
为什么需要多向量检索?
在传统的稠密检索中,一个文档被编码为 单个向量 ,检索时通过 ANN(近似最近邻)算法快速找到与查询最相似的文档。这种方式简单高效,但存在根本性的信息瓶颈——无论文档多长、语义多复杂,所有信息都被压缩进一个固定维度的向量中。
像 ColBERT 这样的 late-interaction 模型 提出了不同的思路:为文档中的 每个 token 生成独立的向量 ,检索时通过 MaxSim 机制在 token 级别进行细粒度的语义匹配。具体来说,就是对查询中的每个 token,找到文档中与之最相似的 token,取最大相似度,然后将所有查询 token 的最大相似度求和作为文档的相关性分数。这种机制保留了 token 级的语义细节,在长文档、复杂查询等场景中展现出显著优势。
然而,多向量表示也带来了全新的工程挑战:一个文档从 1 个向量变为数十甚至数千个向量。传统的 ANN 索引面向的是“一个对象对应一个向量”的场景,无法直接处理“一个对象对应多个向量”的 Embedding List 结构。如何在保持检索质量的前提下实现高效的近似搜索,成为多向量检索落地的核心问题。
本文在文本检索场景下,评估了三种 Embedding List 近似检索策略——TokenANN、MUVERA、LEMUR,覆盖三个 ColBERT 模型和四个不同特征的数据集。主要发现:
- 多向量的价值是有条件的:
BruteForce 层面多向量始终优于单向量 Dense,但经过近似策略后,这一优势仅在长文档复杂查询场景中稳定保持。
- 模型与策略之间存在强烈的亲和性:
embedding 空间的区分度是解释最优策略差异的关键变量,选对模型-策略组合与选对模型本身同等重要。
- LEMUR 存在系统性的长度偏置:这一算法设计层面的局限,在特定模型-数据集组合下会导致灾难性的检索质量崩溃。
我们进一步在多模态 视觉文档检索(DocVQA) 场景中进行了验证。在本文的实验中,多模态是 embedding list 最具说服力的场景——多向量方案相比 Dense 单向量的优势远大于文本场景,且近似策略后仍稳定保持。
三种近似检索策略
给定查询 q 的 token 向量集合 {q₁, q₂, ..., qₘ} 和文档 d 的 token 向量集合 {d₁, d₂, ..., dₙ},MaxSim 将文档的相关性分数定义为:
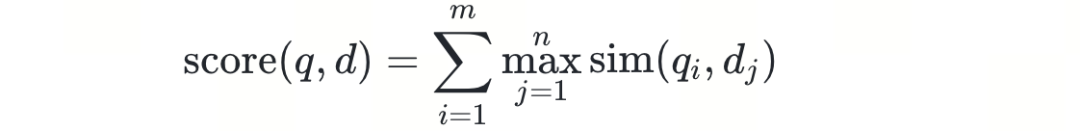
其中 sim 为向量相似度函数,支持内积,余弦相似度等。
BruteForce MaxSim 对所有文档精确计算上述分数,代表多向量检索的质量上限,但计算开销与文档数量线性相关,无法满足大规模检索的延迟要求。三种近似策略的目标都是在不遍历全部文档的前提下,尽可能逼近 BruteForce 的排序结果。它们共享相同的两阶段框架:近似搜索 筛选候选文档,然后对候选进行 精确 MaxSim 重排序。区别在于第一阶段如何高效地从全量文档中筛选出有潜力的候选。
所有策略都包含一个 ratio(候选放大倍数)参数:如果最终需要返回 top-K 文档,近似搜索阶段会先检索 top-(K × ratio) 个候选,再对候选进行精确 MaxSim 重排序。ratio 越大,候选覆盖越全但延迟越高。
TokenANN(直接 Token 索引)
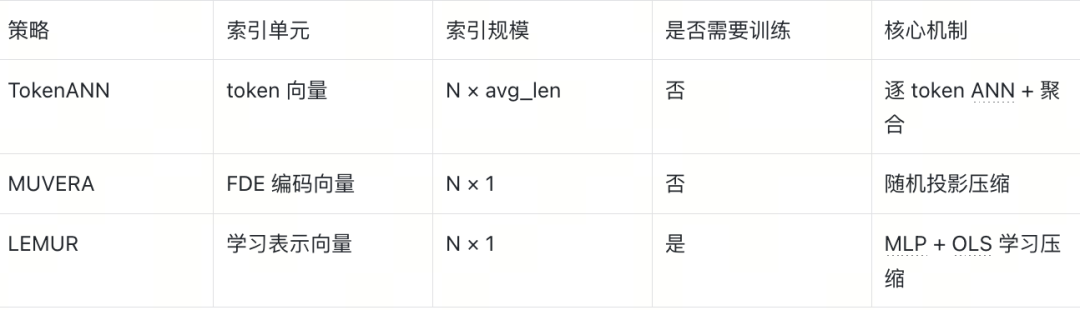
TokenANN 是最直接的思路:将所有文档的所有 token 向量逐一索引到 HNSW 中,搜索时对查询的每个 token 分别进行 ANN 检索,收集命中的文档,再进行精确 MaxSim 重排序。
- 构建:所有文档的所有 token 向量展平 → 共同构建一个 HNSW 索引(维护向量→文档映射)
- 搜索:逐 query token ANN 搜索 → 按文档映射聚合去重 → MaxSim 重排序
索引规模为 N_docs × avg_doc_len,是三种策略中最大的。优点是无信息损失、实现简单;缺点是索引体积大,且搜索时需要对多个 token 分别检索再聚合,延迟最高。
MUVERA(随机投影编码)
核心思想
MUVERA 的核心思想是通过 随机投影 将变长的多向量文档编码为 固定长度的单向量(Fixed Dimension Encoding, FDE),从而将问题转化回标准的单向量 ANN 检索。
