在众多编程语言中,枚举(Enum)并非稀有之物,但 Rust 却将其提升到了一个全新的高度。它不仅是命名常量的集合,更成为构建安全、高效程序的核心基石,从消除“魔法数字”的弊端,到修复著名的“十亿美元错误”,其背后蕴含着精巧的设计与零成本的内存黑科技。接下来,就让我们一起深入剖析 Rust 枚举的强大之处。
从“魔法数字”到 C 语言枚举的局限
在编程的早期阶段,开发者常直接使用整数来表示程序状态。例如,一个网络程序可能用 0 表示断开,1 表示连接,2 表示重连中。
这种直接出现在代码里的神秘“数字”,我们称之为魔数(Magic Numbers)。
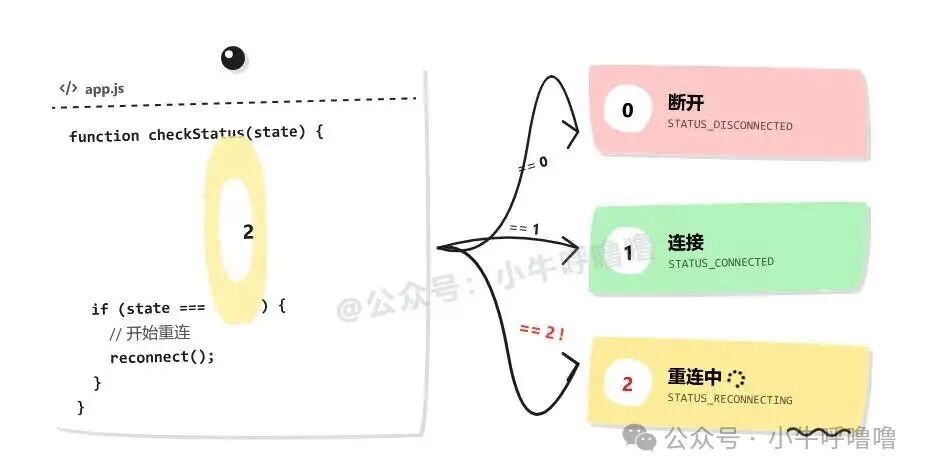
时间一长,连开发者自己都可能忘记 2 究竟代表重连还是失败。为了解决魔数问题,像 C语言 这样的语言引入了枚举(enum),为整数赋予可读性强的名字。
// 定义一个名为 WebState 的枚举,代表网络状态
enum WebState {
Disconnected, // 默认底层是 0
Connected, // 默认底层是 1
Connecting, // 默认底层是 2
}
// 程序入口函数
fn main() {
let state = WebState::Disconnected; // 此时 state 的意义一目了然,不再是冰冷的数字 0
}
C 语言的枚举本质上是一组具名的整型常量,它解决了“状态命名”的问题。但现实世界往往更复杂。例如,状态变为 Connected 时,我们可能还需要知道连接到了哪个 IP 地址。然而在 C 语言中,枚举只能是“标签”,不能包含“数据”。
为了解决这个问题,开发者不得不手动采用 “enum(纯整数常量)+ union(联合体)” 的模式,并自己添加一个 tag 字段来记录当前类型。
typedef enum {
TYPE_INT,
TYPE_FLOAT,
TYPE_STRING
} ValueType;
typedef struct {
ValueType tag; // 手动标签
union {
int i;
float f;
char* s;
} data;
} Value;
