1. 概述
1.1 为什么需要 OpenClaw
在日常使用AI的过程中,构建一个健壮的 Agent 系统会面临一系列现有框架难以解决的问题:
(1)多渠道消息统一处理的痛点
真实场景中,用户可能通过Discord、Telegram、Slack等多种渠道与 AI Agent 交互。现有框架要么只支持 HTTP API 调用,要么需要为每个渠道从零开始写集成代码。OpenClaw内建了十余种渠道支持,并通过插件机制(extensions/)允许扩展更多渠道。
(2)长时运行 Agent 的挑战
多数 Agent 框架假设“一次请求、一次响应”的交互模式。但生产环境中的 Agent 需要:
- 在后台持续运行(Gateway 模式),接收来自多个渠道的消息
- 管理跨多轮对话的会话状态
- 处理 LLM 提供商的各种故障(限流、过载、认证失效)并自动恢复
- 支持多个 API Key 轮换以规避单点故障
(3)灵活的知识扩展需求
Agent 需要在不修改核心代码的前提下,动态获取特定领域的操作指南。例如,同一个 Agent 面对“帮我创建 GitHub PR”和“帮我查今天的天气”需要截然不同的操作知识。这种需求催生了 OpenClaw 的 Skill 机制。
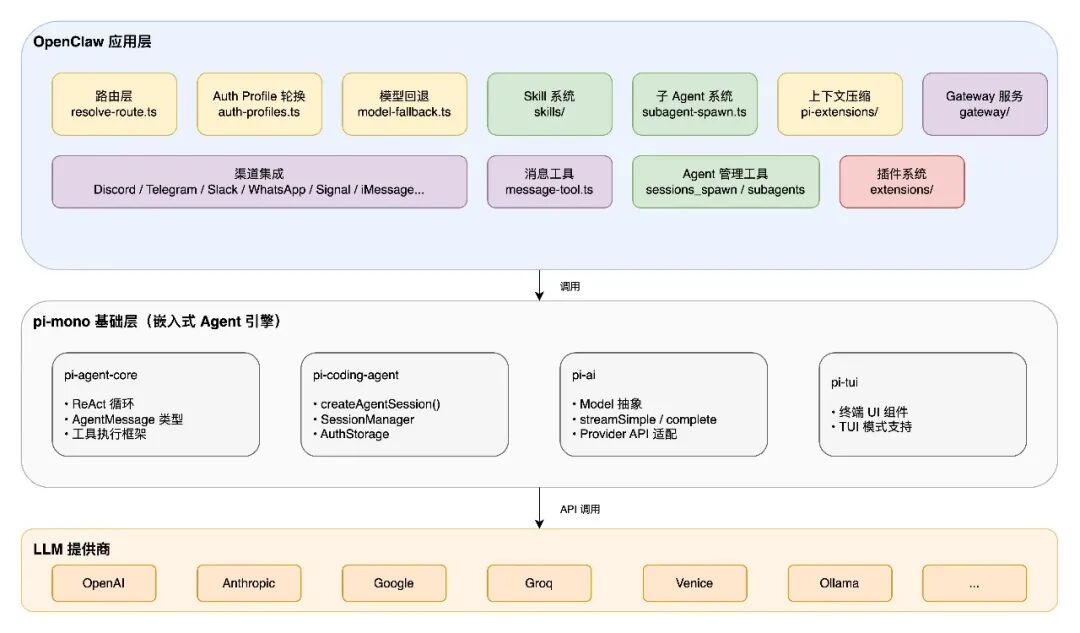
1.2 OpenClaw 与其他架构的区别

OpenClaw 的差异化定位体现在三个层面:
- 基础设施层:基于 pi-mono(嵌入式 Agent 引擎),提供 ReAct 循环、LLM 调用、工具执行等底层能力
- 平台层:在 pi-mono 之上构建路由、容错、认证管理、Skill 系统等生产级能力
- 渠道层:统一消息抽象,让同一个 Agent 可以同时服务于多个通信平台
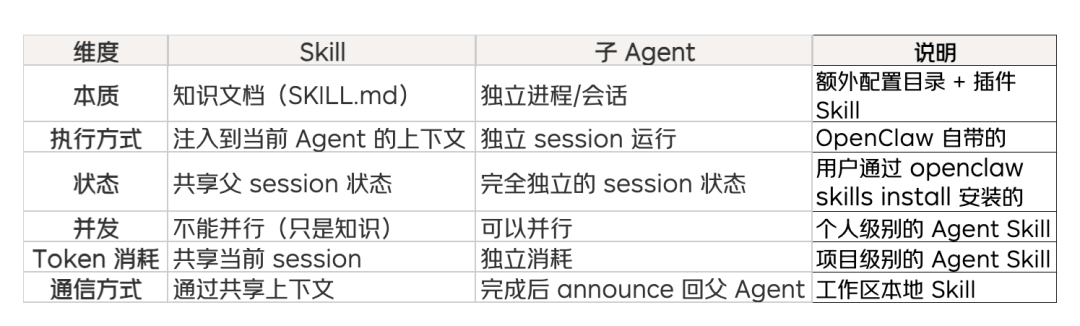
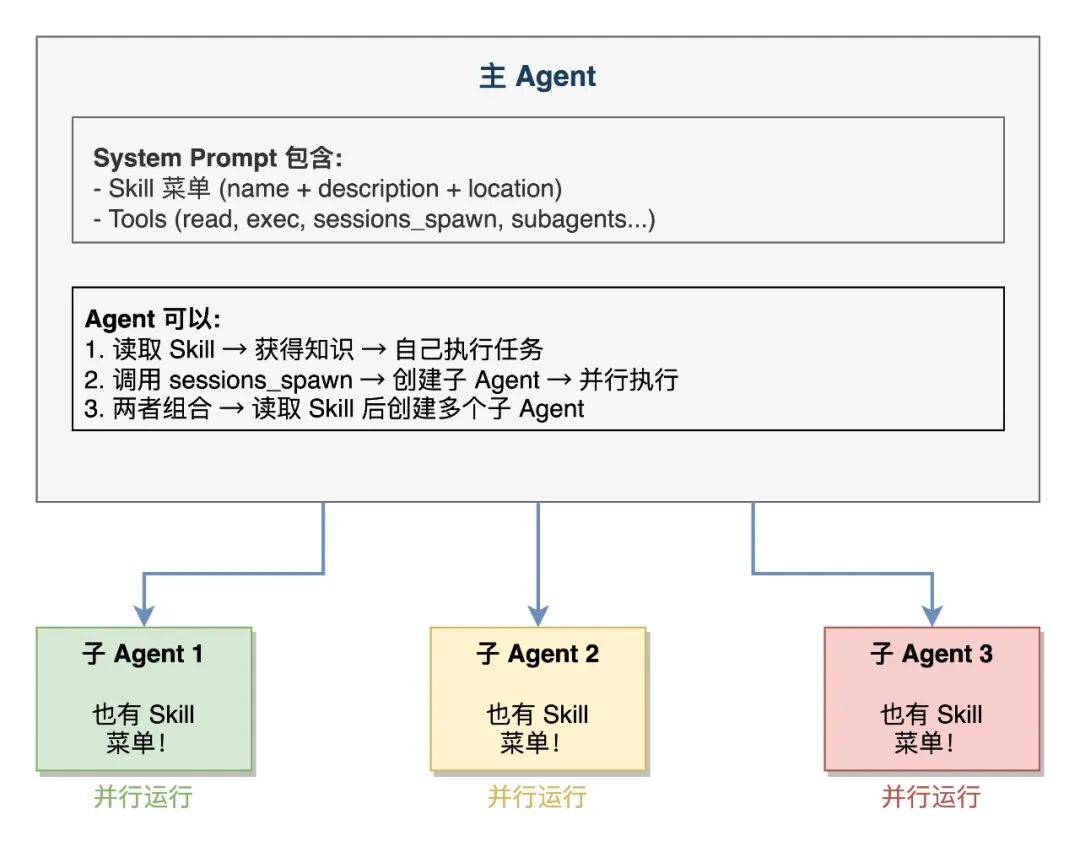
1.3 Agent 与 Skill 的设计理念
OpenClaw 中同时存在两种互补的架构模式:
- Agent + Skill 架构:通过
SKILL.md 文件为 Agent 注入领域知识,就像给一个人发一本操作手册
- 主子 Agent(Subagent)架构:通过创建独立子 Agent 实现并行执行和上下文隔离,就像派出多个助手分头干活
两者不是替代关系,而是互补关系。一个 Agent 可以在读取 Skill 获得知识后,再创建多个子 Agent 并行执行任务;子 Agent 自身也可以使用 Skill。
2. Agent 核心架构
2.1 Agent 执行引擎
OpenClaw 的 Agent 执行引擎是整个系统的核心,负责从接收用户请求到返回 Agent 响应的完整流程。
2.1.1 入口与编排
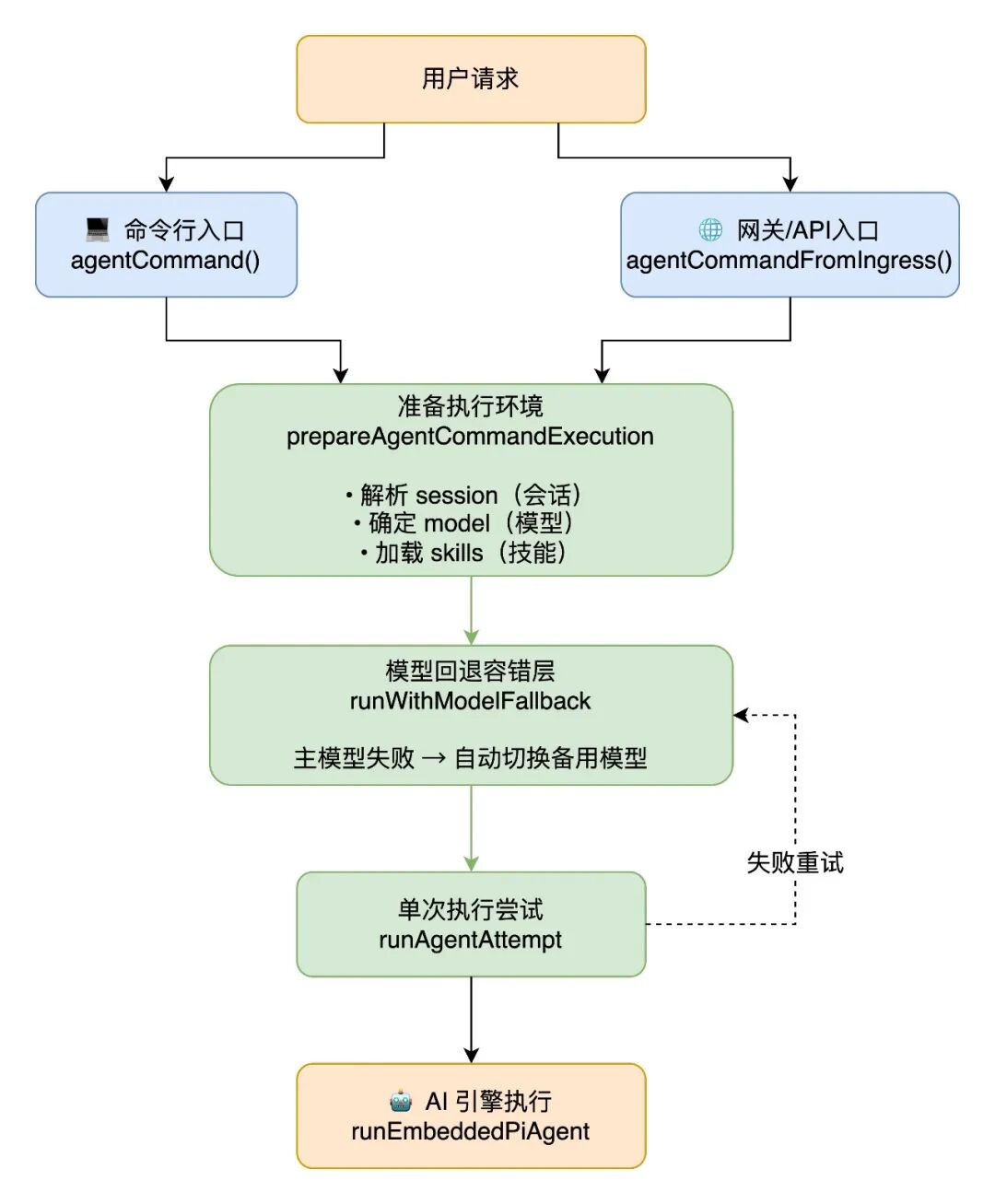
可以把整个执行流程想象成去银行办业务:
- 两个入口,同一套流程:你可以去柜台(命令行),也可以用手机银行(网关/API),但后面办事流程是一样的。
- 准备工作:先查你是谁(
session),决定派哪个柜员帮你(model),看你要办什么业务,准备相关材料(skills)。
- 容错保护层:就像银行的备用柜员制度,1号柜员忙/出问题 → 自动换2号,2号也不行 → 换3号,保证你的业务一定有人办。
- 真正干活:最后由 AI 引擎来处理你的请求。
一句话总结:不管你从哪进来,都走同一条路,而且有“备胎机制”保证服务不中断。
2.1.2 ReAct 循环
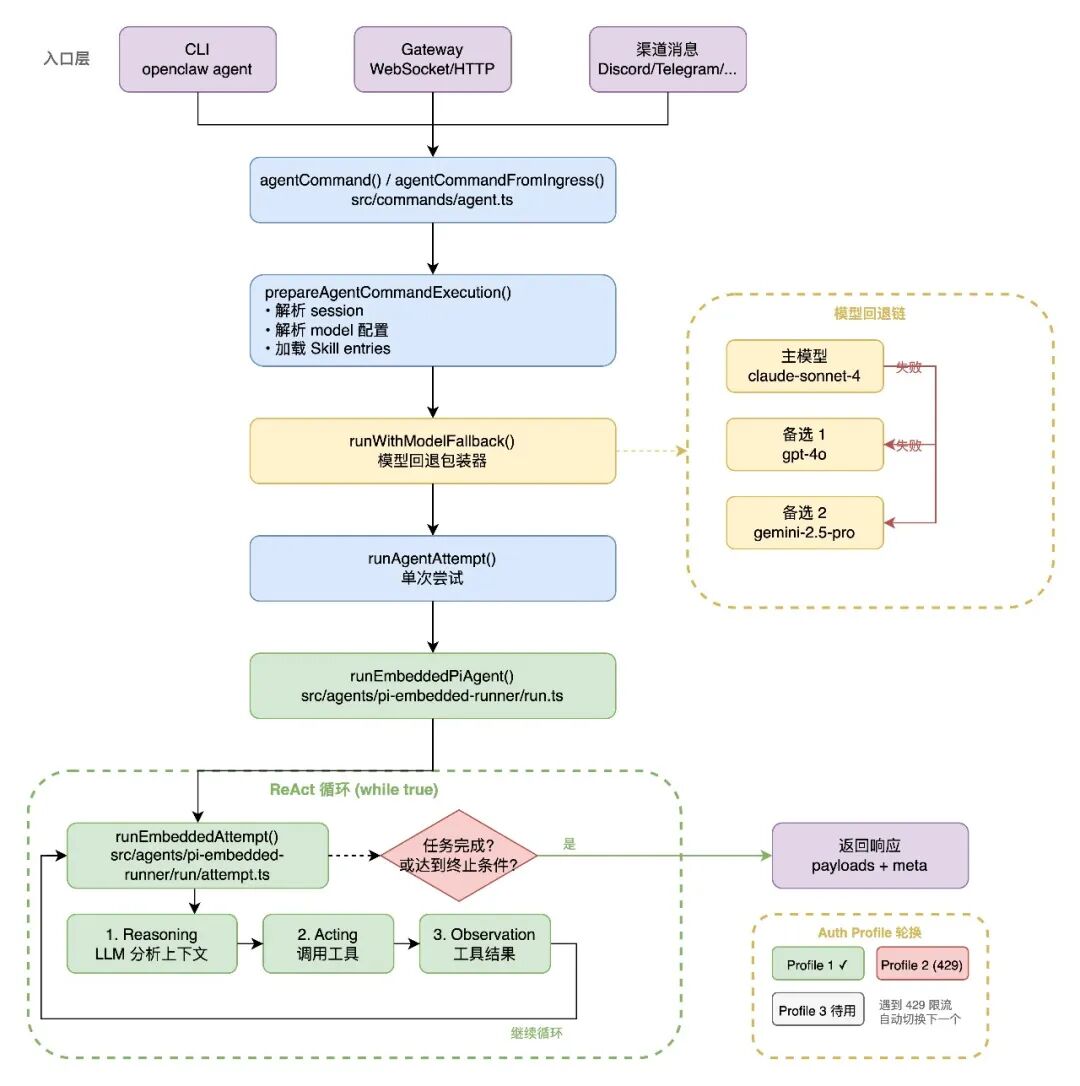
