还是其他岗位,AI 相关知识的考察浓度正变得越来越高。
最近,一份关于腾讯PCG部门的RAG项目面试经历在云栈社区引起了讨论。下面,我们就结合这份面经,深入剖析一个名为“派聪明”的RAG项目可能会被问到的技术细节,为正在准备面试的同学提供一份详尽的参考。

项目拷打
01、给你5分钟,介绍RAG项目整体流程,说出1-2个设计难点
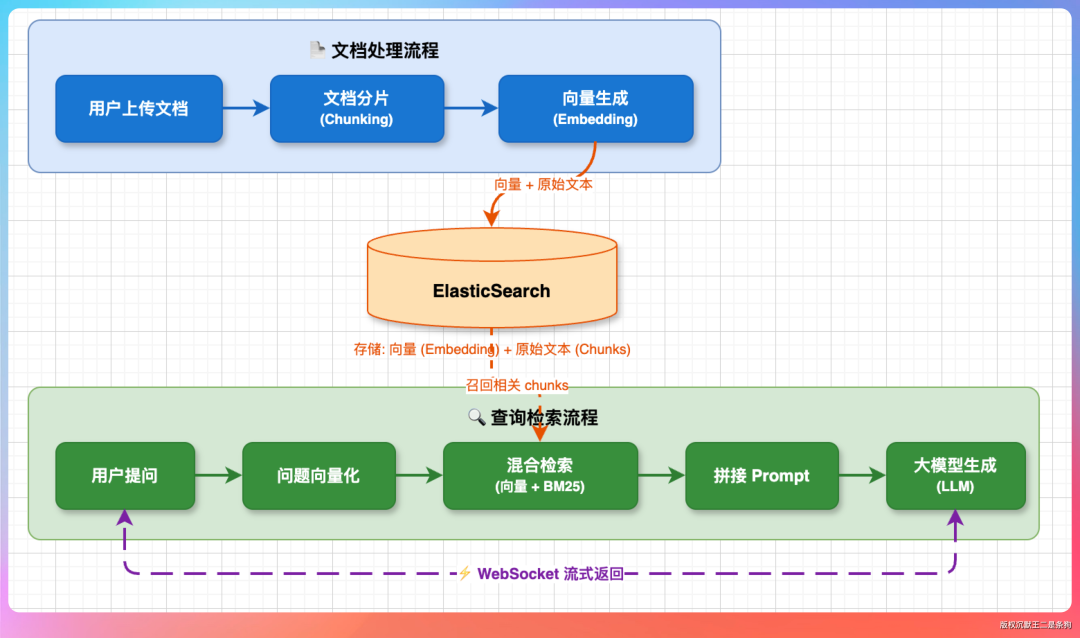
“派聪明”这个RAG项目的整体流程可以概括如下:
- 文档处理流程:用户上传文档(如PDF、Word)后,系统会先进行文档分片(Chunking),将长文档切分成若干个语义相对完整的片段(Chunk)。接着,为每个Chunk生成对应的向量(Embedding)。
- 存储:生成的向量和原始Chunk文本一同存入 ElasticSearch 中,构建起一个支持向量检索和全文检索的混合索引。
- 查询检索流程:当用户提问时,系统将问题同样向量化,然后在ES中执行混合检索(向量相似度检索 + BM25关键词检索),召回最相关的若干个Chunk。
- 生成与返回:将召回的Chunk文本拼接成Prompt,提交给大语言模型(LLM)生成最终答案,并通过WebSocket以流式(Streaming)方式实时返回给前端。
在这个流程中,至少有两个值得深入探讨的设计难点:
第一,分片策略(Chunking Strategy)。这并非简单的“一刀切”。分片过短会导致上下文信息丢失,检索回来的片段可能无法让LLM理解并生成连贯的答案;分片过长则可能超出Embedding模型的Token输入限制,同时也会稀释关键信息的语义密度,降低检索精度。一个常见的优化方案是采用固定大小分片并添加重叠(Overlap),确保相邻Chunk之间有一定内容交叠,从而避免关键信息恰好落在切割边界上而被“腰斩”。
第二,对话上下文管理。在多轮对话中,需要将历史问答记录作为上下文输入给LLM,以保持对话的连贯性。然而,随着对话轮次增加,上下文长度很容易超出LLM的Context Window限制。如何在不丢失重要历史信息的前提下,有效控制输入给模型的Token数量,是RAG项目中一个非常实际的工程难题。
02、除了分片上传,有做断点续传吗?为什么这样设计?
