从“码农”到“AI团队负责人”
我已经记不清上一次亲自打开 IDE 手敲代码是什么时候了。
2021 年 GitHub Copilot 刚推出时,我还觉得这玩意儿挺鸡肋——不就是个代码补全工具吗?而且经常补得牛头不对马嘴。可短短几年过去,我却发现自己已经彻底从“写代码的人”,变成了给 AI 打下手的那一个。
很多开发者可能都有过类似的迷茫:亲手把代码从零写出来、调试通过,那种实打实的成就感才是编程真正的乐趣啊。如果全交给 AI,那我们还剩下什么?还有什么意思呢?
后来我慢慢想明白了,这其实不是乐趣没了,而是爽点需要切换。
就像一个技术 Leader,很多年都不亲自写业务代码了,但他依然能从项目成功中获得强烈的成就感。因为他的价值不再是“自己写对代码”,而是“让团队写对代码”。在 AI Coding 时代,我们也面临同样的转变——从亲手编码,切换到精准调教 AI。这种更高阶的掌控感,带来的成就感其实只增不减。
这本质上是一次开发者角色的根本性转变。
在传统开发模式里,我们 70%-80% 的时间都耗在机械的编码、调试和琐碎实现上,只有少部分时间用来思考需求、设计架构。而在 AI Coding 时代,这个比例几乎完全反转:你 80% 以上的精力,都会花在架构设计、需求拆解、规范制定、任务编排和结果审核上。真正的编码细节,全部交给 AI 完成。
你不再是一线码农,而是变成了 AI Agent 团队的技术负责人。你要像管理一支工程师团队一样,去拆解模糊的业务目标、制定规则和边界、严格验收成果、把控质量底线——只不过你管理的,是一群执行力极强、却极度需要清晰指令的 AI。
很多人用不好 AI Coding,根源就在于角色没有真正转变。他们依然把自己当成写代码的人,把 AI 当成“聪明一点的敲键盘助理”,而不是用管理者的视角去定规则、提需求、做验收,最终只能陷入“AI 写、自己改、越改越乱”的恶性循环。在云栈社区,也有很多开发者在探讨如何更好地驾驭 AI,转变思维是第一步。
选对模型
现在市面上的 AI 编程工具真的卷麻了,IDE 插件、CLI 工具、独立客户端各种形态都有。但编程工具其实只是个壳子,真正决定 AI Coding 好不好用的,永远是底层大模型。模型选拉胯了,再花里胡哨的工具都是屎上雕花。
如果预算拉满、还能搞定网络问题,海外御三家绝对是复杂场景的天花板首选。尤其是 Claude 4.6 Opus,面对复杂业务和高难度架构需求,基本一遍就能给出能用的代码,省心到爆。但缺点也很现实:非常考验钱包的深度,国内使用门槛也高,只适合有条件的团队和高端场景。
对我们国内绝大多数开发者来说,其实目前国内的一些优秀的开源模型已经能够胜任绝大部分开发场景了。2月份刚发布的 智谱 GLM 5 绝对是国内编码赛道的顶流,综合效果吊打一众选手。如果前端小伙伴需要多模态能力,比如看图写界面,可以搭配 Kimi 2.5 使用。
如果追求性价比或者对速度有要求的同学,可以选择 minimax m2.5(最新已经发布了 m2.7,性能有提升,但似乎还是不如 GLM 5)。它家的 Coding Plan 定价比较亲民,推理速度也非常快,还有 High Speed 版本。
当然模型这块变化其实非常快,基本都是一代版本一代神,大家可以平时多关注一下人工智能领域的最新动态。
AI Coding项目的技术选型
如果是新开一个 AI Coding 项目,技术栈的选型除了要考虑业务需要、团队的技术背景外,可能还要考虑 AI 更擅长什么。
目前的 LLM 训练语料主要来自互联网上的公开数据和大量开源代码。所以 AI 对一门编程语言或一个技术栈的熟悉程度,基本和这门语言、技术栈的流行程度、开源库数量、生态成熟度成正比。
目前来看,模型写代码,Python 肯定是最好的,其次是 JavaScript/TypeScript,然后是 Java、Go 这类业务开发语言。所以选型时,尽量优先选择流行度高的框架和语言,能让 AI 的发挥空间大不少。
工具搭配
我一般会选择用一款 CLI 工具(比如 Claude Code 或 OpenCode),搭配一种图形化 IDE(比如 VS Code)来进行开发。
