凌晨三点,监控大屏上的 Redis 内存使用率突然飙升到 95%,紧接着淘汰速率暴增,接口 P99 延迟从 5ms 跳到 200ms。这是许多后端工程师都可能遇到的深夜惊魂。排查下来,问题根源往往在于那个看似简单、却在高并发下暗藏杀机的缓存淘汰策略。
系统当时使用的是最经典的 LRU (Least Recently Used) 策略。理论上,LRU 应该淘汰最久未使用的数据。但实际情况是,一批定时任务进行了全量数据扫描,数百万条冷数据被瞬间读入,挤占了缓存空间,导致真正的热数据被驱逐。早高峰流量袭来时,缓存命中率从 97% 暴跌至 40%。
这便是 LRU 典型的 “缓存污染” (Cache Pollution) 问题。在十万 QPS 的系统里,这可能只是让响应慢几秒;但在千万 QPS 的 高并发 系统中,缓存命中率每下降 1%,就意味着数据库每秒要多承受十万次查询,这直接关系到系统的生死存亡。在云栈社区的技术讨论中,这类由基础策略引发的线上故障屡见不鲜。
LRU:直观逻辑背后的代价
LRU 的假设很直观:最近被访问过的数据,未来被访问的概率更高。因此,它维护一个访问时间序列,淘汰最久未被访问的数据。这也是为什么从 Linux 内核页面置换到早期 Memcached,都能看到 LRU 的身影。

然而,在高 QPS 场景下,LRU 的弱点会被无限放大:
- 缓存污染:如前所述,一次批量扫描就能让大量低频冷数据“污染”缓存,驱逐高频热数据。LRU 只关心“最近是否访问”,不关心“访问了多少次”,无法区分一次性冷数据和持续热数据。
- 淘汰精度不足:一个刚被偶然访问一次的低频 key,在 LRU 队列中的位置可能与每秒被访问上万次的热 key 一样靠前,仅因为它的访问时间更“新”。
- 实现开销大:严格 LRU 需要维护双向链表和哈希表,每次访问都涉及链表节点移动。在千万 QPS 下,这带来巨大的锁竞争和内存操作开销。这也是工程实践中广泛采用近似 LRU 的根本原因。

LFU:用频率对抗污染
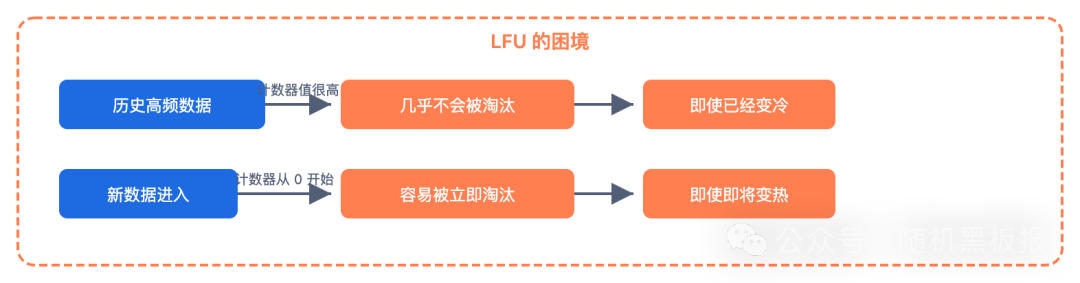