是的,为了实现更好的用户体验,“派聪明”项目实现了断点续传功能。
其核心思路是:将一个大文件预先在客户端切割成多个固定大小的分片(Chunk),然后分片逐个上传。服务端会记录每一个分片的上传状态。如果上传过程因网络波动或页面刷新而中断,再次上传时,前端会先查询已上传的分片列表,只上传那些缺失的分片,最后再由服务端将所有分片合并成完整的文件。
技术实现上,这里用到了 Redis 的 Bitmap。
每个文件对应一个Redis Bitmap,Bitmap中的每一个位(bit)代表该文件的一个分片。位值为1表示该分片已上传成功,为0则表示未上传。前端在上传前,通过查询这个Bitmap就能精确知道哪些分片需要上传,从而实现“续传”。

为什么选择这样的设计?
主要出于对用户体验和服务器资源的考虑。用户上传体积较大的文档(如几十兆的PDF)时,网络不稳定是常见情况。如果没有断点续传,一次失败就要从头再来,用户体验极差,且浪费服务器带宽和计算资源(因为每次都要重新接收和解析整个文件)。而基于Bitmap的实现方案,具有成本低、实现简单、效率高的优点,用极小的内存开销(例如,记录1000个分片的状态仅需约125字节)就解决了实际问题。
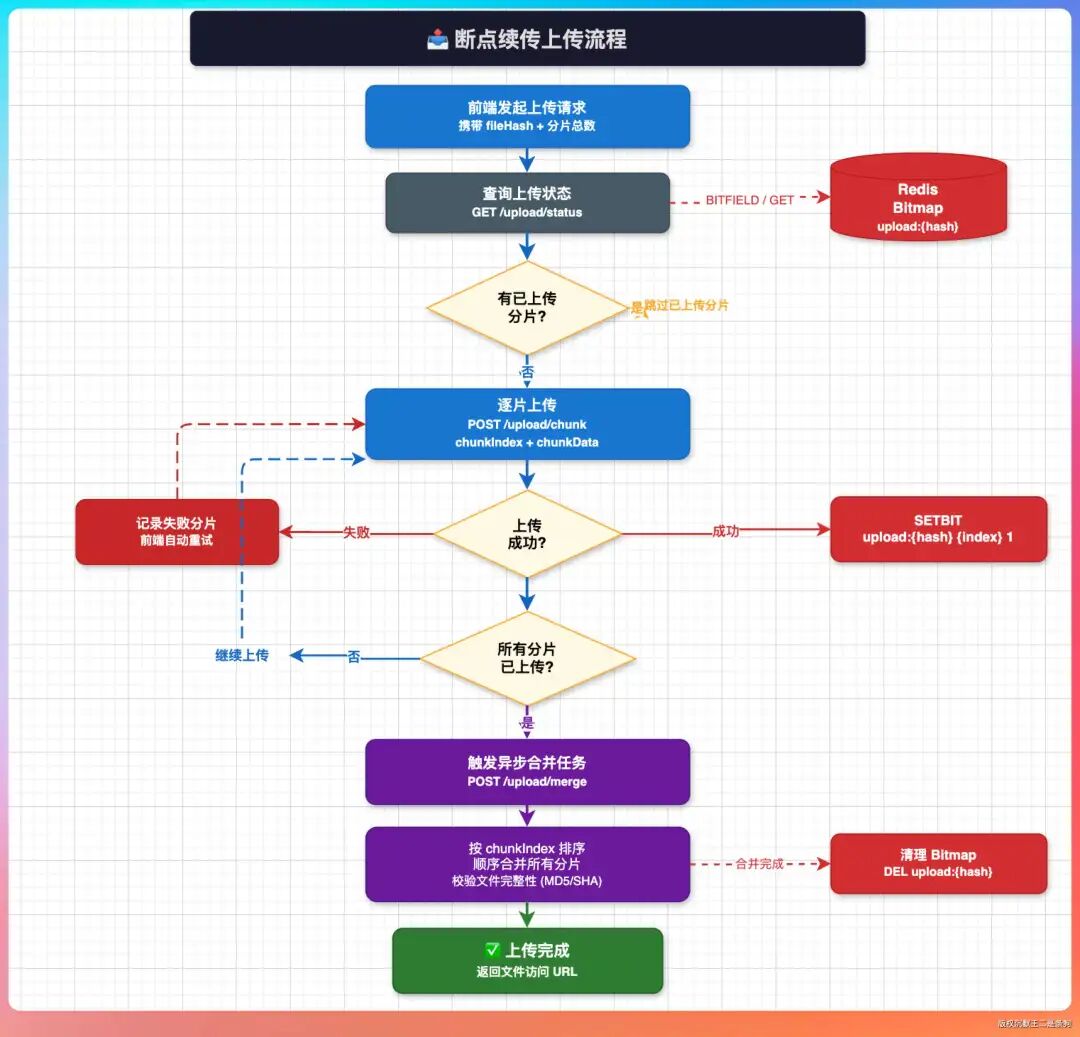
值得一提的是,文件合并操作通常在所有分片上传完成后,由后端异步触发(例如使用MinIO等对象存储的合并接口)。合并完成后,系统会立即启动后续的文档解析、分片和向量化入库流程,实现全链路的异步处理。
03、既然用了Bitmap存储分片索引,Redis底层怎么实现的?还有哪些使用场景?