Agent 的核心执行逻辑在 src/agents/pi-embedded-runner/run.ts 中实现。这是一个基于 ReAct范式 的循环:
- Reasoning:LLM 分析当前上下文,决定下一步行动
- Acting:调用工具执行具体操作
- Observation:将工具结果反馈给 LLM
- 重复直到任务完成或达到终止条件
外层运行循环通过 MAX_RUN_LOOP_ITERATIONS 控制最大迭代次数,该值根据可用的 Auth Profile 数量动态缩放。这意味着配置了更多 API Key 的系统拥有更大的重试空间,充分利用多 Profile 轮换的优势。
2.1.3 单次执行尝试
单次执行的尝试(runEmbeddedAttempt)包含以下步骤:
- 准备 workspace 目录
- 加载 Skill entries(复用 snapshot 或重新加载)
- 构建 System Prompt(注入 Skill 菜单、工具说明、身份信息)
- 创建工具集(文件操作、命令执行、消息发送、子 Agent 管理等)
- 调用
pi-coding-agent 完成一次 LLM 对话
- 处理工具调用结果、流式输出、上下文压缩等
2.2 Agent 配置与作用域
每个 Agent 的 workspace 目录决定了它能访问哪些文件、加载哪些 Skill,形成天然的权限边界。子 Agent 管理等功能是 subagents steer(重定向子 Agent)和 subagents kill(终止子 Agent)操作的底层支撑。
下图展示了从用户请求进入、经过路由匹配、模型解析、ReAct 循环执行、工具调用、到最终响应返回的完整调用链。包含 runWithModelFallback 的回退逻辑和 runEmbeddedAttempt 的内部步骤。
3. Skill 机制详解
3.1 Skill 是什么
Skill 是以 SKILL.md 文件形式存在的知识/指令包,告诉 Agent “如何做某类事情”。它不是可执行代码,而是一份结构化的操作指南。项目中内置约 50+ 个 Skill,涵盖开发工具、知识管理、通信平台等多个领域。
3.2 Skill 的加载机制
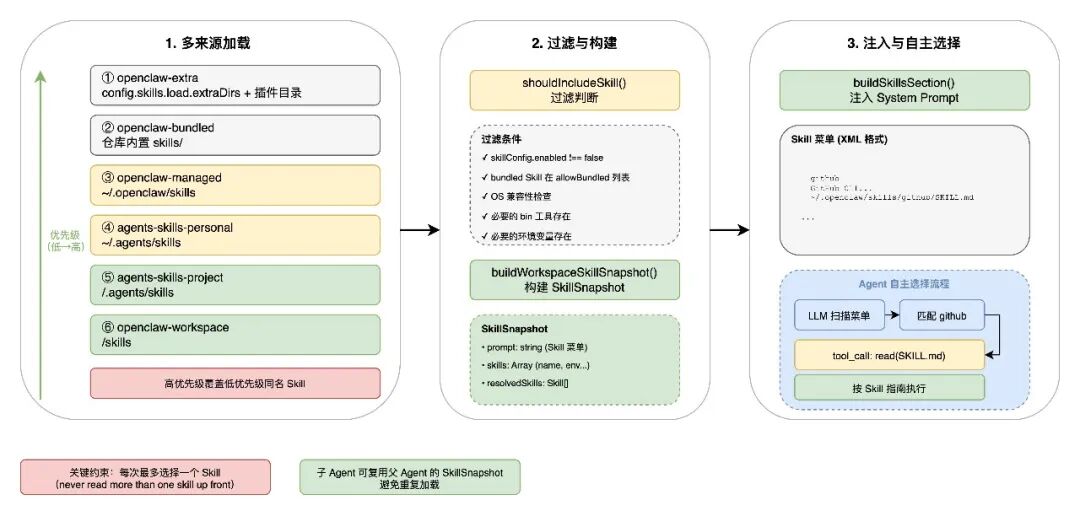
3.2.1 多源加载
Skill 的加载由 src/agents/skills/workspace.ts 中的 loadSkillEntries() 负责,它从 6 个来源 按优先级合并:
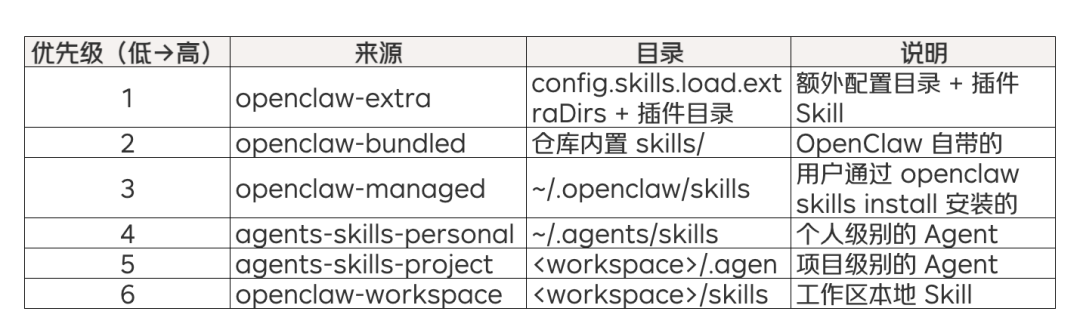
高优先级来源会覆盖低优先级的同名 Skill。例如,项目级的 github Skill 会覆盖内置的 github Skill。
3.2.2 内置 Skill 目录解析
src/agents/skills/bundled-dir.ts 负责定位内置 Skill 目录,按以下顺序查找:
- 环境变量
OPENCLAW_BUNDLED_SKILLS_DIR(优先级最高)
- 可执行文件同级的
skills/ 目录(适用于 bun --compile 构建)
- 从包根目录向上查找包含
SKILL.md 的 skills 目录
3.2.3 插件 Skill
src/agents/skills/plugin-skills.ts 从已启用的插件中收集 Skill 目录。每个插件通过 openclaw.plugin.json 的 skills 字段声明自己提供的 Skill 路径。安全检查确保路径必须在插件根目录内。
