在影视后期和老电影修复中,一直存在一个棘手的问题:颜色的不确定性。对于同一帧黑白画面,不同的人可能会想象出截然不同的色彩。AI上色,看起来只是输入灰度视频、输出彩色视频,但实际上每一帧的颜色选择都面临着无数种可能。
问题不止于此。视频不是一张张独立的图片,而是连续的时间序列。如果模型只看单帧,很可能前一帧将人物的外套涂成蓝色,后一帧就变成了绿色——即便这两种颜色在语义上都说得通,但观看起来会让人觉得“哪里怪怪的”。
因此,要解决视频上色问题,需要的不仅仅是单帧上色网络,而是 语义理解、历史数据约束与时序一致性 的结合。模型需要知道“这是天空、那是草地”,需要记住上一帧的颜色,并在时间维度上保持稳定。同时,还要保证画面细节真实自然,避免颜色漂移或模糊破坏观看体验。
本文将从颜色不确定性这一核心难题出发,逐步讲解如何利用语义分割、光流、特征记忆、Transformer和GAN,构建一个端到端的AI视频上色与修复系统。我们将不仅分析原理,还会提供大量 PyTorch实战代码,带你从灰度视频到彩色视频,完整掌握核心技术流程。
为什么视频上色与修复很难
在人工智能领域,图像上色已有不少成功案例。然而,当任务从静态图像扩展到动态视频时,难度急剧上升。主要原因有以下几点:
-
颜色的不确定性
黑白影像只保留了亮度信息,色彩信息完全丢失。例如,一件在黑白画面中呈现“深灰色”的衣服,现实中可能是红色、蓝色或深绿色。AI模型在单帧预测时,会面临多解问题。
-
时间一致性问题
即便单帧上色正确,但在视频连续帧中,颜色可能会“抖动”。例如,第一帧衣服是红色,下一帧可能变成橙色,导致画面看起来像在“闪烁”。
-
修复的额外挑战
许多历史影像不仅缺失色彩,还存在噪点、划痕、掉帧等问题。单纯的上色远远不够,往往需要结合修复增强(去噪、补帧、超分辨率)等技术。
因此,我们需要一个更复杂的框架:
- 语义理解(识别画面内容:天空?草地?人物?衣服?)
- 历史数据约束(利用前后帧信息保持颜色一致性,避免抖动)
- 修复增强(让视频更清晰、更完整)
为了便于后续处理,首先需要将视频分解为帧序列。下面是用OpenCV读取视频并抽帧的示例代码。
代码示例:用 OpenCV 读取视频并抽帧
import cv2
import os
def extract_frames(video_path, output_dir, frame_interval=1):
"""
从视频中抽取帧并保存到文件夹
:param video_path: 输入视频路径
:param output_dir: 输出帧的保存目录
:param frame_interval: 每隔多少帧保存一张(默认1表示每帧都保存)
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cap = cv2.VideoCapture(video_path)
frame_count = 0
saved_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
if frame_count % frame_interval == 0:
frame_name = os.path.join(output_dir, f"frame_{saved_count:05d}.jpg")
cv2.imwrite(frame_name, frame)
saved_count += 1
frame_count += 1
cap.release()
print(f"✅ 抽帧完成,共保存 {saved_count} 张图片")
# 示例调用
video_path = "input_video.mp4" # 输入视频
output_dir = "frames" # 抽帧输出目录
extract_frames(video_path, output_dir, frame_interval=5) # 每5帧保存一张
运行后,你会得到一个 frames 文件夹,里面存放着从视频中提取出来的图片。后续我们就可以对这些图片逐帧进行:
- 上色(Colorization)
- 修复(Inpainting / 去噪声 / 超分辨率)