在这个结构中,union 只负责分配一块足以容纳最大成员的内存,它本身不知道当前存储的是 int 还是 char*。记忆类型的工作完全交给了外部的 tag 字段。
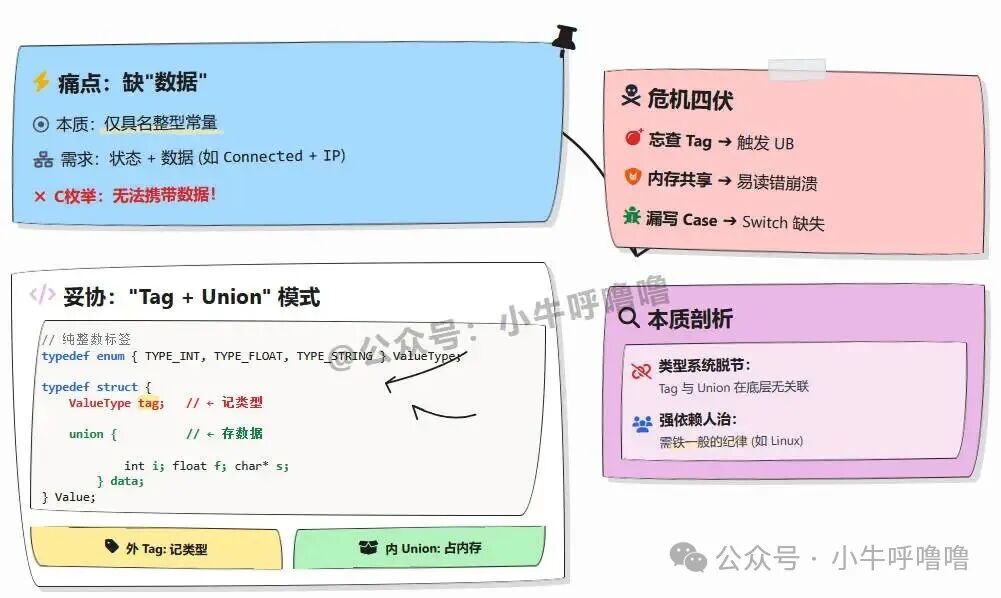
这种“手动挡”操作极易出错:忘记检查 tag 会导致未定义行为;union 内存共享机制可能引发不安全访问;此外,在 switch 语句中漏掉某个 case 也是常见问题。最核心的症结在于,C 语言的类型系统并没有在底层关联 tag 和 union,这种模式在大型项目中极其脆弱,严重依赖团队的高度自律(如 Linux 内核中的大量使用)。
Rust 枚举:代数数据类型(ADT)的威力
在 Rust 中,enum 是一种看似简单却极其强大灵活的类型定义方式。它允许我们列举一个类型所有可能的值,即该类型的实例可以是多种可能值中的某一个。
基础枚举形式
最简单的 Rust 枚举类似于 C 语言的命名常量,用于表示一组固定的可能状态:
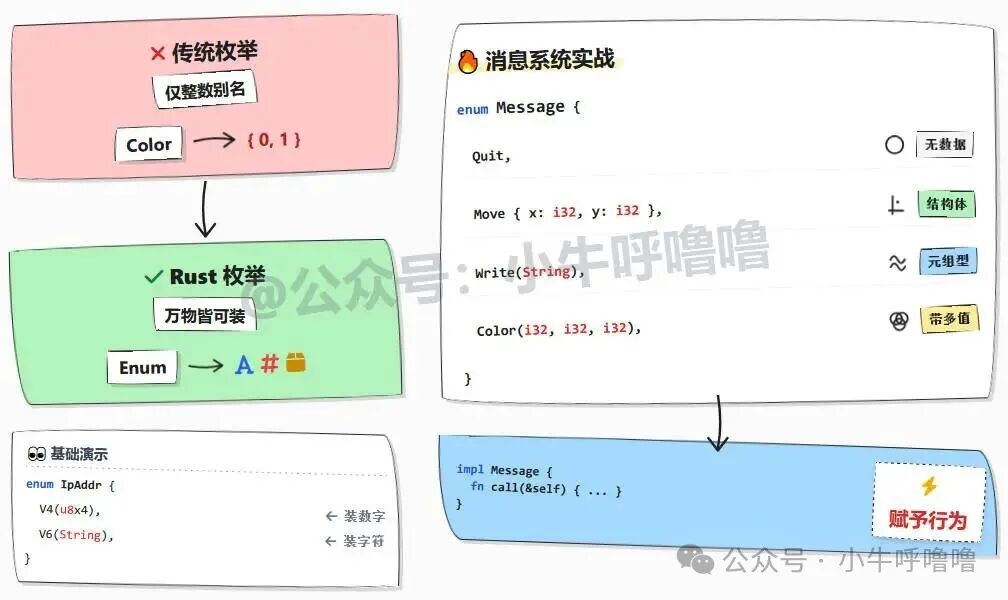
enum IpAddrKind {
V4, // 变体 V4,表示 IPv4
V6, // 变体 V6,表示 IPv6
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(four);
route(six);
}
fn route(ip_kind: IpAddrKind) {
println!("路由 IP 地址...");
}
携带数据的枚举:颠覆传统
Rust 枚举彻底颠覆了传统!它不仅是整数值的别名,更是具有真正数据承载能力的代数数据类型(ADT)。这个概念早在 1970 年代末由 ML 语言提出,而 Rust 则将其引入系统编程领域,并通过精细的内存布局控制解决了性能瓶颈。
让我们看一个更强大的例子:
// 枚举可以像 struct 一样携带数据,每个变体的数据类型、数量完全自由
enum IpAddr {
V4(u8, u8, u8, u8), // IPv4 携带 4 个 u8(字节)
V6(String), // IPv6 携带 String(字符串)
}
fn main() {
let home = IpAddr::V4(127, 0, 0, 1); // V4 变体,传入 4 个数字