3.2.4 过滤与资格判断
并非所有加载的 Skill 都会出现在 Agent 的可用列表中。src/agents/skills/config.ts 中的 shouldIncludeSkill() 执行多层过滤:
- 配置禁用:
skillConfig.enabled === false → 排除
- 内置白名单:
bundled Skill 需在 allowBundled 列表中
- 运行时资格:检查 OS 兼容性、必要的二进制工具、必要的环境变量等
3.2.5 数量限制
src/config/types.skills.ts 中定义了 Skill 的各种限制参数:
SkillsLimitsConfig = {
maxCandidatesPerRoot?: number; // 每个来源目录的最大候选数
maxSkillsLoadedPerSource?: number; // 每个来源的最大加载数
maxSkillsInPrompt?: number; // Prompt 中的最大 Skill 数
maxSkillsPromptChars?: number; // Prompt 中 Skill 段的最大字符数
maxSkillFileBytes?: number; // 单个 SKILL.md 文件的最大字节数
}
3.3 Skill 选择与执行
菜单注入(System Prompt):
所有符合条件的 Skill 的摘要信息会被注入到 Agent 的 System Prompt 中,而非完整内容。src/agents/system-prompt.ts 中的 buildSkillsSection() 负责这个过程。注入到 Prompt 中的 Skill 菜单包含 name、description、location,不包含 SKILL.md 的完整内容,有效控制了 Token 消耗。
Agent 自主选择机制:
Skill 的选择是 Agent(LLM)自主完成的,不是系统硬编码的规则匹配。整个过程是正常的多轮对话:
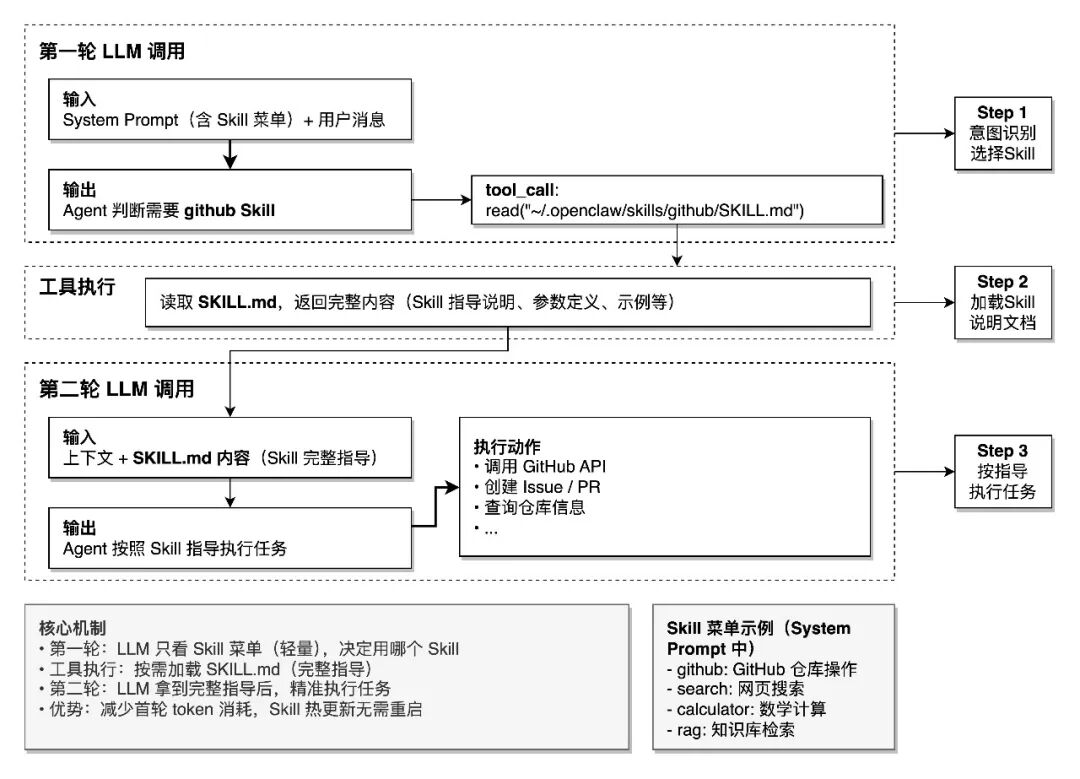
关键约束:never read more than one skill up front——每次最多选择一个 Skill,避免不必要的 Token 消耗。
buildWorkspaceSkillSnapshot() 将 Skill 加载结果封装为 SkillSnapshot:
SkillSnapshot = {
prompt: string; // 生成的 Skill 菜单 Prompt
skills: Array<{
name: string;
primaryEnv?: string; // 主要环境变量
requiredEnv?: string[]; // 必需的环境变量
}>;
skillFilter?: string[]; // Agent 级别的过滤规则
resolvedSkills?: Skill[]; // 已解析的 Skill 对象
version?: number; // 快照版本号
};
子 Agent 启动时可以复用父 Agent 的 SkillSnapshot,避免重复加载。src/agents/pi-embedded-runner/skills-runtime.ts 中的判断逻辑很清晰。
4. 主子 Agent(Subagent)架构
4.1 子 Agent 的设计动机
在以下场景中,单个 Agent 处理所有任务并不高效:
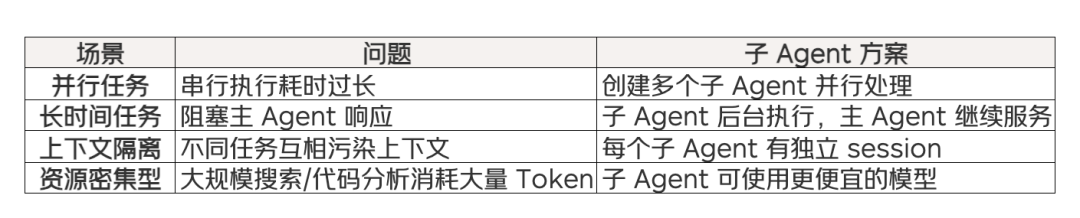
