1 Flash Attention V2 的主要思路
关于 Flash Attention 的提出背景和主要作用,在本文中不再进行介绍,有兴趣的可以阅读笔者之前的文章【CUDA编程】Flash Attention CUDA 算子的实现思路。这里我们先对 Flash Attention V2 相比于 V1 的优化点进行介绍,主要有 3 个优化点。
- 省略 rescale 运算:在计算 时的在 K\V 序列维度上每轮由于更新 值进行的 rescale 运算被省略掉了,V1 版本会迭代地对前序值用 rescale 进行修正,但实际上只需要在最后一轮对输出进行统一修正即可,之前的轮次不需要除以 scale,这样可以减去迭代过程中每一轮的修正的除法操作(修正中乘法还是保留)。
- 增大并行尺度:在 V1 版本中每个 thread block 需要处理整个
[N, d] 矩阵,即仅在 batch 和 heads 两个维度上进行了并行化,总共需要 batch_size * num_head 个 block。Kernel 运行时一个 block 中的 warp 只会被调度到同一个 SM 上运行,当 block 数量很大时,这种调度方式是高效的,因为所有的 SM 资源都会被利用,但是在处理长序列输入时,由于内存限制,通常会减小 batch size 和 head 数量,使得 block 数量减少,从而导致有些 SM 资源会被闲置,进而降低了并行化程度。注意到在 Attention 计算过程中 Q 的序列维度上是完全没有数据依赖的,每一行都是独立地与 K\V 计算,所以 V2 版本在 Q 矩阵的 N 尺度上也进行并行化处理,多个 block 共同处理整个 [N, d] 矩阵。
- warp 级任务划分:在 V1 版本中,首先是在 K\V 维度上循环,存储临时变量
l 和 m,在内循环中频繁读写全局内存;而在 V2 版本中,先在 Q 维度上进行切分,将 l 和 m 存入共享内存,内循环切分 K\V,在内循环中只需要读写共享内存即可,减少了访存压力。
事实上在上述 3 个优化点中,第 2 和第 3 个点是相辅相成,实现了第 2 个点自然也实现了第 3 点,第一点仅仅是较少了一个除法指令,提升不大,笔者在本文中不予实现。本文涉及的 CUDA C++ 源代码如下所示,欢迎下载:
https://github.com/caiwanxianhust/flash-attention-opt
2 CUDA 实现:使用 ldmatrix 和 mma 指令
在上一篇文章中,笔者在实现 CUDA Kernel 时整体代码是基于 thread block 尺度的,也就是说,围绕矩阵计算的操作以及矩阵计算本身都是在 thread block 尺度写的代码,没有把任务完全划分到 warp 层级。另外在计算矩阵乘法时,之前也用的是 WMMA API,灵活性不足,因此,本次将结合 ldmatrix 和 mma 指令对代码进行改写。
2.1 计算任务分派
首先从 thread grid 层级分配一下计算任务,前面介绍过,要在 Q 矩阵的序列维度增加并行化,每个 thread block 不再处理整个 [N, d]矩阵,指定 block_size 为 128,分为 4 个 warp,每个 warp 处理的子矩阵形状为 [Br, d],4 个 warp 相互独立,不需要数据交换,因此一个 [N,d] 矩阵分摊到 N/(4 * Br) 个 block 处理,按照这个思路有如下的执行配置参数:
void launchFlashAttentionKernel_v5(const half* __restrict__ Q, const half* __restrict__ K, const half* __restrict__ V,
half* __restrict__ O, const int batch_size, const int num_head, const int N, const int M, const int d, cudaStream_t stream)
{
constexpr int Bc = 16;
constexpr int Br = 16;
// 让 Bd 等于 Bc 从而使得 QK 矩阵分片[Br, Bc] 与 QKV 矩阵分片[Br, Bd] 形状相同,方便排布
constexpr int Bd = Bc;
assert(M % Bc == 0 && N % (4 * Br) == 0 && d % Bc == 0);
const float softmax_scale = 1.0f / sqrtf((float)d);
/**
__shared__ half s_Q[4 * Br * d];
__shared__ half s_K[Bc * d];
__shared__ half s_V[Bc * d];
__shared__ half s_QK[4 * Br * Bc];
__shared__ half s_S[4 * Br * Bc];
__shared__ half s_O[4 * Br * Bd];
// 前一个 Bc 组的 l 和 m
__shared__ MD_F row_ml_prev[4 * Br];
__shared__ MD_F row_ml[4 * Br];
__shared__ MD_F row_ml_new[4 * Br];
*/
const int sram_size = (4 * Br * 3) * sizeof(MD_F) + (4 * Br * d + 2 * Bc * d + 4 * Br * Bc * 2 + 4 * Br * Bd) * sizeof(half);
dim3 grid_dim(div_ceil(N, 4 * Br), num_head, batch_size);
dim3 block_dim(128);
flashAttentionKernel_v5<Br, Bc, Bd> << <grid_dim, block_dim, sram_size, stream >> > (Q, K, V, O, N, M, d, softmax_scale);
}
从共享内存空间的计算公式可以看出,s_Q、s_K和s_V都是将整行元素都加载到共享内存中,其中s_Q形状为[4 * Br, d]每个 warp 负责维护一个[Br, d]子矩阵,互相独立,s_K和s_V则由 4 个 warp 共用。在隐藏层维度d为128时总共需要约31.5 KB共享内存,如果d 取更大的值,相应的共享内存需求量也会更大。
在 Kernel 内部我们使用 PTX 指令 ldmatrix 和 mma 进行矩阵乘法计算,mma 的矩阵形状为 m16n8k16,为了 与 两个矩阵乘法能够复用寄存器,所以我们实际的矩阵乘法形状为 m16n16k16,通过连续调用两次 mma 指令实现,因此矩阵分片形状参数分别设置为 16,具体如下:
Br:单个 warp 每次处理 Q 矩阵的行数(即序列长度)Bc:每次处理的 K\V 矩阵的行数(即序列长度)Bd:单次 m16n16k16 矩阵运算时的 k,即在 d 维度上的划分尺度
本文中的代码没有考虑 mask 和 padding 场景,假定满足以下尺寸约束条件。