MaxSim 的核心操作是为每个查询 token 找到文档中最相似的 token,MUVERA 的关键洞察是:如果我们用随机投影将向量空间划分为若干区域,相似的向量大概率会落入同一区域。因此,只要按区域(桶)聚合文档的 token 向量,查询 token 在对应桶内就能找到与其最相似的文档 token——将 MaxSim 的全局搜索转化为桶内的局部匹配。
FDE 编码
具体做法是将向量空间划分为固定数量的桶,让每个 token 向量落入对应的桶中,再对桶内向量取均值。无论文档有多少个 token,桶的数量是固定的,因此最终得到固定长度的文档表示。
分桶的具体方式是:随机生成 num_projections 个超平面,每个超平面将空间一分为二。一个 token 向量在每个超平面上要么在正侧(记为 1)要么在负侧(记为 0),这样 num_projections 个超平面产生一个 num_projections 位的二进制编码,对应 2^num_projections 个桶。例如 num_projections=4 时,每个 token 向量得到一个 4 位编码(如 0110),落入 2⁴=16 个桶之一。
对每个桶内的 token 向量取均值,得到一个 token_dim 维的向量;将所有桶的均值拼接,就是一次编码的结果。由于单次随机划分可能不够稳定,MUVERA 使用 num_repeats 组不同的随机超平面独立编码,再将结果拼接。最终 FDE 向量的维度为 num_repeats × 2^num_projections × token_dim。
举一个具体例子:假设 token_dim=2,num_projections=2,一个文档有 4 个 token 向量:[0.3, 0.8]、[0.9, 0.1]、[0.5, 0.6]、[0.7, 0.2]。2 个随机超平面将空间划分为 2²=4 个桶。假设 4 个 token 的二进制编码分别为 00、10、01、10,则:
- 桶 00:mean([0.3, 0.8]) = [0.3, 0.8]
- 桶 01:mean([0.5, 0.6]) = [0.5, 0.6]
- 桶 10:mean([0.9, 0.1], [0.7, 0.2]) = [0.8, 0.15]
- 桶 11:空桶,填零 [0, 0]
拼接 4 个桶的均值,得到 FDE 向量:[0.3, 0.8, 0.5, 0.6, 0.8, 0.15, 0, 0],维度为 2² × 2 = 8。无论文档有 4 个还是 400 个 token,FDE 维度始终是 8。num_repeats 则是用不同的随机超平面重复上述过程多次,将每次的结果拼接,以提高编码的鲁棒性。例如 num_repeats=7 时,最终维度为 7 × 8 = 56。
实际测试中我们使用 MUVERA-3-7(num_projections=3, num_repeats=7)和 MUVERA-4-7(num_projections=4, num_repeats=7)等配置。
非对称编码与检索流程
MUVERA 在文档端和查询端的 FDE 编码并不对称:文档端对桶内向量取 均值(求和后除以数量),而查询端只做 求和(不除以数量)。直觉上,文档的桶内均值代表该区域的“典型语义”,而查询端保留求和是为了让包含更多相似 token 的桶获得更高的匹配权重,从而更好地近似 MaxSim 中“取最大值”的行为。
- 构建:doc 的所有 token 向量 → FDE 编码(桶内取均值) → 固定长度单向量 → HNSW 索引(每文档 1 个向量)
- 搜索:query 的所有 token 向量 → FDE 编码(桶内求和) → ANN 候选 → MaxSim 重排序
索引规模为 N_docs × 1。优点是无需训练、实现简单;缺点是随机投影带来信息损失,且 FDE 维度随参数增长可能很大(如 MUVERA-4-7 在 token_dim=128 时,FDE 维度达 7 × 16 × 128 = 14336),影响 ANN 检索效率。MUVERA 可以和量化结合以降低整体维度或者精度。
LEMUR(学习型多向量压缩)
LEMUR 的核心思想是:将每个文档的多个向量(embedding list)压缩为一个固定维度的向量,使得标准 ANN 搜索可用。与 MUVERA 的无参数随机投影不同,LEMUR 采用数据驱动的方式,训练一个 MLP 网络从语料库中学习最优的压缩映射。