Redis的Bitmap并非一种独立的数据结构,它本质上是对String类型的一种位操作封装。
在Redis中,String类型是以字节数组(byte array)的形式存储的。SETBIT、GETBIT、BITCOUNT等Bitmap操作命令,实际上就是在对这个字节数组执行底层的位运算。每个字节有8个bit,所以一个512MB的String最大可以表示约42亿(2^32)个位,空间效率极高。
例如,执行命令 SETBIT mykey 7 1:
- Redis会找到(或创建)key为
mykey的字符串。
- 计算第7个bit位于第几个字节(
7 / 8 = 0,即第一个字节)的第几位(7 % 8 = 7,即第7位,从0开始计数)。
- 将该位的值设置为1。
除了分片上传进度记录,Bitmap还有其他经典使用场景:
- 用户签到系统:以用户ID作为偏移量(offset),以日期为key。用户签到即执行
SETBIT,统计某用户当月签到天数用BITCOUNT,统计某天哪些用户签到可以用GETBIT遍历用户ID范围。
- 活跃用户统计:每天用一个Bitmap记录活跃用户。要计算连续7天活跃的用户,只需对7个Bitmap执行
BITOP AND操作取交集即可。
- 布隆过滤器(Bloom Filter):在Redis 4.0推出原生Bloom Filter模块之前,使用多个Bitmap来模拟实现布隆过滤器是一种常见方案,用于快速判断某个元素是否可能存在于一个超大集合中。
04、混合检索用了embedding模型+IK分词器,为什么这么设计?
这是为了结合语义检索和关键词检索的优势,实现更精准的召回。
- 向量检索(Embedding模型):优势在于语义匹配。它能理解用户问题的“意图”,即使查询词和文档用词不同但意思相近,也能被召回。例如,“如何提升性能”和“怎样进行优化”的向量可能很接近。
- BM25检索(配合IK分词器):优势在于精确的关键词匹配。它基于词频和逆文档频率进行统计,对于专有名词、产品名、特定技术术语等需要精确匹配的场景非常有效。但它的缺点是不理解语义,对同义词、近义词不敏感。
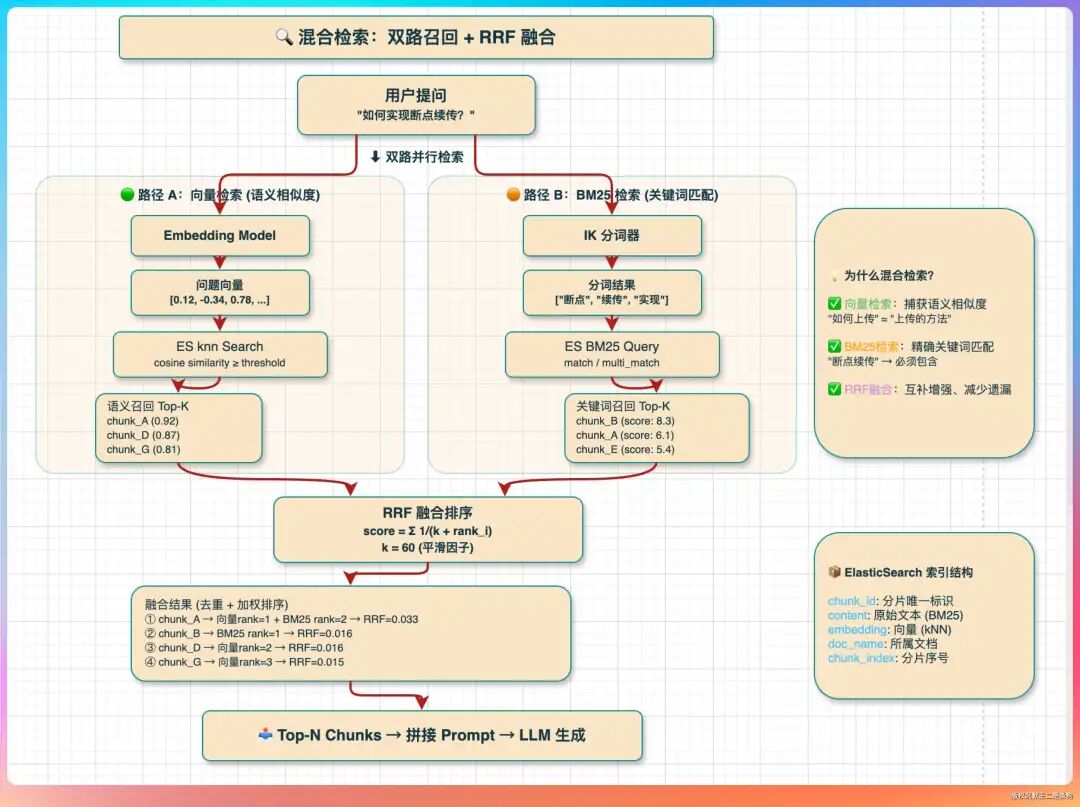
