本文转译自 Jacob Jackson 的博文,原文链接:https://byteofdev.com/posts/making-postgres-slow/ 。
【编者按】在所有人都追求极致性能的今天,有人反其道而行,以近乎“行为艺术”的方式探索了 PostgreSQL 的极限另一面 —— 仅通过调整配置,就让其性能断崖式下跌。
大家总是在琢磨如何让 PostgreSQL 运行得更快。但有没有人想过,如果我们想让它变得极致的慢,该怎么做呢?我知道,大部分人研究提速是为了工作。而我目前正好失业了,于是脑洞大开:原本在写正经的调优指南,不如试试搞个“反向优化”版本,看看能把 PostgreSQL 折腾得多慢。
当然,我不能让事情太简单。这不是降低CPU频率或删除索引那种粗暴操作,所有改动都必须基于 postgresql.conf 文件中的参数调整。同时,数据库还得能在“合理”时间内完成至少一个事务 —— 直接让它彻底卡死就太没技术含量了。这件事其实比看起来更难,因为 PostgreSQL 本身的设计就在极力避免用户做出这种“愚蠢”的决定。
为了量化性能变化,我使用了 Benchbase 实现的 TPC-C 基准测试,配置为 128 个仓库和 100 个连接。数据库使用 PostgreSQL 19devel,系统为 Linux 6.15.6,硬件是 Ryzen 7950x、32GB 内存和 2TB SSD。每轮测试持续 120 秒,包含一次预热和一次数据收集。
在基准配置下(仅做了如调高 shared_buffers 等少数常规优化),PostgreSQL 的 TPS(每秒事务数)达到了不错的 7082。
那么,表演开始了。
1. 首先,废掉缓存
PostgreSQL 高效的原因之一在于其缓存机制。为了迫使所有查询都走最慢的磁盘读取路径,我的目标是把缓存弄到最小。理论上,这可以通过 shared_buffers 参数控制,但它不能设为 0,因为 PostgreSQL 自身运行也需要一些页面缓冲。不过,我可以把它设得非常小。
首先,我将基准测试中的 shared_buffers 从 10GB 降到 8MB:
shared_buffers = 8MB
在这个设置下,TPS 骤降至 1052,只有初始速度的 1/7。
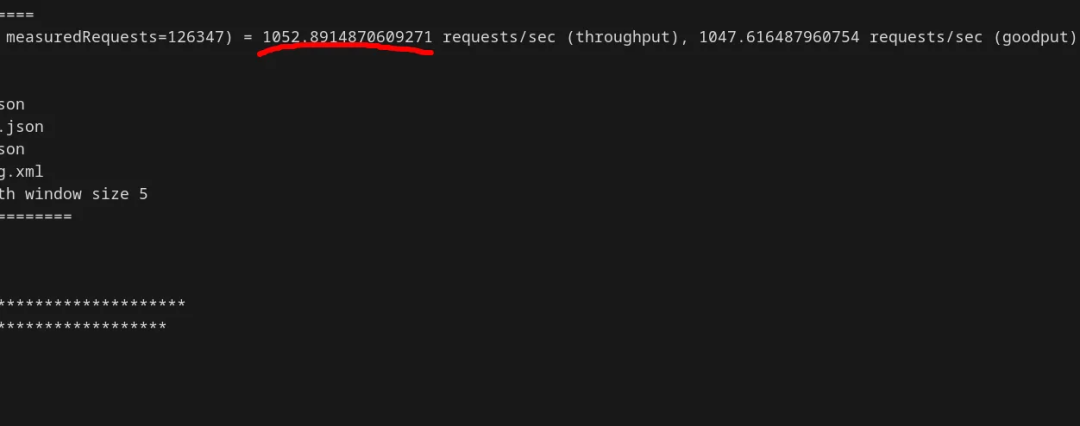
缓冲区缩小后,PostgreSQL 在内存中能保留的页面变少,缓存命中率从 99.90% 暴跌至 70.52%,导致读取系统调用的数量激增了近 300 倍。
但70%的命中率还是太高。我尝试进一步缩小到 128kB,结果直接报错:
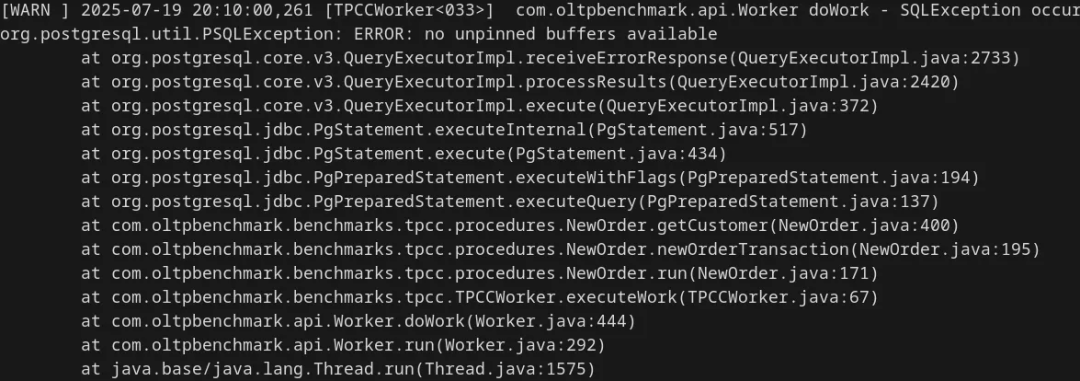
显然,128kB 的共享缓冲区最多只能存约16个数据库页面,而 PostgreSQL 需要同时访问的页面远超此数。几番尝试后,我发现最小可行值大约是 2MB:
shared_buffers = 2MB
此时,TPS 已经降到了 500 以下。
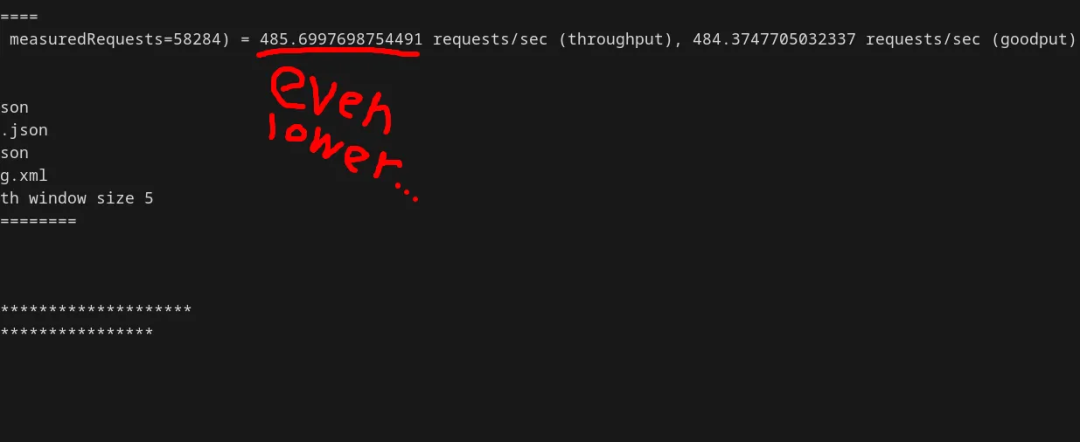
2. 让后台进程“忙”起来
PostgreSQL 除了处理事务,还会运行一些后台任务,比如清理存储碎片的 autovacuum。正常情况下,它只会在发生足够多的数据变更后运行,以避免影响性能。但我可以通过调整参数,让它变得异常“勤快”:
autovacuum_vacuum_insert_threshold = 1 # 只要有一次插入就能触发vacuum
autovacuum_vacuum_threshold = 0 # 触发vacuum所需的最增/删/改数
autovacuum_vacuum_scale_factor = 0 # 计算阈值时不考虑表大小比例
autovacuum_vacuum_max_threshold = 1 # 触发vacuum所需的最大变更数
autovacuum_naptime = 1 # autovacuum间的最小延迟(秒),不能低于1
vacuum_cost_limit = 10000 # 我不想vacuum暂停,所以把这个成本限制设到最大
vacuum_cost_page_dirty = 0
vacuum_cost_page_hit = 0
vacuum_cost_page_miss = 0 # 这些参数都是为了最小化vacuum操作的成本计算
同理,调整负责收集统计信息的自动分析器(autovacuum analyzer):
autovacuum_analyze_threshold = 0
autovacuum_analyze_scale_factor = 0
然后,再想办法让 vacuum 过程本身也慢下来:
maintenance_work_mem = 128kB # 分配给vacuum进程的内存
log_autovacuum_min_duration = 0 # 记录所有autovacuum操作
logging_collector = on
log_destination = stderr,jsonlog
这样一来,TPS 降到了 293,不到初始值的 1/20。
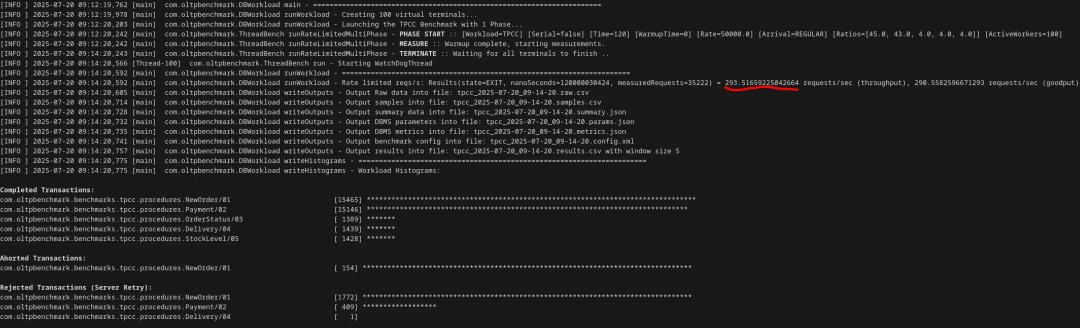
查看日志确认,PostgreSQL 几乎每秒都在对热点表执行无用的 autovacuum 和 analyze,同时缓存命中率极低,不断进行磁盘读取。但我觉得……还不够慢。
3. 折磨 WAL(预写日志)
在将更改提交到实际数据文件前,PostgreSQL 会先写入 WAL。这个模块可配置性很强,正好为我所用。首先,阻止它进行高效的批量写入:
wal_writer_flush_after = 0 # 产生的WAL立即刷新,不缓冲
wal_writer_delay = 1 # 刷新间的最小延迟