assert(M % Bc == 0 && N % (4 * Br) == 0 && d % Bc == 0);
2.2 基础索引和变量定义
由于计算任务是具体到 warp 层级的,所以我们在 Kernel 内首先定义了线程索引 lane_id 和 warp_id,并结合本 warp 的计算任务定义了当前 warp 处理的数据在全局内存中 Q\K\V\O 的元素偏移量。
对于 Q\O 矩阵,每个 block 处理 4 个 [Br, d] 子矩阵,所以索引计算如下:
// 当前 warp 处理的 Q、O 矩阵偏移量
const uint32_t qo_offset = (blockIdx.z * gridDim.y + blockIdx.y) * N * d + blockIdx.x * 4 * Br * d + warp_id * Br * d;
对于 K\V 矩阵,整个 block 共用,所以计算到 block 层级即可:
const uint32_t kv_offset = (blockIdx.z * gridDim.y + blockIdx.y) * M * d;
此外还定义了一些共享内存变量,具体含义如下:
s_Q:加载 Q 矩阵分片,形状为 [4 * Br, d]s_K:加载 K 矩阵分片,形状为 [Bc, d]s_V:加载 V 矩阵分片,形状为 [Bc, d]s_QK:临时存储 矩阵,形状为 [4 * Br, Bc]s_S:临时存储 矩阵,形状为 [4 * Br, Bc]s_O:临时存储矩阵乘法 的结果,形状为 [4 * Br, Bd]row_ml_prev:存储截至前一个分片的所有行的 m 和 l,形状为 [4 * Br]row_ml:存储当前分片处理的所有行的 m 和 l,形状为 [4 * Br]row_ml_new:存储截至当前分片的所有行的 m 和 l,形状为 [4 * Br]
2.3 load Q from Gmem to Smem
由于在 Q 矩阵的序列维度不需要循环迭代,所以一开始就可以对 row_ml_prev 和 row_ml 进行初始化,而 row_ml_new 是在内循环中每轮更新的。同样地,s_Q 也可以在计算前一次性加载,每个 warp 仅需维护自己使用的数据,这里通过向量化加载,每个线程一次性 load 8 个 half。初始化完成后,使用 __syncwarp() 在 warp 内同步即可。
// 初始化 ml
#pragma unroll
for (int k = lane_id; k < Br; k += 32) {
row_ml_prev[warp_id * Br + k] = { -1e20f, 0.0f };
row_ml[warp_id * Br + k] = { -1e20f, 0.0f };
}
// load [4 * Br, d] 的 Q 矩阵分片到 s_Q,每个 warp load [Br, d],每次 load 8 个 half
for (int i = (lane_id << 3); i < Br * d; i += (32 << 3)) {
reinterpret_cast<float4*>(s_Q + warp_id * Br * d + i)[0] = reinterpret_cast<const float4*>(Q + qo_offset + i)[0];
}
__syncwarp();
前面介绍过,矩阵乘法的尺寸为 m16n16k16,所以 A\B\C 矩阵的形状都为 [16, 16],元素类型为 half,分摊到 warp 内每个线程,则每个线程需持有 16*16/32=8 个元素,对应 4 个寄存器,这里对 A\B 矩阵的寄存器进行定义,C 矩阵的寄存器在对 K\V 循环中进行定义和初始化。
// warp 矩阵乘法的尺寸为 16x16x16,调用两次 mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 指令
// 所以 3 个矩阵都需要 4 个寄存器
uint32_t RA[4];
uint32_t RB[4];
2.4 load K\V from Gmem to Smem
对 K\V 在 M 维度分组,每组长度为 Bc,每轮循环前先初始化矩阵 C 的寄存器 RC,然后从全局内存的 K\V 矩阵中 load 数据到 s_K 和 s_V,通过向量化加载,每个线程一次性 load 8 个 half。load 完成后,由于 K\V 是 4 个 warp 共用的,所以需要使用 __syncthreads() 在 block 内同步。
// 初始化矩阵 C 的寄存器
uint32_t RC[4] = { 0, 0, 0, 0 };
// load [Bc, d] 的 K 矩阵分片到 s_K,整个 block 一起 load [Br, d],每次 load 8 个 half
for (int j = (threadIdx.x << 3); j < Bc * d; j += (blockDim.x << 3)) {
reinterpret_cast<float4*>(s_K + j)[0] = reinterpret_cast<const float4*>(K + kv_offset + i * d + j)[0];
reinterpret_cast<float4*>(s_V + j)[0] = reinterpret_cast<const float4*>(V + kv_offset + i * d + j)[0];
}
__syncthreads();
2.5 填充 的 mma 指令的寄存器
Q\K\V 都 load 到共享内存以后,要计算 矩阵,需要在 d 维度上循环进行矩阵乘加操作,步长为 Bd=16。要说明的是,我们 Q\K\V 矩阵的形状均为 [batch_size, num_head, seq_len, d] 且行主序存储,且加载到共享内存时不做转置。因此,此时参与计算的 Q 矩阵分片 [Br, Bd](即 A 矩阵)是一个 16x16 的行主序的矩阵,我们使用 ldmatrix 指令将其加载到寄存器 RA 中,把 ldmatrix 指令封装为宏:
#define LDMATRIX_X4(R0, R1, R2, R3, addr) asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n" : "=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) : "l"(__cvta_generic_to_shared(addr)))
#define LDMATRIX_X4_T(R0, R1, R2, R3, addr) asm volatile("ldmatrix.sync.aligned.x4.trans.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n" : "=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) : "l"(__cvta_generic_to_shared(addr)))