let loopback = IpAddr::V6(String::from("::1")); // V6 变体,传入字符串
}
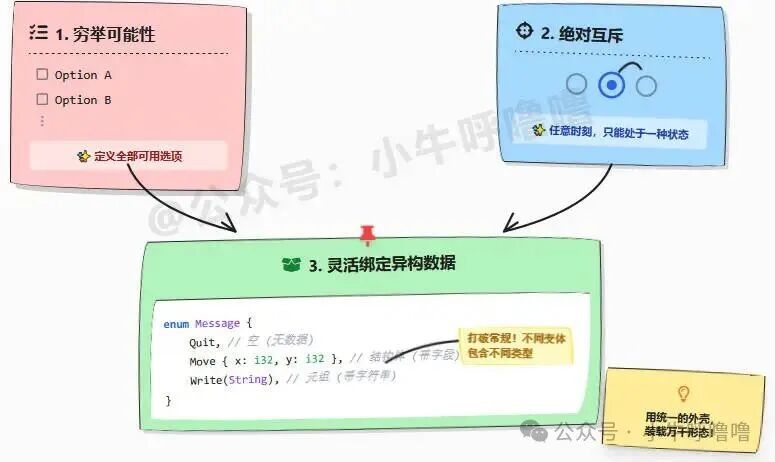
// 更复杂的 Message 枚举(典型场景:事件/消息系统)
enum Message {
Quit, // 无数据变体(unit-like)
Move { x: i32, y: i32 }, // 结构体风格(named fields)
Write(String), // 元组风格(tuple-like)
ChangeColor(i32, i32, i32), // 携带 3 个 i32
}
impl Message { // 可以为枚举实现方法,就像 struct 一样
fn call(&self) { // &self 借用当前实例
// 方法体可以 match self 来处理不同变体
println!("调用消息方法...");
}
}
单一类型 Message 竟能表达四种完全不同的“形态”,每个变体直接携带任意类型的数据,这种设计无疑极其优雅!
模式匹配(Match):安全的解构与穷尽检查
创建了携带数据的枚举实例后,如何安全地取出内部数据(解包)呢?如果像某些语言那样提供类似 my_ip.get_v4() 的方法,那么当实例是 V6 时程序就会崩溃。Rust 绝不允许这种不安全的情况发生,因此引入了强大的 match 控制流。
fn main() {
let home = IpAddr::V4(127, 0, 0, 1);
// match 表达式:把值“放入”模式,编译器检查是否覆盖所有变体
let addr_str = match home { // match 返回值可以赋值
// 每个分支叫 arm,模式 => 表达式
IpAddr::V4(a, b, c, d) => { // 模式绑定变量 a,b,c,d
format!("{}.{}.{}.{}", a, b, c, d) // 返回 String
}
IpAddr::V6(s) => s, // 直接返回绑定的 String
}; // 所有变体必须覆盖,否则编译错误!
