
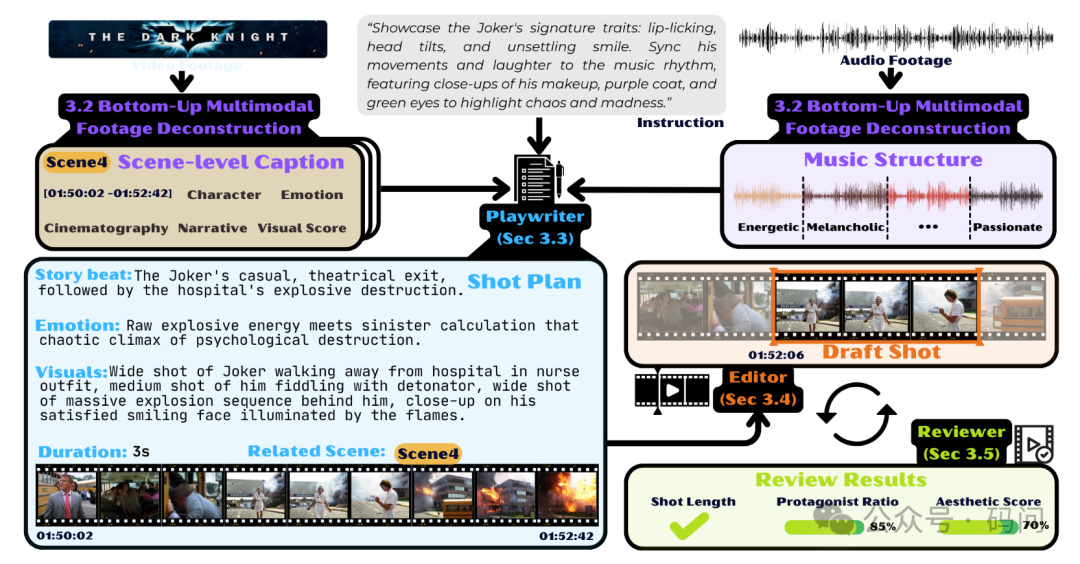
CutClaw 是一个面向长视频素材与音乐的端到端自动剪辑系统。
它首先将原始视频和音频解析为结构化描述,再通过多智能体流水线完成镜头规划(shot_plan)、片段时间戳选取(shot_point)及质量验证,最终渲染输出成片。
传统的视频剪辑要么是自己手动在时间轴上一点点调整节奏,要么是使用预设的模板工具。但模板往往不够灵活,很难实现真正的音画合一。很多现有的AI剪辑工具,通常是先剪好视频,再尝试配上背景音乐,本质上并非由音乐驱动剪辑决策,最终的节奏感总会差那么点意思。
近期,大湾区大学GVC实验室与北京交通大学团队联合开源了CutClaw,从设计上就致力于解决这个痛点。作为一个开源项目,它通过一套精心设计的智能体协作流程,实现了音乐感知的视频剪辑。项目地址如下:
https://github.com/GVCLab/CutClaw
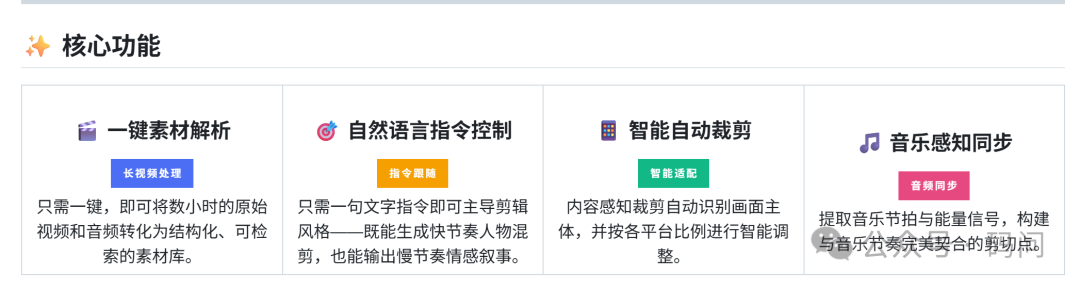
模型选择建议
为了获得最佳效果,项目对不同环节的模型选择给出了建议:
-
视频模型
- 用途:镜头/场景理解与视觉描述生成。
- 推荐:Gemini-3、Qwen3.5、GPT-5.3
-
音频模型
- 用途:语音识别(ASR)及音乐结构分析(节拍/强拍、音高、能量),用于节拍感知分割。
- 推荐:Gemini-3
-
智能体模型
- 用途:驱动编剧 + 剪辑 + 审阅智能体循环,生成
shot_plan 和 shot_point。
- 推荐:MiniMax-2.7、Kimi-2.5、Claude-4.5
相关阅读
若你对人工智能驱动的创意工具或开源实战感兴趣,可以在云栈社区找到更多相关的技术讨论与项目分享。 |  发表于 2026-4-10 04:20:39
|
查看: 194|
回复: 0
发表于 2026-4-10 04:20:39
|
查看: 194|
回复: 0