既然 LRU 的问题在于忽略频率,很自然就想到 LFU (Least Frequently Used):淘汰访问次数最少的数据。LFU 能有效抵御缓存污染,在全量扫描场景下,仅访问1次的冷数据会被优先淘汰,而访问数成千上万的热数据则安然无恙。
但 LFU 引入了新的问题:
- 频率衰减迟钝:历史上访问十万次、但近期不再访问的数据,其高计数会使其长期滞留,无法及时淘汰。
- 新数据冷启动:新加入缓存的数据计数为0,极易被淘汰,即使它可能是即将爆发的热点。
- 计数器开销:为每个 key 维护精确计数器(如64位整数)内存消耗巨大,且实现频率衰减需要遍历所有 key,成本高昂。
LRU 和 LFU 仿佛一对冤家,各自解决了对方的问题,又各自制造了新的麻烦。 真正的挑战在于如何取二者之长。
Redis 的工程智慧:近似 LRU 与 LFU
在实际架构中,Redis 几乎是分布式缓存的标配,它的实现提供了极佳的工程化视角。
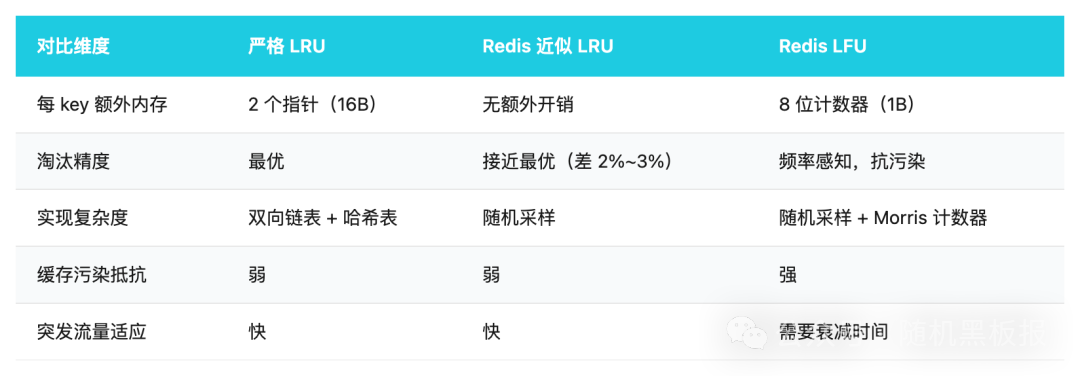
Redis 从未实现严格 LRU,而是采用 近似 LRU:淘汰时,随机采样若干 key(默认5个),淘汰其中最久未访问的。测试表明,采样数达到10时,其效果已非常接近理论最优 LRU。这是一次经典的权衡:用约2%的精度损失,换取了极低的实现复杂度和几乎为零的额外内存开销。
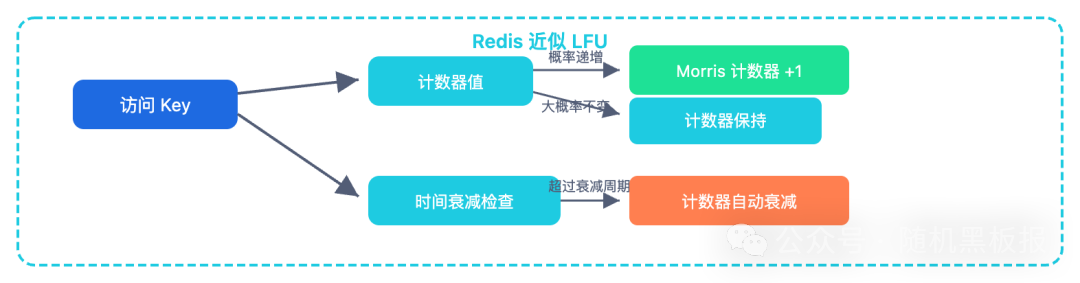
Redis 4.0 引入的 LFU 策略同样是近似实现,包含两个精巧设计:
- Morris 计数器:使用8位对数计数器,通过概率递增(计数器值越大,递增概率越低),用1字节就能近似表达百万级的访问频率。
- 时间衰减:计数器值会随时间自动衰减,解决“历史热、当前冷”的数据占坑问题。
W-TinyLFU:工业级的极致追求
如果说 Redis 是“够用就好”,那么 W-TinyLFU(Java 流行缓存库 Caffeine 的核心算法)则代表了追求极致命中率的系统化方案。
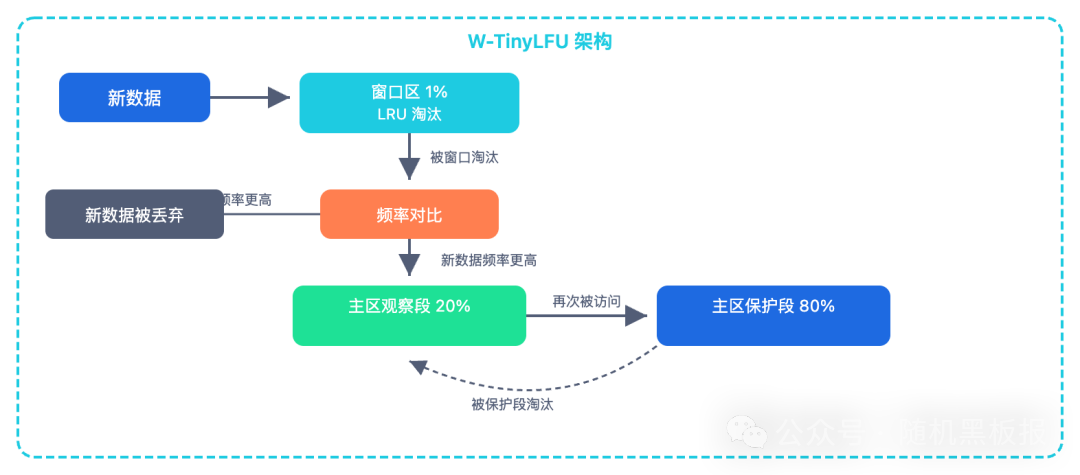
它将缓存空间划分为:
- 窗口区 (Window Cache,占约1%):新数据入口,内部使用 LRU 淘汰,给予新数据“观察期”。