println!("地址是:{}", addr_str);
}
match 表达式会进行穷尽性检查,编译器强制你必须处理枚举的所有可能情况,否则不予编译。这从根本上消灭了“漏处理情况”的 Bug!如果后续为枚举添加新的变体,所有未更新的 match 代码都会在编译时报错,提醒开发者。
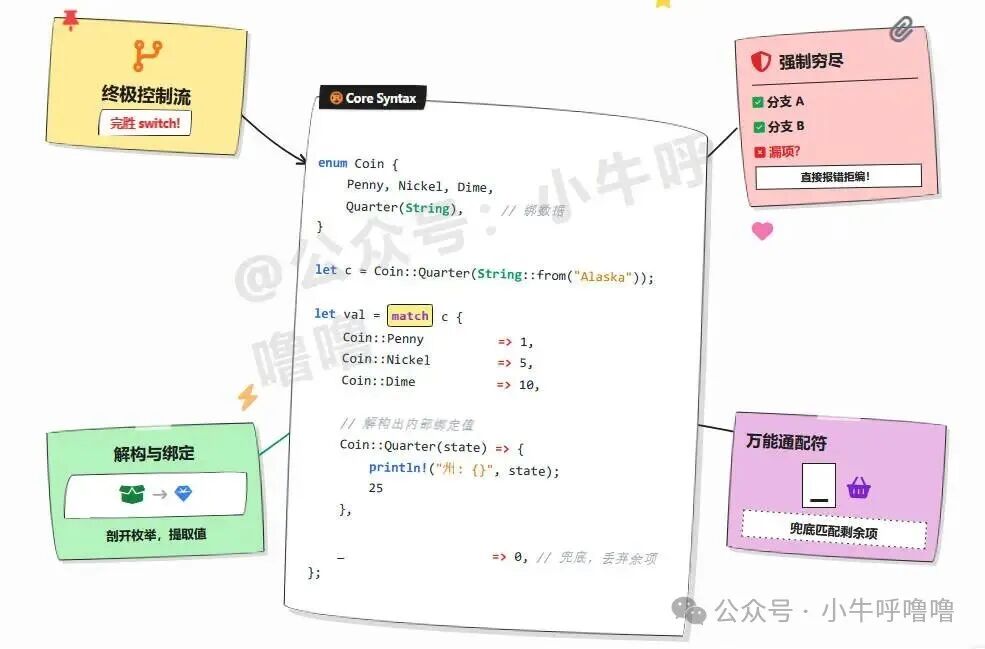
这种强大功能是零运行时开销的。match 将所有复杂性(模式匹配、类型解构、穷尽性分析)都转移到了编译阶段完成,最终生成的机器指令(如整数比较、指针偏移和跳转)与你手写最底层的 C 语言 switch 或 if-else 汇编代码等效,没有任何额外的运行时元数据查询或动态内存分配。这就是 Rust 引以为傲的零成本抽象。
标准库核心枚举:Option 与 Result
终结“十亿美元错误”的 Option<T>
1965 年,Tony Hoare 发明了 Null 引用,但他在 2009 年的 QCon 大会上公开为此道歉,称其为“十亿美元的错误”。对于 Java、C# 或 C++ 程序员而言,NullPointerException 或 Segmentation Fault 绝对是噩梦。Rust 的解决办法是在类型系统层面彻底消灭 Null,取而代之的是内置枚举 Option<T>,用于显式表示一个值“有”或“无”。
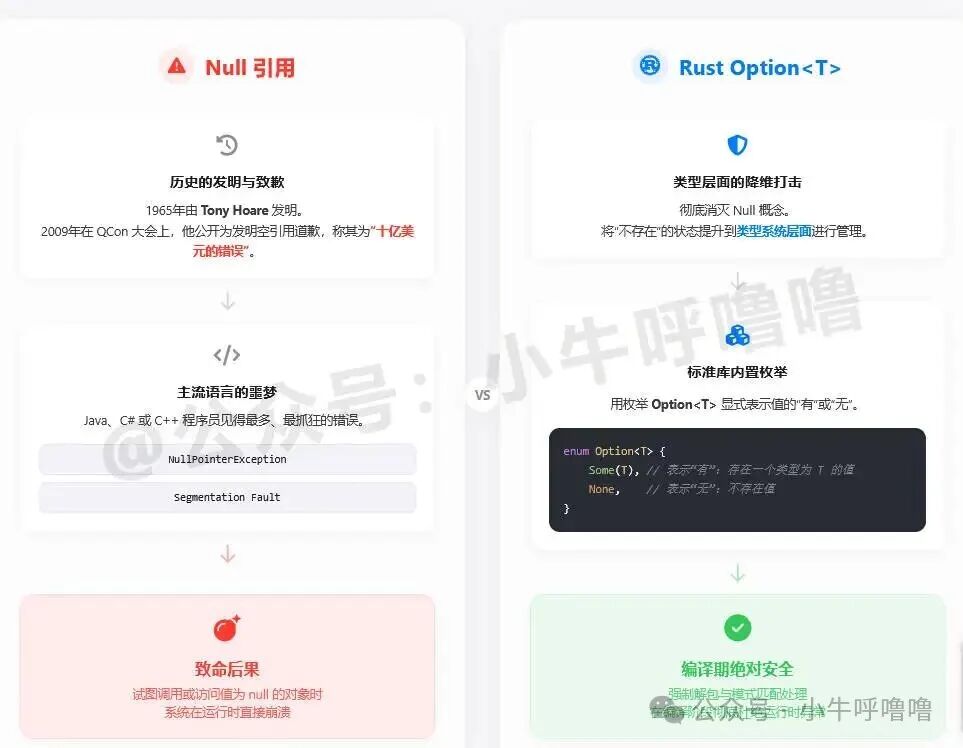
它的定义极其简洁:
pub enum Option<T> {
None, // 没有值
Some(T), // 有值,携带 T
}
Option<T> 强制你在编译时处理值不存在的可能性。看一个例子:
fn find_first_even(numbers: &[i32]) -> Option<i32> {
for &num in numbers {
if num % 2 == 0 {
return Some(num);
}
}
None
}
fn main() {
let my_nums = [1, 3, 5, 7];
let result = find_first_even(&my_nums);
// 编译器强制你必须处理 None 的情况!不能直接使用结果。
match result {
Some(even_num) => {
println!("找到了偶数: {}", even_num);
}
None => {
println!("数组里没有偶数。");
}
}
}
提供错误详情的 Result<T, E>
Option 只能表示“有无”,当操作失败时,None 无法告诉我们“为什么失败”。因此,Rust 标准库提供了专门用于错误处理的枚举 Result<T, E>。它有两个泛型参数:T 代表成功时的数据类型,E 代表失败时的错误类型。
enum Result<T, E> {
Ok(T), // 成功,携带结果
Err(E), // 失败,携带错误信息
}