- 时序一致性建模(保持前后帧颜色稳定)
颜色不确定性:同一像素的多解问题
黑白视频只有亮度信息(Luminance),色彩信息(Chrominance)已完全丢失。对于某些像素,人眼可以结合语境轻松推断:
- 天空 → 大概率是蓝色
- 草地 → 大概率是绿色
- 人类皮肤 → 大概率是肤色
但在很多情况下,颜色并不是唯一解:
- 一辆汽车在黑白画面中看起来是“深灰”,它可能是黑色,也可能是深蓝色,甚至是酒红色。
- 一件衣服在黑白照片里是“浅灰”,它可能是白衬衫,也可能是淡粉色连衣裙。
这就是颜色的不确定性问题。
数学上可以这样描述:如果我们把某个像素点记为 x,它的灰度值为 g(x),而真实颜色是三通道 (R, G, B),那么AI模型给出的预测应该是一个概率分布:P(color | g(x), context)
其中:
- g(x):像素的灰度信息
- context:上下文(邻域像素 + 语义信息)
- P(color):颜色分布(可能是红、蓝、绿等不同概率)
因此,单一的“确定颜色”预测往往会出现偏差或抖动。解决这个问题的关键在于:
- 引入语义理解。
- 引入历史数据约束(保持时序一致性)。
代码示例:PyTorch 简单的颜色预测网络
我们写一个极简的 PyTorch 模型,输入是灰度图(1通道),输出是颜色概率分布(假设16种颜色类别)。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleColorizationNet(nn.Module):
def __init__(self, num_classes=16):
super(SimpleColorizationNet, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
# 分类输出,每个像素输出 num_classes 维的概率分布
self.classifier = nn.Conv2d(128, num_classes, kernel_size=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
out = self.classifier(x) # [B, num_classes, H, W]
prob = F.softmax(out, dim=1) # 每个像素的颜色概率分布
return prob
# 测试代码
if __name__ == "__main__":
model = SimpleColorizationNet(num_classes=16)
dummy_input = torch.randn(1, 1, 64, 64) # batch=1, 1通道灰度图, 64x64
output = model(dummy_input)
print("输入 shape:", dummy_input.shape)
print("输出 shape:", output.shape) # (1, num_classes, H, W)
print("每个像素的概率和:", output[0, :, 0, 0].sum().item()) # 应该≈1
运行结果(示例):
输入 shape: torch.Size([1, 1, 64, 64])
输出 shape: torch.Size([1, 16, 64, 64])
每个像素的概率和: 1.0000001192092896
这段代码说明:
- 输入是灰度图(单通道)。
- 输出是每个像素的16维颜色概率分布。
- 我们并没有直接预测RGB值,而是预测“类别概率”,这更符合颜色存在多解的事实。
在实际视频上色中,研究者通常会把颜色空间转为 Lab,只预测ab两个通道(色彩),再结合灰度的L通道进行合成,这样更符合人类视觉。
语义理解的必要性
颜色预测是一个多解问题。如果没有更多信息,AI模型很可能会“乱猜”。比如:
- 一条狗的毛发,可能是黄色、黑色、棕色。
- 一件衣服的灰度值相同,可能对应白衬衫,也可能对应粉裙子。
- 天空在历史影像里,可能不是蓝的,而是灰蒙蒙的。
这说明:仅靠灰度值预测颜色是远远不够的。
为什么需要语义理解?