创建子 Agent 是主 Agent 主动决定的,不是系统自动触发。Agent(LLM)根据任务复杂度自行判断是否需要创建子 Agent。
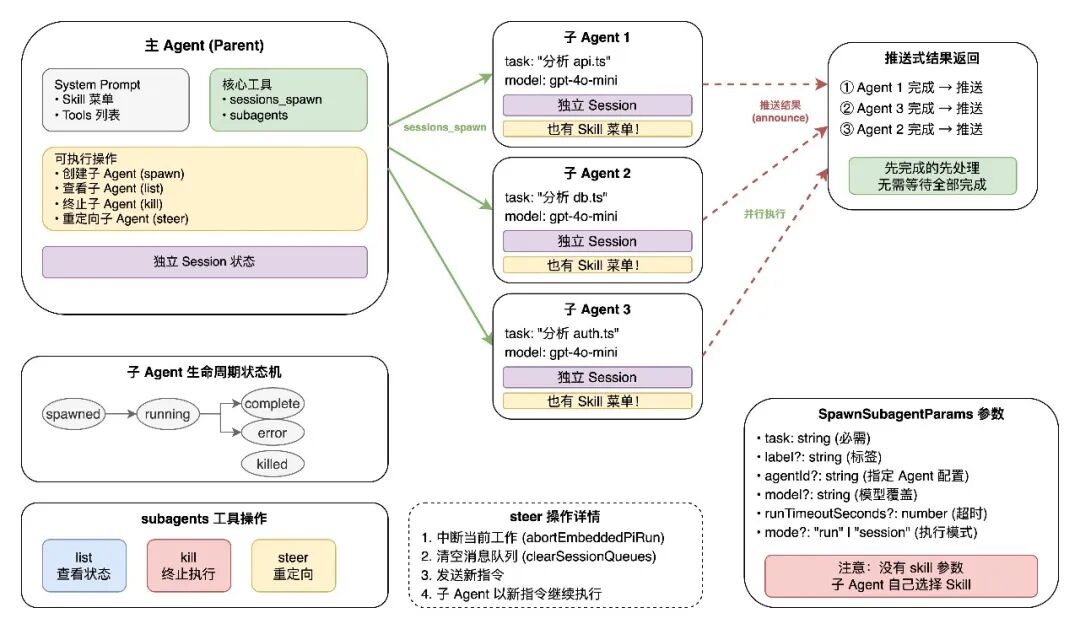
4.2 子 Agent 创建机制
sessions_spawn工具:
子 Agent 通过 sessions_spawn 工具创建(定义在 src/agents/tools/sessions-spawn-tool.ts)。
SpawnSubagentParams 参数:
SpawnSubagentParams = {
task: string; // 必需:任务描述
label?: string; // 可选:标签(用于识别)
agentId?: string; // 可选:指定使用哪个 Agent 配置
model?: string; // 可选:模型覆盖
thinking?: string; // 可选:思考级别
runTimeoutSeconds?: number; // 可选:超时时间
thread?: boolean; // 可选:绑定到消息线程
mode?: "run" | "session"; // 可选:一次性执行 or 持久会话
cleanup?: "delete" | "keep"; // 可选:结束后清理策略
sandbox?: "inherit" | "require"; // 可选:沙箱模式
expectsCompletionMessage?: boolean; // 可选:是否期望完成消息
attachments?: Array<{...}>; // 可选:附件
};
注意这里没有 skill 或 skillFilter 参数——子 Agent 的 Skill 选择是自主的。
创建模式:
mode: “run”(默认):一次性执行,完成任务后自动结束。适合明确的单次任务。mode: “session”:创建持久会话,可以多次交互。适合需要迭代的复杂任务。
创建流程:
spawnSubagentDirect() 的核心流程:
- 校验参数:验证
agentId 格式、thread/mode 兼容性、sandbox 权限
- 深度检查:检查
spawnDepth 是否超过 maxSpawnDepth,防止无限递归
- 子 Agent 数量检查:检查
maxChildren 限制
- 创建 child session:生成唯一的
childSessionKey
- 注册运行:通过
registerSubagentRun 记录到注册表
- 异步执行:调用 Gateway 的
agent 方法启动子 Agent
- 触发 Hook:发出
subagent_spawned 事件
4.3 子 Agent 生命周期
状态追踪:
src/agents/subagent-registry.ts 维护所有子 Agent 的运行记录,核心数据结构为 subagentRuns: Map<string, SubagentRunRecord>。它提供了丰富的查询和管理 API:
registerSubagentRun(params):注册新的子 AgentlistSubagentRunsForRequester(sessionKey):列出某个父 Agent 的所有子 AgentcountActiveRunsForSession(sessionKey):统计活跃子 Agent 数量markSubagentRunTerminated(runId, reason):标记终止releaseSubagentRun(childSessionKey):释放资源