关于 ldmatrix 指令的用法,笔者在上一篇文章中有详细介绍,本文不再赘述,有兴趣的可以阅读文章:【CUDA编程】关于矩阵乘加操作的四个指令(ldmatrix、mma、stmatrix、movmatrix)详解
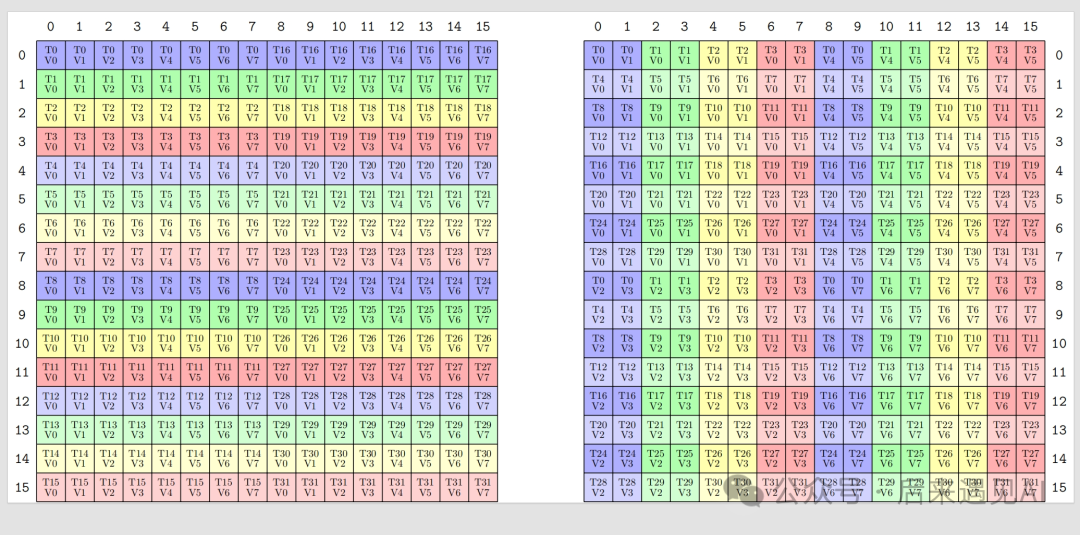
对于 A 矩阵按照上述内存排布 load 数据即可,warp 内每个线程均提供一个地址,按照左图计算索引,load 完成后各线程持有的矩阵元素见右图。
索引计算方式比较简单,整体来说先从上往下、再从左往右,即 4 个 m8n8 小矩阵的 load 顺序如下:
0-15 线程 load 0 和 1 号小矩阵,每行的首地址为 (lane_id % 16) * d,2 和 3 号小矩阵每行的首地址分别加 8,就得到如下地址计算公式。
// 从 s_Q load 16x16 矩阵分片到 RA,使用 ldmatrix.sync.aligned.x4.m8n8.shared.b16 指令
// warp 内每个线程都需要传入一个地址
uint32_t saddr = warp_id * Br * d + k + (lane_id % 16) * d + (lane_id / 16) * 8;
LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], s_Q + saddr);
对于 K 矩阵分片 [Bc, Bd](即 B 矩阵)的 load 有些特殊,B 矩阵在矩阵乘法中相当于时列主序的,而 mma 指令要求 B 矩阵也是列主序的,所以此时直接用 LDMATRIX_X4 加载即可,无需转置,内存排布如下所示:
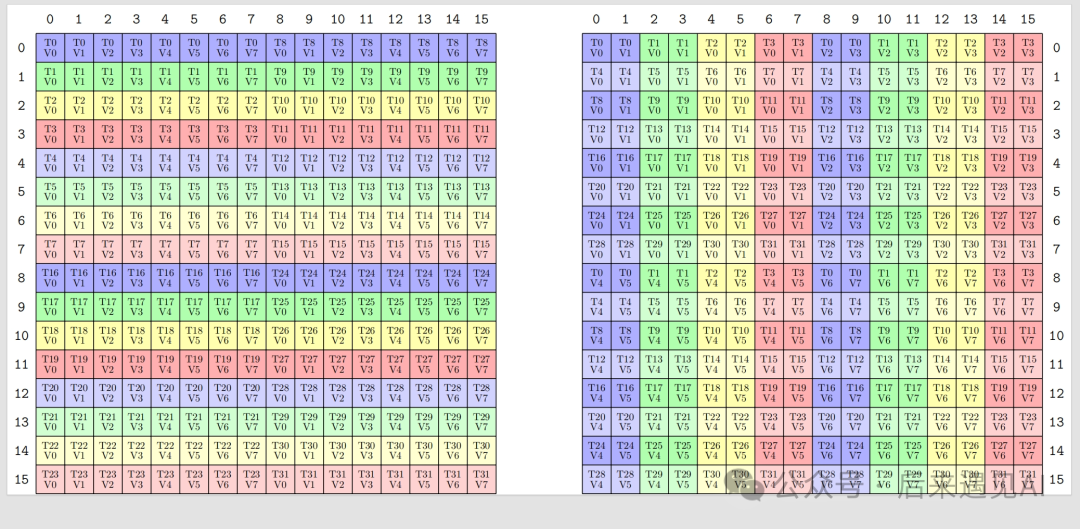
有两个地方需要注意:第一点,上述矩阵的形状为 [Bc, Bd](行主序),正好对应在 s_K 中的存储形式。第二点,上图与前面 A 矩阵的排布图有所不同,这是 mma 指令对 B 矩阵的特殊要求,按要求 load 即可,索引参照上图计算,load 完成后各线程持有的矩阵元素见右图。
索引计算方式与 A 矩阵有所不同,整体来说先从左往右、再从上往下,即 4 个 m8n8 小矩阵的 load 顺序如下:
warp 内线程 0-7加载第一个8x8矩阵,线程8-15加载第二个8x8矩阵,线程16-23加载第三个8x8矩阵, 线程24-31加载第四个8x8 矩阵,小矩阵的排布与 A 矩阵不同。
先来看小矩阵的偏移量,起始偏移量为:
(lane_id / 16) * d * 8 + ((lane_id / 8) % 2) * 8
再加上小矩阵内部的行偏移量:
(lane_id % 8) * d
得到整体偏移量计算公式:
// 从 s_K(列主序) load 16x16 矩阵分片到 RB,使用 ldmatrix.sync.aligned.x4.m8n8.shared.b16 指令
// warp 内线程 0-7 加载第一个 8x8 矩阵,线程 8-15 加载第二个 8x8 矩阵,线程 16-23 加载第三个 8x8 矩阵, 线程 24-31 加载第四个 8x8 矩阵
// 此时可以认为 4 个子矩阵是行主序排布的,子矩阵内部元素列主序排布
// 子矩阵偏移量 = ((lane_id / 8) % 2) * 8 + (lane_id / 16) * d * 8)
saddr = k + (lane_id % 8) * d + ((lane_id / 8) % 2) * 8 + (lane_id / 16) * d * 8;
LDMATRIX_X4(RB[0], RB[1], RB[2], RB[3], s_K + saddr);
2.6 计算 mma
本文中矩阵乘加操作基于 mma 指令进行,我们将其封装为宏:
#define MMA_M16N8K16_F16F16F16F16(RD0, RD1, RA0, RA1, RA2, RA3, RB0, RB1, RC0, RC1) asm volatile("mma.sync.aligned.m16n8k16.row.col.f16.f16.f16.f16 {%0, %1}, {%2, %3, %4, %5}, {%6, %7}, {%8, %9};\n" : "=r"(RD0), "=r"(RD1) : "r"(RA0), "r"(RA1), "r"(RA2), "r"(RA3), "r"(RB0), "r"(RB1), "r"(RC0), "r"(RC1))
A\B 矩阵按 mma 指令的内存布局要求加载到寄存器后,就可以执行 mma 计算了,因为 mma 指令没有 m16n16k16,所以我们通过执行两次 m16n8k16 代替,代码如下:
MMA_M16N8K16_F16F16F16F16(RC[0], RC[1], RA[0], RA[1], RA[2], RA[3], RB[0], RB[1], RC[0], RC[1]);
MMA_M16N8K16_F16F16F16F16(RC[2], RC[3], RA[0], RA[1], RA[2], RA[3], RB[2], RB[3], RC[2], RC[3]);
2.7 将 QK 从寄存器写入 Smem
在 d维度以Bd为步长循环执行 mma 操作,就把[Br, d] * [d, Bc]的结果存入了寄存器RC中,此时一个 warp 中的RC将持有一个形状为[Br, Bc]的矩阵,为了方便进行后续 softmax 计算我们将其写入共享内存s_QK 中,此时需要结合 mma 指令中 C 矩阵的内存排布进行索引计算:
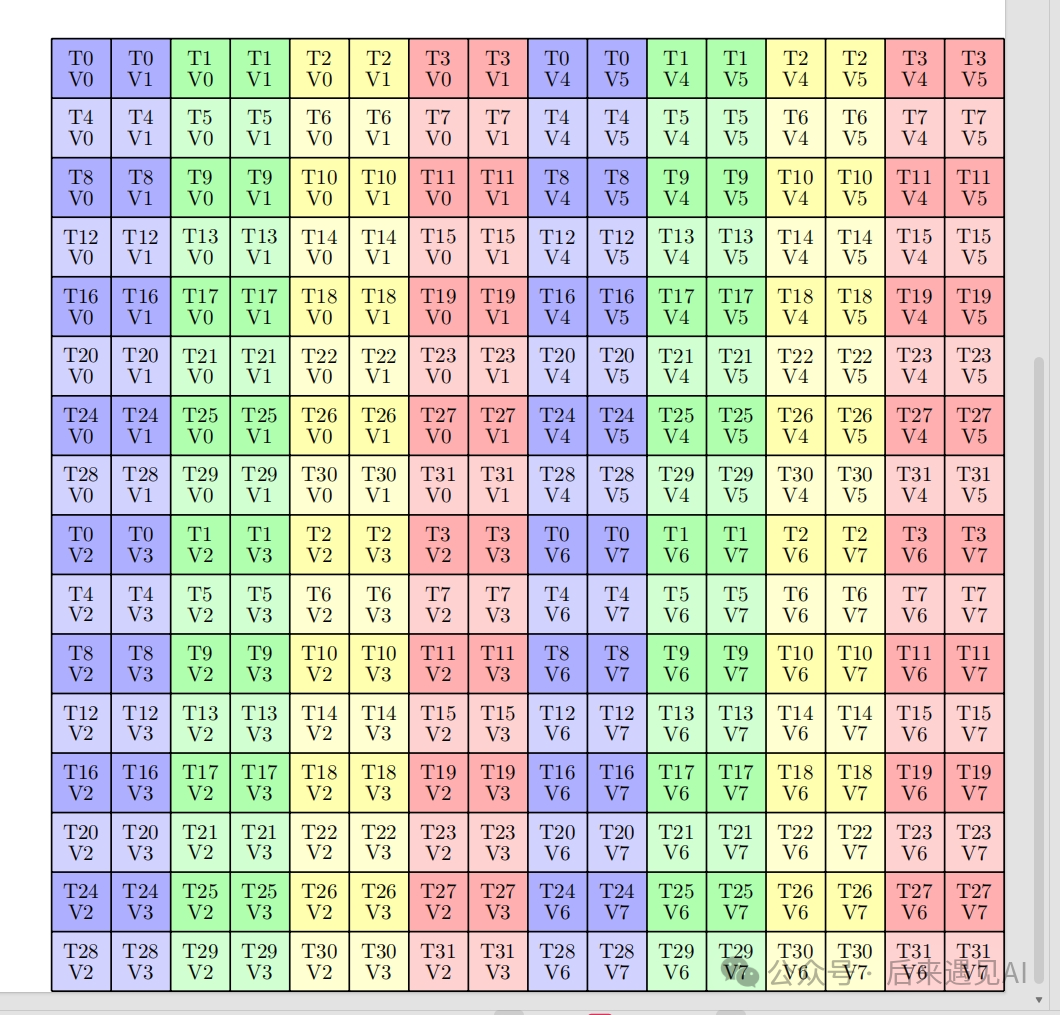
其实在 Hopper 架构中提供了 stmatrix 指令用于将 C 矩阵写入共享内存,但是无奈笔者没有 Hopper 的卡,只好手动写入。从图中可以看到,C 矩阵索引计算方式与 A\B 矩阵有所不同,整体来说分为 4 个 m8n8 小矩阵,且每个小矩阵中的元素都被一个 warp 持有,每个线程分别在每个小矩阵中持有 2 个元素,那我们分别写入即可。
不难发现,在小矩阵内部,行索引为 lane_id / 4(每行只有 4 个线程),列索引为 (lane_id % 4) * 2,那么 4 个小矩阵分别通过 4 行代码加载,思路比较清晰:
#define LDST32BITS(value) (reinterpret_cast<half2 *>(&(value))[0])
// 将矩阵 C 的寄存器变量写入 s_QK,每个 warp 仅负责 [Br, Bc] 分片,sm_90 之前不支持 stmatrix 指令
// 子矩阵按列主序填充,参照 mma 指令规定的矩阵 C 的元素排布,每次写入 32bit
uint32_t store_smem_qk_m = lane_id / 4;
uint32_t store_smem_qk_n = (lane_id % 4) * 2;
LDST32BITS(s_QK[warp_id * Br * Bc + store_smem_qk_m * Bc + store_smem_qk_n]) = LDST32BITS(RC[0]);