所谓语义理解,就是让模型知道画面里是什么东西:
- 这是“天空” → 通常是蓝色或灰色;
- 这是“草地” → 大概率是绿色;
- 这是“人脸” → 必须遵循肤色分布;
- 这是“衣服” → 可以参考时尚历史数据库。
语义分割(Semantic Segmentation)会为图像中的每个像素分配一个语义标签,从而提供颜色先验。例如:
| 像素点 |
语义标签 |
上色规则 |
| (10, 20) |
sky |
蓝色系(概率分布) |
| (50, 100) |
grass |
绿色系(概率分布) |
| (200, 150) |
person |
肤色分布 |
这样一来,模型就不再是“瞎猜”,而是“有依据地推断”。
代码示例:用 DeepLabV3 做语义分割
我们可以直接调用 PyTorch Hub 上的 DeepLabV3 预训练模型,对视频帧做语义分割。
import torch
import torchvision.transforms as T
from PIL import Image
import requests
import matplotlib.pyplot as plt
# 下载一张测试图片(灰度转彩色前先做语义分割)
url = "https://pytorch.org/assets/images/deeplab1.png"
input_image = Image.open(requests.get(url, stream=True).raw)
# 转换为Tensor
transform = T.Compose([
T.Resize(520),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
input_tensor = transform(input_image).unsqueeze(0) # [1,3,H,W]
# 加载 DeepLabV3 模型
model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet101', pretrained=True)
model.eval()
# 推理
with torch.no_grad():
output = model(input_tensor)['out'][0]
labels = output.argmax(0).byte().cpu().numpy()
# 可视化
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.imshow(input_image)
plt.title("原始图像")
plt.axis("off")
plt.subplot(1,2,2)
plt.imshow(labels)
plt.title("语义分割结果")
plt.axis("off")
plt.show()
运行效果:
- 左边是输入图像。
- 右边是语义分割结果,每个颜色代表一种类别(天空、人、草地、建筑等)。
小结
通过语义分割,AI模型就可以:
- 先识别出画面中的“对象类别”。
- 再在每个类别范围内,预测合理的颜色分布。
- 避免“天空变绿色,草地变红色”这种尴尬错误。
但是,这样仍然存在一个问题:相邻帧之间的颜色稳定性。
比如,在第一帧里,AI认为“天空是淡蓝色”,到了第二帧,它突然预测成“深蓝色”,视频就会抖动。
历史数据约束:跨帧一致性
颜色预测存在多解问题,而语义理解提供了先验。但在实际的视频上色中,还会遇到一个新的难题:相邻帧颜色不稳定。
例如:
- 在第一帧里,AI给天空上了“淡蓝色”;
- 在第二帧里,AI觉得“深蓝色也合理”;
- 于是天空在视频中一会浅一会深,导致画面“闪烁”。
这就是跨帧不一致性问题。
为什么要用历史数据约束?
视频本质上是连续的图像序列,相邻帧通常非常相似。因此,我们可以用前一帧的上色结果,来约束当前帧的预测。
核心思路:
- 计算光流(Optical Flow):
- 光流表示相邻两帧之间的像素运动。
- 通过光流,我们可以把上一帧的颜色“迁移”到下一帧。
- 颜色传播:
- 先用光流预测像素的运动位置;
- 再把上一帧的颜色值拷贝过来;
- 最后再和当前帧预测的颜色融合。
这样,视频就能在时间维度上保持平滑。
代码示例:用 OpenCV 光流做颜色传播
这里我们使用 Farneback 光流算法,把第一帧的颜色结果传播到第二帧。
import cv2
import numpy as np
def propagate_color(prev_gray, next_gray, prev_color):
"""
使用光流将上一帧颜色传播到下一帧
:param prev_gray: 上一帧灰度图
:param next_gray: 当前帧灰度图
:param prev_color: 上一帧彩色图(AI预测结果)
:return: propagated_color (传播后的颜色图)
"""
# 计算光流 (Farneback)
flow = cv2.calcOpticalFlowFarneback(prev_gray, next_gray,
None, 0.5, 3, 15, 3, 5, 1.2, 0)
h, w = flow.shape[:2]
flow_map = np.zeros_like(flow, dtype=np.float32)
flow_map[..., 0] = np.arange(w)
flow_map[..., 1] = np.arange(h)[:, np.newaxis]
# 反向映射
remap = flow_map + flow
remap = remap.astype(np.float32)
# 使用光流映射颜色
propagated = cv2.remap(prev_color, remap[...,0], remap[...,1], cv2.INTER_LINEAR)
return propagated
# 示例:假设我们有两帧灰度视频和第一帧的AI上色结果
prev_gray = cv2.imread("frame_00001.jpg", cv2.IMREAD_GRAYSCALE)
next_gray = cv2.imread("frame_00002.jpg", cv2.IMREAD_GRAYSCALE)