注册表还具备持久化能力:子 Agent 记录会保存到磁盘,系统重启后通过 restoreSubagentRunsFromDisk() 恢复未完成的工作。
生命周期事件:
子 Agent 的生命周期通过以下事件(src/agents/subagent-lifecycle-events.ts)来表示:
export const SUBAGENT_ENDED_REASON_COMPLETE = "subagent-complete"; // 正常完成
export const SUBAGENT_ENDED_REASON_ERROR = "subagent-error"; // 执行出错
export const SUBAGENT_ENDED_REASON_KILLED = "subagent-killed"; // 被主动终止
export const SUBAGENT_ENDED_REASON_SESSION_RESET = "session-reset"; // session 被重置
export const SUBAGENT_ENDED_REASON_SESSION_DELETE = "session-delete"; // session 被删除
这些事件会被转化为结果回传给父 Agent。
推送式结果返回:
OpenClaw 采用逐个推送而非统一返回的方式处理子 Agent 结果。runSubagentAnnounceFlow() 负责这个过程:
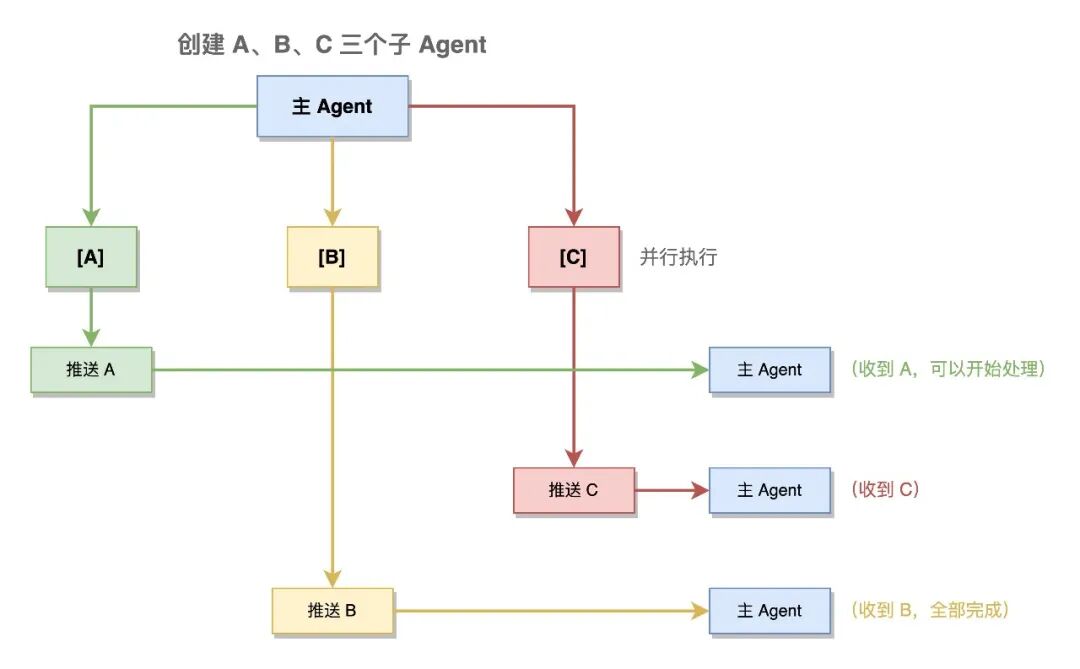
推送式返回的优势:
- 提前处理:无需等待所有子 Agent 完成,先完成的先处理
- 提前终止:发现答案后可以
kill 其余子 Agent,节省资源
- 渐进式反馈:用户可以看到逐步的进度
- 部分失败处理:某个子 Agent 失败时可以立即补救,不影响其他
- 精细超时:每个子 Agent 独立超时,互不影响
4.4 主 Agent 对子 Agent 的管理
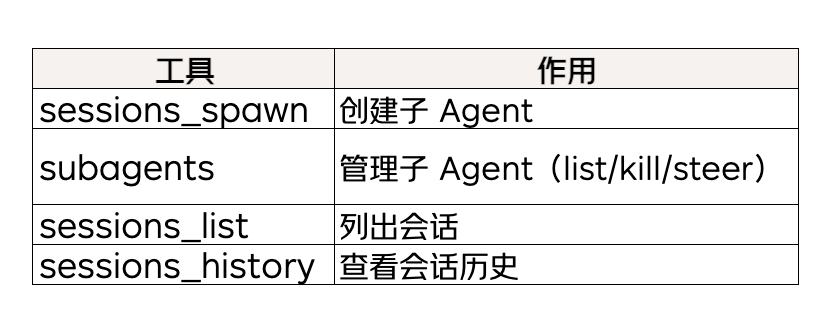
主 Agent 通过 subagents 工具管理子 Agent:
list:查看状态
列出所有活跃和近期完成的子 Agent,包括运行状态、标签、模型等信息。
kill:终止执行
target=具体标签/ID:终止指定子 Agenttarget=all 或 target="*":终止所有子 Agent
steer:重定向(核心容错机制)
当子 Agent 方向偏离或卡住时,主 Agent 可以通过 steer 重新指挥。
Steer 的执行步骤:
- 中断当前工作:调用
abortEmbeddedPiRun() 中止子 Agent 当前执行
- 清空队列:清除子 Agent 的待处理消息队列
- 等待停止:确认子 Agent 已完全停止
- 发送新指令:向子 Agent 注入新的任务描述
- 重新开始:子 Agent 以新指令继续执行
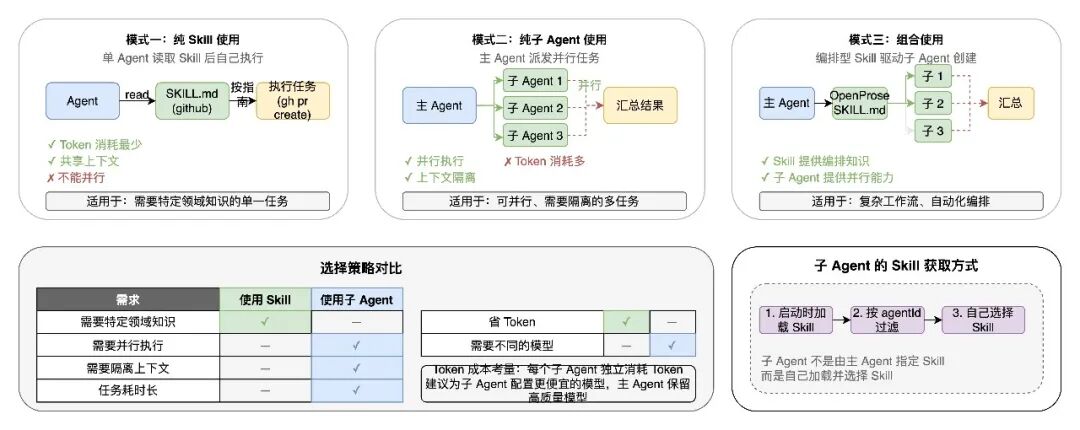
5. Skill 与子 Agent 的协作
5.1 两者的互补关系
Skill 和子 Agent 在 OpenClaw 架构 中扮演不同但互补的角色:
5.2 子 Agent 的 Skill 获取
子 Agent 不是由主 Agent 指定 Skill,而是自己加载并选择 Skill:
- 子 Agent 启动时,根据自己的
workspace 加载所有 Skill
- 根据
agentId 对应的 skills 配置过滤
- 生成自己的 Skill 菜单注入到 System Prompt
- 自行决定使用哪个 Skill