LDST32BITS(s_QK[warp_id * Br * Bc + (store_smem_qk_m + 8) * Bc + store_smem_qk_n]) = LDST32BITS(RC[1]);
LDST32BITS(s_QK[warp_id * Br * Bc + store_smem_qk_m * Bc + store_smem_qk_n + 8]) = LDST32BITS(RC[2]);
LDST32BITS(s_QK[warp_id * Br * Bc + (store_smem_qk_m + 8) * Bc + store_smem_qk_n + 8]) = LDST32BITS(RC[3]);
__syncwarp();
2.8 求 Softmax
对 s_QK 求 Softmax 整体还是采用 online-softmax 思想,循环计算 m 和 l,关于 online-softmax 原理有兴趣的可以阅读笔者的另一篇文章:【CUDA编程】online softmax 的 CUDA 实现
每个 warp 需要完成 [Br, Bc] 矩阵的按行 softmax,即一个 [16, 16] 矩阵,共有 256 个元素。如果使用一个线程计算一行元素的方式,显然有一半的线程要闲置,并且存在 bank conflict。为了避免这种情况,我们不妨换个思路,一个 warp 每次单独处理 2 行(32 个元素),在 0-15 和 16-31 两个线程组内分别做规约,然后整体循环 8 次。
在 16 个线程组成的线程组内做规约的代码我们可以参考 warp 内规约实现,借助 __shfl_xor_sync 指令交换数据。MD_F 对象的更新公式为:
代码及实现如下:
template <int GroupSize = 16>
__device__ __forceinline__ MD_F threadGroupAllReduce(MD_F val) {
float tmp_m;
#pragma unroll
for (int mask = (GroupSize / 2); mask > 0; mask >>= 1) {
tmp_m = max(val.m, __shfl_xor_sync(0xffffffff, val.m, mask, GroupSize));
val.d = val.d * __expf(val.m - tmp_m) + __shfl_xor_sync(0xffffffff, val.d, mask, GroupSize) * __expf(__shfl_xor_sync(0xffffffff, val.m, mask, GroupSize) - tmp_m);
val.m = tmp_m;
}
return val;
}
// 对 s_QK 求 softmax,每个 warp 单独计算 [16, 16] 矩阵的 softmax,根据 online-softmax 先计算 m 和 l
// 一个 warp 每次单独处理两行,在 warp 内的 16 个线程内部做规约,总共需要处理 8 次
#pragma unroll
for (int j = 0; j < 8; j++) {
// 读取 2 行数据到 warp
MD_F tmp_ml = { __half2float(s_QK[warp_id * Br * Bc + j * 32 + lane_id]) * softmax_scale, 1.0f };
__syncwarp();
// 每行数据由 16 个线程组成的 group 持有,内部 reduce
tmp_ml = threadGroupAllReduce<16>(tmp_ml);
// 当前线程处理的行索引
uint32_t current_row = warp_id * Br + j * 2 + (lane_id / 16);
if ((lane_id % 16) == 0) {
row_ml[current_row] = tmp_ml;
row_ml_new[current_row] = MDFOp()(row_ml_prev[current_row], tmp_ml);
}
__syncwarp();
s_S[current_row * Bc + (lane_id % 16)] = __float2half(
__expf(__half2float(s_QK[current_row * Bc + (lane_id % 16)]) * softmax_scale - row_ml[current_row].m));
__syncwarp();
}
规约计算出 m 和 l 后,顺带更新 row_ml 和 row_ml_new,然后依据 safe-softmax 思想将 s_QK 中的元素减去每行最大值后取指数存入 s_S 用于后续计算。
2.9 填充 的 mma 指令的寄存器
在 计算中,整体矩阵的计算尺寸为[Br, d] * [d, Bc] -> [Br, Bc],由于d的值通常比较大,所以我们在d的维度上让Q和K以步长Bd切分为[16, 16]小矩阵后滑动进行矩阵乘加。 有所不同,其整体计算尺寸为[Br, Bc] * [Bc, d] -> [Br, d],左矩阵s_S已经是一个[16, 16]矩阵了,所以只需要让右矩阵 V 在d的维度上以步长Bd切分为[16, 16] 小矩阵后滑动进行矩阵乘法即可,无需累加结果矩阵。这里透露出 3 个点:
- A 矩阵只需要在循环前初始化一次,每轮复用即可
- 每轮循环时都需要将 C 矩阵初始化为 0
- B 矩阵是在每轮循环时滑动读取
s_V 中的矩阵分片来填充
下面我们来填充 A 矩阵的寄存器,将前面 softmax 的结果 s_S填充到寄存器RA中作为操作的左矩阵(即 A 矩阵) ,依然还是使用 ldmatrix 指令填充,索引计算方式不变,但要注意的是,s_S与s_Q都是行主序,但是 stride 有所不同,前者是Bc(即16),后者是d,所以参照着 2.5 节的索引计算公式把d换成Bc 即可。
// 从 s_S load 到 RA,使用 ldmatrix.sync.aligned.x4.m8n8.shared.b16 指令
// warp 内每个线程都需要传入一个地址
uint32_t warp_offset = warp_id * Br * Bc;
LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], s_S + warp_offset + (lane_id % 16) * Bc + (lane_id / 16) * 8);
在每一次滑动计算前,都需要将结果矩阵的寄存器初始化为 0,前面说过,本文的两个矩阵乘法尺寸均为 m16n16k16,所以寄存器 RA、RB 和 RC 是复用的,所以直接初始化 RC 即可。
// 计算 QKV 矩阵,每次计算尺寸为 16x16x16,
for (int k = 0; k < d; k += Bd) {
// 初始化 RC
RC[0] = 0;
RC[1] = 0;
RC[2] = 0;
RC[3] = 0;
...