- 主区 (Main Cache,占99%):又分为 保护段 (Protected, 80%) 和 观察段 (Probation, 20%)。
其核心操作在于 准入过滤器:当窗口区的数据被淘汰时,需与主区观察段的数据进行频率 PK,胜者留下,败者出局。
频率统计采用 Count-Min Sketch 概率数据结构。其精妙之处在于,仅用每个 key 约 4 位的空间,就能进行足够准确的频率估计,并且通过定期将所有计数器右移一位(除以2)即可实现全局衰减,无需遍历 key。

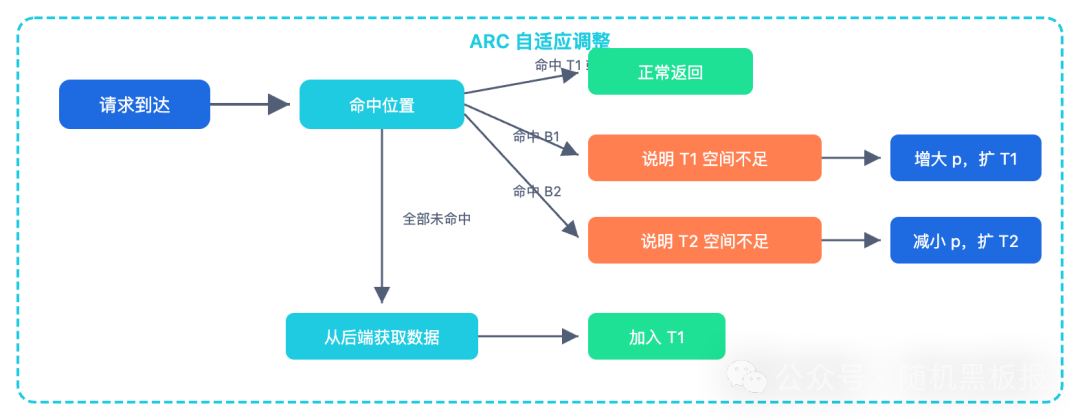
ARC:自适应的动态平衡术
ARC (Adaptive Replacement Cache) 走了另一条路:它不预设 LRU/LFU 的固定比例,而是动态调整。
ARC 维护四个列表:
- T1:最近只被访问一次的数据(LRU 思想)。
- T2:最近被访问两次及以上的数据(LFU 思想)。
- B1、B2:分别记录从 T1、T2 淘汰的 key 的历史(只存元数据)。
T1 和 T2 共享缓存空间,其大小比例由一个参数 p 控制。ARC 的智能体现在 p 的动态调整上:
- 若访问命中了 B1(从 T1 淘汰的历史 key),说明 T1 空间不足,应增加
p,扩大 T1。
- 若访问命中了 B2(从 T2 淘汰的历史 key),说明 T2 空间不足,应减小
p,扩大 T2。
ARC 的核心洞察是:最优的 LRU/LFU 混合比例并非固定,而是随访问模式动态变化的。 尽管其专利已过期,但较高的实现复杂度和内存开销(需维护淘汰历史)限制了其在分布式缓存中的广泛应用。
不同系统规模的策略选型指南
选择淘汰策略需结合系统规模与业务特点,它不只是一个技术配置项。
- 十万 QPS 级别:LRU 通常足够。此时缓存命中率的小幅波动,数据库层一般能够承受。实现简单、理解成本低是其主要优势。
- 百万 QPS 级别:需要开始严肃对待缓存污染。应考虑启用 Redis 的 LFU 策略,或在本地缓存层引入 Caffeine (W-TinyLFU)。目标是提升命中率稳定性。
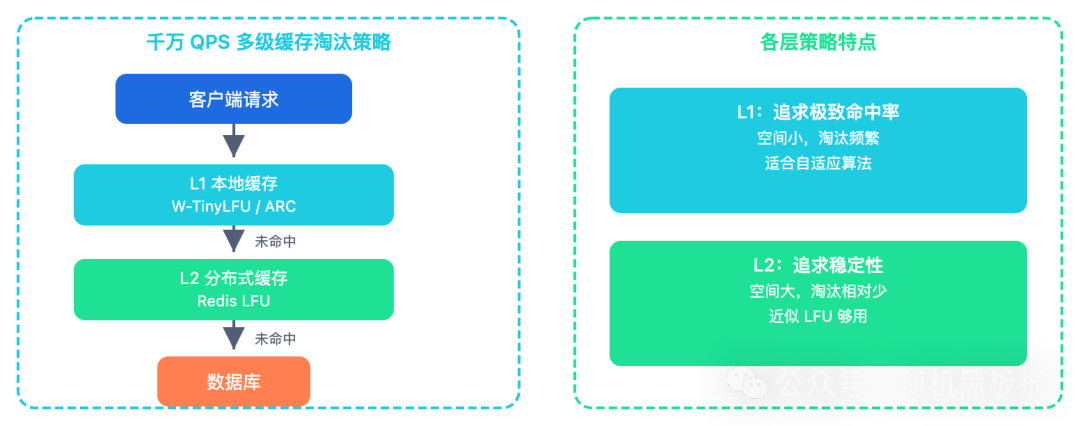