通过配置可以限制不同 Agent 的 Skill 范围:
{
agents: {
list: [
{
id: "research-bot",
skills: ["web-research", "summarize"] // 只允许这两个 Skill
},
{
id: "code-bot",
skills: ["github", "coding-agent"] // 只允许这两个 Skill
}
]
}
}
5.3 组合使用场景
编排型 Skill:
某些 Skill(如 OpenProse)本身会指导 Agent 创建子 Agent:
用户: prose run my-workflow.prose
↓
主 Agent 扫描 Skill 菜单 → 匹配到 OpenProse Skill
↓
主 Agent 读取 OpenProse SKILL.md → 获得 workflow 编排指南
↓
OpenProse Skill 指导 Agent 创建多个子 Agent 执行 workflow
↓
子 Agent 1: 执行 step-1 子 Agent 2: 执行 step-2
在 OpenClaw 项目约 50+ 个 Skill 中,绝大多数(50+ 个)是纯知识型的,编排型 Skill 是特例。
5.4 选择策略指南
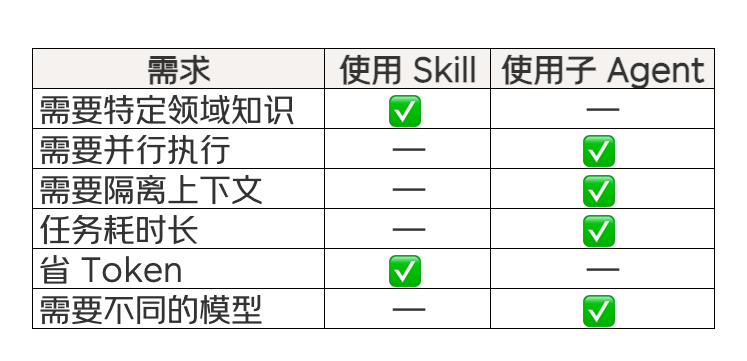
Token 成本考量:每个子 Agent 都有独立的上下文和 Token 消耗。对于重复性或密集型任务,建议为子 Agent 配置更便宜的模型,主 Agent 保留高质量模型。
6. 容错与可靠性机制
OpenClaw 在 pi-mono 基础引擎之上构建了多层容错机制,确保 Agent 在面对各种故障时能够自动恢复。
6.1 错误分类与识别
系统首先将来自 20+ LLM 提供商的不同错误格式统一标准化为以下类型:
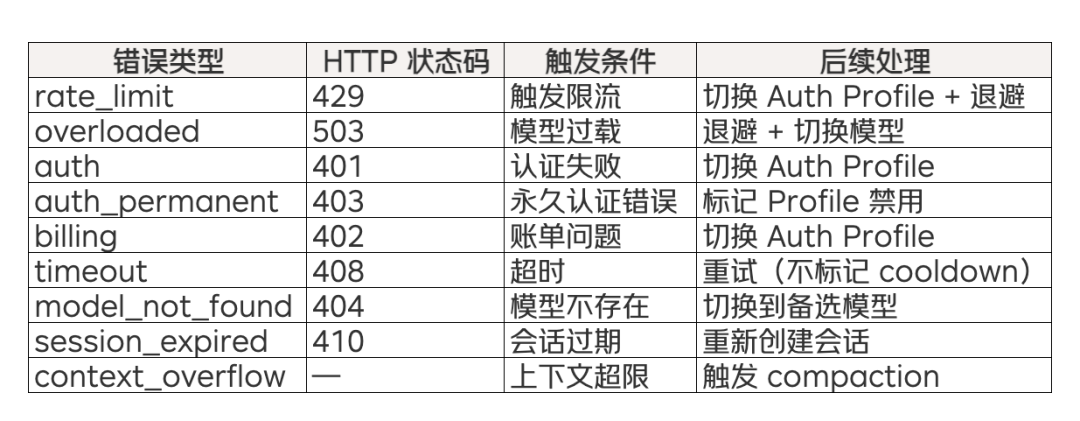
这套分类机制将临时故障(可重试)和永久故障(需要切换或人工干预)清晰地区分开来,为后续各层容错策略提供决策依据。
6.2 认证熔断器
OpenClaw 支持配置多个 API Key / Auth Profile,通过熔断器模式管理其健康状态:
- 健康追踪:记录每个 Profile 的成功/失败历史
- 自动轮换:当前 Profile 失败时(如 429 限流),自动切换到下一个
- 熔断保护:对已知失败的 Profile 暂停请求,防止重复失败
- 渐进恢复:通过探测机制检测 Profile 是否恢复正常
run.ts 中的 advanceAuthProfile() 是轮换的核心逻辑,当遇到认证相关错误时切换到下一个可用 Profile。
6.3 模型回退
当主模型不可用时,系统按照配置的回退链自动切换:
主模型(如 claude-sonnet-4-20250514)
│ 失败
▼
备选模型 1(如 gpt-4o)
│ 失败
▼
备选模型 2(如 gemini-2.5-pro)
│ 失败
▼
报告错误
回退链在 AgentConfig.model.fallbacks 中配置,runWithModelFallback() 负责执行。回退是跨提供商的——可以从 Anthropic 回退到 OpenAI 再到 Google,实现多提供商冗余。
6.4 上下文恢复
当对话历史过长导致上下文窗口溢出时,系统自动执行压缩:

系统最多尝试 3 次 compaction,如果仍然溢出,还会尝试截断工具结果。
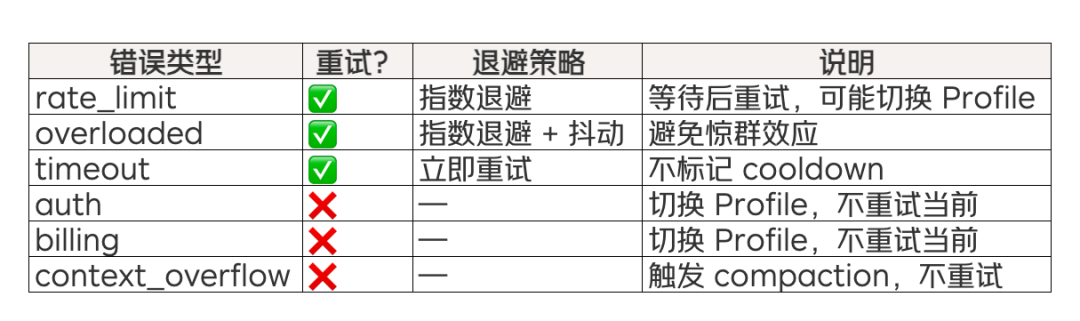