让我们尝试打开一个文件:
use std::fs::File;
fn main() {
let file_result = File::open("hello.txt"); // 返回 Result<File, std::io::Error>
match file_result {
Ok(file) => {
println!("文件打开成功: {:?}", file);
}
Err(error) => {
println!("糟糕,打开文件失败了,原因是: {}", error);
}
}
}
这种方式相比 Java 的异常传播机制,其优势在于错误必须显式处理,函数签名本身就会告诉你它可能失败。在 Rust 标准库中,文件读写、网络请求、JSON解析等几乎所有可能失败的操作都返回 Result。
枚举的内存布局与零成本优化
如果你只把枚举当作语法糖,那只是看到了冰山一角。了解枚举在内存中的布局,是深入理解其性能优势的关键。
Rust 枚举的内存布局由两部分组成:
- 判别值(discriminant):标识当前是哪个变体。
- 数据载荷(payload):存储变体携带的数据。
我们来看这个枚举的内存大小:
enum MyEnum {
A, // A 不带数据
B(u8), // B 带一个 8 位整数 (1 byte)
C(u64), // C 带一个 64 位整数 (8 bytes)
}
由于 Rust 会为所有变体分配相同的内存空间,因此首先需要找到最大变体所需的内存。这里 C(u64) 需要 8 字节。同时,Rust 会用隐藏的判别值(通常需要 1 字节)来记录当前是哪个变体。最终,总大小会进行内存对齐,补齐到对齐数(这里是 8)的整数倍。
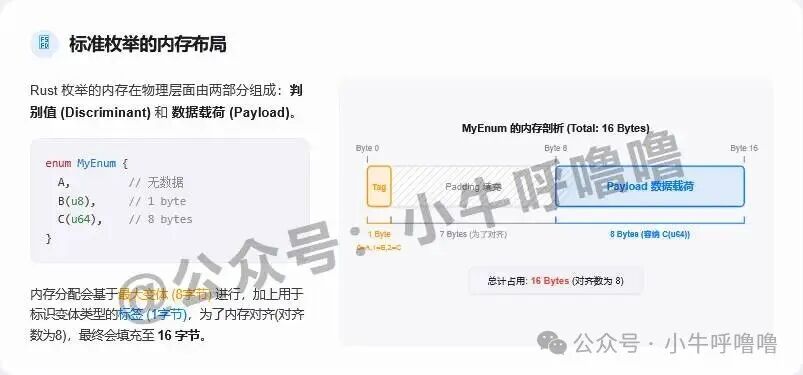
因此 MyEnum 的大小是:1(标签) + 7(填充) + 8(最大数据) = 16 字节。可以用代码验证:
use std::mem;
enum MyEnum {
A,
B(u8),
C(u64),
}
fn main() {
println!("size = {}", mem::size_of::<MyEnum>()); // 16
println!("align = {}", mem::align_of::<MyEnum>()); // 8
}
那么问题来了:所有带数据的枚举都需要这额外的 1 字节判别值吗?让我们回顾一下 Option<T>,特别是当 T 是指针时:
fn main() {
let pointer_size = std::mem::size_of::<Box<i32>>();
let option_size = std::mem::size_of::<Option<Box<i32>>>();
println!("普通指针大小: {}", pointer_size); // 8
println!("Option 指针大小: {}", option_size); // 依然是 8!!