}
接下来要填充 B 矩阵,这里就不能参考 2.5 中的 s_K矩阵的填充了,因为虽然s_K和s_V的形状都为[bs, bh, M, d],且都为行主序,但是在矩阵乘法中两者的意义完全不同,s_K是以转置的形式参与矩阵运算的,而s_V就是以V的形式参与矩阵乘法,无需转置。而 mma 指令要求 B 矩阵是以转置的形式存储在寄存器RB中,所以这里的要用到 ldmatrix 指令的转置形式,我们将其封装为LDMATRIX_X4_T 宏,通过 ldmatrix 转置指令,我们无需关心线程直接寄存器的数据交换问题,内存排布图如下:
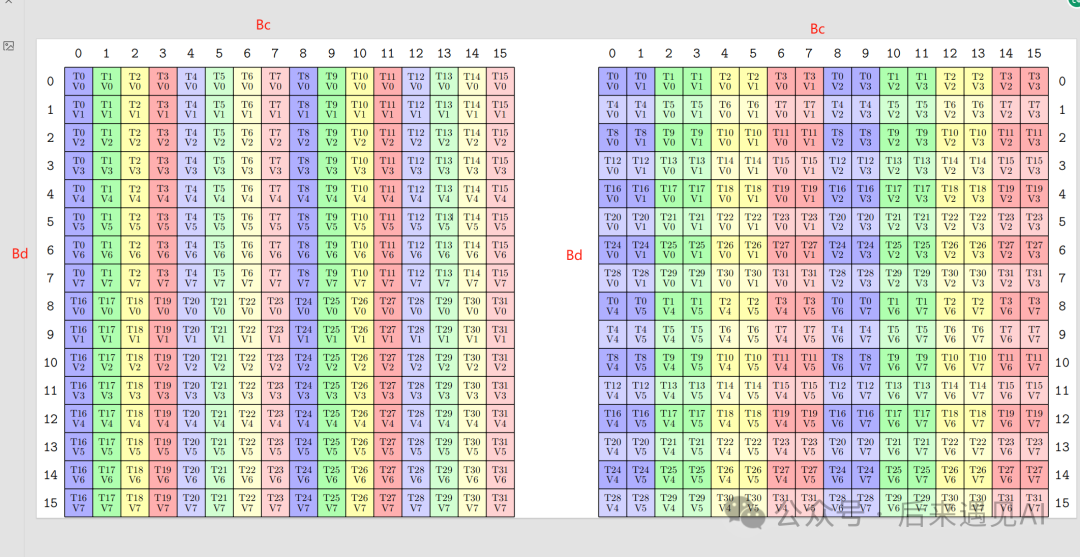
上图中矩阵的维度参数都已标出,源矩阵是一个 [Bd, Bc] 列主序的矩阵,其实相当于 [Bc, Bd] 行主序矩阵,与 s_V 的内存排序正好对应,右矩阵是转置之后的样子。为什么要转置?前面介绍过,这是 mma 指令对参与矩阵的布局要求,目前针对 m8n8 仅支持 row.col 乘法。根据左图,我们有如下的索引计算公式:
// 从 s_V load 16x16 矩阵分片到 RB,使用 ldmatrix.sync.aligned.x4.trans.m8n8.shared.b16 指令
// warp 内每个线程都需要传入一个地址
LDMATRIX_X4_T(RB[0], RB[1], RB[2], RB[3], s_V + k + (lane_id % 16) * d + (lane_id / 16) * 8);
可以看到,s_V 的索引计算与 s_Q 类似,所以简单起见可以这样认为,当 B 矩阵是以 [k, n] 形状行主序存储时,其索引计算完全参照以 [m, k] 形状行主序存储的 A 矩阵即可,仅需要把指令换成转置形式。直白一点,按不转置计算索引,转置的事情交给底层指令。
2.10 计算 mma
寄存器填充完成后,直接调用 mma 指令计算即可,这里没有什么特殊的,代码与 2.6 一致。
MMA_M16N8K16_F16F16F16F16(RC[0], RC[1], RA[0], RA[1], RA[2], RA[3], RB[0], RB[1], RC[0], RC[1]);
MMA_M16N8K16_F16F16F16F16(RC[2], RC[3], RA[0], RA[1], RA[2], RA[3], RB[2], RB[3], RC[2], RC[3]);
2.11 将 从寄存器写入 Smem
无论 A\B 矩阵布局怎么变,mma 指令的结果矩阵的内存布局都是固定的,所以从寄存器中将结果写回的操作索引计算都是相似的,这里不再赘述,直接参考 2.7 即可。
// 将矩阵 C 的寄存器变量写入 s_O[4 * Br, Bd],每个 warp 仅负责 [Br, Bd] 分片,sm_90 之前不支持 stmatrix 指令
// 子矩阵按列主序填充,参照 mma 指令规定的矩阵 C 的元素排布,每次写入 32bit
uint32_t store_smem_o_m = lane_id / 4;
uint32_t store_smem_o_n = (lane_id % 4) * 2;
LDST32BITS(s_O[warp_id * Br * Bd + store_smem_o_m * Bd + store_smem_o_n]) = LDST32BITS(RC[0]);
LDST32BITS(s_O[warp_id * Br * Bd + (store_smem_o_m + 8) * Bd + store_smem_o_n]) = LDST32BITS(RC[1]);
LDST32BITS(s_O[warp_id * Br * Bd + store_smem_o_m * Bd + store_smem_o_n + 8]) = LDST32BITS(RC[2]);
LDST32BITS(s_O[warp_id * Br * Bd + (store_smem_o_m + 8) * Bd + store_smem_o_n + 8]) = LDST32BITS(RC[3]);
__syncwarp();
2.12 更新 O 矩阵
的结果存储在 s_O 中,形状为 [16, 16],我们要把这个结果根据 Flash Attention 公式更新到全局内存 O 矩阵中。本文开始时笔者介绍过,省略 rescale 运算这个优化点笔者没有实现,因此更新公式与 V1 版本一致,具体如下,推导过程可以阅读我的上一篇 Flash Attention 文章,这里不在赘述。
公式有了之后就是分配任务的问题,由于 s_O 的形状为 [16, 16],所以每个 warp 更新 O 矩阵的范围也是 [16, 16] 的矩阵分片,每个 warp 更新 2 行,一个 warp 分为 2 组,每组处理一行 16 个元素,整体循环 8 次,代码如下,注释比较清晰,就不再赘述了。
// 更新 O,每个 warp 每次更新 [16, 16] 分片
// 一个 warp 每次单独处理两行,在 warp 内的 16 个线程为一组,总共需要处理 8 次
#pragma unroll
for (int j = 0; j < 8; j++) {
// 当前元素在 [16, 16] 矩阵中的行索引
uint32_t current_row = j * 2 + (lane_id / 16);
// 当前元素在矩阵 O 中的索引
uint32_t out_idx = qo_offset + current_row * d + k + (lane_id % 16);
// 当前元素在矩阵 s_O[4 * Br, Bd] 中的索引
uint32_t s_o_idx = warp_id * Br * Bd + current_row * Bd + (lane_id % 16);
// exp(m_prev-m_new)
float exp_sub_prev_new_m = __expf(row_ml_prev[warp_id * Br + current_row].m - row_ml_new[warp_id * Br + current_row].m);
// exp(m_cur-m_new)
float exp_sub_cur_new_m = __expf(row_ml[warp_id * Br + current_row].m - row_ml_new[warp_id * Br + current_row].m);
// 1.0 / l_new
float rlf_i = 1.0f / row_ml_new[warp_id * Br + current_row].d;
// 更新矩阵 O
O[out_idx] = __float2half(rlf_i * (row_ml_prev[warp_id * Br + current_row].d * exp_sub_prev_new_m * __half2float(O[out_idx]) +
exp_sub_cur_new_m * __half2float(s_O[s_o_idx])));
}
2.13 更新 row_ml_prev
最后注意在每次沿 M 维度迭代之后将本组计算得到的 row_ml_new 更新到 row_ml_prev,以备下一次循环使用。
