之前在群里看到有人讨论“记忆就是蒸馏”,本想简单聊两句,结果越写越长,索性整理成文。今天想聊聊智能体记忆系统(Agent Memory)的真正核心,它不是简单的存储,而是一套复杂的治理工程。
要理解记忆系统,首先要明确一个现状:如今大模型在单次对话中已经足够聪明。真正的问题在于,它无法以一种可靠、可更新、可追溯的方式,将过去学到的东西带到当下的对话中。
举个例子:一个数据分析智能体第一次对话时得知你偏好 Plotly,第五次推断出你真正关注的是留存率而非 DAU,第二十次则积累了足够信号,判断你的汇报对象是一位重视 ROI 叙事的副总裁。这三层理解——工具偏好、业务焦点、沟通语境——每一层都需要不同的时间尺度才能浮现。没有记忆系统,智能体永远只能停留在第一次对话的水平。
请记住:上下文窗口的扩展(128K、200K、1M)解决的是带宽问题,而非建模问题。将过去50次对话全塞进提示词(prompt),模型面对的是一个巨大且未经结构化的信号场,它需要同时完成“记忆检索”和“任务执行”这两个正交的认知负载。已有基准测试证实,在35个会话、300个对话轮次的尺度上,长上下文和 RAG 在时间推理、长程一致性方面仍明显落后于人类。
因此,记忆正从一个附加功能,演变为Agent架构的核心子系统——一个完整的 写入 (write) – 管理 (manage) – 读取 (read) 闭环,而不仅仅是“有个存储层”。
先划清边界:Memory 不是什么?
谈论记忆系统之前,必须厘清它与几个易混淆概念的职责边界。
Memory 与 State 职责不同。State 是当前会话内的短期运行态:对话上下文、工具调用的中间结果、规划器的当前步骤。会话结束,State 即销毁。Memory 是跨会话持续存在、可影响未来决策的结构化历史。实践中二者偶有交叉,但设计上解决的是不同时间尺度的问题。
Memory 与 Policy 不应等同。Policy 管理的是“允许与禁止”——权限边界、安全规则、合规约束。它是系统的外部规范,通常不应被记忆系统动态修改。如果 Agent 的记忆能改写自己的权限规则,那不是进化,是越权。
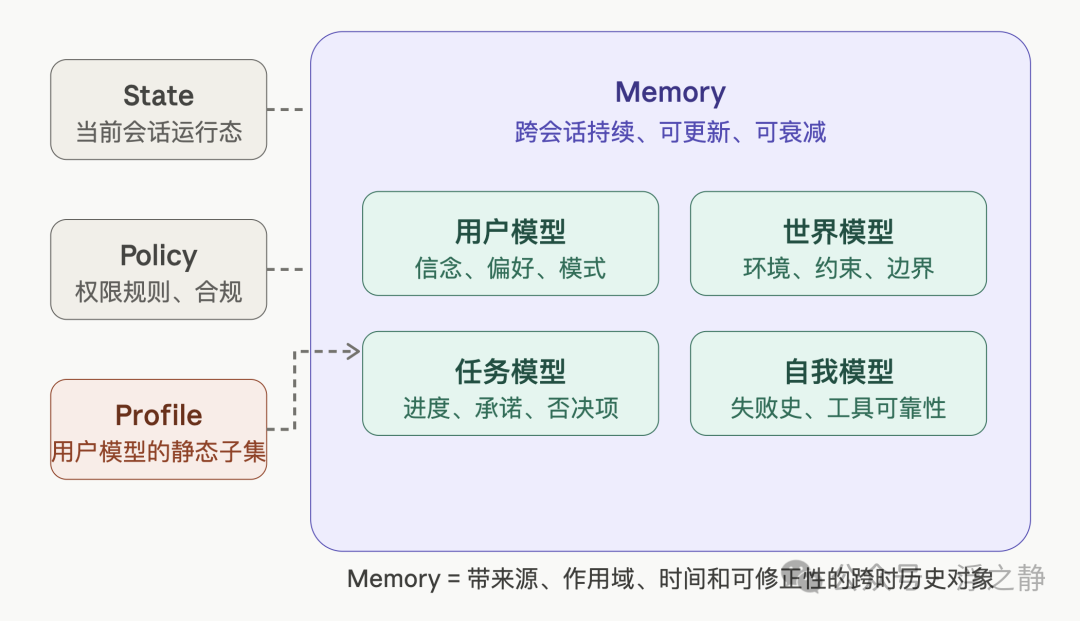
