多智能体工作流最怕什么?改上游一句提示词,下游全乱。在搭建复杂的 LLM Agent 链路时,Prompt 工程师经常陷入这种“局部达标、全局崩坏”的死循环。上游 Agent 的指令明明很完美,输出一到中间节点,下游直接跑偏;中间步骤又缺乏标准答案,传统自动化优化方法根本没法公平分摊功劳或过错。
这就引出了 ICML 2026 收录的 MASPO 框架。它把多智能体协同调参从“凭感觉试错”推向了系统级联合优化。在这篇论文中,作者提出了一套无监督的迭代框架,用“局部-前瞻-全局”联合评估和错位案例挖掘,试图破解信用分配与分布漂移的难题。论文表明该框架无需人工标注,但优化器和评估器的 LLM API 账单可不会自动清零。账还是要算的:这套方法真的能替代手工调参吗?背后的 API 算力开销和评估器偏好,会不会成为新的瓶颈?
论文:MASPO: Joint Prompt Optimization for LLM-based Multi-Agent Systems
发表:ICML 2026
论文:https://arxiv.org/pdf/2605.06623
代码:https://github.com/wangzx1219/MASPO
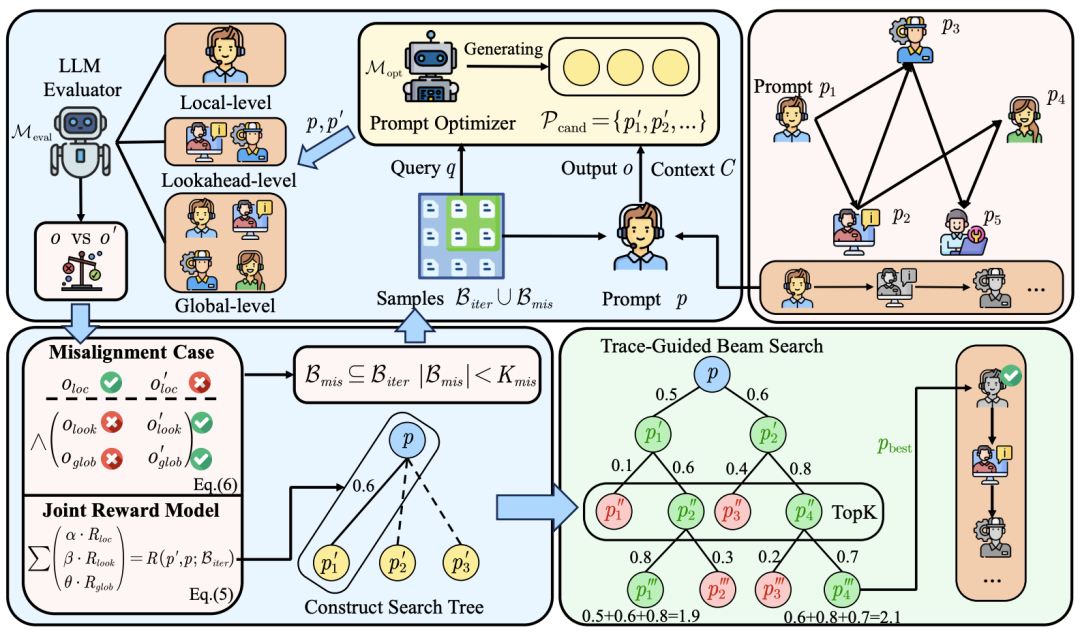
核心解法:用“联合评估”代替“单点打分”
单智能体优化看的是“答对没”,多智能体优化得看“配合得好不好”。MASPO 的核心直觉是:不能只盯着当前 Agent 自己的输出,还得看它给下游留下的“上下文”好不好用。
为此,作者设计了一个多粒度的联合奖励机制,把评估拆成了三个维度:
- 局部有效性:保证当前角色不跑题,完成自己的分内事。
- 前瞻潜力:量化当前 Prompt 的改动对直接下游 Agent 的“涟漪效应”。换句话说,上游说的话,下游能不能听懂并接着干?