// 更新 row_ml_prev
if (lane_id < Br) {
row_ml_prev[warp_id * Br + lane_id] = row_ml_new[warp_id * Br + lane_id];
}
__syncthreads();
至此,主要逻辑都已经介绍完毕,完整代码可以下载下来结合博客查阅。
3 CUDA 实现:加入 swizzle 策略
回顾一下前面的数据加载过程,不难发现一个问题,在对 shared memory 进行访问的时候,我们都是以矩阵分片的形式整体读写,而没有考虑过 shared memory 的 bank conflict 机制,那么以上写法是否会有 bank conflict 呢?当然是有的,下面会逐步进行分析。
如何优化 bank conflict 场景?通过 swizzle 策略。
3.1 bank conflict 机制
要回答这个问题,我们先来回顾一下 bank conflict 的定义,也就是说什么是 bank conflict。
共享内存在物理上被划分为连续的 32 个 bank,这些 bank 宽度相同且能被同时访问,从 Maxwell 架构开始,每个 bank 宽度为 32bit,即 4 个字节,bank 带宽为每个时钟周期 32bit。32 个 bank 对应 warp 的 32 个线程,其用意是在一次内存事务中每个线程各自访问一个 bank,仅需要一次内存事务(即 32 个线程并行化访问)。如果 warp 内多个线程在一次内存访问中访问到了同一个 bank,则如下两种场景:
- 如果来自一个 warp 的多个线程访问到共享内存中相同 32bit 内的某个字节时,不会产生 bank conflict,读取操作会在一次广播中完成,如果是写入操作,也不会有 bank conflict,且仅会被其中一个线程写入,具体是哪个线程未定义;
- 而如果来自一个 warp 的多个线程访问的是同一个 bank 的不同 32bit 的地址,则会产生 bank conflict。
我们可以把共享内存的 32 个 bank 想象为由很多层组成,每个 bank 每层有 32bit,假设同一 warp 内的不同线程访问到某个 bank 的同一层的数据,此时不会发生 bank conflict,但如果同一 warp 内的不同线程访问到某个 bank 的不同层的数据,此时将产生 bank conflict。
3.2 Q\K\V 的访问优化
由于 Q\K\V 矩阵分片在共享内存中具有相似的内存排布形式,如 [Br, d]、[Bc, d],本文 Kernel 中 Br = Bc = 16,d 通常取 128,我们就以这个场景分析一下访问 shared memory 中 Q\K\V 矩阵分片的 bank conflict 情况。
当 Br = Bc = 16,d = 128 时,Q\K\V 矩阵分片的形状为 [16, 128](未特殊说明时均为行主序),而 mma 操作要求的 mnk 均为 16,所以我们仅在 d 维度上滑动加载,示意图如下:
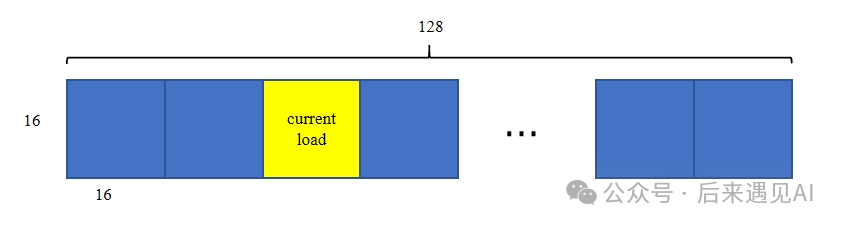
也就是说,在一个 [16, 128] 大矩阵中,我们每次滑动 load 一个 [16, 16] 小矩阵到寄存器,要分析这个小矩阵是否存在 bank conflict,就要搞清楚,这个小矩阵的每个元素都在哪个 bank 中。
以 half类型为例,在一个[16, 128]大矩阵中,每个元素占 2 个字节,一行128个元素占256个字节。而 shared memory 中每4个字节为1个 bank,32个 bank占用128个字节,也就是说,一个[16, 128]大矩阵的一行正好对应两组 32 bank 的 shared memory。换句话说,在[16, 128]大矩阵中,同一列元素位于同一个 bank!按照这个思路我们总结一下,当元素类型为half时,只要 stride 长度为64 的整数倍,矩阵的同一列元素都将位于同一个 bank。
我们每次加载 [16, 16] 小矩阵是通过 ldmatrix.sync.aligned.x4.m8n8 指令加载的,即分 4 次每次加载一个 m8n8 矩阵,对于这个 m8n8 矩阵而言,由于同一列的元素在同一个 bank,那么一个 warp 的线程需要 8 次内存访问才能完全访问这个 m8n8 矩阵,所以产生了 4x7-way bank conflict。
怎么才能解决这个问题,合理的想法是改变 shared memory 的内存排布,方法不止一种,本文只介绍通过 swizzle 策略来优化这个问题。网上关于 swizzle 策略的文章有很多,笔者就不班门弄斧了,本文只介绍用法,具体原理有兴趣的可以在知乎上搜一搜相关文章,笔者推荐 reed 大佬的文章:cute 之 Swizzle
所谓 swizzle 就是说,我们在从 global memory 往 shared memory 加载矩阵分片的时候,打乱原始顺序,让同一 warp 线程在读取 m8n8 矩阵的时候访问到不同 bank 上。具体通过一个 swizzle 函数实现,输入是逻辑地址,输出是映射后地址。
/**
* \tparam S: SShift, right shift the addr for swizzling
* \tparam B: BShift, bits to be swizzled
* \tparam M: MBase, bits keep the same
*/
template <uint32_t B, uint32_t M, uint32_t S>
__device__ __forceinline__ uint32_t swizzle(uint32_t addr)
{
constexpr auto Bmask = ((1 << B) - 1) << M;
return ((addr >> S) & Bmask) ^ addr;
}
swizzle 函数有 3 个模板参数,M 表示线程一次加载个元素,把这个元素称为一个新元素,这个值与数据类型有关,在ldmatrix.sync.aligned.x4.m8n8.shared.b16场景下这个值等于3;S表示一行有个新元素,当源矩阵 stride 小于64,如16或32时,S取3;B表示以 行为单位重映射。
在本文的场景下,M 取3;d = 128包含16个8个half组成的新元素,所以S取4;以8行为单位重映射,所以B取3。按照这个思路调用 swizzle 函数后,原矩阵在 shared memory 中的实际排布如下图示意:

上图中每个小格子代表原矩阵中连续的 8 个 half 元素,也表示 ldmatrix 指令的 m8n8 矩阵的一行。左上图表示 global memory 中的布局,笔者把一次 load 的 [16, 16] 矩阵上了色,相同颜色的格子表示一次 m8n8 load 的小矩阵。可以发现,原本在全局内存中的 m8n8 矩阵如果直接直接 load 到 shared memory,每行的元素都在一个 bank,势必造成 bank conflict,但是按右上图加载以后,同色的 8 行分属不同列,属于不同的 bank,因此 bank conflict 被消除。
