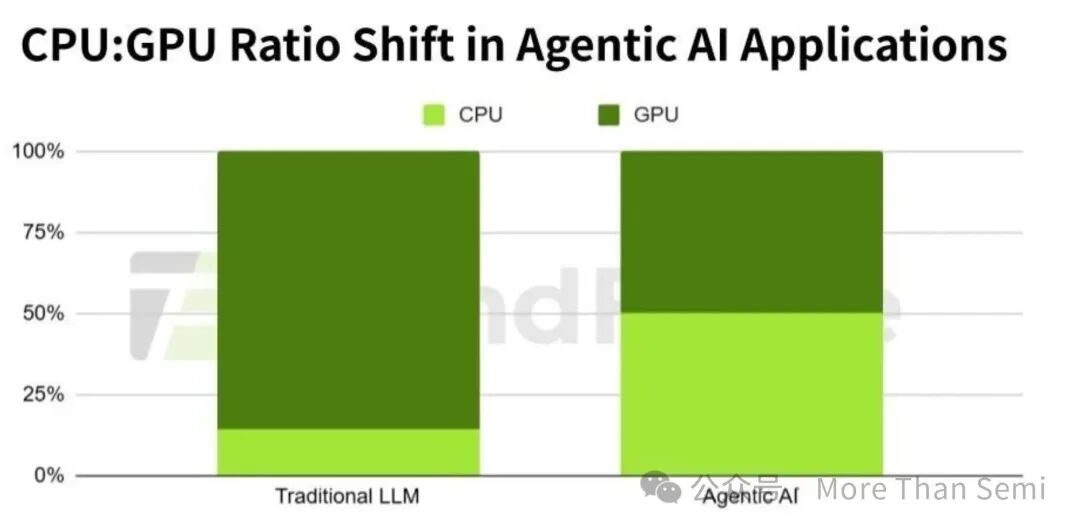
最近一份行业报告指出,Agentic AI 对 CPU 的需求远超预期,正推动 CPU 与 GPU 的比例发生结构性转变,趋向 1:1。
数据中心的架构正在重构
变化的根源在于 AI 应用的形态正在进化。
早期的通用大语言模型交互很简单:用户提问,模型直接生成答案。在这种单向、密集的计算场景下,GPU 确实是绝对的主力。
但如今的 Agentic AI 智能体工作模式完全不同。例如,当你询问“今天上班穿什么”时,它不会凭空想象,而是需要执行一系列链式操作:查询实时天气、定位你所在的城市、或许还要调取你的日程日历,最后综合所有外部信息给出个性化建议。这类调用外部工具、对接多样化 API、处理非结构化数据源的“脏活累活”,恰恰是 CPU 的传统优势领域,GPU 在此环节基本难以插手。因此,现代数据中心的架构开始出现专门为 Agentic 负载设计的 CPU 专用机架,它们不配备 GPU,专门处理这类复杂的逻辑与调度任务。
推理环节的变化同样耐人寻味。大语言模型生成回答通常分为两个阶段。第一阶段是生成第一个 token(解码),计算和内存访问都极为密集,此时 GPU 是主力。
但进入后续 token 的生成阶段,情况就不同了。这个阶段可以进一步拆解:其中的多头注意力机制部分仍由 GPU 负责;而前馈神经网络部分,则开始有专用芯片介入。英伟达收购 Groq 后推出的 LPU(语言处理单元)正是瞄准这一场景。原因很直接:此阶段性能瓶颈往往在于内存带宽。最新的 GPU 采用 HBM4 内存,带宽约为 22TB/秒。而 LPU 由于使用片上 SRAM,带宽可达惊人的 150TB/秒。对于这类内存密集型计算,LPU 的效率优势显著。
传统的 Transformer 架构模型训练和推理,CPU 与 GPU 的典型配比约为 1:4,即一颗 CPU 调度四颗 GPU。现在的逻辑已截然不同:你需要独立的 CPU 机架运行智能体,GPU 机架运行大模型,而每个 GPU 机架可能还需要搭配 2 到 4 个 LPU 机架来处理推理流水线。如果模型像 DeepSeek 那样大量采用混合专家架构,对 LPU 的需求会更高,因为 MoE 本质上由大量并行的前馈网络构成,正是 LPU 的强项。
由此可见,数据中心的硬件构成正从过去的同构化,快速走向复杂的异构计算。
市场叙事与实际部署的差距
英伟达保持着一年一代新品的发布节奏,每次都在推动更复杂的封装、更高的功耗和更昂贵的配套设施。这种节奏看似激进,但实际部署情况可能与市场感知存在差距。
云服务商确实会采购最新的旗舰产品,但这在很大程度上是出于品牌和营销策略——他们需要在产品线中展示拥有最先进的硬件,以实现与竞争对手的差异化。然而,这些顶级配置的实际部署规模,可能远小于我们的想象。真正承担主流工作负载的,往往是上一代甚至更早的硬件。
这其实很合理。云服务商会进行严谨的评估:我的业务是否真的需要最新一代硬件带来的边际性能提升?还是用性价比更高的上一代产品就已足够?毕竟每一代产品的价格涨幅可观,而性能提升并非总是线性的。