6.5 智能重试策略
对临时性故障使用指数退避 + 抖动策略,避免“惊群效应”:
const OVERLOAD_FAILOVER_BACKOFF_POLICY: BackoffPolicy = {
initialMs: 250, // 初始延迟 250ms
maxMs: 1_500, // 最大延迟 1.5s
factor: 2, // 指数因子(250 → 500 → 1000 → 1500)
jitter: 0.2, // 20% 随机抖动,分散请求
};
const DEFAULT_RETRY_CONFIG = {
attempts: 3, // 最多 3 次
minDelayMs: 300, // 最小延迟 300ms
maxDelayMs: 30_000,// 最大延迟 30s
jitter: 0, // 默认无抖动
};
不同错误类型采取不同策略:
6.6 容错层级总结
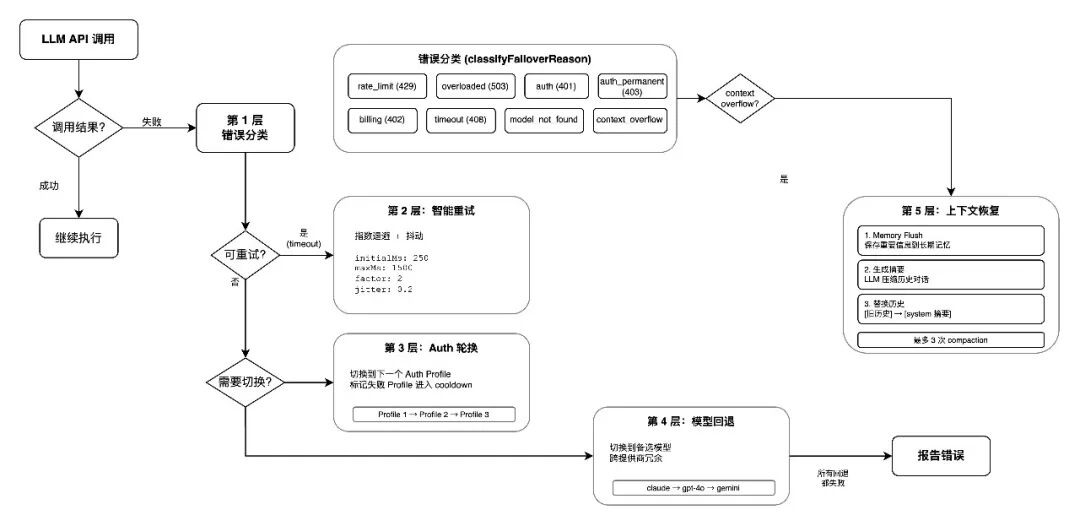
整个容错体系形成五层防御:
第 1 层:错误分类 → 统一识别错误类型
第 2 层:智能重试 → 临时故障自动重试
第 3 层:Auth 轮换 → API Key 级别的故障转移
第 4 层:模型回退 → 模型/提供商级别的故障转移
第 5 层:上下文恢复 → 上下文溢出时自动压缩
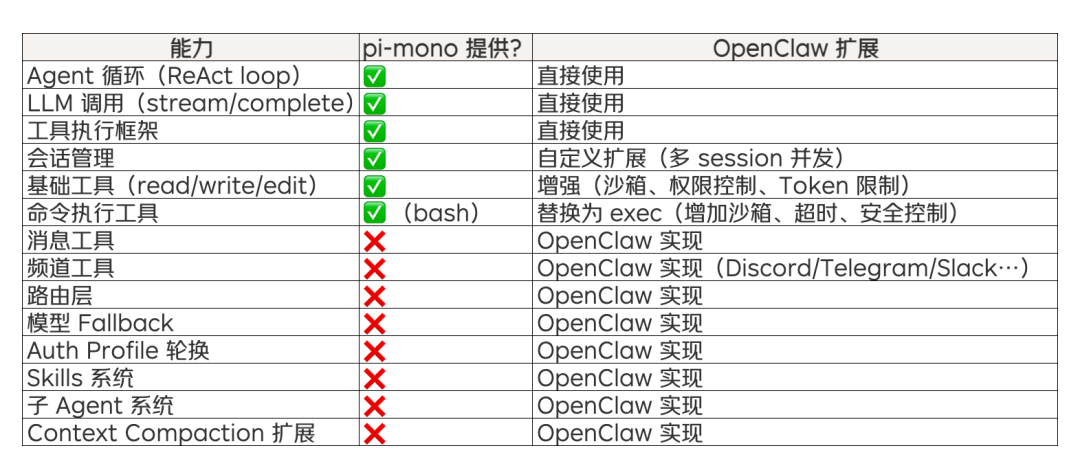
7. OpenClaw 与 pi-mono 的关系
OpenClaw 并非从零构建 Agent 引擎,而是基于 pi-mono 这个嵌入式 Agent 基础包进行扩展。理解两者的边界有助于把握系统的整体架构。
7.1 pi-mono 提供的基础能力
pi-mono 由多个子包组成:

pi-mono 提供了一个功能完备的 Agent 引擎,但它主要面向单用户、单 session、请求-响应的场景。
7.2 OpenClaw 的扩展与定制
OpenClaw 在 pi-mono 之上构建了生产级的扩展层:
7.3 架构分层
pi-mono 提供单用户、单 session、请求-响应模式的 Agent 引擎,OpenClaw 在其上构建多用户、多 session、多渠道的生产级扩展。
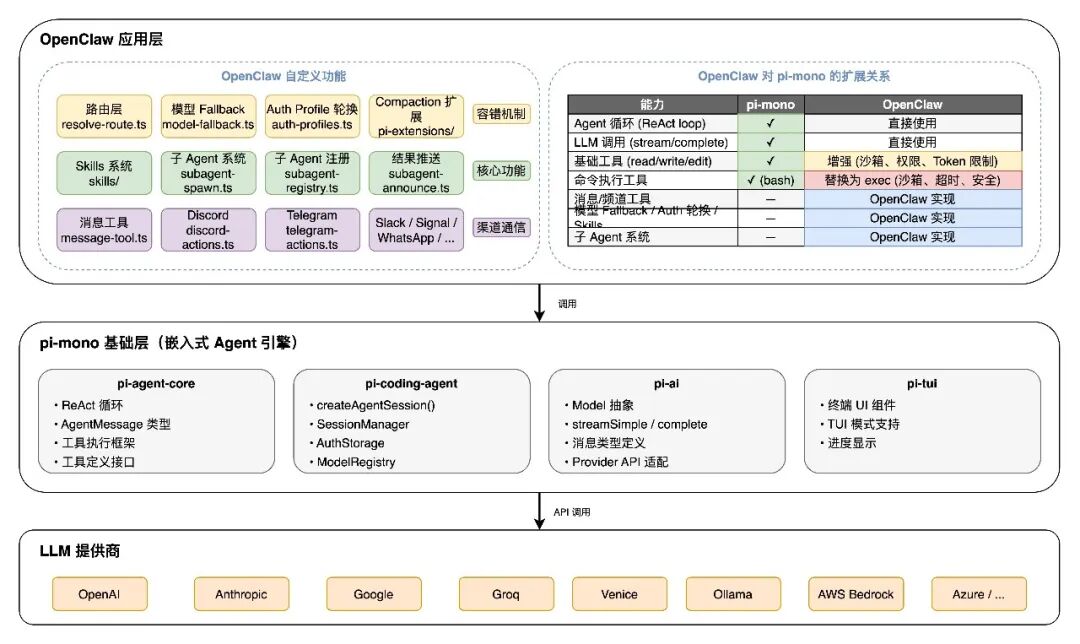
8. 工具系统
8.1 核心工具分类
OpenClaw Agent 的工具分为四大类:
(1)文件工具(来自 pi-mono,被 OpenClaw 增强)

(2)命令执行工具(OpenClaw 替换 pi-mono 的 bash)

(3)消息与频道工具(OpenClaw 独有)
使 Agent 能够与外部通信平台交互,是 OpenClaw 多渠道能力的具体体现。
(4)Agent 管理工具(OpenClaw 独有)
8.2 工具权限策略
src/agents/pi-tools.policy.ts 定义了子 Agent 的工具权限策略,通过两级拒绝列表实现:
所有子 Agent 始终禁止的工具
const SUBAGENT_TOOL_DENY_ALWAYS = [
"gateway", "agents_list", "whatsapp_login", "session_status",
"cron", "memory_search", "memory_get", "sessions_send",
];
叶子节点子 Agent(最深层)额外禁止的工具
const SUBAGENT_TOOL_DENY_LEAF = [