两者结合,可以优劣互补。向量检索负责捕捉语义层面的相关性,BM25负责确保关键术语的精确命中。IK分词器在这里的作用至关重要,因为它是专门针对中文优化的分词工具。中文没有空格分隔,直接按字切分或使用英文分词器效果很差。IK分词器能将“检索增强生成”正确地切分为“检索”、“增强”、“生成”等词,使BM25算法能够正常工作。
最后,系统通过RRF(Reciprocal Rank Fusion) 或加权融合等算法,将两路检索结果合并、去重、重新排序,得到最终的Top-N个相关Chunk,再送入LLM生成答案。
05、BM25算法和KNN算法分别是什么?具体怎么实现的?
BM25(Best Matching 25) 是信息检索领域的经典算法,可以看作是TF-IDF的改进版。其核心思想是衡量查询词与文档的相关性,公式考虑了:
- 词频(TF):一个词在文档中出现的次数越多,相关性可能越高。
- 逆文档频率(IDF):一个词在所有文档中越常见(如“的”、“是”),其区分度越低,权重应减小。
- 文档长度归一化:避免长文档仅仅因为包含更多词汇而获得不合理的高分。
在 ElasticSearch 中,BM25是其默认的相似度评分算法,开发者无需手动实现,在创建索引和查询时直接使用即可。
KNN(K-Nearest Neighbors,K近邻) 在向量检索场景下,指的是查找与查询向量在向量空间中最邻近的K个向量。
具体实现上,在项目中:
- 文档Chunk通过Embedding模型转换为固定维度的稠密向量(dense vector)。
- 在ElasticSearch的Mapping中,定义一个
dense_vector类型的字段来存储这些向量。
- 用户提问时,问题也被转换为同维度的向量。
- 执行ES的
knn查询,指定query_vector和k值(返回最近邻的数量),ES会计算余弦相似度(Cosine Similarity)或点积(Dot Product)并返回最相似的K个文档。
这使得项目无需引入专门的向量数据库(如Milvus、Pinecone),利用ElasticSearch 8.x及更高版本的原生支持即可高效完成向量检索。
06、文档分片存储怎么考虑的?