}
令人惊讶的是,Option<Box<i32>> 的大小竟然和 Box<i32> 一样,都是 8 字节!这就是 Rust 的黑科技——空指针优化(Niche Pointer Optimization)。
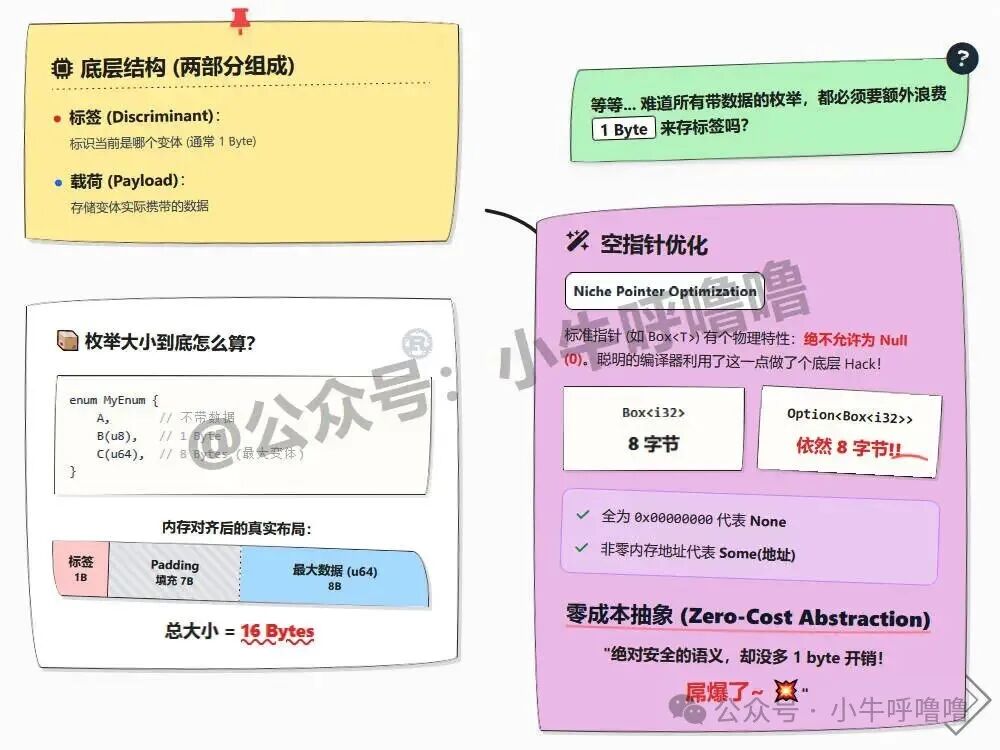
聪明的编译器知道 Box<T> 这样的指针在物理上绝不允许为 0(Null)。因此,它做了一个底层 Hack:如果这 8 个字节全为 0,它就代表 None;如果是其他非零的内存地址,它就代表 Some(地址)。 这样,我们既拥有了绝对安全的 Option 语义,又没有产生任何额外的内存开销!这就是 “零成本抽象” 的完美体现。
总结
通过本文的梳理,我们从消除魔数的 C 语言枚举出发,深入探讨了可以携带数据的 Rust 代数数据类型;为了安全提取数据,引入了强制穷尽检查的 match 模式匹配;为了彻底消灭 Null 灾难,深入应用了 Option<T>;为了进行详细的错误处理,了解了 Result<T, E>;最后,在最底层,我们见识了编译器如何利用精妙的内存布局优化,实现了零成本的安全。
记住最核心的一句话:Rust 枚举(Enum) = 零成本安全、可携带数据的、编译时穷尽检查的“代数数据类型(ADT)”。
当然,枚举的玩法远不止于此,它还可以用于实现状态机、构建抽象语法树(AST)、结合泛型等高级场景。可以说,Rust 枚举绝非简单的语法糖,它是构筑 Rust 程序安全与性能灵魂的核心要素之一。
开始动手写代码吧,Rust 编译器将会是你最坚实的后盾!如果你对这类深入原理与技术实战的内容感兴趣,欢迎在 云栈社区 与更多开发者交流探讨。
 发表于 2026-4-15 01:17:01
|
查看: 128|
回复: 0
发表于 2026-4-15 01:17:01
|
查看: 128|
回复: 0