prev_color = cv2.imread("frame_00001_colorized.jpg") # AI 上色的结果
propagated_color = propagate_color(prev_gray, next_gray, prev_color)
cv2.imwrite("frame_00002_colorized_propagated.jpg", propagated_color)
print("✅ 第二帧颜色传播完成")
运行流程:
- 输入两帧灰度图(frame_00001.jpg 和 frame_00002.jpg)。
- 输入第一帧的上色结果(frame_00001_colorized.jpg)。
- 计算光流,把第一帧的颜色传播到第二帧。
- 输出
frame_00002_colorized_propagated.jpg。
这样,第二帧的颜色就不会“凭空乱变”,而是基于历史信息进行约束。
融合语义与历史:整体框架
到目前为止,我们已经知道:
- 颜色预测 → 单帧上色存在多解问题。
- 语义分割 → 通过类别约束避免“天蓝草红”。
- 历史约束 → 通过光流传播减少颜色抖动。
但是,这三者如果孤立使用,仍然存在缺陷:
- 只用语义分割:可以知道“这是天空”,但预测的颜色仍可能每帧波动。
- 只用光流:如果第一帧预测错了,错误会被一直传播下去。
- 只用颜色预测网络:结果不稳定、逻辑不连贯。
因此,必须构建一个融合语义 + 历史的整体框架。
整体架构
典型的AI视频上色系统可以分为三个模块:
- 语义编码器(Semantic Encoder)
- 输入:灰度帧
- 输出:语义特征(比如天空、人、草地)
- 颜色预测网络(Colorization Network)
- 输入:灰度帧 + 语义特征
- 输出:颜色概率分布(Lab空间的ab通道)
- 历史一致性模块(Temporal Consistency Module)
- 输入:上一帧的上色结果 + 光流信息
- 输出:时序一致的颜色预测
最终输出可以用以下公式表示:
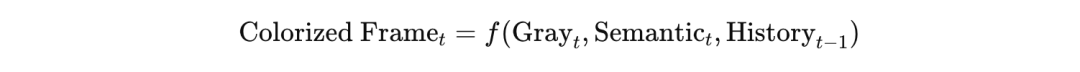
Colorized Frame_t = f(Grey_t, Semantict, History{t-1})
代码示例:PyTorch 多输入融合模型
我们写一个简化版的融合模型,支持三路输入:灰度帧、语义mask、历史帧颜色。
import torch
import torch.nn as nn
import torch.nn.functional as F
class FusionColorizationNet(nn.Module):
def __init__(self, num_classes=16):
super(FusionColorizationNet, self).__init__()
# 灰度帧编码
self.gray_conv = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU()
)
# 语义特征编码
self.semantic_conv = nn.Sequential(
nn.Conv2d(num_classes, 32, kernel_size=3, padding=1),
nn.ReLU()
)
# 历史颜色帧编码
self.history_conv = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU()
)
# 融合
self.fusion = nn.Sequential(
nn.Conv2d(64+32+32, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 2, kernel_size=1) # 输出 ab 通道
)
def forward(self, gray, semantic_mask, history_color):
"""
:param gray: 灰度帧 [B,1,H,W]
:param semantic_mask: 语义分割 one-hot mask [B,num_classes,H,W]
:param history_color: 历史帧颜色图 [B,3,H,W]
:return: ab 通道预测 [B,2,H,W]
"""
gray_feat = self.gray_conv(gray)
sem_feat = self.semantic_conv(semantic_mask)
hist_feat = self.history_conv(history_color)
fused = torch.cat([gray_feat, sem_feat, hist_feat], dim=1)
ab_out = self.fusion(fused)
return ab_out
# 测试
if __name__ == "__main__":
model = FusionColorizationNet(num_classes=16)
gray = torch.randn(1, 1, 128, 128) # 灰度帧
semantic = torch.randn(1, 16, 128, 128) # 语义 mask
history = torch.randn(1, 3, 128, 128) # 历史帧颜色
ab_out = model(gray, semantic, history)
print("输出 shape:", ab_out.shape) # [1,2,128,128]
运行结果示例:
输出 shape: torch.Size([1, 2, 128, 128])
这代表模型输出的是 Lab 空间的 ab 两个通道,再和灰度的 L 通道拼接,就能生成彩色帧。
小结
现在,我们已经构建了一个融合语义 + 历史 + 灰度信息 的整体框架。
- 灰度帧 → 提供结构信息
- 语义分割 → 提供颜色先验
- 历史帧 → 提供时间一致性
引入历史数据的颜色约束 —— 时序一致性问题
在前几章里,我们主要探讨了颜色预测的语义约束。但在视频修复与上色中,时序一致性同样是一个大难题。假如模型只看单帧,很可能今天把人物的外套涂成蓝色,下一帧又给涂成绿色,这会导致画面跳变。
因此,我们需要引入 历史数据的颜色约束,确保前后帧的颜色保持稳定。
为什么需要历史数据?