文档分片存储的设计需要综合权衡多个因素:
- 分片大小(Chunk Size):这是最关键的参数。太小(如100个token)会导致每个Chunk信息不完整,检索回来的片段缺乏足够上下文,LLM难以生成好答案。太大(如2000个token)可能超出Embedding模型输入限制,且会稀释核心语义,降低检索精度。经过实践,512个token左右是一个较为通用和合理的平衡点。
- 重叠(Overlap):在相邻Chunk之间保留一定重叠(如50个token),可以有效防止关键信息被生硬地切断在两个Chunk之间,确保每个Chunk在边界处保持语义的连贯性。
- 元数据(Metadata):每个Chunk在存储时,必须附带丰富的元数据,例如:来源文档的唯一ID、该Chunk在文档中的序号(chunk_index)、原始文件名等。这有助于答案溯源(告诉用户答案来自哪份文档的哪个部分),也便于实现如“滑动窗口”式的多Chunk召回。
- 存储架构选择:采用分层存储策略,各司其职,是保证系统性能与可扩展性的关键。
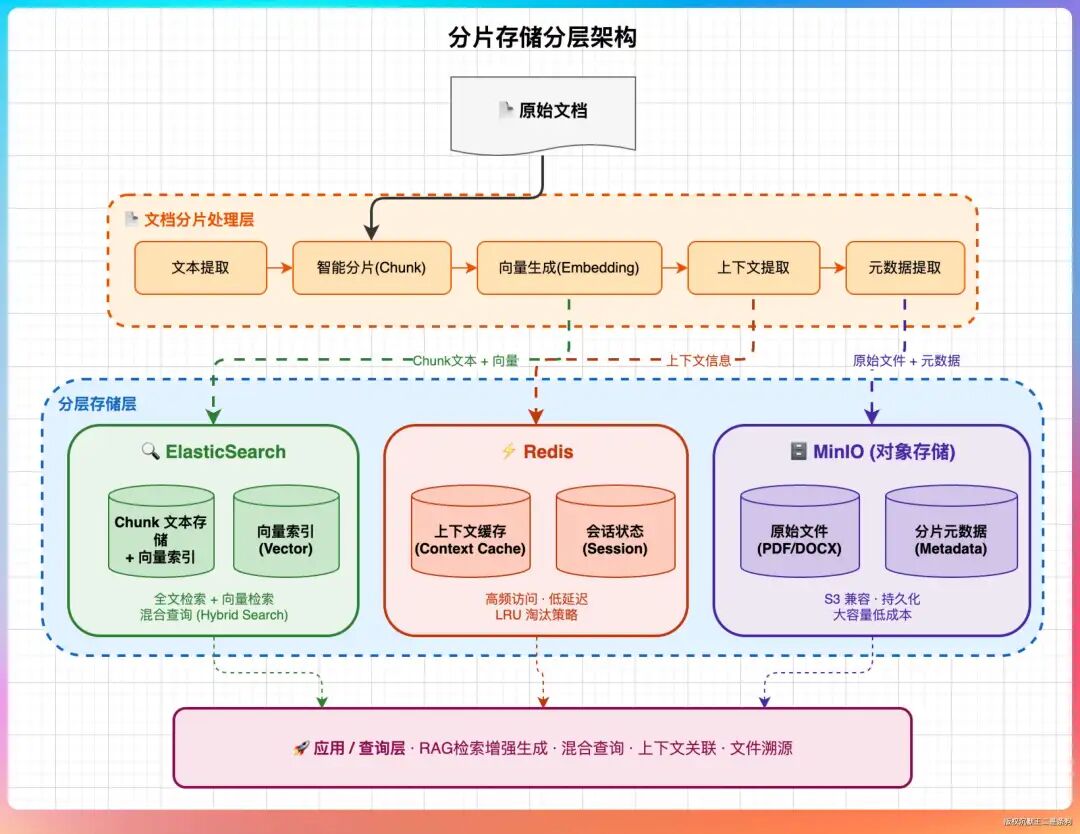
- ElasticSearch:存储Chunk的原始文本和对应的向量,承担核心的混合检索任务。
- Redis:存储高频访问的对话上下文、会话状态等,利用其内存数据库的低延迟特性。
- 对象存储(如MinIO):持久化保存用户上传的原始文件(PDF/DOCX)及分片元数据,具备大容量、低成本的特点。
07、为什么选WebSocket?