右上图是映射后的内存排布图,右下图表示的是在寄存器中的矩阵布局,应与原矩阵保持一致。从图中可以看出,总共有两个地方需要用到 swizzle 函数:load QKV from gmem to smem 以及 load QKV from smem to reg,即“一写一读”。
对于 Q 矩阵,写入 shared memory 的时候:
// load [4 * Br, d] 的 Q 矩阵分片到 s_Q,每个 warp load [Br, d],每次 load 8 个 half
// s_Q 的宽度是 d,当大于 64 的时候 swizzle_B 应该取 3,当前按 d = 128 考虑
for (int i = (lane_id << 3); i < Br * d; i += (32 << 3)) {
uint32_t dst_addr = swizzle<3, 3, 4>(i);
reinterpret_cast<float4*>(s_Q + warp_id * Br * d + dst_addr)[0] = reinterpret_cast<const float4*>(Q + qo_offset + i)[0];
}
__syncwarp();
从 shared memory 往寄存器 load 的时候:
// 从 s_Q load 16x16 矩阵分片到 RA,使用 ldmatrix.sync.aligned.x4.m8n8.shared.b16 指令
// warp 内每个线程都需要传入一个地址
uint32_t src_addr = k + (lane_id % 16) * d + (lane_id / 16) * 8;
uint32_t dst_addr = swizzle<3, 3, 4>(src_addr);
LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], s_Q + warp_id * Br * d + dst_addr);
对于 K、V 矩阵也是类似的,写入 shared memory 的时候:
// load [Bc, d] 的 K 矩阵分片到 s_K,整个 block 一起 load [Br, d],每次 load 8 个 half
// s_K s_V 的宽度是 d,当大于 64 的时候 swizzle_B 应该取 3,当前按 d = 128 考虑
for (int j = (threadIdx.x << 3); j < Bc * d; j += (blockDim.x << 3)) {
uint32_t dst_addr = swizzle<3, 3, 4>(j);
reinterpret_cast<float4*>(s_K + dst_addr)[0] = reinterpret_cast<const float4*>(K + kv_offset + i * d + j)[0];
reinterpret_cast<float4*>(s_V + dst_addr)[0] = reinterpret_cast<const float4*>(V + kv_offset + i * d + j)[0];
}
__syncthreads();
从 shared memory 往寄存器 load 的时候:
// 从 s_K(列主序) load 16x16 矩阵分片到 RB,使用 ldmatrix.sync.aligned.x4.m8n8.shared.b16 指令
// warp 内线程 0-7 加载第一个 8x8 矩阵,线程 8-15 加载第二个 8x8 矩阵,线程 16-23 加载第三个 8x8 矩阵, 线程 24-31 加载第四个 8x8 矩阵
// 此时可以认为 4 个子矩阵是行主序排布的,子矩阵内部元素列主序排布
// 子矩阵偏移量 = ((lane_id / 8) % 2) * 8 + (lane_id / 16) * d * 8)
src_addr = k + (lane_id % 8) * d + ((lane_id / 8) % 2) * 8 + (lane_id / 16) * d * 8;
dst_addr = swizzle<3, 3, 4>(src_addr);
LDMATRIX_X4(RB[0], RB[1], RB[2], RB[3], s_K + dst_addr);
// 从 s_V load 16x16 矩阵分片到 RB,使用 ldmatrix.sync.aligned.x4.trans.m8n8.shared.b16 指令
// warp 内每个线程都需要传入一个地址
uint32_t src_addr = k + (lane_id % 16) * d + (lane_id / 16) * 8;
uint32_t dst_addr = swizzle<3, 3, 4>(src_addr);
LDMATRIX_X4_T(RB[0], RB[1], RB[2], RB[3], s_V + dst_addr);
总的来说,原本代码中的索引计算部分不用变更,只需要在写入和读取 shared memory 的时候加一层 swizzle 即可。
3.3 、 与 的访问优化
Q\K\V 矩阵分片在共享内存中具有相似的内存排布形式,读写方式也类似,所以有相同的 swizzle 参数,上节中一并进行介绍。同样地, 、 与 在 shared memory 中也具有相同的内存排布,因此两者也有相同的 swizzle 映射方式,下面进行介绍。
warp 中的线程对 shared memory 中 、 与 三个矩阵的访问有下面 5 个场景:
- 第一次 mma 计算完成后从寄存器写入 ;
- 读取 ,用于 Softmax 计算;
- Online Softmax 完成后从 中读取到寄存器;
- 第二次 mma 计算完成后从寄存器将 写回 shared memory;
- 读取 用于更新 矩阵。
在 Br = Bc = Bd = 16且元素类型为half的场景下,每个 warp 访问的 shared memory 中的 、 与 矩阵的尺寸都是[16, 16],对这个[16, 16]矩阵来说,每行16个元素,占32个字节,每4行元素组成32个 bank,而 warp 在读写数据的时候是以m8n8为单位分4次访问的。那么对于一次m8n8访问,第0-3行分别会与第4-7 行产生 bank conflict。
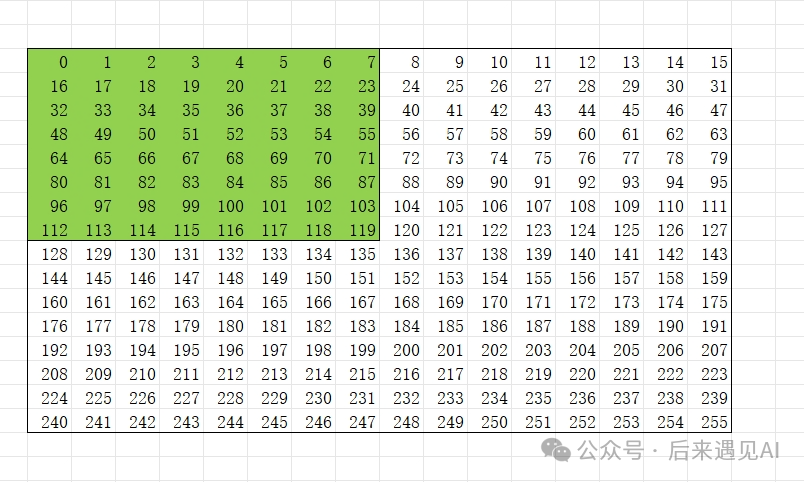
如上图所示,在一次 m8n8 访问中,索引为 0-7 的行与 64-71 的行都属于 shared memory 的第 0-3 bank,存在 bank conflict。可能直接看这个图不够清晰,那我们不妨把 [16, 16] 矩阵按 32 个 bank 为一行进行平铺如下:
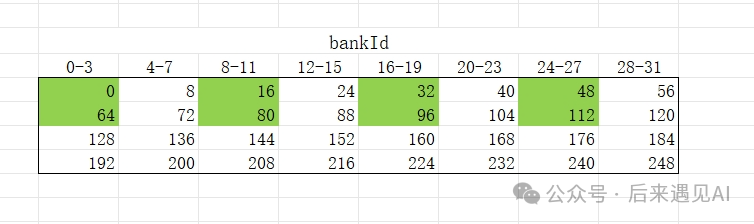
上图中一个格子代表连续的 8 个元素,可以清晰地看出存在 1x4 way bank conflict,下面我们基于 swizzle 函数将其重映射。