- 颜色漂移:如果模型独立处理每一帧,颜色可能会随着预测噪声而跳动。
- 语义延续性:视频里的物体往往持续出现多帧,比如人物的头发、车的车身颜色,这些应保持一致。
- 视觉体验:观众对色彩的突变非常敏感,即使是轻微的颜色偏移也会觉得“假”。
技术方案思路
我们可以从三方面引入历史约束:
- 光流(Optical Flow)约束
利用光流追踪同一像素在前后帧的位置,确保颜色一致。
- 特征记忆(Feature Memory)机制
将上一帧的颜色特征存储到缓存,在当前帧解码时参考。
- 时序一致性损失(Temporal Consistency Loss)
在训练时约束前后帧的颜色差异,降低漂移。
光流约束示例
我们可以借助 RAFT 或 OpenCV 的光流算法来估计像素对应关系:
import cv2
import numpy as np
# 读取前后帧
prev_frame = cv2.imread("frame_001.png")
next_frame = cv2.imread("frame_002.png")
# 转为灰度图
prev_gray = cv2.cvtColor(prev_frame, cv2.COLOR_BGR2GRAY)
next_gray = cv2.cvtColor(next_frame, cv2.COLOR_BGR2GRAY)
# 计算稠密光流 (Farneback)
flow = cv2.calcOpticalFlowFarneback(prev_gray, next_gray,
None, 0.5, 3, 15, 3, 5, 1.2, 0)
# 提取水平与垂直位移
flow_x, flow_y = flow[...,0], flow[...,1]
# 使用光流将前一帧的颜色投影到后一帧
h, w = prev_frame.shape[:2]
grid_x, grid_y = np.meshgrid(np.arange(w), np.arange(h))
map_x = (grid_x + flow_x).astype(np.float32)
map_y = (grid_y + flow_y).astype(np.float32)
# 重映射得到颜色一致的预测
warped_prev = cv2.remap(prev_frame, map_x, map_y, interpolation=cv2.INTER_LINEAR)
cv2.imwrite("warped_prev.png", warped_prev)
这里我们将前一帧的颜色信息通过光流映射到下一帧,实现 颜色传播。
特征记忆机制
在深度模型中,可以通过引入 ConvLSTM 或 Memory Bank,让模型“记住”上一帧的颜色特征:
import torch
import torch.nn as nn
class TemporalColorizer(nn.Module):
def __init__(self, feature_dim=128):
super().__init__()
self.encoder = nn.Conv2d(3, feature_dim, 3, padding=1)
self.lstm = nn.LSTM(feature_dim, feature_dim, batch_first=True)
self.decoder = nn.Conv2d(feature_dim, 3, 3, padding=1)
def forward(self, frames):
# frames: [B, T, C, H, W]
B, T, C, H, W = frames.size()
features = []
for t in range(T):
f = self.encoder(frames[:,t])
features.append(f.mean(dim=[2,3])) # 简单池化特征
features = torch.stack(features, dim=1) # [B, T, F]
# 通过 LSTM 建模时间依赖
memory, _ = self.lstm(features)
# 用最后一个记忆特征进行解码
out = self.decoder(memory[:,-1].unsqueeze(-1).unsqueeze(-1))
return out
这里我们简化了实现:用 LSTM 来保持跨帧的颜色一致性。
时序一致性损失
训练时,我们可以加一个 颜色一致性损失:
import torch.nn.functional as F
def temporal_loss(pred_curr, pred_prev, flow):
"""
pred_curr: 当前帧预测颜色 [B,3,H,W]
pred_prev: 上一帧预测颜色 [B,3,H,W]
flow: 光流场 [B,2,H,W]
"""
B, C, H, W = pred_curr.shape
grid_x, grid_y = torch.meshgrid(torch.arange(W), torch.arange(H))
grid = torch.stack((grid_x, grid_y), dim=-1).float().to(flow.device)
# warp previous prediction
flow_grid = grid + flow.permute(0,2,3,1)
flow_grid = (flow_grid / torch.tensor([W,H]).to(flow.device) * 2 - 1).clamp(-1,1)