RAG项目选择WebSocket,主要是为了实现流式输出(Streaming Response)。
大语言模型生成答案并非一次性完整输出,而是一个Token接着一个Token地“思考”和“吐出”。如果等待LLM全部生成完毕再通过HTTP一次性返回,用户会面对长时间的白屏等待,体验非常糟糕。
WebSocket支持服务端主动向客户端推送数据,因此可以将LLM实时生成的每个Token立刻推送给前端。用户看到的效果就是答案像打字一样逐字出现,这与ChatGPT、文心一言等主流AI产品的交互体验一致。
相比于另一种实现流式推送的技术SSE(Server-Sent Events),WebSocket是全双工的,这意味着连接建立后,客户端和服务端可以随时互发消息。例如,用户可以在答案生成到一半时发送“停止”指令,服务端能即时接收并中断LLM的生成过程,更加灵活。
当然,如果场景仅需服务端向客户端的单向推送,SSE也是一个更轻量、实现更简单的选择。
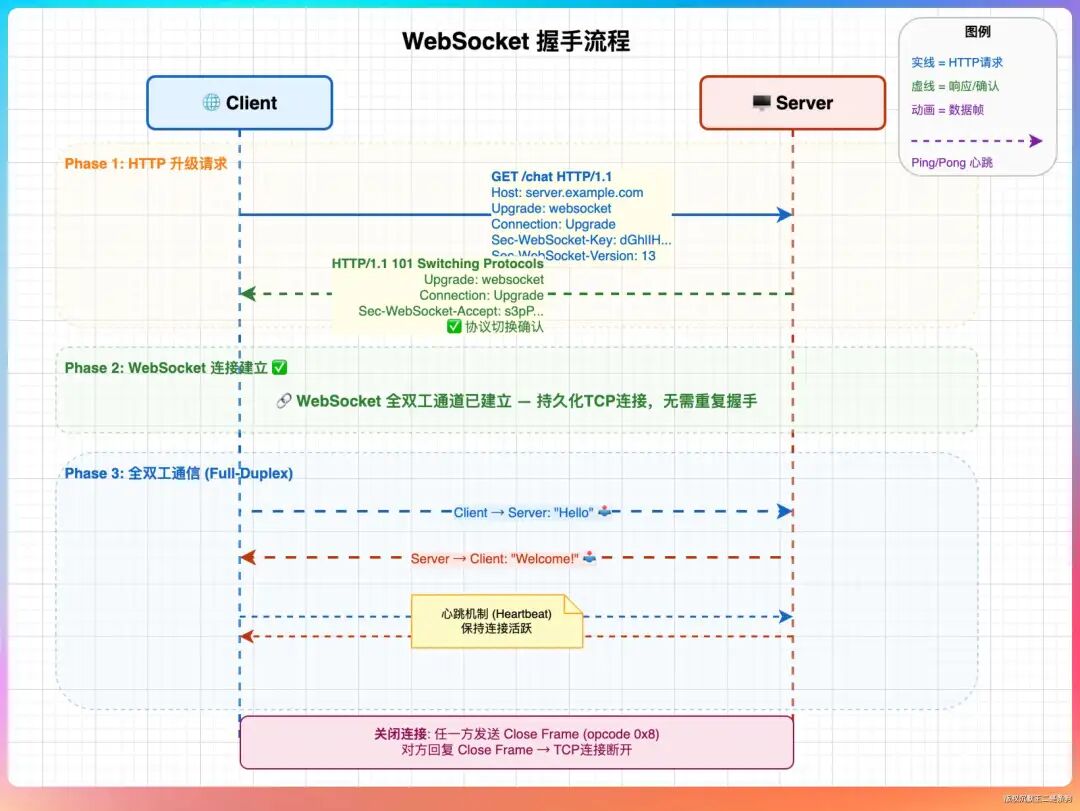
WebSocket基于什么协议?
WebSocket协议本身基于TCP,但其握手阶段借用了HTTP/1.1协议。具体过程如下:
- 客户端发起一个普通的HTTP GET请求,并在请求头中包含
Upgrade: websocket 和 Connection: Upgrade 等特殊字段。
- 服务端若支持WebSocket,则返回HTTP 101状态码(Switching Protocols),表示同意将协议升级为WebSocket。
- 此后,该TCP连接将不再使用HTTP协议进行通信,转而使用WebSocket帧协议,实现持久的全双工通信。