- 千万 QPS 级别:采用多级缓存,分层施策。常见的架构是 L1 本地缓存 + L2 分布式缓存(如 Redis)。
- L1 本地缓存:空间有限,淘汰频繁,对算法精度敏感,适合使用 W-TinyLFU 或 ARC 等 算法。
- L2 分布式缓存 (Redis):空间相对充裕,直接使用其内置的、经过充分优化的近似 LFU 策略即可,无需在客户端重复造轮子。

不容忽视的隐藏成本与监控
除了算法本身的命中率,还需关注以下隐藏成本和可观测性:
- 淘汰风暴:当缓存满时,集中淘汰大量 key 会阻塞服务(如 Redis 主线程)。应对策略:设置内存使用阈值(如85%),提前开始渐进式淘汰;利用 Redis 6.0+ 的异步淘汰 (
lazyfree-lazy-eviction) 特性。
- 与 TTL 的交互:一个低频但 TTL 很长的 key,可能比一个高频但 TTL 将到的 key 更晚被 LRU 淘汰。需要将淘汰策略与过期策略统一设计。
- 精细化监控:仅有整体命中率是远远不够的,你需要:
- 分业务、分 key 模式的命中率统计。
- 淘汰速率与淘汰操作延迟。
- 被淘汰 key 的“年龄”(距上次访问时间)分布。
- 没有细粒度监控,你对缓存效率的评估就如同盲人摸象。
结语:从选择算法到设计系统
缓存淘汰策略的演进,是从单一维度(时间)到多维度(频率、适应性)的探索过程。但在真实的系统设计中,比选择算法更重要的,是对业务数据访问模式的深刻理解。你知道有定时全量扫描,就该选择抗污染的 LFU 变种;你知道热点切换极快(如秒杀),就要警惕那些对历史频率依赖过重的策略。
在千万 QPS 的体系里,缓存淘汰必须与分层架构、容量规划、监控告警深度融合,形成一套完整的缓存治理方案。最后留一个开放思考:当缓存中同时存在“高频小对象”和“低频大对象”时,如何将对象大小纳入淘汰决策,实现缓存空间的价值最大化?这指向了学术界称为“Size-Aware Eviction”的方向,也是工业界未来值得探索的课题。
 发表于 2026-4-10 04:23:13
|
查看: 169|
回复: 0
发表于 2026-4-10 04:23:13
|
查看: 169|
回复: 0