Memory 与 Profile 是包含关系。Profile 是用户模型的一个低维、显式、便于消费的快照层——如名字、角色、偏好标签。它是记忆的输出产物,而非记忆本身。将 profile 等同于 memory,就像把一张名片等同于你对一个人的全部理解。
一句话定义:Memory 保存的是可跨时延续并影响未来决策的结构化历史——所谓“结构化”,指的是带来源、作用域、时间权重和可修正性的历史对象,而不仅仅是“把聊天记录再存一份”。 这条边界划清了,后面的讨论才有意义。
蒸馏只是管道的一步
许多人将“蒸馏”和“记忆”混用,也有人将其完全对立,这两种理解都有偏差。
摘要 (summary)、反思 (reflection)、会话总结 (session summary)——这些都是有用的技术动作,但它们更准确的身份是 记忆管道 (memory pipeline) 中管理环节的一个操作,而不是记忆本身。就像压缩是通信系统的一步,但你不能说“压缩 = 通信”。
蒸馏的根本局限不在于“做了压缩”,而在于它天然偏向静态结论。一条摘要能写下“用户偏好 TypeScript”,却很难保留这条偏好是如何形成的、在什么上下文下成立、最近是否正在漂移。它擅长留下结论,不擅长留下形成结论的轨迹。而对生产级 Agent 来说,轨迹往往比结论更有价值——你要的不只是“知道他喜欢什么”,而是“理解他在什么条件下会改主意”。
结论是:蒸馏试图把过去变成一句话,而记忆试图把过去变成一个还能继续更新的模型。蒸馏在管理链路中有其位置,但如果一个系统做完摘要就停止,没有后续的冲突检测、信念衰减、回溯修正,那它只是在做归档,而非真正的记忆。
四个核心建模对象
“记忆就是记住用户偏好”——这个方向没错,但只覆盖了四分之一。一种高价值的划分方式,是将记忆的建模对象分为四类:
- 用户模型:偏好、风险偏好、沟通习惯、决策模式。例如,用户从“抵触 TypeScript” 到“逐渐接受”再到“主动要求重写”——这个转变轨迹本身就是高价值信号。
- 任务模型:哪些方案被否决过,哪些结论已确认,哪些产出物是当前版本,哪些承诺尚未完成。许多 Agent 失败并非不懂你,而是不记得事情推进到了哪一步。
- 世界模型:操作环境:仓库结构、API 约束、系统边界、组织规则、数据新鲜度。大量“个性化错误”本质上是没记住你所在的环境已经变化。