虽然目前大部分 AI IDE 都有所谓的 BUILDER 模式,但我还是更倾向于把 CLI 工具作为与 AI 配合编程的主力。它足够轻量,占用资源少,可以多开,多个项目并行工作,甚至一个项目里也能并行做多个任务。另外 CLI 工具的界面简单,信息清晰,很容易跟踪和审查 AI 的任务思路与解决方案,可以在它出现方向性错误时随时打断、纠正。而在 IDE 界面上,无关信息太多,反而不利于专注地和 AI 交互。
不过图形化工具还是有用的。AI 写的代码最终还是需要人工审核,这时候用图形化工具更直观,一些文件操作、Git 操作也是图形化界面更好用。所以两者最好搭配起来,各自用在适合的场景里。
Bash is All You Need
这方面很多人会忽略。工具装上了就直接开始写代码,结果发现 AI 调用工具老是出错。装好AI编程工具只是第一步,我们还需要给工具准备一套合适的环境,其中最重要的就是 Bash。
目前的 CLI 工具,最核心的一些操作,比如关键字查找、文件检索等,都大量依赖 Bash 中的关键命令,比如 glob 或 grep。另外调试 API 之类的,也需要 curl、jq 这些成熟的工具。Bash 生态里有大量这样的工具,可以照顾到 AI Coding 的方方面面,不需要再去一个一个造轮子。
所以 Claude Code 核心工程师 Thariq Shihipar 才会说:“Bash is All You Need。”
那 Windows 的同学怎么办呢?最佳方案就是 WSL2,轻量又高效,把所有的开发环境都装到 WSL 里面就行。我测试过,在 WSL 中 OpenCode 调用工具的成功率明显高于在 PowerShell 下运行,而且 PowerShell 下还经常会出现一些莫名其妙的 Bug。
制定项目“宪法”
大部分工具都会要求在项目根目录中保存一份项目规范说明文件,不同工具有不同的名字,比如 CLAUDE.md 或 AGENTS.md。这个文档可以看作是当前项目中 AI Coding 的最高指导规范。
那么我们应该怎么写这个文档呢?当然现在的工具基本都有一键生成的指令,比如 /init,但光靠自动生成的文档,效果显然没那么好。我的建议是:想象一下你们团队招了一个新人,是一个资深工程师,技术上没问题,但对你当前的业务背景和技术架构一无所知。那么为了让他能上手干活,你会给他培训什么内容?这些东西大概率就应该放到 AGENTS.md 里。
但要注意,一些看起来重要、却可以在需要时再查询的东西,就不要全塞进一个文档里了。我们可以借鉴现在比较火的 Skill 设计哲学——渐进式披露。像 API 文档、数据库 schema 这些内容很重要,但非常庞杂,可以把它们放到独立文档甚至网络上,只在 AGENTS.md 里引用这些信息的位置、说明查询方式就行了。这样 AI 在需要时自然会去查询,而不是一开始就把上下文占满,影响任务执行的效率。
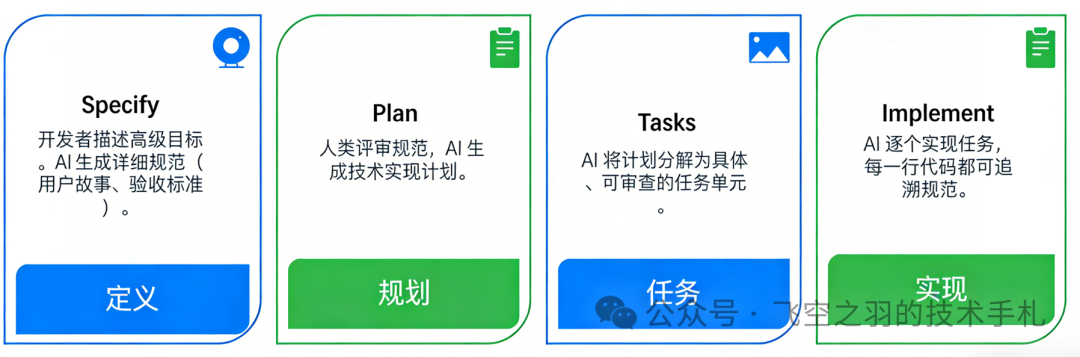
Vibe Coding VS Spec Driven
Vibe Coding(氛围编程)和 Spec Driven(规格驱动开发)是当前两种非常流行的开发方式。我用一张表来展示它们之间的差异:
| 项目 |
Vibe Coding |
Spec Driven |
| 核心思想 |
边想边写,对话式快速迭代,想到哪写到哪 |
文档优先,标准先行,先定义所有规则,再交给 AI 执行 |
| 主要优势 |
灵活度高,上手门槛低,适合探索性开发 |
全程可控可追溯,代码规范度高,Bug 率低,长期维护成本极低 |
| 主要缺点 |
极易跑偏,代码质量不可控,多次迭代后逻辑容易混乱,长期维护成本极高 |
前期需要投入时间编写规范文档,灵活度相对较低,不适合频繁变更的探索性项目 |
| 适用场景 |
小型个人项目、快速原型验证、临时 Bug 修复、简单脚本编写 |
企业级项目、团队协作、长期维护的生产级项目、核心业务功能开发 |
目前绝大多数开发者用的都是 Vibe Coding,上来就一两句话的需求丢给 AI,让它直接写代码,边写边改,最终很容易陷入“AI 写的代码完全不符合业务逻辑,改的时间比自己写还长”的困境。
对于企业级的长期项目、团队协作场景,我强烈推荐使用 Spec Driven 开发范式,这是目前解决 AI 代码失控、保证交付质量的最优解。市面上也有不少 Spec Driven 的工具,比如 OpenSpec 和 Speckit。至于怎么做好 Spec Driven,这是一个非常复杂的话题,下次可以单独来讲,这里先略过了。