构建阶段:
- 准备训练数据:从所有文档的 token 向量中随机抽取 num_train_samples 个向量。将每个样本视为只含单向量的查询,计算它与每个文档的 MaxSim 分数,得到标签矩阵 Y num_samples × num_docs。
- 训练MLP:训练一个两段式的 MLP(多层感知机),输入为 dim 维的向量,输出为 num_docs 维的预测分数(即预测该向量与每个文档的 MaxSim)。网络的前半段称为
特征提取器 ,将输入映射到 hidden_dim 维的中间表示;后半段为 输出层 ,将中间表示映射到最终预测。训练的目标是让预测分数逼近真实的 MaxSim 标签。
- OLS拟合文档表示 W:训练完成后,丢弃输出层,只保留特征提取器。用它将所有样本向量映射为 hidden_dim 维的中间特征 Z num_samples × hidden_dim,然后通过最小二乘法(OLS)求解文档表示矩阵 W num_docs × hidden_dim,使得 Z × W^T 尽可能逼近真实标签 Y。这样,每个文档被压缩为一个 hidden_dim 维的向量。
- 建ANN索引:在 W 上构建 HNSW 索引(每文档 1 个向量)。
搜索阶段:
- 对查询的所有 token 向量通过特征提取器得到隐藏特征,将所有 token 的隐藏特征求和为一个向量。
- 用该向量在 W 的 HNSW 索引上进行 ANN 搜索,得到候选文档。
- 对候选文档进行精确 MaxSim 重排序。
索引规模同样为 N_docs × 1。优点是数据自适应压缩,能够针对具体语料库学习最优的文档表示;缺点是需要训练时间,且存在系统性的 长度偏置问题(详见第 5 节)。
策略对比总结
实验设计
文本检索
模型
我们选取三个不同规模和特性的 ColBERT 模型,以及一个 Dense 单向量基线:
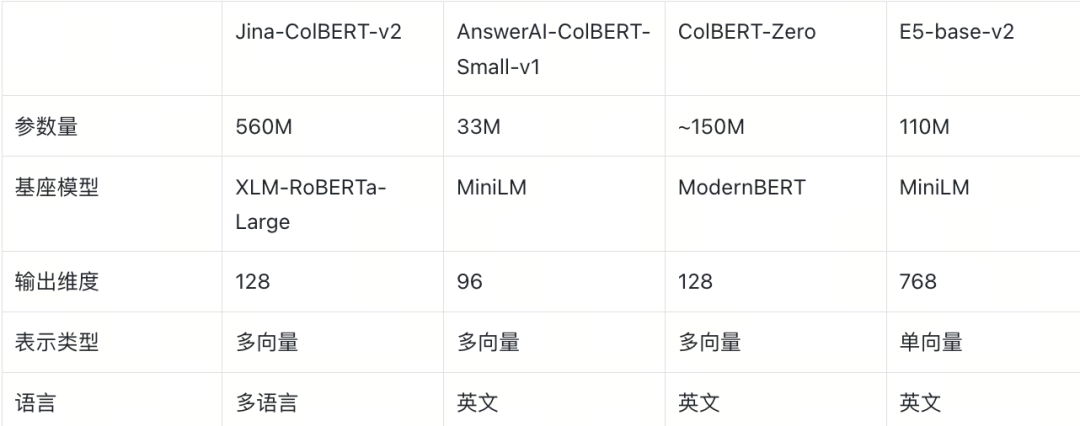
三个 ColBERT 模型在参数规模、基座架构和 embedding 空间特性上存在显著差异,这些差异将直接影响近似策略的表现(详见第 5 节)。Dense E5-base-v2 作为单向量基线,用于衡量多向量方案相对于传统稠密检索的优势。
数据集
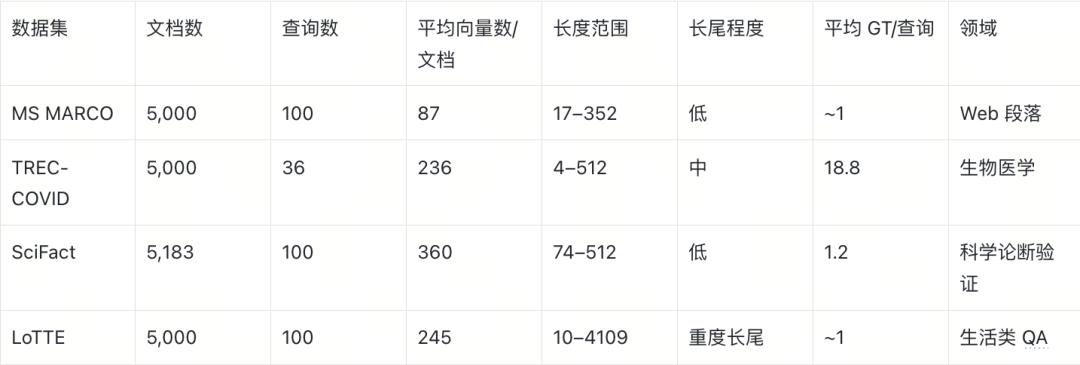
四个数据集在文档长度分布上形成互补:MS MARCO 为短文档且分布紧凑;SciFact 为长文档但分布均匀;TREC-COVID 长度方差较大;LoTTE 是唯一具有 重度长尾 的数据集,最长文档超过 4000 向量。这一长尾特性将在 LEMUR 的长度偏置分析中扮演关键角色。
数据采样说明:TREC-COVID 和 LoTTE 从完整语料库中随机采样 5,000 篇文档,再筛选在样本中命中足够 GT 的查询(TREC-COVID 要求 ≥5 篇,LoTTE 要求 ≥1 篇);MS MARCO 由于语料库极大(880 万篇)且标注稀疏(每条查询仅 ~1 篇 GT),随机采样几乎无法命中 GT,因此采用混合采样先确保 GT 文档入选,再用随机文档填充至 5,000 篇;SciFact 使用全部 5,183 篇文档。所有模型(含 Dense E5 基线)共享相同的文档集和查询集,仅编码模型不同。
策略配置
所有近似策略均以 HNSW 作为底层 ANN 索引,统一 ratio=5.0(即候选放大 5 倍后 MaxSim 重排序)。具体配置:
MUVERA-3-7:num_projections=3, num_repeats=7(FDE 维度 = 7 × 8 × token_dim)MUVERA-4-7:num_projections=4, num_repeats=7(FDE 维度 = 7 × 16 × token_dim)LEMUR:hidden_dim=256, num_layers=2, num_train_samples=20000
多模态检索
模型
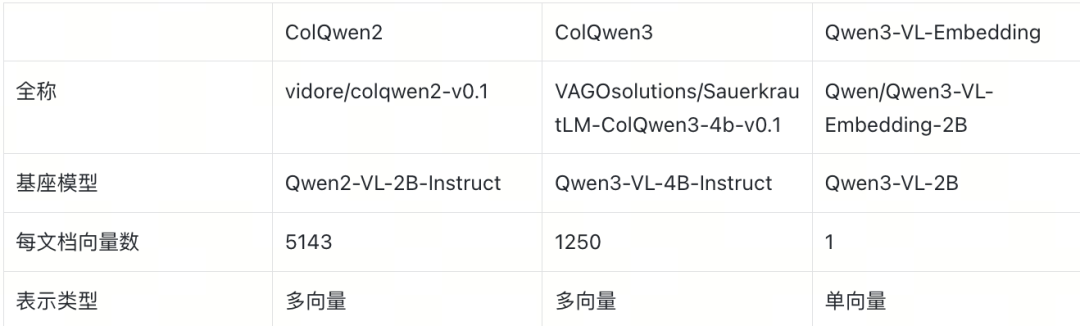
在视觉文档检索场景中,我们选取两个 ColQwen 多向量模型和一个 Dense 基线:
多模态模型将文档页面图像编码为 patch 级向量(类似文本场景中的 token 向量),查询文本编码为 token 级向量,检索同样基于 MaxSim 机制。
数据集