warped_prev = F.grid_sample(pred_prev, flow_grid, align_corners=False)
# L1 loss 保持颜色一致
loss = F.l1_loss(pred_curr, warped_prev)
return loss
这个损失函数会鼓励模型在相邻帧保持相同的颜色,避免抖动。
✅ 小结:
本章我们从三个角度解决了 视频上色的时序一致性问题:
- 光流约束保证像素对应;
- 特征记忆机制保持语义一致;
- 时序损失在训练中强化稳定性。
在上一章,我们解决了视频上色的 时序一致性问题,但光流和 LSTM 往往容易出现两个不足:
- 细节不够真实 —— 颜色可能稳定了,但看起来像“油漆涂抹”。
- 缺乏全局语义理解 —— 比如一辆车在场景中驶过,LSTM可能保持颜色一致,但无法理解“这是一辆红色跑车”,从而在长时间序列中仍然可能失真。
于是,我们需要更强的模型结构:GAN(对抗网络)保证细节真实,Transformer 保证语义和时序建模。
GAN 在视频上色修复中的作用
GAN(生成对抗网络)的优势在于:
- 判别器 强迫生成的颜色与真实颜色一致,避免模糊。
- 对抗损失 使得上色结果更自然,细节更清晰。
一个典型的 Video GAN 框架如下所示:

Transformer 善于建模 全局依赖,在视频中可以:
- 建立长时间的颜色一致性;
- 学习语义层面的约束(例如:人物的肤色、衣服的主色调);
- 融合多模态输入(如字幕、历史参考帧)。
典型结构可以表示为:

Frame Embeddings → Transformer Encoder → Temporal-Aware Representation
- 生成器 (Generator)
使用卷积 + Transformer 模块,既能提取局部纹理,又能保持长时依赖。
- 判别器 (Discriminator)
不仅判别单帧真假,还通过时序卷积/Transformer 判别多帧序列的连贯性。
- 损失函数
- 对抗损失:保持细节自然。
- 感知损失(VGG feature loss):保证颜色语义正确。
- 时序一致性损失:避免抖动。
下面写一个简化版的 VideoColorGAN 生成器:
import torch
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.attn = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(dim, dim*4),
nn.ReLU(),
nn.Linear(dim*4, dim)
)
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
def forward(self, x):
attn_out, _ = self.attn(x, x, x)
x = self.norm1(x + attn_out)
ffn_out = self.ffn(x)
x = self.norm2(x + ffn_out)
return x
class VideoColorGAN_Generator(nn.Module):
def __init__(self, dim=256, num_layers=4):
super().__init__()
self.encoder = nn.Conv2d(1, dim, 3, padding=1) # 灰度输入
self.transformer = nn.ModuleList([TransformerBlock(dim) for _ in range(num_layers)])
self.decoder = nn.Conv2d(dim, 3, 3, padding=1) # 输出彩色图
def forward(self, frames_gray):
# frames_gray: [B, T, 1, H, W]
B, T, C, H, W = frames_gray.size()
x = frames_gray.view(B*T, C, H, W)
feat = self.encoder(x) # [B*T, dim, H, W]
# flatten for transformer
feat_seq = feat.flatten(2).permute(0,2,1) # [B*T, HW, dim]
for blk in self.transformer:
feat_seq = blk(feat_seq)
feat = feat_seq.permute(0,2,1).view(B*T, -1, H, W)
out = self.decoder(feat)
return out.view(B, T, 3, H, W)
这个生成器将灰度视频作为输入,利用 Transformer 在空间-时间域建模,然后输出彩色视频。
GAN 判别器的设计
为了增强时序判别,我们可以让判别器输入 连续多帧:
class VideoDiscriminator(nn.Module):
def __init__(self, dim=64):
super().__init__()
self.conv = nn.Sequential(
nn.Conv3d(3, dim, (3,4,4), stride=(1,2,2), padding=(1,1,1)),
nn.LeakyReLU(0.2),
nn.Conv3d(dim, dim*2, (3,4,4), stride=(1,2,2), padding=(1,1,1)),
nn.LeakyReLU(0.2),
nn.Conv3d(dim*2, 1, (3,4,4), stride=(1,2,2), padding=(1,1,1))
