上周,Cursor 发布了 Composer 2。这是他们专为智能体(Agentic)软件工程设计的前沿级 AI 模型。本文将根据其技术报告,深入浅出地解析核心要点:这些模型是如何训练的、强化学习(RL)框架是如何设计的,以及 “CursorBench” 基准测试到底在衡量什么。
注:Cursor 并未赞助此文,我只是喜欢研读新论文并记录所学。
Cursor(@cursor_ai) Composer 2 is now available in Cursor.
特别说明: 本文旨在提供教育性科普。我将严格专注于技术部分,拒绝废话,不带节奏,也不会提及发布周期间发生的任何争议。
以下是根据 Cursor 官方技术报告整理的 Composer 2 诞生过程。
两阶段训练流程
Composer 2 遵循一个两阶段训练流水线,旨在构建深厚的知识储备和执行能力:
- 持续预训练(Continued Pretraining, CPT): 此阶段侧重于增强模型的潜在编程能力和特定领域知识,确保模型对编程语言、模式和文档有“深度”理解。
- 大规模强化学习(Large-Scale RL): 这是“智能体化”的训练步骤。RL 用于提升模型的端到端表现。AI 在此学习如何推导问题、在终端执行命令,并在长任务中保持一致性。
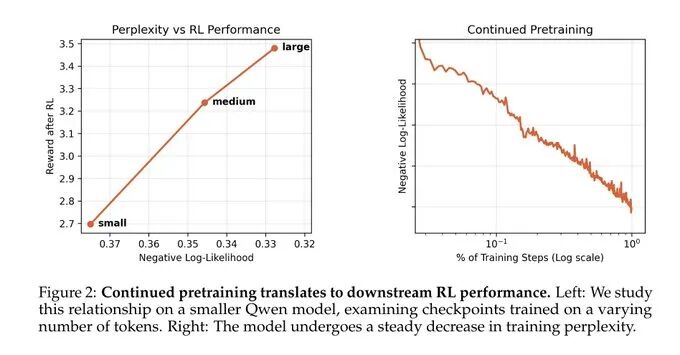
第一阶段:持续预训练(Continued Pretraining, CPT)
持续预训练是语言模型训练中常见的后期处理步骤。CPT 的目标是让基础语言模型成为特定领域的专家。
你向模型输入特定领域(例如“编程”)的大规模文本数据,并进行“下一个 Token 预测”训练。目标是增强模型在该领域的知识,即使这可能会以降低不相关领域(如“扑克牌”)的性能为代价。
Composer 2 的 CPT 阶段旨在将基础模型(Kimi K2.5)转化为“编程专家”,之后才会通过强化学习让它学习如何使用工具或与环境交互。
核心观点: CPT 并不是为了训练“能力”,更多是为了增加模型的“领域知识”。
1. 基础模型选择:Kimi K2.5
Cursor 团队选择 Kimi K2.5 作为 Composer 2 的底座。
- Kimi K2.5 是一个 混合专家模型(MoE)。
- 拥有 1.04 万亿参数,其中单次前向传播仅激活 320 亿参数。
- MoE 架构允许模型拥有海量知识库(数万亿参数的高容量),同时保持计算高效。
2. CPT 分三个特定阶段进行
预训练并非一�而就,而是采用循序渐进的方式,逐渐将重点转向更高质量、更复杂的数据:
- 阶段 1 - 批量训练(32k 序列长度): 模型首先在以代码为主的大规模混合数据上训练,以构建广泛的领域知识。
- 阶段 2 - 长上下文扩展(256k 序列长度): 为了处理现代代码库,序列长度从 32K 提升到 256K。这让模型能够同时“看到”并推导多个文件或超长文档。
- 阶段 3 - 有监督微调(SFT): 在进入 RL 阶段之前,进行最后简短的微调学习,使模型与特定的编程任务对齐,进一步精炼其知识。
技术报告中未提及具体的公开数据集。也没有提到他们是否在训练中使用了来自 Cursor 用户会话的实际数据。
3. 多 Token 预测(MTP)