其默认端口与HTTP/HTTPS一致(ws对应80,wss对应443),便于穿透各种网络防火墙。
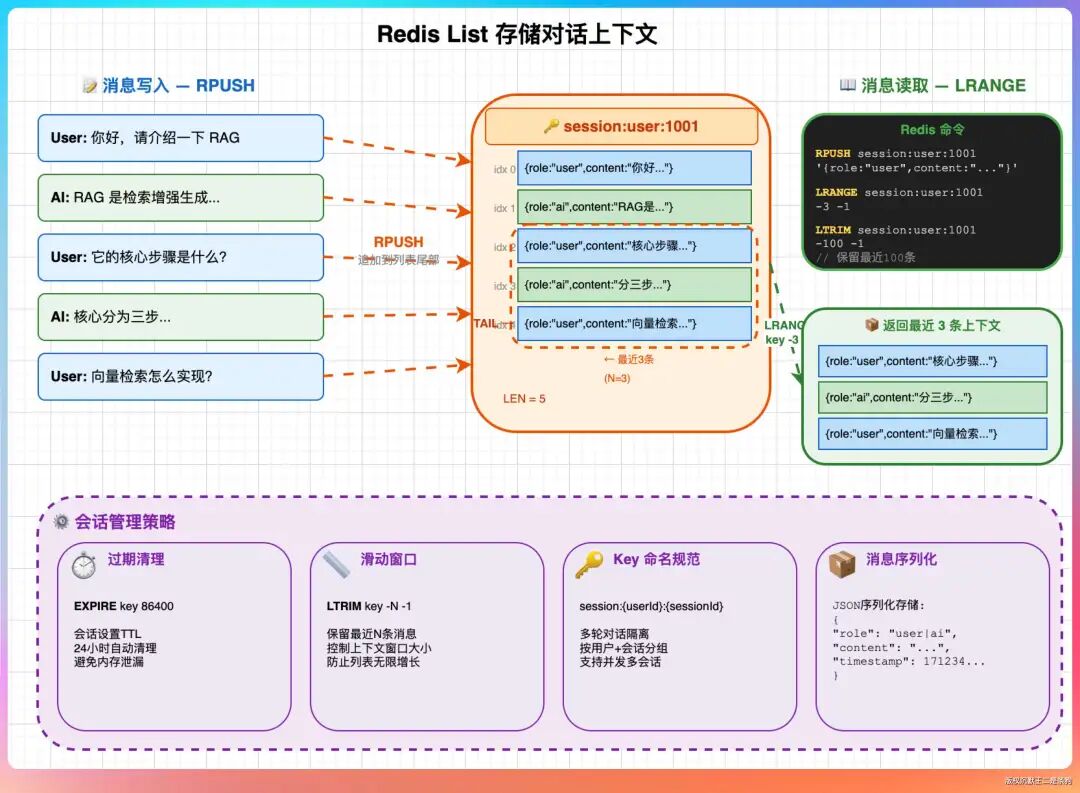
08、用Redis存储对话上下文,具体用的哪种类型?
对于对话上下文这种有序的消息列表,最自然和合适的选择是 Redis 的 List 类型。
每条消息通常包含role(user/assistant)和content两个字段。具体实现方式如下:
- 写入:以
session:{userId}:{sessionId}格式作为Key,将每条序列化为JSON字符串的消息,使用RPUSH命令追加到List的尾部。
- 读取:使用
LRANGE key 0 -1可以获取该会话的所有历史消息。更常见的做法是使用LRANGE key -N -1来获取最近的N条消息(例如,LRANGE key -20 -1获取最近10轮对话,假设每轮包含一问一答)。
为什么是List,而不是其他类型?
- String:每次读写都需要对整个上下文字符串进行序列化/反序列化,修改麻烦且有并发写入冲突的风险。
- Hash:适合存储结构化的键值对,但无法保证消息的先后顺序。
- ZSet(有序集合):虽然可以通过时间戳作为score来保证顺序,功能上可以实现,但对于简单的消息列表场景显得过于复杂,性能开销也相对更大。
因此,List因其天然的有序性、支持两端操作(可用LTRIM来截断老旧消息以控制长度)以及操作简单高效的特点,成为存储对话上下文的首选。
09、对话上下文过长怎么办?除了取最近N轮,还有别的方法吗?