- 全局一致性:兜底整个长链路最终有没有偏离目标。
在实际打分时,在该实验设定与任务平均下,这组经验权重 0.4:0.4:0.2 很有意思:过度追求局部正确或只看重最终结果都不行,重点得放在“承上启下”的前瞻潜力上。
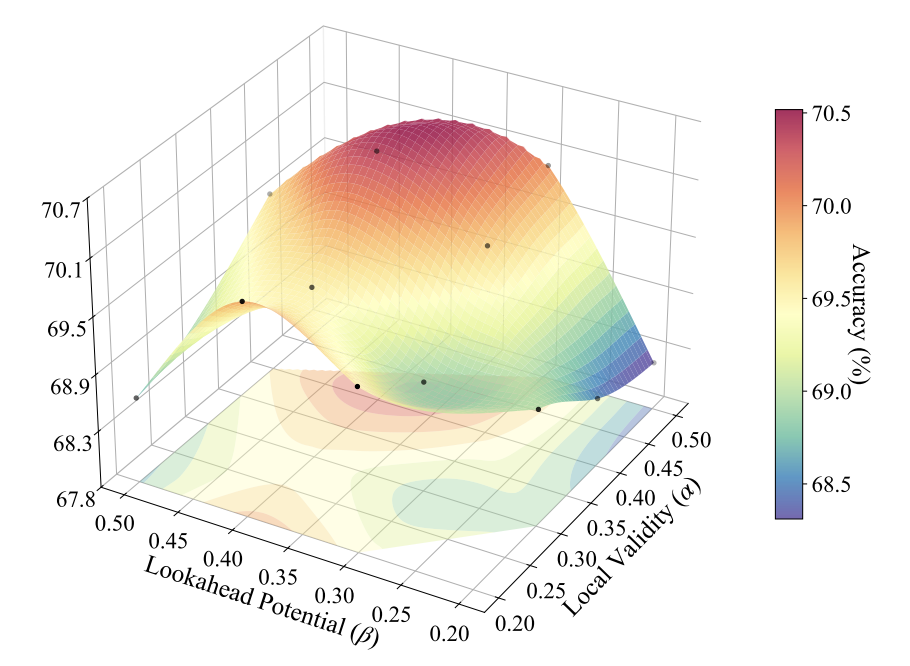
这张三维插值曲面图直观展示了权重分配对准确率的影响。可以看出,当局部有效性和前瞻潜力的权重较高(接近 0.4 和 0.4)时,性能达到峰值。这说明在长链条协同中,中间步骤的“可用度”比单纯的“自洽性”或“全局正确”更关键。不过,该结论是基于特定任务平均后的插值结果,且受限于论文设定的搜索步长,不代表所有业务拓扑的通用最优解。
动态搜索:如何专治“各扫门前雪”与“上下文漂移”?
解决了“怎么打分”的问题,搜索策略也得跟上。多智能体环境是非平稳的:上游 Prompt 一变,下游面对的输入分布就彻底变了。如果还用静态搜索,很快就会因为信息过期而失效。
MASPO 用了两招来应对:
- 错位感知采样:系统会主动从历史轨迹中挖掘“局部达标但全局失败”的困难负例。这就像流水线质检员专门挑“零件尺寸合格但装不上整机”的次品返工,强迫优化器定向修复协同断裂点。
- 坐标上升调度与束刷新:优化器按拓扑顺序轮流更新各角色的 Prompt。更关键的是,每当上游节点更新后,MASPO 会定期重置下游的历史候选分数。这相当于重新校准流水线节拍,防止按旧图纸打分导致误判。
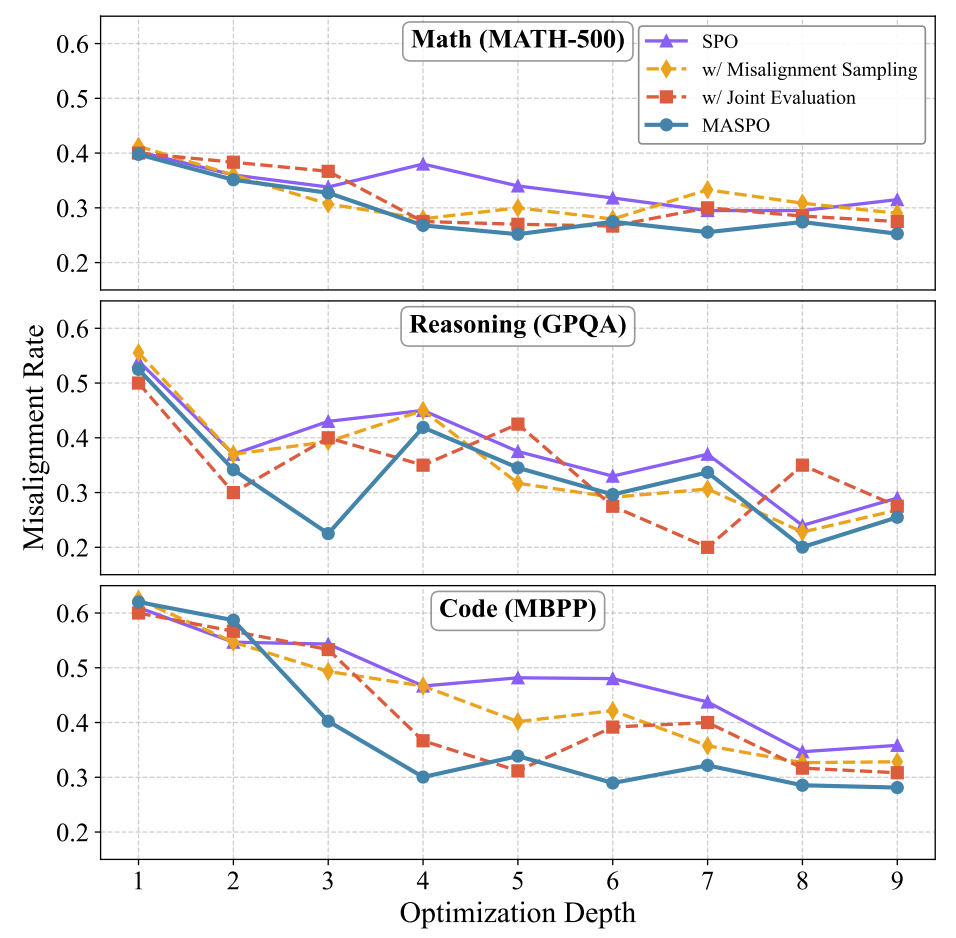
随着优化深入,错位率呈持续下降趋势,并在后期趋于平缓(约 0.2-0.25 区间)。这说明错位采样机制确实提供了有效的高价值负反馈,但算法仅能将分布漂移控制在可接受范围,能有效缓解而非彻底消除协同错位现象。
实验与算力账本:提升 2.9 个百分点背后,代价是什么?