DocVQA(Document Visual Question Answering)包含真实文档图像及对应的自然语言问题,任务是根据问题检索最相关的文档页面。
策略配置
与文本检索相同,使用 TokenANN、MUVERA-3-7、MUVERA-4-7、LEMUR,ratio=5.0。
评估体系
我们使用两类指标从不同角度评估检索质量:
E2E 指标(对 Ground Truth 的端到端质量)
衡量检索系统最终找到真实相关文档的能力,包括:
nDCG@10:归一化折损累积增益,综合衡量 top-10 结果的排序质量MRR@10:首个相关文档的排名倒数,衡量首结果精度R@100:top-100 结果中相关文档的召回率
Math 指标(对 BruteForce 的还原度)
将 BruteForce MaxSim 的排序结果当做 Ground Truth,衡量近似策略对其的保持程度。可计算 Math nDCG@10、Math R@100 等,与 E2E 指标使用相同的度量方式,区别仅在于 Ground Truth 来源不同。这一类指标反映的是 近似算法本身的精度 ,与下游标注无关。
需要注意的是,这两类指标衡量的是不同维度的质量:Math 指标反映近似算法对 BruteForce 排序的保持度,E2E 反映最终找到真实相关文档的能力。两者并不总是一致——当 MaxSim 本身与人类相关性判断存在偏差时,高 Math 指标不一定带来高 E2E 质量。我们将在实验结果中对比这两类指标。
本文主要报告 ratio=5.0 的结果,即查询 5 * top-k 篇文档进行 rerank。
文本检索:多向量的价值是有条件的
BruteForce 层面:多向量始终占优
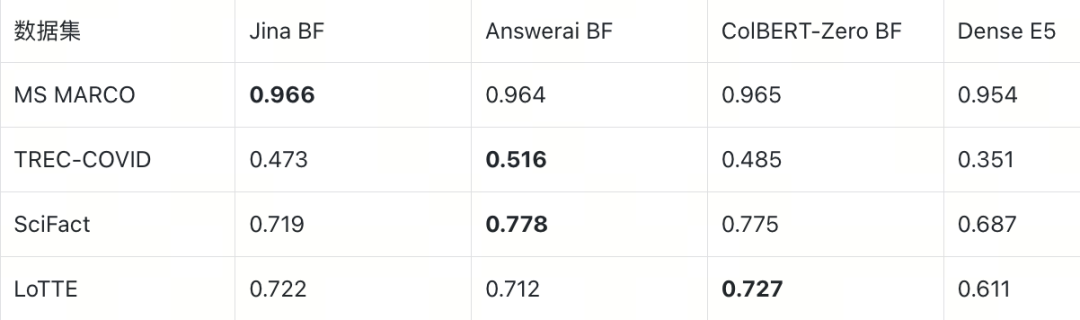
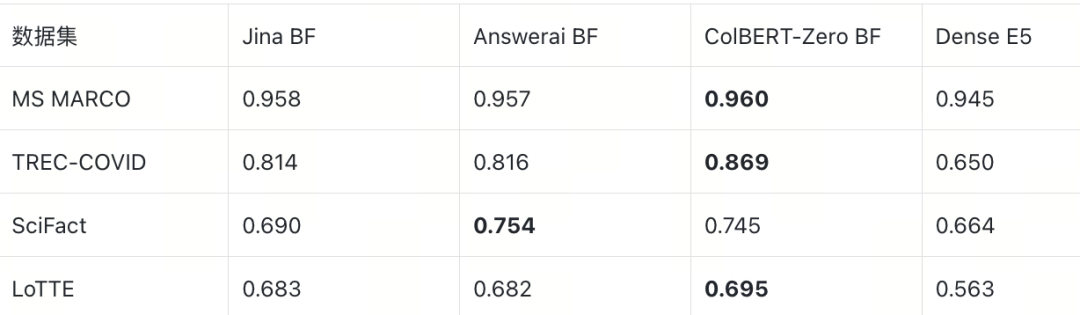
在精确计算 MaxSim 的 BruteForce 条件下,ColBERT 多向量在所有数据集上均优于 Dense E5 单向量:
E2E nDCG@10(BruteForce)
E2E MRR@10(BruteForce)
E2E R@100(BruteForce)
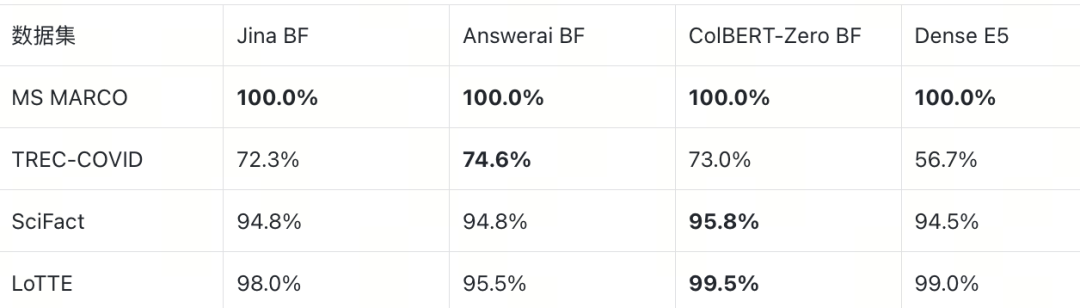
多向量的优势幅度与场景强相关:MS MARCO 上各指标差距均在 ~1pp 以内(短文档,语义简单),而 TREC-COVID 上差距最为显著——nDCG@10 高出 12–17pp,MRR@10 高出 16–22pp,R@100 高出 16–18pp,验证了 token 级交互在长文档复杂场景中的核心价值。
近似后:优势仅在部分场景保持
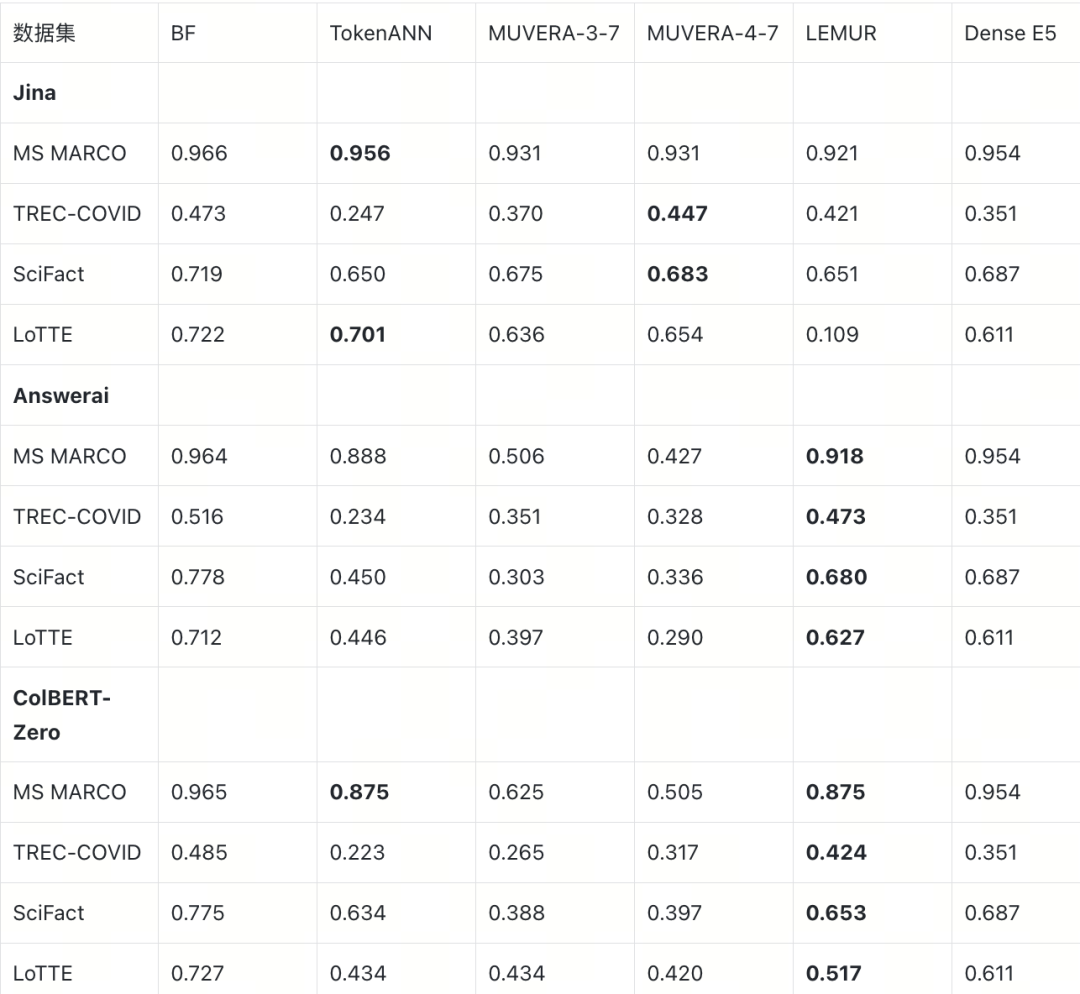
下表列出 E2E nDCG@10 作为核心指标(完整的 MRR@10 和 R@100 数据见附录 A)。加粗标注每行最优近似策略。
E2E nDCG@10(ratio=5.0)
按数据集分析
- TREC-COVID:多向量方案的核心优势场景。 三个模型的最优策略 nDCG@10 均大幅超过 Dense E5(+7~12pp),R@100 同样全面领先(68.6%~71.2% vs 56.7%)。长文档、复杂查询、密集标注的特性使 token 级交互的优势在近似损耗后仍然显著。
- MS MARCO:优势几乎消失。 仅 Jina TokenANN 勉强持平 Dense E5(0.956 vs 0.954),其余组合均不如。短文档场景下多向量的增量本就有限(BF 仅高 ~1pp),近似损耗足以抹平。(注意:本文 MS MARCO 采用混合采样,任务难度低于全库检索,结论适用范围有限。)
- SciFact:全面不如 Dense E5。 尽管 BruteForce 层面多向量优势明显(+3~9pp nDCG@10),所有模型的最优近似策略均未能超过 Dense E5 的 0.687。SciFact 文档平均向量数最多(~360),是近似损耗最大的场景。
- LoTTE:表现严重分化。 Jina TokenANN(0.701)大幅超过 Dense E5(0.611),Answerai LEMUR(0.627)也有优势,但 ColBERT-Zero 最优仅 0.517,远低于 Dense E5。值得注意的是 Jina LEMUR 在 LoTTE 上出现灾难性崩溃(nDCG 0.109,R@100 仅 30.5%),这一现象将在第 5 节长度偏置分析中详细讨论。