显然参数 M取3;每行 stride 为16占8个 bank,不足32个 bank 按32bank 为一行铺平,所以铺平后一行有个新元素,S取3;一个m8n8矩阵占用行,所以B取1。按照这个思路调用 swizzle 函数后,原矩阵在 shared memory 中的实际排布如下图示意:
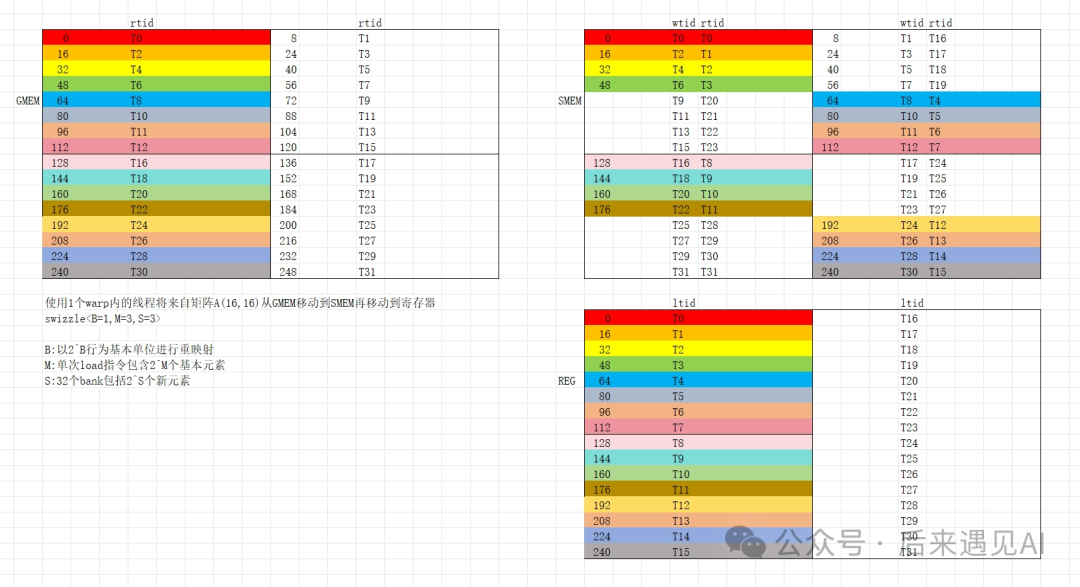
按 32 个 bank 为一行铺平后如下,很显然 bank conflict 已经被消除。

从寄存器写入 :
// 将矩阵 C 的寄存器变量写入 s_QK,每个 warp 仅负责 [Br, Bc] 分片,sm_90 之前不支持 stmatrix 指令
// 子矩阵按列主序填充,参照 mma 指令规定的矩阵 C 的元素排布,每次写入 32bit
// s_QK 宽度为 Bc,等于 16,此时 swizzle_B = 1
uint32_t store_smem_qk_m = lane_id / 4;
uint32_t store_smem_qk_n = (lane_id % 4) * 2;
uint32_t dst_addr_c0 = swizzle<1, 3, 3>(store_smem_qk_m * Bc + store_smem_qk_n);
uint32_t dst_addr_c1 = swizzle<1, 3, 3>((store_smem_qk_m + 8) * Bc + store_smem_qk_n);
uint32_t dst_addr_c2 = swizzle<1, 3, 3>(store_smem_qk_m * Bc + store_smem_qk_n + 8);
uint32_t dst_addr_c3 = swizzle<1, 3, 3>((store_smem_qk_m + 8) * Bc + store_smem_qk_n + 8);
LDST32BITS(s_QK[warp_id * Br * Bc + dst_addr_c0]) = LDST32BITS(RC[0]);
LDST32BITS(s_QK[warp_id * Br * Bc + dst_addr_c1]) = LDST32BITS(RC[1]);
LDST32BITS(s_QK[warp_id * Br * Bc + dst_addr_c2]) = LDST32BITS(RC[2]);
LDST32BITS(s_QK[warp_id * Br * Bc + dst_addr_c3]) = LDST32BITS(RC[3]);
__syncwarp();
在读取 做 Softmax 的时候由于上述 swizzle 映射不改变数据存储的行索引,因此按行 Softmax 的时候也无需知道其逻辑地址,只需要在后续 mma 计算前 swizzle 即可。
从 中读取到寄存器:
// 从 s_S load 到 RA,使用 ldmatrix.sync.aligned.x4.m8n8.shared.b16 指令
// warp 内每个线程都需要传入一个地址
// s_S 布局与 s_QK 一致,所以通过 swizzle<1, 3, 3> 映射
uint32_t warp_offset = warp_id * Br * Bc;
uint32_t dst_addr = swizzle<1, 3, 3>((lane_id % 16) * Bc + (lane_id / 16) * 8);
LDMATRIX_X4(RA[0], RA[1], RA[2], RA[3], s_S + warp_offset + dst_addr);
从寄存器将 写回 shared memory:
// 将矩阵 C 的寄存器变量写入 s_O[4 * Br, Bd],每个 warp 仅负责 [Br, Bd] 分片,sm_90 之前不支持 stmatrix 指令
// 子矩阵按列主序填充,参照 mma 指令规定的矩阵 C 的元素排布,每次写入 32bit
// s_O 宽度为 Bd,等于 16,此时 swizzle_B = 1
uint32_t store_smem_o_m = lane_id / 4;
uint32_t store_smem_o_n = (lane_id % 4) * 2;
uint32_t dst_addr_c0 = swizzle<1, 3, 3>(store_smem_o_m * Bd + store_smem_o_n);
uint32_t dst_addr_c1 = swizzle<1, 3, 3>((store_smem_o_m + 8) * Bd + store_smem_o_n);
uint32_t dst_addr_c2 = swizzle<1, 3, 3>(store_smem_o_m * Bd + store_smem_o_n + 8);
uint32_t dst_addr_c3 = swizzle<1, 3, 3>((store_smem_o_m + 8) * Bd + store_smem_o_n + 8);
LDST32BITS(s_O[warp_id * Br * Bd + dst_addr_c0]) = LDST32BITS(RC[0]);
LDST32BITS(s_O[warp_id * Br * Bd + dst_addr_c1]) = LDST32BITS(RC[1]);
LDST32BITS(s_O[warp_id * Br * Bd + dst_addr_c2]) = LDST32BITS(RC[2]);
LDST32BITS(s_O[warp_id * Br * Bd + dst_addr_c3]) = LDST32BITS(RC[3]);
__syncwarp();
读取 用于更新 矩阵时通过 swizzle 找到逻辑地址:
// 当前元素在 [16, 16] 矩阵中的行索引
uint32_t current_row = j * 2 + (lane_id / 16);
// 当前元素在矩阵 s_O[4 * Br, Bd] 中的索引
uint32_t s_o_idx = warp_id * Br * Bd + swizzle<1, 3, 3>(current_row * Bd + (lane_id % 16));
至此本文代码中所有 swizzle 策略的地方已介绍完毕,通过 ncu 分析可以看出加入 swizzle 映射后整体 bank conflict 次数降低了 99.33%,至于为什么没有降到 0,笔者也没有搞懂,欢迎大佬们指出意见。
4 小结
本文基于 Flash Attention V2 的主要思路结合 PTX 指令应用给出基于笔者理解的 CUDA 实现,并结合 swizzle 机制优化了前几个 Kernel 都存在的 bank conflict 问题,本文源码地址如下,欢迎下载阅读,对于源代码中前几个 Kernel 实现如有疑问,欢迎阅读上一篇文章:【CUDA编程】Flash Attention CUDA 算子的实现思路
https://github.com/caiwanxianhust/flash-attention-opt
如果你对更多底层性能优化和人工智能加速计算感兴趣,欢迎在云栈社区交流探讨。
 发表于 2026-4-11 04:40:03
|
查看: 203|
回复: 0
发表于 2026-4-11 04:40:03
|
查看: 203|
回复: 0