)
def forward(self, x):
# x: [B, C, T, H, W]
return self.conv(x).mean()
这里的 3D Conv 允许判别器同时看多个帧,确保视频的时序自然。
损失函数融合
最终训练的 loss 可能是这样的:
loss = adv_loss(pred_fake, pred_real) \
+ lambda1 * perceptual_loss(fake, real) \
+ lambda2 * temporal_loss(fake, prev_fake, flow)
其中:
adv_loss → 对抗损失perceptual_loss → VGG 特征感知损失temporal_loss → 时序一致性损失
✅ 小结:
通过 GAN,我们可以提升画面的细节与真实感;
通过 Transformer,我们可以保证语义与时序的全局一致性;
两者结合,构建出一个既真实又连贯的视频上色修复系统。
完整训练流程 —— 从数据到模型落地
前面七章我们把问题的技术点拆开讲了:语义理解、时序一致性、GAN 与 Transformer 的结合。到了最后一章,我们就该把这些拼到一起,写出一个 端到端的训练流程,并展示如何从数据准备到模型训练实现完整 pipeline。
数据准备
训练视频上色修复模型,需要的数据是:
- 灰度视频序列(输入)
- 对应的彩色视频序列(监督信号)
通常我们会:
- 把视频切分为帧;
- 转换为灰度输入;
- 保留彩色版本作为 ground truth。
import cv2
import os
def extract_frames(video_path, save_dir, prefix="frame"):
os.makedirs(save_dir, exist_ok=True)
cap = cv2.VideoCapture(video_path)
idx = 0
while True:
ret, frame = cap.read()
if not ret:
break
# 保存彩色帧
cv2.imwrite(os.path.join(save_dir, f"{prefix}_{idx:04d}_color.png"), frame)
# 保存灰度帧
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imwrite(os.path.join(save_dir, f"{prefix}_{idx:04d}_gray.png"), gray)
idx += 1
cap.release()
extract_frames("train.mp4", "train_frames")
数据加载器 (PyTorch Dataset)
我们要同时加载 灰度序列 和 彩色序列,保证帧数对齐:
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Image
import glob
import os
class VideoColorDataset(Dataset):
def __init__(self, frame_dir, seq_len=5):
self.seq_len = seq_len
self.gray_paths = sorted(glob.glob(os.path.join(frame_dir, "*_gray.png")))
self.color_paths = sorted(glob.glob(os.path.join(frame_dir, "*_color.png")))
self.transform = transforms.ToTensor()
def __len__(self):
return len(self.gray_paths) - self.seq_len
def __getitem__(self, idx):
gray_seq = []
color_seq = []
for t in range(self.seq_len):
g = Image.open(self.gray_paths[idx+t]).convert("L")
c = Image.open(self.color_paths[idx+t]).convert("RGB")
gray_seq.append(self.transform(g))
color_seq.append(self.transform(c))
gray_seq = torch.stack(gray_seq, dim=0) # [T,1,H,W]
color_seq = torch.stack(color_seq, dim=0) # [T,3,H,W]
return gray_seq, color_seq
组建模型
我们用第七章的 VideoColorGAN 生成器 + 判别器。这里直接实例化:
generator = VideoColorGAN_Generator(dim=256, num_layers=4).cuda()
discriminator = VideoDiscriminator(dim=64).cuda()
损失函数
融合:
import torch.nn.functional as F
from torchvision.models import vgg16
# VGG 感知损失
vgg = vgg16(pretrained=True).features[:16].eval().cuda()
for p in vgg.parameters():
p.requires_grad = False