策略表现模式
在本文的超参配置下(ratio=5.0,固定 MUVERA/LEMUR 参数),可以清晰看到 模型与策略之间的强烈亲和性 :
- Jina:TokenANN 和 MUVERA 表现最优,LEMUR 在 LoTTE 上灾难性崩溃。
- Answerai 和 ColBERT-Zero:LEMUR 在所有数据集上均排名第一,其他策略大幅落后。尤其 Answerai 的 MUVERA 表现极差(如 SciFact MUVERA-3-7 仅 0.303)。
这一模型-策略亲和性将在第 5 节中从 embedding 空间区分度 的角度深入分析。
近似质量:Math nDCG@10
Math nDCG@10 衡量近似策略对 BruteForce 排序结果的还原度(详见 3.3 节)。完整 Math R@100 数据见附录 B。加粗标注每行最优策略。
Math nDCG@10(相对 BruteForce,ratio=5.0)
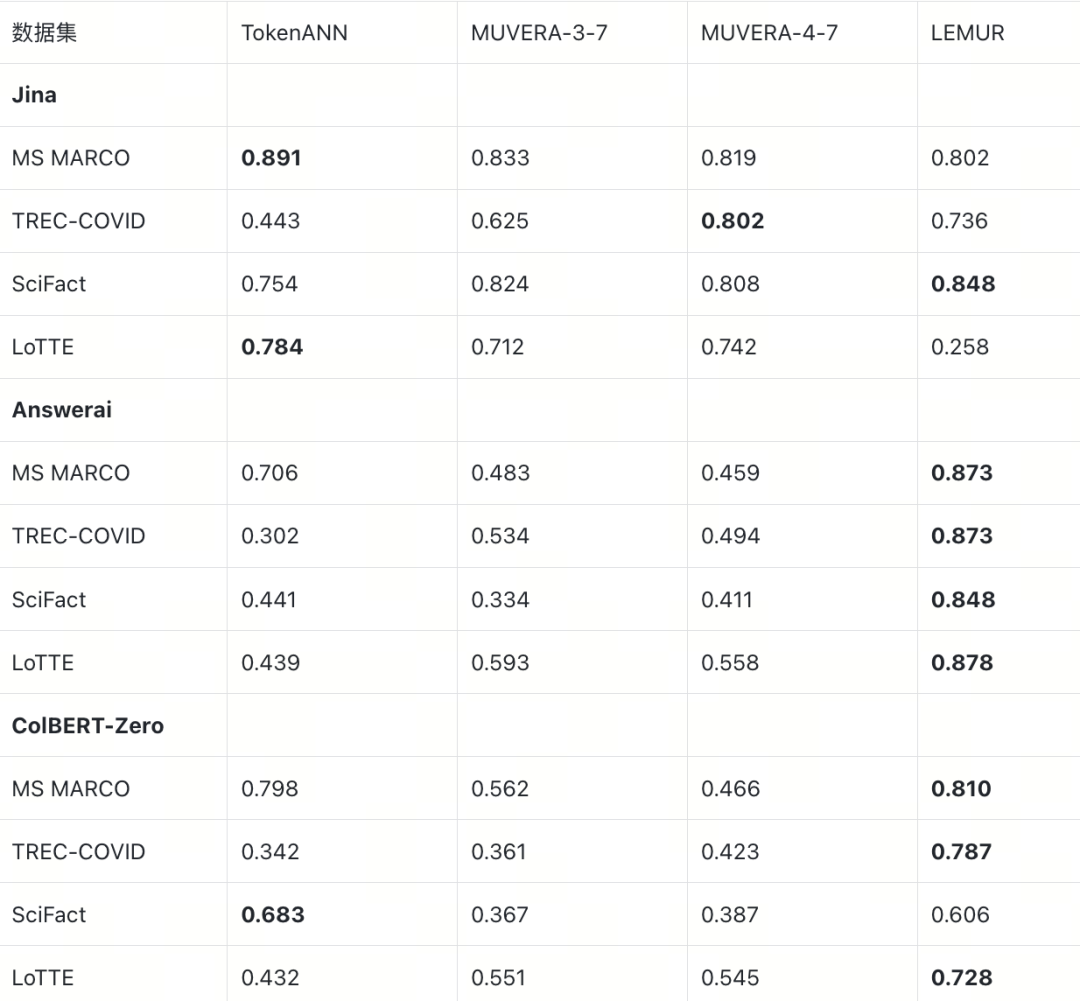
对比 E2E nDCG@10,有以下发现:
- 模型-策略亲和性:Math 表中 Answerai 和 ColBERT-Zero 的最优策略与 E2E 表一致(均为 LEMUR)。Jina 在 E2E 上偏好 TokenANN/MUVERA,Math 上也以这两者为主(SciFact 例外,LEMUR Math nDCG 略高)。
- ColBERT-Zero SciFact 是最大瓶颈:最优 Math nDCG@10 仅 0.683,远低于其他组合,近似阶段本身的质量损耗就已经很严重。
- Jina LEMUR LoTTE 崩溃在 Math 层面同样可见:Math nDCG@10 仅 0.258,与 E2E 的 0.109 一致——问题出在近似阶段而非重排序,将在第 5 节详细分析。
简言之,BruteForce 层面多向量始终更好,但这一优势能否在近似检索中保持,取决于数据集特征(文档复杂度、查询难度)和模型-策略的匹配程度。在 TREC-COVID 这样的长文档复杂场景中,多向量方案即使经过近似也能显著胜出;而在 MS MARCO、SciFact 这样的场景中,直接使用 Dense 单向量可能是更务实的选择。
Embedding 空间区分度与策略亲和性
第 4 节的数据揭示了一个显著的模式:Jina 偏好 TokenANN/MUVERA,而 Answerai 和 ColBERT-Zero 偏好 LEMUR。本文观察到,embedding 空间的 区分度 差异是解释这一亲和性的一个很强的变量。
什么是 Embedding 区分度
Embedding 区分度描述的是模型输出的 token 向量在空间中的分散程度。高区分度意味着不同 token 的向量彼此远离,单个 token 向量具有较强的辨识力;低区分度意味着 token 向量彼此靠近,单个向量难以区分不同的语义。
我们通过以下方式量化区分度:从语料库中随机抽取 token 向量作为单向量查询,计算每个样本与所有文档的 MaxSim 分数,统计这些分数的分布特性。以 LoTTE 数据集为例:
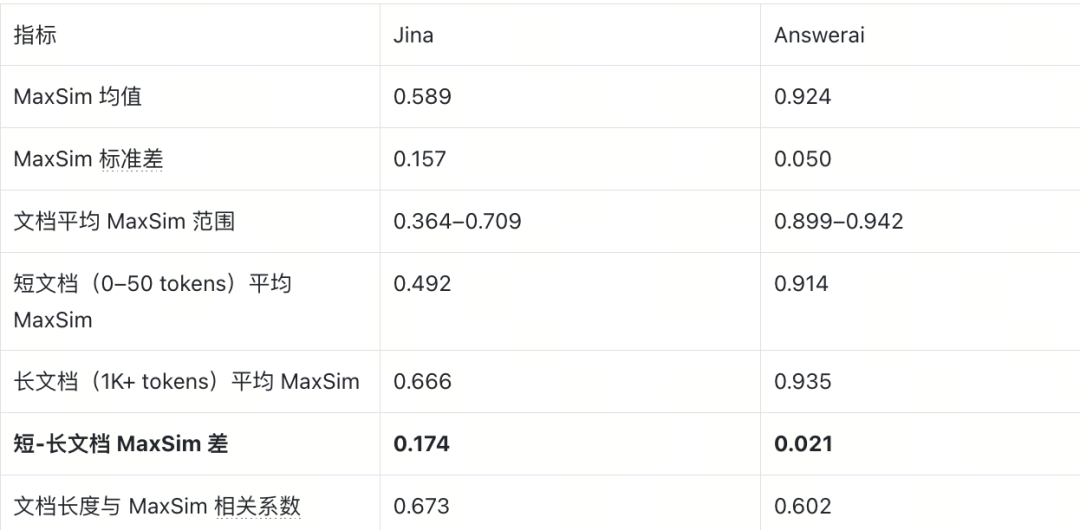
Jina 的 MaxSim 分布范围宽(均值 0.589,标准差 0.157),不同文档获得的分数差异大——空间区分度高。Answerai 的 MaxSim 高度集中(均值 0.924,标准差 0.050),几乎所有文档都获得相近的分数——空间区分度低。ColBERT-Zero 介于两者之间,属于中等区分度。
关键的是最后三行:Jina 的短文档与长文档 MaxSim 差高达 0.174,而 Answerai 仅 0.021。这意味着在高区分度空间中,文档长度本身就会显著影响 MaxSim 分数——这将直接导致 LEMUR 的长度偏置问题(详见 5.3 节)。
区分度与策略亲和性
高区分度(Jina)→ TokenANN / MUVERA 有效
当 token 向量彼此远离时,每个 token 都是独特的“语义探针”。TokenANN 对单个 query token 做 ANN 搜索时,能精准命中语义相关的 doc token,从而有效聚合出相关文档。MUVERA 的随机投影分桶也能将语义相似的 token 划分到同一桶中,因为空间中的区分度足以支撑分桶的局部保序性。