"subagents", "sessions_list", "sessions_history", "sessions_spawn",
];
叶子节点判断:当子 Agent 的 spawnDepth >= maxSpawnDepth 时,被视为叶子节点,不能再创建自己的子 Agent,从而防止无限递归。非叶子节点的子 Agent 保留 sessions_spawn 和 subagents 工具,支持多级子 Agent 嵌套。
8.3 自定义工具扩展
插件(extensions/)可以通过 openclaw.plugin.json 注册自定义工具。工具定义遵循统一接口:
type AnyAgentTool = {
label: string; // 显示标签
name: string; // 工具名称(唯一标识)
description: string; // 功能描述(注入 Prompt)
parameters: TSchema; // 参数 Schema
execute: (toolCallId: string, args: unknown) => Promise<ToolResult>;
};
9. 常见问题
Q1: Skill 选择需要额外调用 LLM 吗?
不需要额外调用。Skill 选择是 Agent 在正常多轮对话的第一轮中完成的——Agent 扫描 Skill 菜单,调用 read 工具读取 SKILL.md,这只是普通的工具调用。
Q2: Skill 能并行执行吗?
不能。Skill 是知识文档,不是执行单位。如果需要并行执行,应创建多个子 Agent,每个子 Agent 可以各自使用 Skill。
Q3: 子 Agent 的 Skill 是谁指定的?
子 Agent 自己决定。主 Agent 通过 sessions_spawn 只传递 task(任务描述),子 Agent 启动后自行加载和选择 Skill。可以通过 agents.list[].skills 配置限制某个 Agent 可用的 Skill 范围。
Q4: 子 Agent 之间能互相通信吗?
不能直接通信。子 Agent 的结果通过 announce 机制推送给父 Agent,由父 Agent 做信息中转。这种设计保持了架构的简洁性和可预测性。
Q5: 子 Agent 报错后怎么办?
父 Agent 会收到错误通知(subagent-error 事件),可以通过 subagents 工具进行补救:kill 终止后重新 spawn,或使用 steer 发送新指令让子 Agent 换个方向继续。
Q6: 系统支持多少层子 Agent 嵌套?
由 maxSpawnDepth 配置决定(默认值在 DEFAULT_SUBAGENT_MAX_SPAWN_DEPTH)。达到最大深度的子 Agent 成为叶子节点,不能再创建子 Agent。
10. 结语
OpenClaw 的架构设计紧密围绕生产级 AI Agent 系统的实际需求展开。其核心创新在于清晰地区分了 Skill(知识) 与 子 Agent(执行单元) 两种扩展模式,并通过多层容错、多渠道集成、灵活的权限与配置体系将它们有机结合。这种设计使得系统既能通过 Skill 快速赋予 Agent 新能力,又能通过子 Agent 实现复杂的并行与编排任务,同时保证了整个系统在面对真实环境中的各种故障时的高度鲁棒性。希望这篇深入的技术解析,能为致力于构建复杂 AI Agent 应用的开源开发者与架构师们提供有价值的参考。欢迎在 云栈社区 与我们进一步探讨。
 发表于 2026-4-16 23:00:36
|
查看: 238|
回复: 0
发表于 2026-4-16 23:00:36
|
查看: 238|
回复: 0
