
当AI不仅能写代码,还能自己跑命令、连网络、调工具时,安全团队的血压大概和开发者的效率一起飙升了。
OpenAI最近分享了他们在内部“拴住”Codex的工程实践。不聊模型架构,也不谈Scaling Law,只谈一件很现实的事:怎么给具备自主执行能力的Agent上缰绳。
这篇博文的核心不是能力突破,而是一套企业级安全治理架构的披露。
说白了,它试图回答一个让所有引入Coding Agent的团队头疼的问题:放权怕出事,管死没效率,中间的平衡点到底怎么找?
当AI开始自己跑命令,安全团队的“缰绳”在哪?
Coding Agent正在从“补全建议”快速迈向“自主执行”。
它能直接操作仓库、运行Shell、调用外部API。问题来了:传统安全日志(及部分基础端点告警)主要记录“某个进程启动了”或“某个文件被改了”。
这就像看默片,只知道动作,看不懂意图。安全团队面对的是一个黑盒,开发者面对的是频繁的安全拦截。
企业落地卡在了合规与效率的夹缝里。OpenAI的这篇分享,正是把镜头从模型能力转向了控制面设计。
控制面设计:沙箱、审批与网络策略的联动逻辑
官方给出的方案并不玄幻,而是典型的系统工程思路:划边界、设关卡、管身份。
沙箱负责划定技术执行边界(能写哪、能不能联网),审批策略负责处理越界请求。
两者联动,相当于给Agent圈了一个“带电子围栏的测试场”,出圈必须打报告。
网络访问默认不开绿灯。通过代理策略做域名黑白名单,只放行预期目标。
凭证则强制托管进系统密钥环,并绑定企业工作区登录,确保所有操作都能追溯到具体身份。

这段配置展示了官方如何通过TOML文件将开发目录纳入沙箱白名单,并开启自动审查模式。
它说明控制策略已经高度配置化,但不能说明这套语法是否已随公开版CLI全量发布。目前更合理的理解是,它反映了OpenAI内部或企业版的基线实践。
网络策略的配置同样遵循“最小权限”原则。看这份名单时,注意缓存搜索限制与域名拦截的粒度:
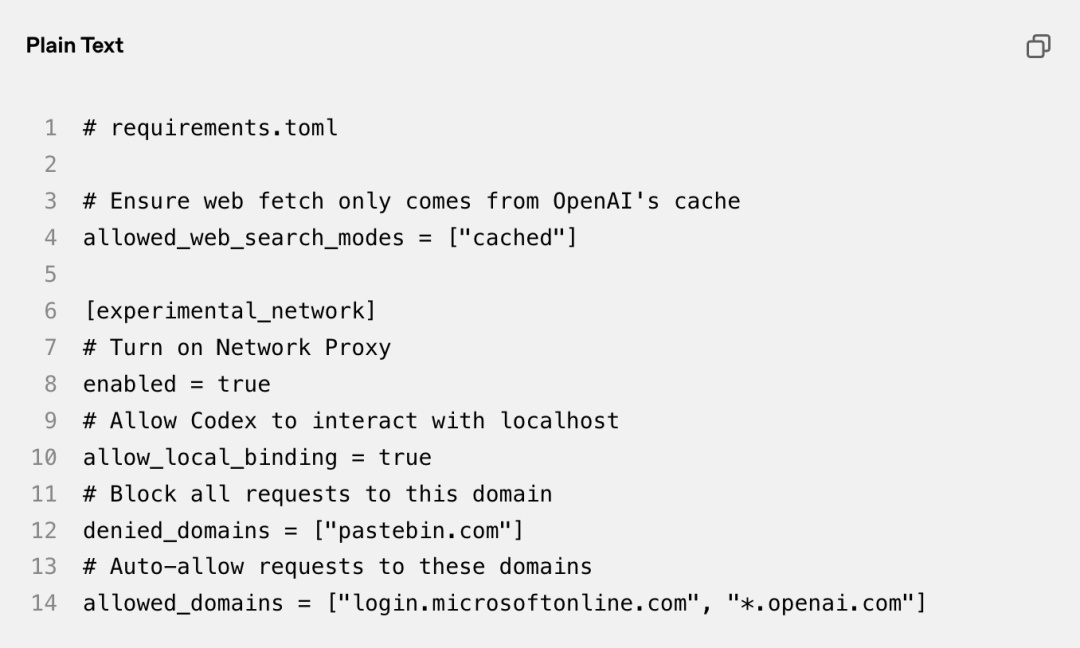
这里明确了搜索仅允许缓存模式、拦截特定域名、放行内部及认证域名。
它说明了网络边界可控,但不能说明维护这份名单的运维开销与误拦率。工程上最麻烦的地方往往不是写规则,而是动态更新。
规则过滤与自动审批:在“管死”和“放养”之间找平衡
如果每个命令都要人工点“允许”,开发者的心流大概会被切得稀碎。
OpenAI引入了两层机制来保效率:基于前缀的命令规则引擎,以及Auto-review子智能体。
规则引擎负责处理确定性高的日常操作。比如gh pr view或kubectl get,直接免审放行。
看这段规则时,重点看前缀匹配与参数组合的白名单逻辑:

这种基于前缀和参数组合的机制,在工程上非常直观。它说明了常见良性操作可以被快速放行。
但它不能说明面对复杂管道命令或动态生成脚本时的覆盖边界。静态规则本质上需要持续迭代。
更值得关注的是Auto-review子智能体。官方称,当遇到常规审批请求时,Codex会把计划和上下文发给这个子智能体,由它自动批准低风险操作。
这听起来很美好,但账还是要算的。子智能体本身也是LLM,“低风险”的定义权交回给模型,意味着审批链路引入了新的不确定性。
目前尚未确认该子智能体的误放行率、对抗鲁棒性(如提示注入诱导审批)以及具体的模型架构。在缺乏量化拦截数据的情况下,它更适合作为辅助减负工具,而非绝对的安全闸门,初期落地建议保留人工复核兜底机制。
可观测性升级:从“发生了什么”到“为什么发生”
控制只是前半段,出事之后怎么查才是安全团队的日常。
OpenAI明确提出“Agent原生遥测”的概念。说白了,就是给Agent装上行车记录仪和黑匣子,而不是只依赖路口监控。
传统日志记录进程和文件变动,Agent原生遥测则结构化导出用户提示、工具审批决策、执行结果、MCP调用和网络拦截事件。
看这段导出配置时,重点看日志捕获的字段范围与OTLP端点设置:
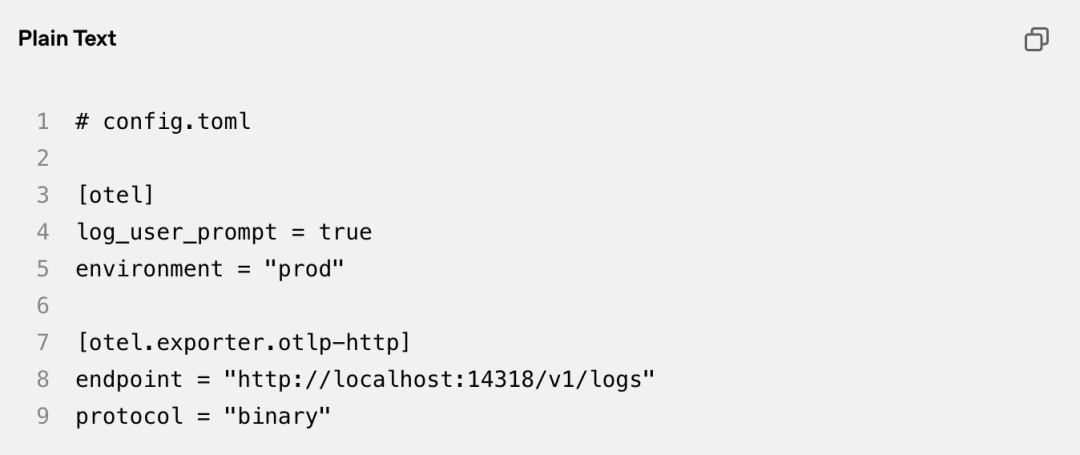
配合OpenTelemetry标准导出,这些日志可以直接接入企业SIEM。它说明了意图与决策链的可追溯性设计。
但它不能说明数据集中导出后的隐私脱敏策略是否符合GDPR或严格的企业合规要求。
官方在文中也直言了传统日志的局限:

这句话点出了Agent安全治理的核心痛点:意图可解释性。
OpenAI内部还接入了一个AI安全分诊智能体,用日志去反推用户意图和Agent决策链,做告警降噪。
这套“用AI管AI”的闭环在逻辑上是自洽的,但分诊智能体的降噪效果、误报/漏报率同样缺乏第三方验证。
官方声称 vs 工程现实:哪些能抄作业,哪些得自己趟?
读完全文,需要明确几个边界。
首先,这是一篇官方工程经验总结,而非经过同行评议的安全协议。
所有“确保安全采用”“自动放行低风险”的表述,均基于OpenAI内部技术栈(如macOS托管偏好、特定CLI版本)和单方声称。
对国内AI团队和Agent开发者的启发在于:Agent安全早已超出“模型对齐”的范畴,进入了系统工程深水区。
沙箱隔离、细粒度审批流、结构化意图日志,这三件套有望成为企业级Coding Agent的参考基线。
Auto-review和AI分诊展示了LLM实时风控的可行路径,但在对抗场景(恶意仓库诱导、越狱Prompt)下的防护边界,仍需各团队根据自身业务数据做红蓝对抗测试。
这套范式能抄的是架构思路和控制面设计逻辑;不能直接照搬的,是具体的配置依赖、未公开的模型阈值,以及缺少量化指标的安全承诺。
给Agent上缰绳,没有一劳永逸的开关,只有持续迭代的工程权衡。
参考:Running Codex safely at OpenAI
来源:OpenAI Blog
链接:https://openai.com/index/running-codex-safely
 发表于 2026-5-11 18:48:48
|
查看: 162|
回复: 0
发表于 2026-5-11 18:48:48
|
查看: 162|
回复: 0