- 自我模型:尝试过什么、哪条路径失败过、哪个工具在什么场景下不稳定、哪些推断只是暂定假设。没有这层记忆,Agent 不是在学习,只是在重复犯错。
意图 (intent) 并非单独存储在某个字段里。它是这四层模型长期耦合后浮现出来的上层能力——就像一个跟了你三年的助理,他“懂你”不是因为背了一本偏好手册,而是因为他同时理解你的脾气、项目进度、组织环境和他自己的能力边界。
基本记忆单元:从字符串到结构化对象
如果记忆不是一句摘要,那它到底是什么?这个问题不回答,系统就没有锚点。
若要将记忆构建为可计算对象,至少需要六个维度:
- 内容:这条记忆具体陈述了什么。例如,“用户在性能和开发体验之间倾向于优先选择性能。”
- 类型:它属于哪一类。建议至少区分五种:事件 (event,发生了什么)、断言 (assertion,用户明确声明了什么)、信念 (belief,Agent 推断出来的)、约束 (constraint,不可违反的边界)、承诺 (commitment,Agent 做出但尚未完成的承诺)。不同类型的更新机制完全不同。
- 置信度:Agent 对这条记忆的确信程度。主要适用于信念和承诺。对于事件和断言,它们的“发生”通常比其“含义是否成立”更确定。
- 来源:这条记忆从何而来。是用户明确表达的、从行为推断的、从环境观察到的,还是 Agent 自己生成的。来源决定了它的可信层级和可撤销性。没有来源追溯 (provenance),Agent 无法区分一条扎实的用户声明和一次自己的高置信度幻觉。
- 作用域:它在什么上下文下成立。“偏好性能优先”可能在后端架构决策中成立,但在前端原型阶段未必。没有作用域,信念就会被过度泛化。
- 时间与衰减:什么时候产生的,上次被确认或引用是什么时候,衰减权重是多少。
将这六个维度固定下来,记忆就从“一堆字符串”变成了可查询、可追溯、可修正、可过期的结构化对象。

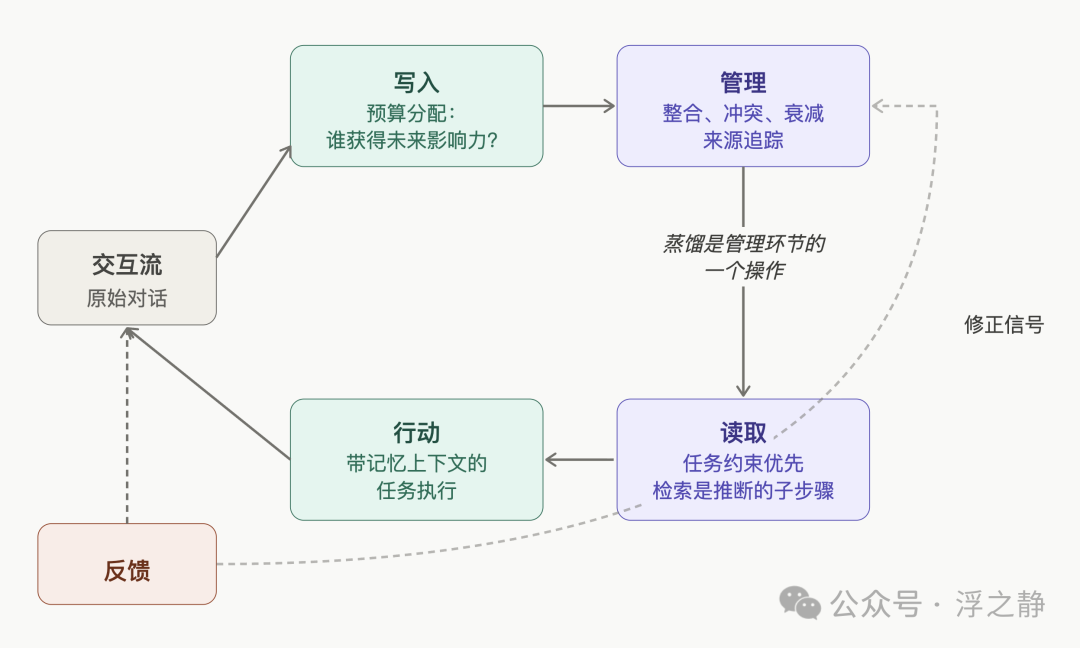
三条核心链路:写入、管理、读取
记忆系统不是一个容器,而是三条链路构成的闭环:写入、管理、读取。
写入链路:预算分配
写入链路最容易被简化为“有价值就存”。但系统设计者必须考虑:存储预算、检索预算、未来注意力都有限——到底什么该存?