甚至出现了一个反直觉的现象:某些云平台上,更新的 B200 实例定价可能比 H100 还要便宜。这看似反常,实则是一种聪明的商业策略。一方面,台积电 CoWoS 封装等产能爬坡,改善了 B200 的供应;另一方面,云厂商通过降低单价来刺激使用量。虽然单价低了,但 B200 在处理最新大模型时能生成更多 token、承载更多请求,用户的总账单反而可能增加。这是一种典型的“以低价引流,靠用量盈利”的策略。
再看自研芯片,除了谷歌的 TPU 形成了生态闭环,其他云厂商的定制化 ASIC 在短期内恐难成气候。一个核心原因是软件迭代的速度太快,专用芯片的灵活性不足。这些厂商的软件算法团队自身的迭代速度,可能已经超过了硬件团队的设计周期。等芯片流片成功,软件需求和模型架构可能又已革新。谷歌 TPU 的成功,得益于其深厚的软硬件协同能力与相对稳定的内部模型需求,其他厂商目前尚不具备同等条件。
训练和推理会并行发展
有一种观点认为,随着推理需求爆发式增长,模型训练的重要性会下降。
但现实可能并非如此。业界有一个基本观察:模型规模越大,往往能涌现出更多、更复杂的智能。尽管其背后的科学原理尚未完全明晰,但经验数据支撑了这一结论。
因此,前沿模型大概率会继续增大规模,对超大规模训练的需求不会消失。英伟达推出的功耗超过 3000 瓦的 Kyber 架构芯片,正是为这种极限训练场景准备的。
与此同时,另一条提高能效的路线也在并行发展。像 DeepSeek 这样的团队,在算力受限的情况下,转而从算法层面进行深度优化,广泛采用混合专家等技术创新来提升效率。人脑的功耗仅为 50 到 150 瓦,而当今的大型 AI 数据中心功耗已达兆瓦级别。这提示我们,在 计算 的能效比上,AI 系统仍有巨大的优化空间。
未来很可能是“两条腿走路”:一边继续攀登算力巅峰,以支撑更大规模的模型训练;另一边持续精进算法,让每一次计算都更加高效。
CPU 市场的新机会
英伟达推出了基于 ARM 架构的 Vera CPU,ARM 公司也推出了 AGI CPU,它们的目标都是进军数据中心,与英特尔、AMD 的 x86 阵营争夺市场。
这场竞赛才刚刚拉开帷幕。Agentic AI 确实为 CPU 市场注入了新的增长动力,创造了新的场景。但 x86 架构在数据中心各类复杂工作负载上拥有长期积累的软件生态与优化优势,ARM 阵营想要真正分得可观的市场份额,仍需时间。
一个值得关注的细节是,英特尔目前的 CPU 正处于产能受限的状态。这从侧面印证,由 Agentic AI 等因素驱动的 CPU 需求,正在快速增长。
对这类异构计算和系统架构的演进感兴趣?欢迎来 云栈社区 的 智能 & 数据 & 云 板块,与更多开发者一起交流前沿趋势与技术实践。
 发表于 2026-4-17 02:01:58
|
查看: 177|
回复: 0
发表于 2026-4-17 02:01:58
|
查看: 177|
回复: 0