多 Token 预测是一种训练和推理技术,使模型能同时预测未来多个 Token,而非仅预测下一个。 Cursor 在 CPT 阶段引入了 MTP:
- 自蒸馏: MTP 层通过自蒸馏从零训练。模型被教授去预测主语言模型头对未来 Token 的精确逻辑概率分布。
- 投机解码(Speculative Decoding): 这些层实现了更快的推理,允许模型在单次传递中”猜测”未来多个 Token,再由主模型验证。这通过”爆发式”生成短的可预测序列,极大提升了效率。
第二阶段:强化学习(RL)
如果说 CPT 构建了模型的“知识”,那么 RL 则全关于“能力”的训练——即执行任务。
以下是他们训练使用的一些任务示例:

他们在环境设计上透露的信息量令人惊讶,有很多内容可以拆解。
环境设计:Anyrun 与 Firecracker
环境不仅仅是一个沙箱,它使用了一个名为 Anyrun 的 Rust 平台,通过 Amazon EC2 和 AWS Firecracker 在云端安全、隔离地启动智能体。
- 隔离性: 每个智能体都在专用的 Firecracker VM(轻量化虚拟化技术)中运行。这允许模型安全地执行“不可信代码”,同时拥有完整的开发环境。
- 功能: 这些虚拟机支持完整的开发栈,包括用于“计算机使用”任务的浏览器和 GUI。
- 分叉与快照(Forking & Snapshotting): Anyrun 支持在文件系统和内存级别进行快照。这在 RL 中至关重要,因为它允许系统保存轨迹中间状态,稍后恢复进行验证或内省。这意味着如果智能体犯了错,可以重置轨迹并以更好的先验知识重试。
- 网络控制: 外部访问受 Anygress 管理,负责代理流量并强制执行策略(如删除敏感请求头),确保智能体不会产生非预期的外部影响。
奖励系统(Reward System)
Composer 2 的奖励机制混合了“功能正确性”和“行为塑造”:
- 最终奖励(Final Reward): 主要信号来自任务的整体成功,例如通过测试,或达到某个目标状态。这是经典的 RLVR(可验证奖励的强化学习) 理念,直接根据成功/失败信号进行端到端训练。
- 非线性长度惩罚: 一项平衡速度与深度的创新。惩罚遵循开口向下的曲线:在简单任务上,多出的 Token 会受到重罚;但在复杂任务上,模型被“允许”思考更久,而不会受到不成比例的惩罚。
- 辅助奖励: 包括代码风格(易读性)、沟通(鼓励清晰解释操作)以及工具惩罚(针对“坏习惯”的负奖励,如创建了 TODO 列表却从未完成)。
观测与观测空间
- 多模态输入: 模型接收代码、终端输出,甚至某些任务中的生产环境观测日志。
- 自我总结(Self-Summarization): 当任务超长超过上下文窗口时,模型会生成一份之前动作的总结。该总结成为下次观测的一部分,让模型在数百次工具调用中仍能“记住”已完成的工作。
Cursor 训练框架(Harness)
该框架旨在与 Cursor IDE 的实际环境完全匹配,确保 RL 训练出的模型在部署后表现一致。
- 每个环境启动时都会带上一套共享工具库,模型通过 RPC 方式调用这些工具。
- 某些依赖重资源或外部数据的工具,例如语义搜索,不放在 VM 内部执行,而是以接口形式从外部提供给模型使用。
- 支持“实时代码更新”,训练团队无需重启任务即可向 RL 环境部署新工具。
RL 算法细节