因此,记忆写入本质上是一次 有预算约束下的决策。这里的预算不只是存储空间,还包括未来的检索成本、推理时的注意力开销,以及后续的冲突管理代价。在这些约束下,写入要做的是决定:哪些信息值得获得对未来决策的影响力。
这意味着不能只看“这条信息有没有价值”,而要看它相对于已有记忆的边际价值。行为证据通常比口头表态更值得分配写入预算。用户说“我不喜欢 ORM” 是一条断言;而连续三次在你提供 ORM 方案后又手写 SQL,则是可以提炼为信念的行为模式,且后者的来源更坚实。
管理链路:最易被忽视,却最关键
管理链路决定了记忆系统最终会成为资产还是垃圾堆。它至少需要处理五件事:
- 整合:把碎片化的信号聚合成结构化的信念。蒸馏在这里发挥价值,但它只是整合的手段之一。
- 冲突处理:用户在不同时间表达了相反偏好怎么办?“以最新为准”是偷懒的蒸馏思维。更合理的做法是保留矛盾,建模为“此维度上的偏好是情境依赖的”,然后在读取时根据当前情境选择。
- 衰减与遗忘:不能遗忘的系统会被旧判断拖死。遗忘不是缺陷,而是防止系统过拟合现实的必要机制。
- 来源追踪:没有来源追溯,Agent 无法判断自己的信念有多可信,也无法在出错时回溯责任链。
- 权限治理:用户必须能查看、编辑、删除 Agent 关于自己的记忆。这不只是合规要求,更是建立信任的基础。
读取链路:任务约束优先
传统做法是 RAG 式的语义相似度召回。这在记忆场景下有一个根本局限:它假设相关性由表面语义决定。
但真正有价值的记忆调用往往是反直觉的。例如,用户问“帮我写缓存方案”,最相关的记忆可能不是上次讨论缓存的对话,而是三个月前提到的“黑五”流量峰值问题——那条信息决定了设计约束,但在语义空间里跟“缓存”距离很远。
因此,读取应该从语义相似度召回,升级为任务约束驱动的检索-推断耦合。检索没有被取代,而是降级为推断过程的一个子步骤。接口上,这意味着从 retrieve(query) 到 read(task_context, belief_graph) 的转变。
进化 = 修正 + 遗忘
“记忆会进化”这句话容易流于空泛。落到实处,就是两个核心能力:
- 自我修正:当 Agent 基于记忆做出了用户不满意的响应,这个负反馈不应只触发“换一个答案”,而应回溯到记忆层进行诊断和修正。
- 有策略的遗忘:当前基准测试已经开始单独考核选择性遗忘、知识更新、偏好漂移。一个不能遗忘的系统最终一定会被自己的旧判断锁死。
这里有一个更深层的洞察:失效的不是经验本身,而是那些失去了更新机制的经验。Few-shot 示例、摘要、微调后的偏好画像——它们并不天然低级。其真正问题是,一旦脱离了持续校正的闭环,就从资产变成了惯性。
落地判断与未来
不谈宏大叙事,只谈工程现实。当记忆系统足够成熟时,它逼近的目标不是“复制你”,而是在特定任务领域中,近似你的判断风格与约束偏好。这个目标不需要科幻感,它需要的是前述每一层都扎实实现。
回顾整条链路,你会发现每一步的核心问题都是治理:写入决定什么信息获得对未来决策的影响力;管理决定什么信念继续保持有效;读取决定什么记忆真正进入当下决策;遗忘决定什么经验退出舞台。
评测标准也在转向:从“能不能回忆” 到“能不能更新、能不能适时弃权、能不能处理漂移、能不能选择性遗忘”。
记忆系统的难点从来不在容量,而在治理。
拓展阅读与参考资料
如果你想与更多对人工智能和系统架构感兴趣的开发者交流,可以访问云栈社区,那里有更多深入的讨论和资源。
 发表于 2026-4-17 01:08:05
|
查看: 122|
回复: 0
发表于 2026-4-17 01:08:05
|
查看: 122|
回复: 0