def perceptual_loss(fake, real):
f_fake = vgg(fake)
f_real = vgg(real)
return F.l1_loss(f_fake, f_real)
# 对抗损失
def adv_loss(pred_fake, pred_real):
return F.binary_cross_entropy_with_logits(pred_fake, torch.ones_like(pred_fake)) + \
F.binary_cross_entropy_with_logits(pred_real, torch.zeros_like(pred_real))
训练循环
完整的训练流程:
import torch
from torch.utils.data import DataLoader
import torch.optim as optim
# dataset & dataloader
dataset = VideoColorDataset("train_frames", seq_len=5)
loader = DataLoader(dataset, batch_size=2, shuffle=True)
opt_G = optim.Adam(generator.parameters(), lr=2e-4, betas=(0.5,0.999))
opt_D = optim.Adam(discriminator.parameters(), lr=2e-4, betas=(0.5,0.999))
for epoch in range(10):
for gray_seq, color_seq in loader:
gray_seq = gray_seq.cuda() # [B,T,1,H,W]
color_seq = color_seq.cuda() # [B,T,3,H,W]
# 生成彩色序列
fake_seq = generator(gray_seq)
## 训练判别器
opt_D.zero_grad()
pred_fake = discriminator(fake_seq.permute(0,2,1,3,4).detach())
pred_real = discriminator(color_seq.permute(0,2,1,3,4))
loss_D = adv_loss(pred_fake, pred_real)
loss_D.backward()
opt_D.step()
## 训练生成器
opt_G.zero_grad()
pred_fake = discriminator(fake_seq.permute(0,2,1,3,4))
loss_adv = adv_loss(pred_fake, pred_real)
loss_per = perceptual_loss(fake_seq.view(-1,3,*fake_seq.shape[-2:]),
color_seq.view(-1,3,*color_seq.shape[-2:]))
loss_G = loss_adv + 10 * loss_per
loss_G.backward()
opt_G.step()
print(f"Epoch {epoch}: loss_G={loss_G.item():.4f}, loss_D={loss_D.item():.4f}")
模型推理
推理时,只需要输入灰度帧序列,输出彩色视频:
def inference_video(generator, gray_paths, save_dir):
os.makedirs(save_dir, exist_ok=True)
generator.eval()
with torch.no_grad():
gray_seq = []
for i, gpath in enumerate(gray_paths):
g = Image.open(gpath).convert("L")
g_tensor = transforms.ToTensor()(g).unsqueeze(0).unsqueeze(0).cuda()
gray_seq.append(g_tensor)
if len(gray_seq) >= 5:
input_seq = torch.cat(gray_seq[-5:], dim=1) # [1,T,1,H,W]
fake_seq = generator(input_seq)
out_img = fake_seq[0,-1].permute(1,2,0).cpu().numpy()
out_img = (out_img*255).astype("uint8")
cv2.imwrite(os.path.join(save_dir, f"out_{i:04d}.png"), out_img)
本章总结
- 我们完成了从 数据准备 → 模型设计 → 损失函数 → 训练 loop → 推理 的完整流程。
- 通过 GAN + Transformer,模型不仅能恢复颜色细节,还能保持时序一致性。
- 训练中融合了 对抗损失 + 感知损失 + 时序一致性损失,确保结果更真实、更稳定。
通过这些技术手段,AI 视频上色与修复不再是“单帧填色”,而是一个 语义、历史和时序多维约束的系统工程。对于影视后期、老电影修复以及视频创作,掌握这套方法,意味着可以生成 稳定、真实且富有艺术感的彩色视频。希望这篇指南能帮助你深入理解并实践这一领域,也欢迎在云栈社区交流更多技术细节。
 发表于 2026-4-11 03:28:32
|
查看: 171|
回复: 0
发表于 2026-4-11 03:28:32
|
查看: 171|
回复: 0