数据佐证:Jina 的 TokenANN Math R@100 在所有数据集上均为 68.5%~88.5%,远高于 Answerai 的 44.6%~65.5%。
低区分度(Answerai)→ LEMUR 有效
当 token 向量彼此靠近时,ANN 检索无法有效区分相关与不相关的 token——搜索一个 query token 会命中大量语义无关但向量相近的 doc token,导致 TokenANN 和 MUVERA 的初筛质量极差。
但 LEMUR 在低区分度下不受影响。LEMUR 的训练标签是 MaxSim 分数:label[v, d] = max_{t∈d} IP(v, t)。在低区分度空间中,所有 token 对的内积都压缩在极窄的范围内(Answerai 为 0.90~0.94),文档长度对 MaxSim 的影响微乎其微(短文档 0.914 vs 长文档 0.935,差仅 0.021)。LEMUR 的主要弱点——长度偏置(详见 5.3 节)——在这种空间中被自然消除,MLP 转而学习语义特征。Answerai LEMUR Math nDCG@10 在所有数据集上均达 0.848~0.878。
LEMUR 的长度偏置:从机制到崩溃
LEMUR 长度偏置的根源在于 MaxSim 标签的计算方式。对于采样向量 v 和文档 d(以内积(IP)为例):
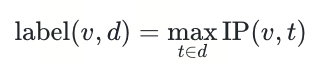
文档包含的 token 越多,取到高内积值的概率越大——这是一个纯粹的统计效应。当 embedding 空间的区分度足够高时,这一效应会产生系统性的 长度偏置 :长文档的 MaxSim 分数系统性地高于短文档,不是因为它们语义更相关,而是因为取 max 的集合更大,命中高内积值的概率更高。
MLP 在训练时会捕捉这一统计规律,学到的主要信号变成“长文档 = 高 MaxSim”而非“语义相关 = 高 MaxSim”。OLS 回归 W = pinv(Z)Y 随即产生编码文档长度的权重向量,导致检索时按长度而非相关性排序。
长度偏置的严重程度取决于两个因素的叠加:
- Embedding 区分度:区分度越高,短文档与长文档的 MaxSim 差异越大(见 5.1 节表格)。Jina LoTTE 上差距 0.174,Answerai 仅 0.021。
- 文档长度方差:长度分布越不均匀,长度偏置的影响越大。LoTTE 的文档长度跨越 10~4109 tokens,呈重度长尾分布,是四个数据集中长度方差最大的。
当高区分度(Jina)与高长度方差(LoTTE)叠加时,LEMUR 出现灾难性崩溃:Math R@100 仅 24.7%,E2E nDCG@10 从 BF 的 0.722 降至 0.109。而同样是 Jina,在长度分布较均匀的 MS MARCO 和 SciFact 上,LEMUR 虽非最优但仍可用(nDCG 0.921、0.651)。同样是 LoTTE,Answerai LEMUR 则完全不受影响(R@100 95.1%,nDCG 0.627)。
这不是实现 bug,而是 LEMUR 算法设计中的固有风险——MaxSim 标签天然携带长度信号,当该信号足够强时,MLP 会优先学习长度而非语义。在没有长度归一化或平衡采样等缓解措施的情况下,高区分度 + 高长度方差的组合将导致严重的质量退化。
多模态验证:视觉文档检索
文本检索中,多向量的优势在近似后大幅缩水,仅在部分场景保持。视觉文档检索场景是否也如此?我们在 DocVQA 上使用 ColQwen2、ColQwen3 和 Dense Qwen3-VL-Embedding 进行了验证(实验设计见 3.2 节)。
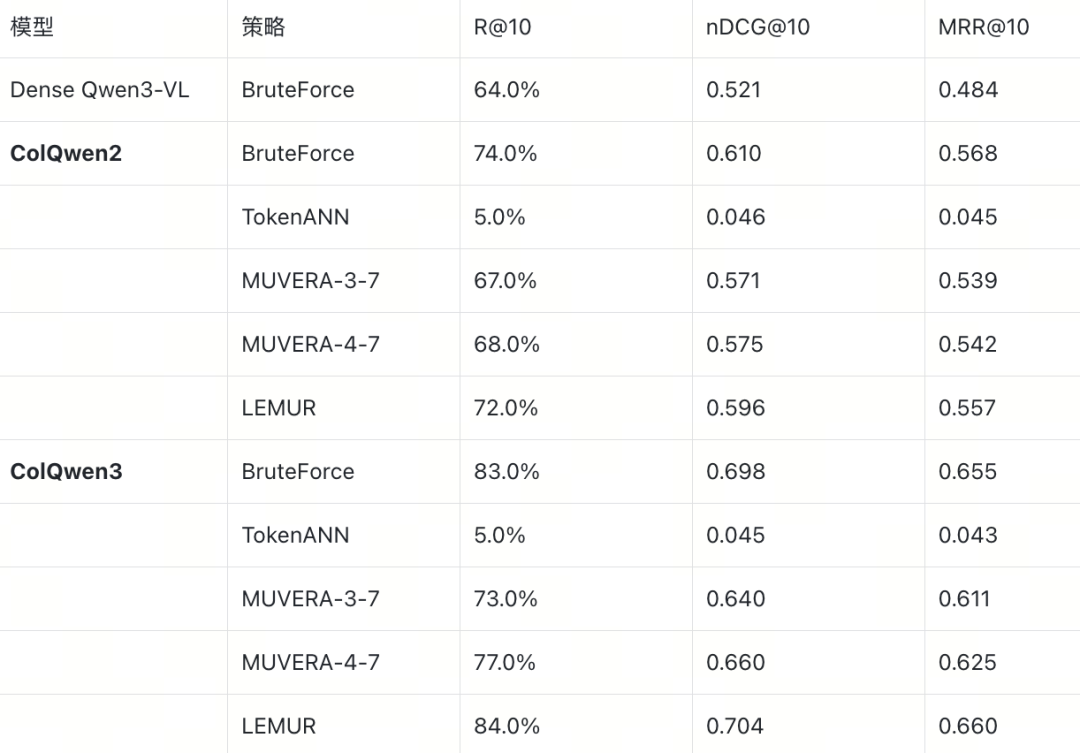
E2E nDCG@10(DocVQA,ratio=5.0)

与文本检索的对比,有以下发现:
- 多向量优势更加显著且近似后稳定保持。 BruteForce 层面,ColQwen2 和 ColQwen3 分别比 Dense 高出 8.9pp 和 17.7pp nDCG@10。经过近似策略后,ColQwen2 最优策略 LEMUR(0.596)仍超过 Dense 7.5pp,ColQwen3 最优策略 LEMUR(0.704)超过 Dense 18.3pp。相比文本检索中多向量优势在 MS MARCO、SciFact 上被近似损耗抹平的情况,视觉文档检索的多向量优势更加稳固。