管理上下文
我们都知道模型的上下文是有限的,目前主流模型一般在 200k 左右。看起来很长,但项目的长期记忆、各种工具调用的结果、对话记录都要塞进去,其实很容易占满。而且上下文超过一定程度后,一是 AI 处理速度明显下降,二是因为 LLM 的注意力机制,部分关键信息可能被遗忘,导致任务成功率下降。
所以我们需要主动控制上下文大小,尽可能精简上下文,比如控制 AGENTS.md 的大小等,这些前面已经提到过。
另外,很多同学习惯在一个对话上下文里不断下达任务,让 AI 持续工作,这个习惯不太好。如果任务之间没有太多关联性,最好新开一个会话来完成新任务,而不是在旧会话里继续往下聊,否则旧任务的信息和数据反而会干扰 LLM 的判断。即使任务之间有关联,在完成关键节点后,也应该用编程工具自带的压缩指令,主动总结、压缩上下文,清除冗余的工具调用等无效信息,让大模型始终保持在高效工作的状态。
出错了怎么办
人都会犯错,AI助手犯错也是非常正常的事情,如果AI 没有按需求完成任务,先别急着骂模型傻,可以按照下面的步骤来排查:
1. 判断问题的根源
究竟是模型的智能不足,还是我们给出的信息不足以完成这个任务。
比如让 AI 写一个排序算法的代码,这个任务一般不需要外部信息,靠模型内部的“常识”就能解决,如果还是失败,那很可能是模型自身的问题。反之,如果让 AI 对接一个外部系统,但连外部系统的 API 都没提供,那也别指望它能正确完成——这属于上下文信息量不足。
2. 如果是模型智能问题
最直接的方式当然是换模型,用更强、更大的上位模型来替代。但有时客观条件限制,可能没得选,那就只能人工帮它拆解任务,将一个复杂目标拆成多个相对简单的子任务,并给出明确的路径指引。这样能明显提升 AI 的成功率,有点像你刚进公司时,组长带你完成困难任务的过程。
3. 如果是上下文信息缺失
补充关键信息就行,比如 API 文档在哪里、怎么查。这里有个小技巧:交代完任务后,先让 AI 确认一下,当前信息是否足够完成任务,还有什么需要补充的,而不是布置完任务就立刻让它开始干。
4. 如果一个错误重复出现好几次
说明我们的 AGENTS.md 可能存在问题,缺少一些关键的约束或指引。需要把当前犯错的场景补充进去。如果已经有了明确说明,AI 还是会犯错,可以尝试调整说明文本的格式、位置等,这属于提示词工程的范畴了,不同模型对提示词的敏感程度不一样,只能多试几次。
5. 总结复杂问题
如果你和 AI 配合完成了一个复杂问题的排查,中途你给了大量指导和纠正,那么任务完成后,最好让 AI 把排查过程整理成文档。下次遇到类似问题,就可以直接参考之前的排查过程,不必每次都重复一遍痛苦的指导流程。这和我们解决完难题后通常写文章总结的道理是一样的。
总的来说,遇到问题是难免的,但要尽可能坚持让 AI 自己处理、解决问题,我们只需要从中给一些提示和指导就行,而不是遇到一点问题就觉得 AI 不行、浪费时间,直接人类接管。
和 AI 结对写代码是需要磨合的,你也要多练习,才能知道 AI 的能力边界在哪里,怎么跟 AI 沟通、交代任务的成功率更高——我们也要学会成为一个 Leader,而不是手下人一出错就亲力亲为。
当然,最终的代码质量底线还是需要人类来把控。这一步主要是在代码提交时,用 Git 工具检查 AI 修改的代码范围和内容是否符合要求。我通常会先让 AI 自己审查一遍(很多开发工具都有内置命令支持,比如 OpenCode 的 /review,也可以根据自己的情况写提示词封装一个命令),然后再自己审核和测试,这样出错的概率会更小。一个清晰且经过验证的技术架构,能为 AI 的代码生成提供坚实的依据和边界。
总结
回过头来看,AI Coding 带给我们的,其实不是“程序员被替代”的焦虑,而是一次角色升级的机会。
你不再需要把大量精力消耗在机械的编码和调试上,而是可以把更多时间放在真正有创造性的工作里:架构设计、需求拆解、规范制定、质量把控。这些才是技术工作中更有价值的部分。
 发表于 2026-4-11 05:35:14
|
查看: 180|
回复: 0
发表于 2026-4-11 05:35:14
|
查看: 180|
回复: 0