优化器和评估器的账单不会自动清零,但账本必须算清。
在该实验设置下(使用 Qwen3-8B 作为骨干,Gemini-2.5-pro 作为优化/评估器),MASPO 在 6 个跨领域任务(数学、推理、代码生成)上的平均准确率,相比最强基线提升了约 2.9 个百分点(绝对提升)。作者声称,提升幅度在 Sequential 和 Hierarchical 拓扑下都保持稳定。
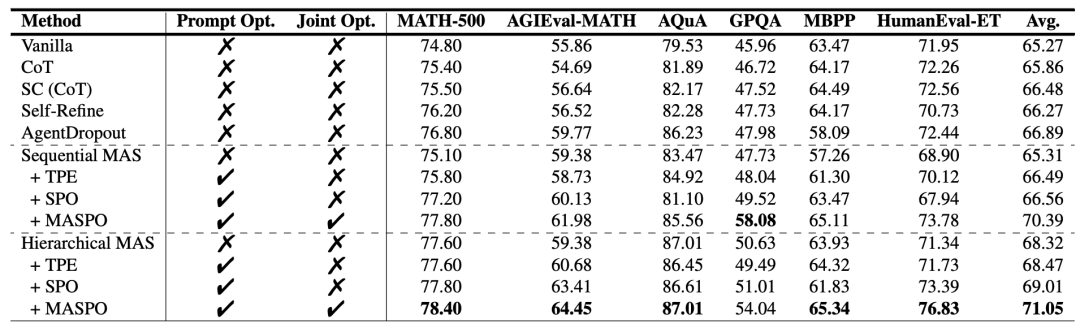
该表验证了在该实验设置下,联合调度策略确实带来了稳定增益。它证明了多粒度评估与错位挖掘的协同价值。但需要明确,这里的提升属于渐进式改进,且高度依赖 Gemini-2.5-pro 的评估偏好,不同模型规模或分布外任务中优势可能收窄,不宜直接外推为业务必然收益。
算力账本方面,论文在消融实验中控制了搜索步数和 Gemini API 调用总量。结果显示,即便给基线方法同等预算,MASPO 的机制优势依然存在。同时,即使用 8B 级别的小模型作为优化器,系统仍能跑通并获得正向收益,这为算力受限场景留出了妥协空间。不过,跨模型迁移时(如把优化后的 Prompt 直接给其他架构模型),提升幅度会因模型基线能力不同而产生波动。
落地启示:这把自动化尺子适合怎么用,又不适合怎么用?
MASPO 给 Agent 架构师提供了一条自动化路径,但工程落地不是拿着论文跑完 demo 就完事的。
- 适合谁用:如果你的 MAS 拓扑相对固定(如串行、层级),中间推理步骤缺乏标准答案,且人工反复修改 Prompt 已经陷入瓶颈,这套框架值得引入做离线调优。
- 什么时候慎用:对实时延迟极度敏感的业务,或者采用动态路由、全连接复杂拓扑的场景,MASPO 的多轮轨迹收集和束刷新会带来明显的计算延迟,目前尚未验证其在动态图结构中的有效性。
- 实操建议:可以先用强评估模型跑一轮离线优化,得到一套高质量的 Prompt 模板后,再蒸馏或冻结到轻量级推理模型中。此外,LLM 作为裁判(LLM-as-a-Judge)的主观偏好会直接引导优化方向,上线前务必严格监控评估器是否存在特定的评分漂移。
局部达标永远不等于全局最优。MASPO 的价值在于把多智能体协同的“玄学”拆解成了可计算的拓扑评估与动态搜索。它不是终点,而是 Agent 工程从手工作坊迈向系统化调优的一个可靠路标。
如果你也对这类前沿的框架调优与落地实践感兴趣,云栈社区 聚集了许多一线开发者在持续交流,欢迎来一起琢磨。
 发表于 2026-5-11 18:51:23
|
查看: 140|
回复: 0
发表于 2026-5-11 18:51:23
|
查看: 140|
回复: 0