- TokenANN 完全失效。 两个模型的 TokenANN nDCG@10 均不足 0.05。视觉模型的 patch 向量数量极大(ColQwen2 每文档 5143 个、ColQwen3 每文档 1250 个),单个 patch 仅编码局部图像区域,语义信息有限,per-token ANN 无法有效定位相关文档,导致候选质量极差。
- MUVERA 和 LEMUR 均有效。 排除 TokenANN 后,两种压缩策略都能较好地保持 BruteForce 质量。ColQwen3 LEMUR 的 nDCG@10(0.704)甚至略高于 BF(0.698),这一 0.006 的差异在 100 条查询的小样本上更可能是评测噪声。
视觉文档的多向量价值更大。 文档图像包含表格、图表、排版等复杂视觉元素,单个向量难以捕捉这些多层次的信息,而 patch 级多向量能在空间上保留局部视觉特征。这使得多向量相对于 Dense 的增量远大于文本场景,近似策略的损耗也不足以抹平这一优势。
探索:直接在 Embedding List 上构建 HNSW
前文的三种策略都需要将多向量压缩或拆解为单向量后再建 ANN 索引,不可避免地引入信息损失。一个自然的问题是:能否跳过压缩,直接在 embedding list 粒度上构建 HNSW?
方法
将每个文档的 embedding list 作为 HNSW 中的一个节点,节点间的相似度定义为双向 MeanMaxSim:
sim(A, B) = MeanMaxSim(A, B) + MeanMaxSim(B, A)
实现上通过取负转为距离传入 HNSW。这一设计涉及三个关键选择:
- 为什么双向? HNSW 建图要求距离函数具有对称性,而 MaxSim 本身不对称(MaxSim(A,B) ≠ MaxSim(B,A)),因此需要双向计算。
- 为什么取 Mean? MaxSim 的值随左侧向量数量增长——文档越长,求和项越多,分数越高。除以左侧长度消除这一偏置,使不同长度的文档在建图时获得可比的相似度度量。
- 为什么搜索时用 MaxSim 而非 MeanMaxSim? 检索排序只需要 MaxSim(query, doc),即查询中每个 token 在文档中的最佳匹配之和,这直接衡量查询相对于文档的匹配程度。反向的 MaxSim(doc, query) 衡量的是文档中每个 token 在查询中的配对,由于文档远长于查询,大量文档 token 与查询无关,反向分数主要是噪声,不具备检索意义。建图时双向计算是合理的:节点都是文档,文档之间的双向 MeanMaxSim 能有效衡量彼此的语义相关性;而搜索时查询与文档角色不对等,应回到语义上有意义的单向 MaxSim(query, doc)。
实验结果
我们在 MS MARCO(Jina,avg_len=87)和 TREC-COVID(Answerai,avg_len=236)上进行了测试。
E2E nDCG@10

Math nDCG@10

EmbList HNSW 的 Math nDCG@10 远高于三种策略(0.98+ vs 0.87~0.89),近似阶段几乎无损。E2E 上 TREC-COVID 完全达到 BF 水平(0.516),MS MARCO 也几乎持平(0.957 vs 0.966)。
代价与局限
构建时间是主要瓶颈。 EmbList HNSW 的每次距离计算是双向 MeanMaxSim,需要计算两个 embedding list 间所有 token 对的内积,复杂度为 O(avg_len² × dim),相比单向量的 O(dim) 贵 avg_len² 倍;但节点数从 N × avg_len 降为 N,少 avg_len 倍。两者相抵,理论建图耗时比为 O(avg_len)。实测比值约为 avg_len × 0.07~0.08:

比值 / avg_len 分别为 0.07、0.077,与理论 O(avg_len) 一致。
更关键的限制是 embedding list 长度的上界。 当文档包含数千个向量时(ColQwen2 每文档 5143),距离计算代价随 list 长度急剧增长,构建和搜索的延迟都将变得不可接受。这一限制排除了长文档和多模态等核心应用场景,因此该方案暂不纳入 Knowhere 的实现。
