对于在本地部署过AI模型的开发者来说,Ollama 可能并不陌生。它原本是一个让你在本地电脑轻松运行各类大模型的“AI运行平台”,通常只需一行命令就能完成本地化部署。
而在今年(2026年)3月中旬,Ollama 与 NVIDIA 云提供商合作,推出了托管开放模型的云服务。这项服务承诺不记录日志、不将用户数据用于训练,也没有制定任何数据保留政策,旨在提供一种便捷、保护隐私的云端 人工智能 模型调用方式。
官方将其免费计划描述为“轻量使用”,适合聊天、模型体验、轻量级的代码生成和助手场景。它的计费方式并非固定的 token 数或请求次数,而是按实际消耗的云资源计量,主要取决于所选模型的大小以及请求的持续时间。
免费计划的使用限制
免费用户在使用时会受到以下限制:
- 并发限制:只能同时运行 1 个云模型。
- 额度限制:采用“5小时会话限额”加“7天周限额”的双重机制。
- 超限响应:超过速率或额度限制时,API 会返回
HTTP 429 Too Many Requests 状态码。
由于官方未明确公布具体的 token 限额,有用户通过实测进行了估算,推算的免费额度大致如下:
- 每 5 小时会话限额:约 50 万 token
- 每 7 天周限额:约 100 万 token
如何开始使用
操作流程非常简单:
- 访问官网注册:访问 ollama.com ,使用任意邮箱即可注册。也可以直接使用 Google 或 GitHub 账号授权登录。
- 创建 API Key:登录后,访问
ollama.com/settings/keys 页面,添加并获取你的 API 密钥。
- 查看可用模型:目前支持的模型包括 Gemma4、Qwen3.5、Kimi K2.5、GLM-5、GPT-OSS、MiniMax M2.7 等。访问
ollama.com/search?c=cloud 可以查看所有可用的云端模型。
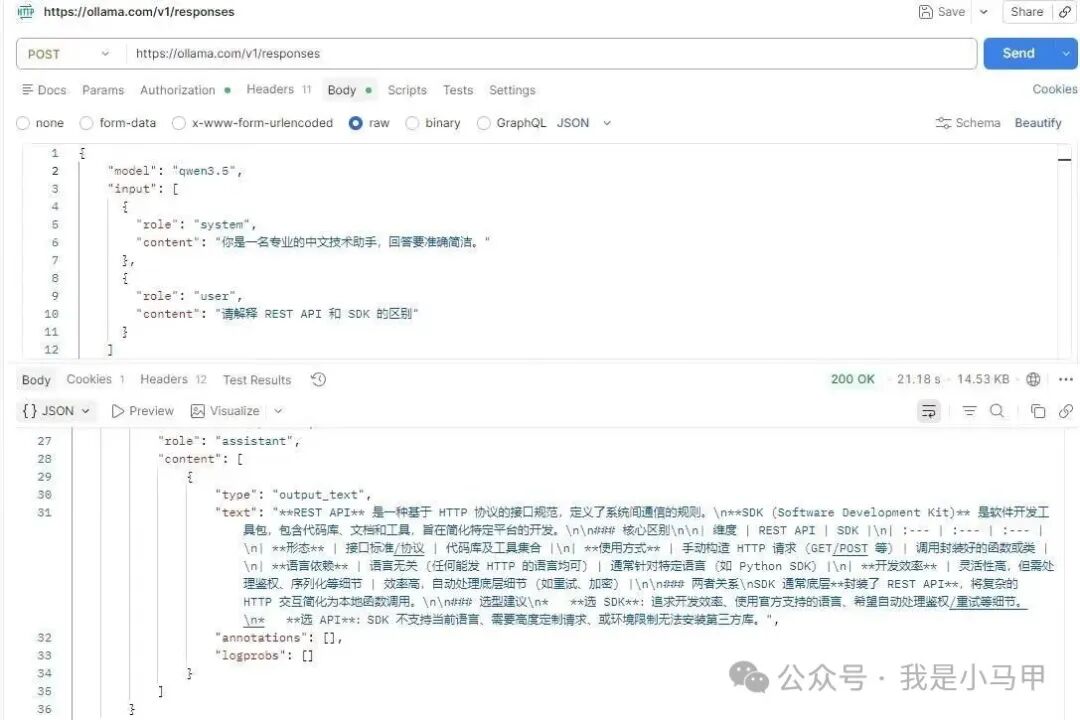
- API 端点:服务提供与 OpenAI 兼容的 API,地址为
https://ollama.com/v1。
- 在线测试:你可以在官网提供的 Playground 界面直接测试 API 的调用效果。
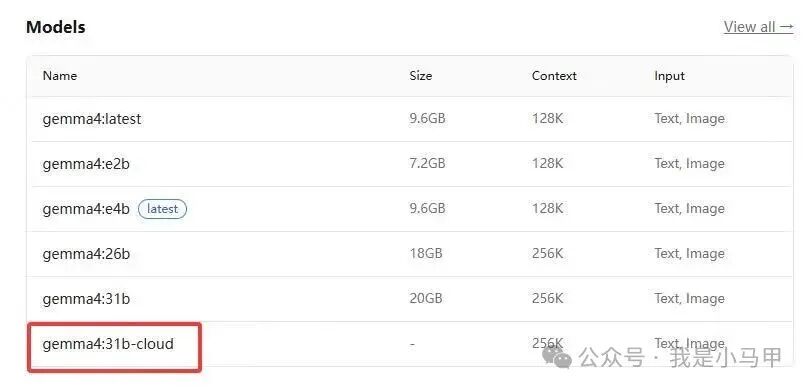
选择模型时的注意事项
调用 API 时指定模型名称需要特别注意:必须使用模型名称中带有 -cloud 后缀的版本,这些才是专门用于云端托管的模型。在模型列表中,这类模型会被明确标识出来。
总结与评价
- 注册便捷:注册过程非常简单,无需验证信用卡或手机号,仅需一个有效邮箱,门槛极低。
- 额度限制:免费额度对于重度或生产级使用来说比较有限,更适合体验和轻量级测试。
- 访问速度:目前从国内直接请求 API,响应速度尚可,网络延迟在可接受范围内。
- 变通方案:如果单一账号的 token 额度不够用,可以考虑多注册几个账号交替使用,以应对非高频的使用场景。
总的来说,Ollama 云版为开发者和爱好者提供了一个极其便捷的途径来体验和调用最新的开源大模型,其 云原生 的服务形式免去了本地部署的繁琐。虽然免费额度有限,但对于学习、原型验证和轻量级应用来说,已经是一个相当有吸引力的选择。如果你想了解更多关于 AI 模型应用和云端开发的实践,可以关注 云栈社区 上的相关讨论。 |  发表于 2026-4-13 03:57:03
|
查看: 610|
回复: 0
发表于 2026-4-13 03:57:03
|
查看: 610|
回复: 0