Composer 2 使用了 组相对策略优化(GRPO) 的变体:
- 单轮次制度(Single-Epoch Regime): 为了防止过拟合,模型从不在同一个 Prompt 上训练两次。
- 优势计算: 与标准 GRPO 不同,他们不按标准差对组优势进行归一化。他们发现,如果每个采样轨迹都同样正确,归一化会过度放大细微的行为差异。
- 移除长度标准化: 他们去掉了 GRPO 中的长度标准化项,以避免引入偏向更短(或更长)回复的偏差,转而依赖上述非线性长度惩罚来控制输出长度。
作者并未明确提及在 RL 阶段使用“带额外提示或 linter 错误重新生成轨迹”的正式策略蒸馏步骤。 在 RLRF(带丰富反馈的强化学习)环境中,策略蒸馏正变得非常流行(SDPO、ERL),因此我猜测 Cursor 可能很快也会将其纳入训练栈。
异步强化学习
整个系统被拆分为独立的服务:训练、环境、推理和评估。这种架构在当前的 RL 训练中越来越常见(Minimax 和智谱的 GLM-5 也采用了类似设计)。异步 RL 的目标是让所有组件互不等待,最大化吞吐量。
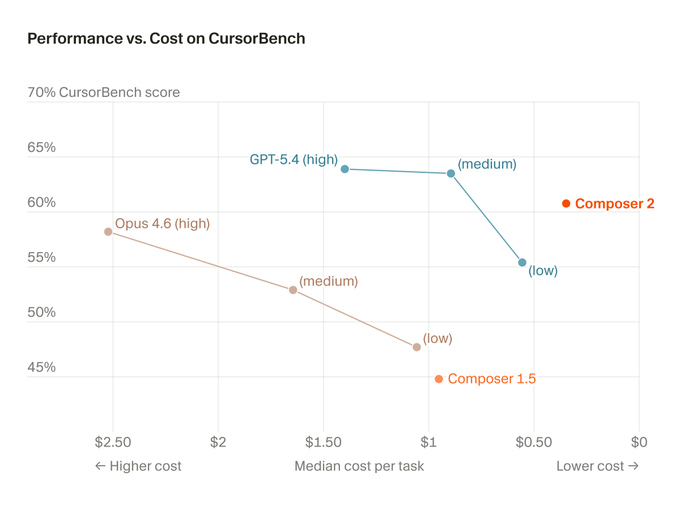
CursorBench
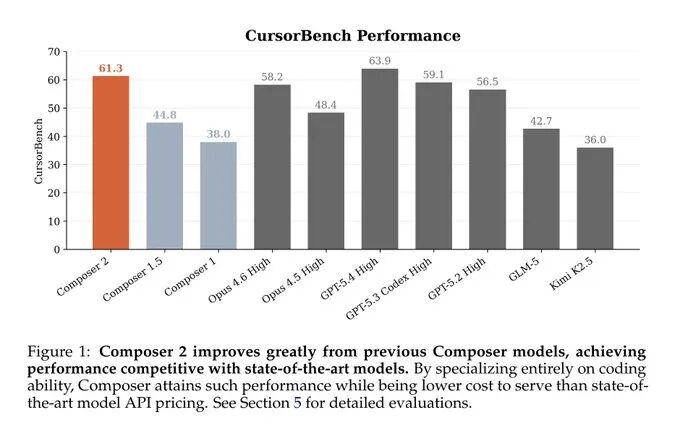
技术报告还深入探讨了 CursorBench。不同于依赖 GitHub Issue/PR 的公开基准测试,CursorBench 源自 Cursor 团队和用户遇到的真实软件工程问题。
它包含跨越数十个大型现实代码库(包括 Cursor 自己的代码库)的 1000 个任务。
- 任务不只是“实现 X”,通常包含模糊指令:例如“修复新功能中的 Bug”,但并没有明确定义什么是“新功能”。

示例任务之一,是通过交叉比对源码与生产日志,而不是只看堆栈追踪,来诊断一个构建工具 Bug。
另一个任务里,智能体需要分析 954 个 JSON 响应文件,找出一个很隐蔽的流式处理 Bug,还要为它写一个启发式检测器,并反复调参,避免过度计数。

CursorBench 是一套动态演进的基准测试,随着模型变聪明,会发布新的迭代版本(v0, v1, v2, v3),以走在公开榜单“饱和”之前。
原始报告中包含更多关于训练基础设施、任务示例、基准分数和对比的信息,建议查阅。
技术报告原文及相关链接:
我开发了 Paper Breakdown 来帮助自己理解这类技术论文。它支持 AI 辅助高亮标注,还能在多篇论文之间快速切换上下文。这个工具在内容写作中帮了我很大忙,包括撰写本文所需的研究工作。
你可以在电脑上免费用 AI 阅读这篇论文:http://paperbreakdown.com/abs/2603.24477
原文:https://x.com/neural_avb/status/2038624382214635574
作为专注于技术分享的云栈社区,我们持续关注AI编程与Agent领域的最新进展,Composer 2的训练框架,特别是其高度隔离和可快照的Anyrun环境,为如何在云端安全、高效地训练和执行复杂任务提供了极具参考价值的范本。
 发表于 2026-4-11 03:54:54
|
查看: 216|
回复: 0
发表于 2026-4-11 03:54:54
|
查看: 216|
回复: 0