简单的“滑动窗口”方案(只保留最近N轮对话)实现成本最低,但缺点明显:它会无条件地丢弃超出窗口的早期信息。如果用户在对话开始时定义了某个关键概念或提出了核心需求,在后续的长对话中再次涉及相关内容时,模型将因为“失忆”而无法连贯回应。
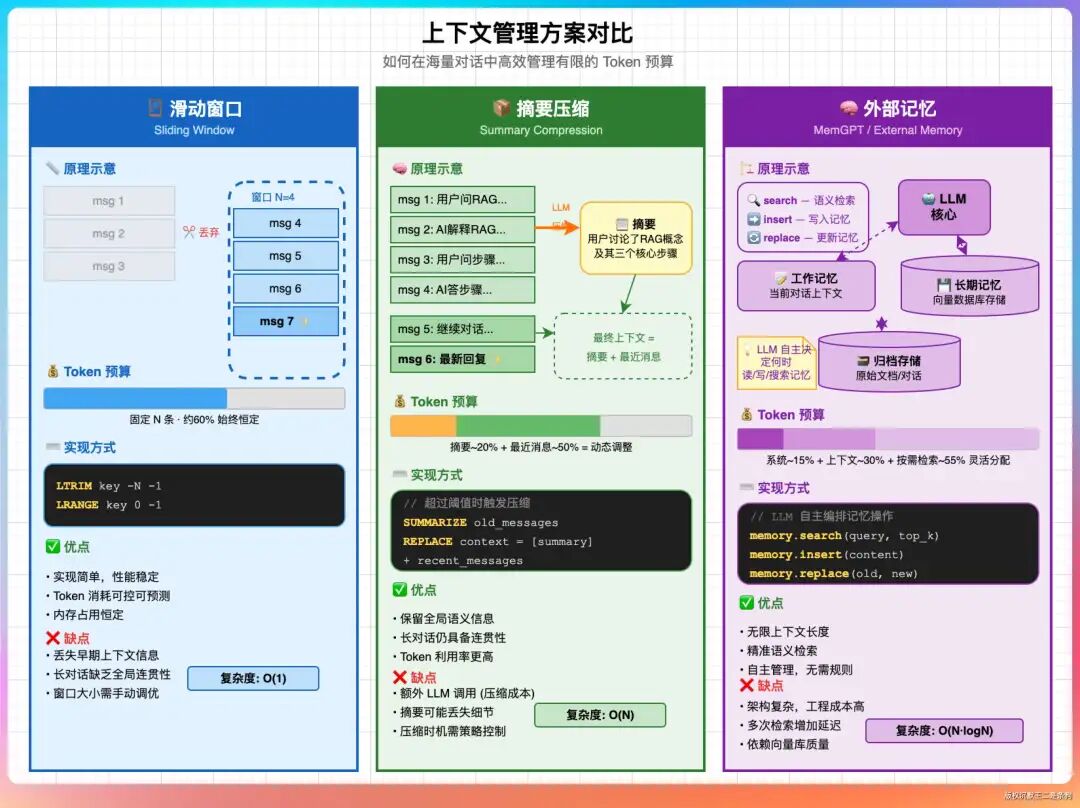
更高级的上下文管理方案包括:
- 摘要压缩(Summarization):当上下文长度超过阈值时,不是直接丢弃旧消息,而是调用一次LLM,将早期的对话内容总结成一段简短的摘要。然后将“摘要 + 最近的完整对话”作为新的上下文。这样做既保留了历史信息的精华,又有效控制了Token数量,代价是增加了额外的LLM调用成本和轻微延迟。
- 重要性打分与筛选(Importance Scoring):为历史消息中的每一条(或每一段)计算一个重要性分数。当需要裁剪上下文时,优先保留高分消息,而不是简单地按时间顺序截断。例如,用户说“请记住我的需求是A”这样的话,重要性分数应该远高于一句普通的问候。
- 外部记忆(External Memory):参考MemGPT等架构的思想,将对话中提炼出的关键事实、用户偏好等“长期记忆”存储到一个独立的向量数据库或知识库中。每次对话时,先根据当前问题从这个外部记忆中检索相关信息,再拼接到上下文中。这相当于为对话系统增加了一个可动态查询的“备忘录”。
- 动态Token预算(Dynamic Token Budget):系统根据当前问题的复杂度和类型,动态决定分配给上下文的Token数量。简单查询给予较小的上下文窗口以快速响应;复杂、需要多步推理的问题则分配更大的上下文窗口,允许带入更长的历史信息链。
Ending
我一直认为,简历上的项目,必须“经得起拷打”。这并不意味着你需要对每一个技术细节都了如指掌、回答得滴水不漏,而是要能够清晰地展示你的技术思考路径——你为什么选择这个方案?是否考虑过其他替代方案?遇到线上问题时,你的排查思路是怎样的?
项目背后是思路,思路背后是积累。 这也正是我建议大家在实践RAG这类项目时,不要仅仅满足于跑通Demo,而是要深入每一个环节,思考其背后的权衡与设计哲学的原因。
最后,无论面试结果如何,都值得花时间将面试中被问到的问题认真复盘一遍。面试本身就是一次高效的技术梳理和查漏补缺,它能逼迫你从一个更高的视角去审视自己的知识体系,这种收获往往比埋头看书更直接、更深刻。
加油,共勉。
 发表于 2026-4-10 04:08:02
|
查看: 137|
回复: 0
发表于 2026-4-10 04:08:02
|
查看: 137|
回复: 0