然后,让检查点(checkpoint)尽可能频繁地发生:
min_wal_size = 32MB # 检查点后的最小WAL大小(设到最小以频繁检查点)
max_wal_size = 32MB # 最大WAL大小(同样最小化)
checkpoint_timeout = 30 # 检查点间的最大时间间隔(秒,已是最小值)
checkpoint_flush_after = 1 # 每写入8kB就刷新到磁盘
再最大化 WAL 的写入开销:
wal_sync_method = open_datasync # 应该是最慢的磁盘刷新方式
wal_level = logical # 为逻辑复制输出额外信息,增加负担
wal_log_hints = on # 强制WAL写出完整的修改页
summarize_wal = on # 为备份开启另一个额外进程
track_wal_io_timing = on # 收集更多(无用的)计时信息
checkpoint_completion_target = 0 # 完全不平滑检查点的I/O负载
结果:TPS 降至 98,低于初始值的 1/70。
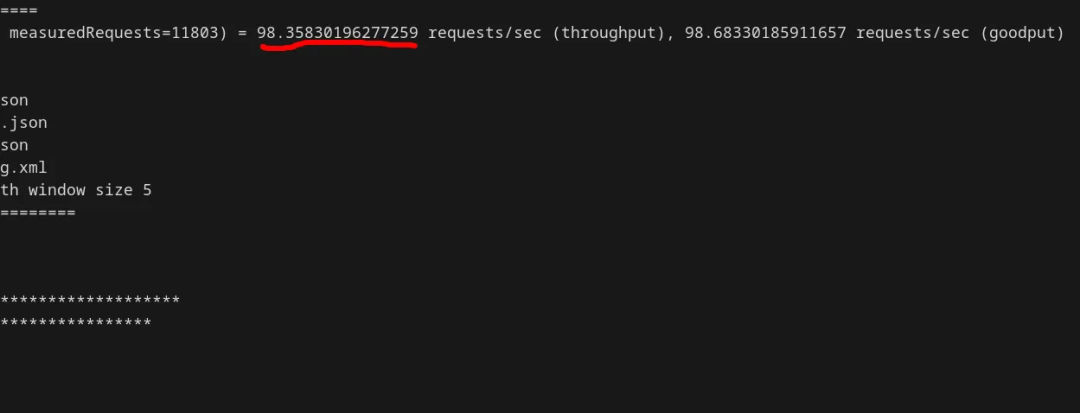
日志显示检查点频繁到不正常(间隔仅487毫秒),但这对我的目标来说是件“好事”。
4. 从“思想”上禁用索引
我答应过不动索引,但可以让查询计划器“讨厌”索引。PostgreSQL 通过估算随机访问(索引扫描)和顺序访问(全表扫描)的成本来选择执行计划。只需把随机访问的成本设得天高,优化器自然会放弃索引:
random_page_cost = 1e300 # 设置访问一个随机页面的成本
cpu_index_tuple_cost = 1e300 # 设置处理一个索引元组的成本
为了避免全表扫描出错,我把 shared_buffers 调回 8MB,但这无助于提升性能。
至此,TPS 暴跌至 0.87,每秒事务数不到1,比默认配置慢了7000多倍 —— 而这一切仅通过修改配置文件达成。
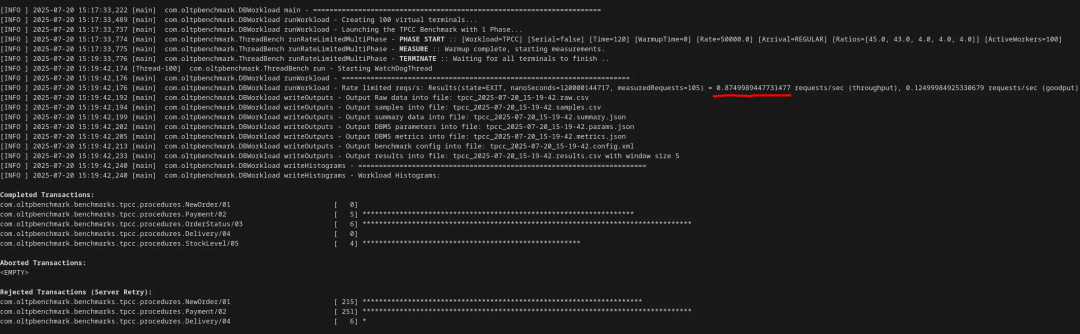
5. 最后的绝杀:强制 I/O 单线程
虽然不能让 PostgreSQL 完全单线程运行,但从版本 18 开始,新增的 io_method 参数可以控制 I/O 方式。我可以强制所有 I/O 通过单个工作线程处理:
io_method = worker
io_workers = 1
最终,TPS 跌至 0.016,性能下降超过 42000 倍!如果排除因死锁未完成的事务,情况更“惨”:100个连接在120秒内,仅成功完成了11个事务。
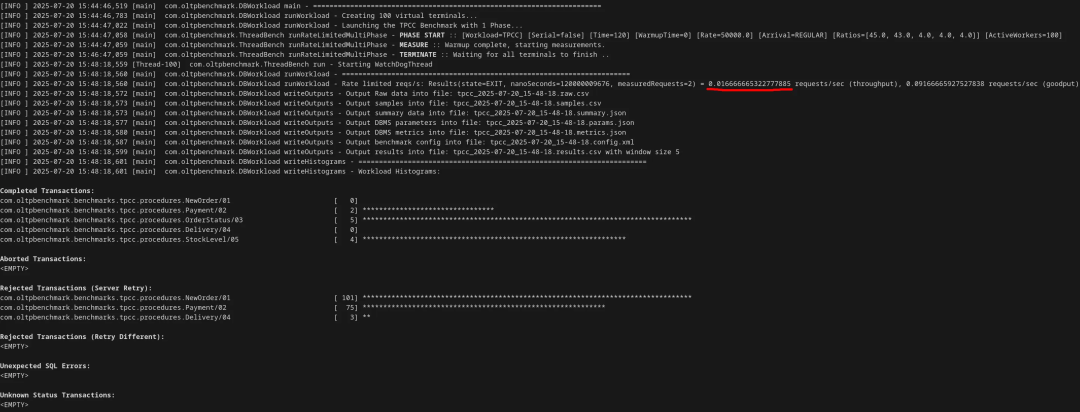
6. 总结与配置清单
经过数小时“努力”,调整了32个参数后,我成功“优化”出了一个极其缓慢的 PostgreSQL 实例。以下是所有修改过的非默认参数清单:
shared_buffers = 8MB
autovacuum_vacuum_insert_threshold = 1
autovacuum_vacuum_threshold = 0
autovacuum_vacuum_scale_factor = 0
autovacuum_vacuum_max_threshold = 1
autovacuum_naptime = 1
vacuum_cost_limit = 10000
vacuum_cost_page_dirty = 0
vacuum_cost_page_hit = 0
vacuum_cost_page_miss = 0
autovacuum_analyze_threshold = 0
autovacuum_analyze_scale_factor = 0
maintenance_work_mem = 128kB
log_autovacuum_min_duration = 0
logging_collector = on
log_destination = stderr,jsonlog
wal_writer_flush_after = 0
wal_writer_delay = 1
min_wal_size = 32MB
max_wal_size = 32MB
checkpoint_timeout = 30
checkpoint_flush_after = 1
wal_sync_method = open_datasync
wal_level = logical
wal_log_hints = on
summarize_wal = on
track_wal_io_timing = on
checkpoint_completion_target = 0
random_page_cost = 1e300
cpu_index_tuple_cost = 1e300
io_method = worker
io_workers = 1
你可以使用 BenchBase 的 PostgreSQL 版本,配合 TPC-C 工作负载(128仓库,100连接,120秒测试时长)来复现这个结果。甚至,你还可以尝试探索比我更“狠”的参数组合。
后记
这篇文章在海外社区引发了一些有趣的讨论。有开发者调侃:“所以,我们可以先用这种配置启动一个新实例,再换成默认配置,然后声称我们把性能提升了42000倍?” 也有人说:“你不需要等到失业才这么做,我在工作中经常这样(无意中)。”
这种反向探索虽然看似无厘头,却从另一个角度加深了我们对数据库各个模块协同工作方式的理解。知其所以然,方能知其所以不然。如果你对数据库调优、基准测试或其它后端技术有更多兴趣,欢迎来 云栈社区 交流讨论。
 发表于 2026-4-11 19:25:24
|
查看: 152|
回复: 0
发表于 2026-4-11 19:25:24
|
查看: 152|
回复: 0