尽管如此,该实验验证了一个重要的上界:当近似阶段几乎无损时,多向量检索的 E2E 质量可以非常接近 BruteForce。这也说明当前三种策略的主要瓶颈确实在近似阶段的信息损失。
结论与策略选择指南
核心发现
本文通过三个 ColBERT 模型、四个文本数据集和一个多模态数据集的系统评测,得出以下结论:
- 多向量在多模态检索中价值突出。 视觉文档包含表格、图表、排版等复杂视觉元素,单向量无法充分表达这些多层次信息。DocVQA 实验中,ColQwen3 BruteForce nDCG@10 比 Dense 高出 17.7pp,经过近似策略(LEMUR)后依然高出 18.3pp,近似损耗几乎为零——这一优势幅度远超文本场景。在本文的实验中,多模态检索是 embedding list 方案最具说服力的应用场景。
- 文本场景中,多向量的价值是有条件的。 BruteForce 层面多向量始终优于 Dense 单向量,但经过近似策略后,这一优势仅在长文档复杂查询(如 TREC-COVID)中稳定保持。在本文评测设定下,短文档简单场景(如 MS MARCO)中 Dense 单向量可能是更务实的选择。
- 模型与策略之间存在强烈的亲和性。 本文观察到,embedding 空间的区分度是解释最优策略差异的一个很强的变量:高区分度模型(如 Jina)倾向于在 TokenANN / MUVERA 上表现更好,低区分度模型(如 Answerai)倾向于在 LEMUR 上表现更好。选错策略的代价可能远大于选错模型——Jina LEMUR 在 LoTTE 上 nDCG@10 仅 0.109,而 Jina TokenANN 达 0.701。
- LEMUR 存在系统性的长度偏置风险。 当高 embedding 区分度与高文档长度方差叠加时,LEMUR 会出现灾难性的质量崩溃。这是 MaxSim 标签中固有的长度信号导致的算法层面风险。
- 近似阶段是主要瓶颈。 EmbList HNSW 实验表明,当近似阶段几乎无损时(Math nDCG@10 > 0.98),E2E 质量可以非常接近 BruteForce。当前三种策略的质量损失主要来自近似阶段的信息压缩。
策略选择指南
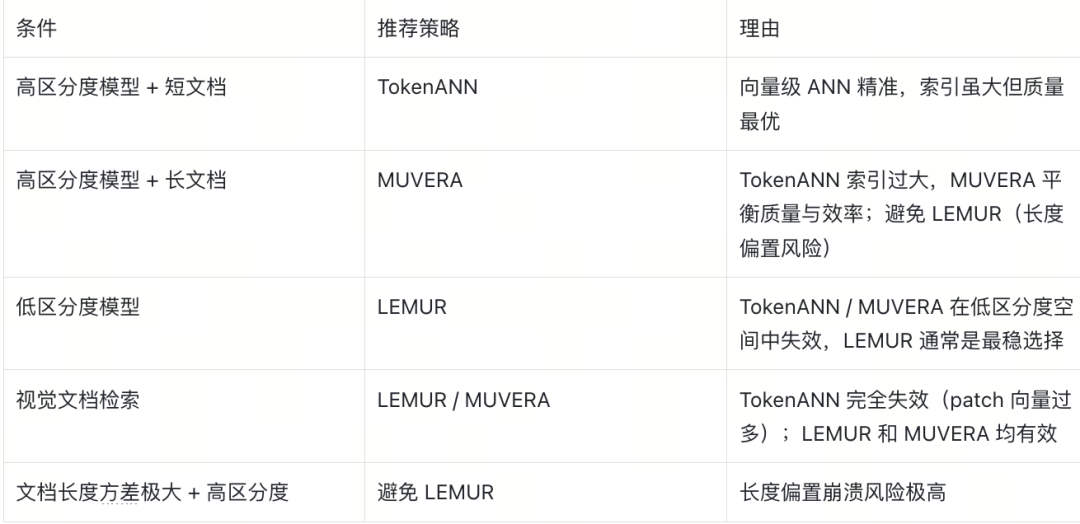
以上推荐基于本文的超参配置(ratio=5.0,固定 MUVERA/LEMUR 参数)。实际部署时,可以通过采样 token 向量计算跨文档 MaxSim 分布作为快速启发式诊断(注意该指标本身混有文档长度效应),再结合具体超参调优和小规模评测选择策略。
关于延迟
本文聚焦检索质量,延迟不作详细展开,但值得简要说明三种策略的延迟特征。搜索分为两个阶段:候选筛选(ANN 搜索)和 MaxSim 重排序。
- LEMUR 延迟最低且最稳定:候选筛选是标准的单向量 HNSW 搜索(hidden_dim 固定),速度很快。
- MUVERA 候选筛选延迟受 FDE 维度影响:维度越大(num_projections 和 num_repeats 越高),一阶段越慢。
- TokenANN 延迟最高:需要对每个 query token 分别进行 ANN 搜索再聚合,搜索次数与查询长度成正比,显著慢于另外两种策略。
对于 MUVERA 和 LEMUR,候选筛选速度较快,MaxSim 重排序占据了绝大部分延迟——这也意味着在这两种策略下,ratio 参数对总延迟的影响远大于策略本身的选择。
对于希望深入探讨具体技术细节和实现方案的开发者,也可以到 云栈社区 的“人工智能”或“算法/数据结构”板块,查看更多相关主题的深度分析和实战分享。
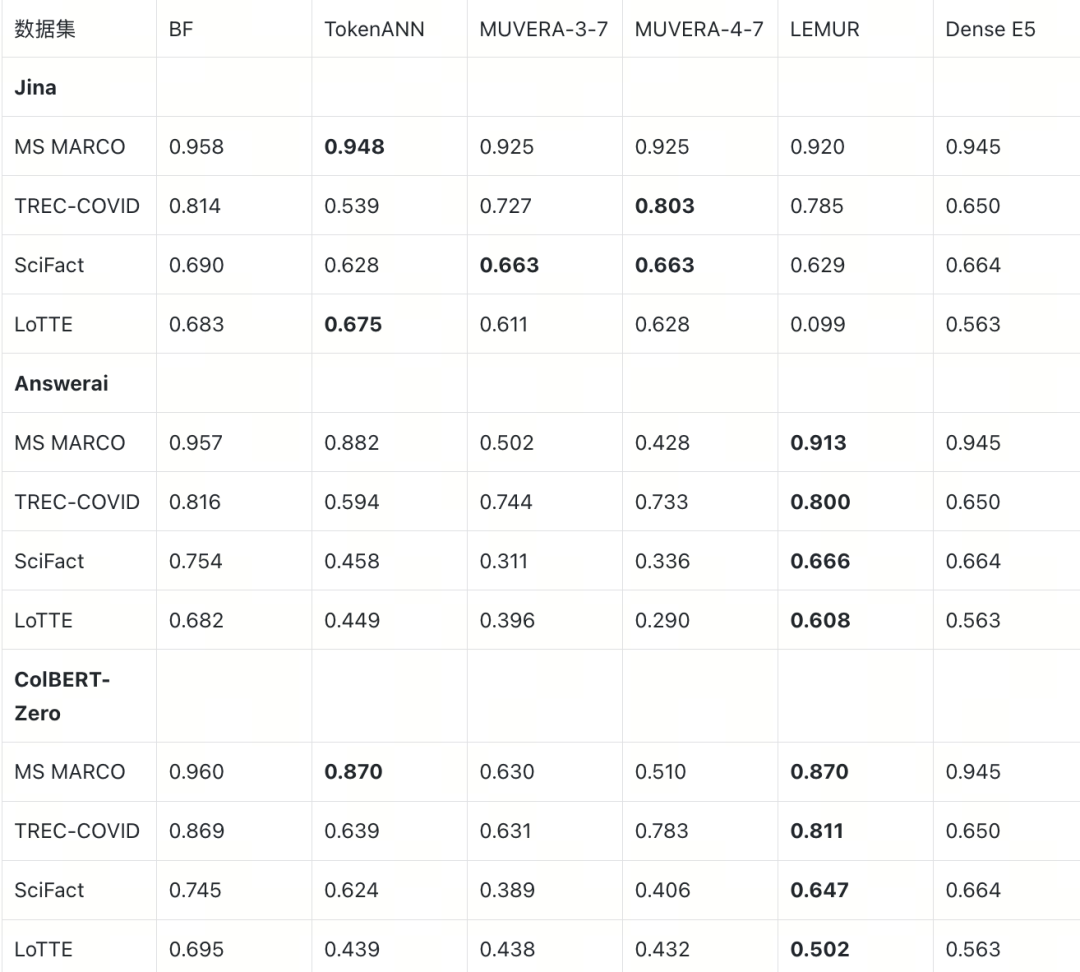
附录 A:完整 E2E 指标数据
E2E MRR@10(ratio=5.0)
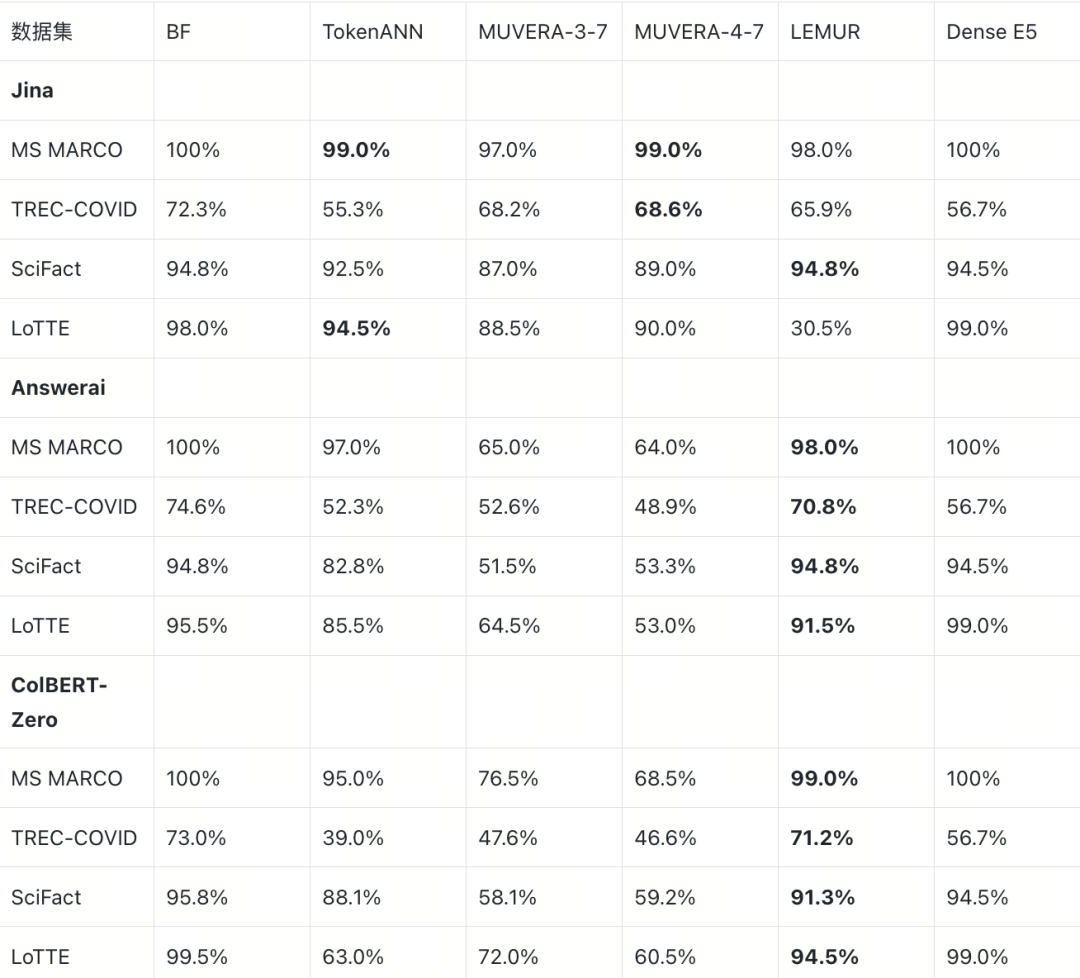
E2E R@100(ratio=5.0)
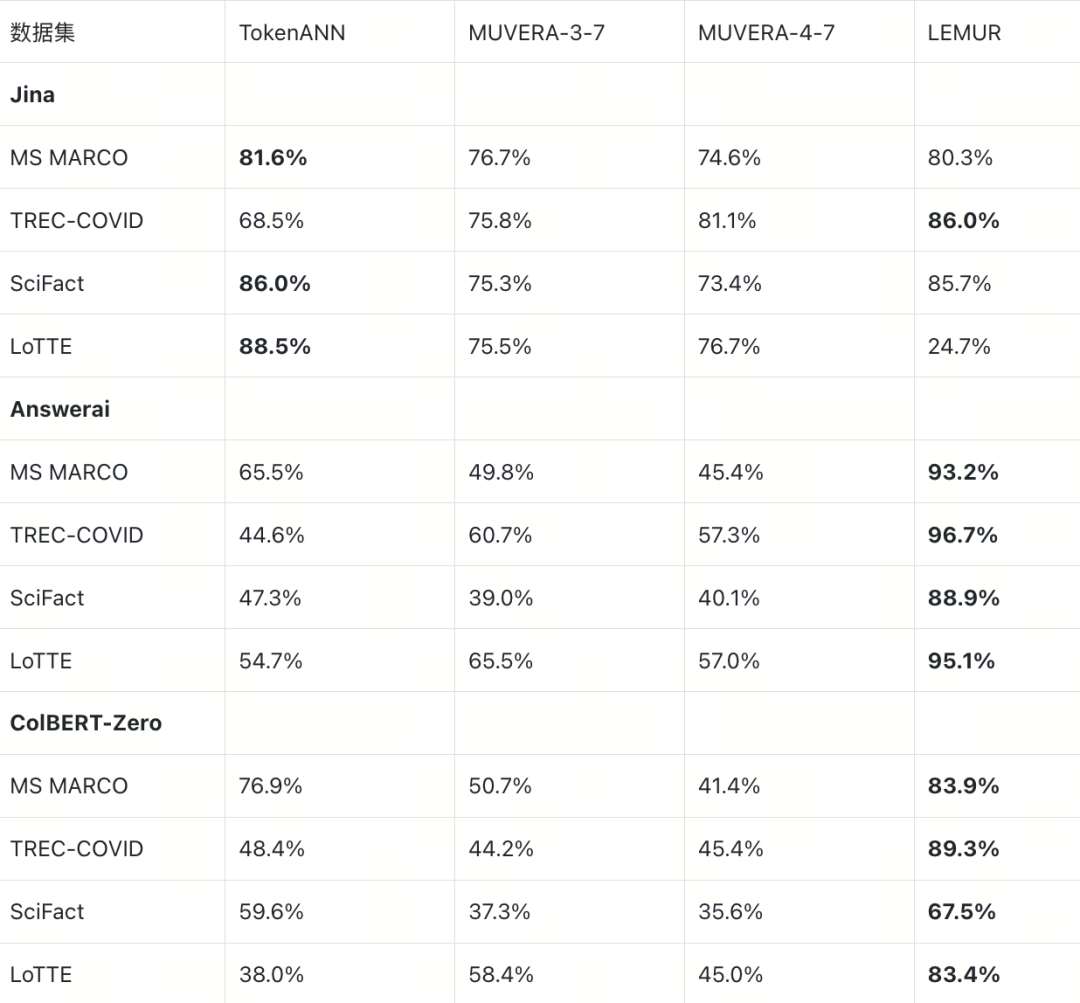
附录 B:Math R@100
Math R@100(相对 BruteForce,ratio=5.0)
附录 C:DocVQA 完整数据
E2E 指标(DocVQA,ratio=5.0)
 发表于 2026-4-16 21:32:36
|
查看: 135|
回复: 0
发表于 2026-4-16 21:32:36
|
查看: 135|
回复: 0
