英国生物学家达尔文于 1859 年出版了震动学术界与宗教界的《物种起源》,书中提出了生物进化论——生命不断演变,物竞天择,适者生存。

其实,计算机技术的发展轨迹与生命演化如出一辙。如果我们只盯着当下,却不去梳理技术的来龙去脉,许多设计难免会让人摸不着头脑。遗憾的是,这恰恰是当今计算机教育的普遍现状——历史感缺席。正因如此,我们不妨从历史演进的角度,重新审视 CPU 以及它的发展历程。本篇文章,就先聚焦于 CPU 与复杂指令集 CISC。
什么是CPU?
从程序员的视角来看,CPU 其实是个相当单纯的家伙。

无论我们写的是简单的 Hello World,还是 Photoshop 这样的大型应用,最终都会被编译器翻译成一条条朴素的机器指令。在 CPU 眼里,所有程序并没有本质区别:无非是有的指令多一些,有的少一些罢了。这些指令保存在可执行文件里,程序运行时被加载到内存,CPU 便马不停蹄地逐条执行。它才不在乎你的程序是简是繁,埋头苦干就完了。所以说,CPU 是很纯粹的东西。如果你好奇 CPU 到底是怎么造出来的,也可以看看《你管这破玩意叫CPU》一文。
那么,CPU 执行的这些机器指令,到底是什么样的?接下来我们把目光进一步聚焦。
CPU的能力圈:指令集
描述一个人的能力,我们通常会说:会写代码、会炒菜、会唱歌……巴菲特给这种描述起了个好名字,叫“能力圈”。你可以吩咐一个人写代码,他就有能力写出代码来。CPU 也一样,每种 CPU 都有自己的能力圈,只不过它有个专属名词——指令集,也就是 Instruction Set Architecture (ISA)。指令集里规定了 CPU 能完成的各种任务,比如:会加法,会从内存把数据搬到寄存器,会跳转,会比较大小……总之,ISA 告诉程序员,这块 CPU 究竟能做什么。你从 ISA 里挑一条指令发给 CPU,CPU 就乖乖照办。
那 ISA 有什么用呢?当然是用来写程序的!在计算机的洪荒年代,程序员都直接面向 CPU,用汇编语言手写程序。那会儿还没那么多花哨的概念——面向对象、设计模式,统统不存在的。写代码嘛,查查 ISA 就够了。可以说,指令集就是 CPU 规定出来的、告诉程序员该怎样指挥自己干活的一套规范。
需要注意的是,不同 CPU 会采用不同类型的指令集,而指令集的类型不仅决定了汇编程序该怎么写,还会直接影响 CPU 的硬件设计走向。究竟该采用哪种指令集、如何设计 CPU?这场论战从诞生之初一直持续到现在,而且越来越精彩。
我们先来看最先诞生的一种指令集类型:复杂指令集(Complex Instruction Set Computer),也就是 CISC。如今统治桌面 PC 与服务器领域的 x86 架构,正是基于 CISC。生产 x86 处理器的,就是我们熟悉的那家“等,等等等等”的英特尔,以及 AMD。
抽象:少就是多
时间回到 20 世纪 70 年代,那时的编译器还很稚嫩,远没有如今这么聪明。没多少程序员敢完全信任编译器,绝大部分程序还是靠汇编语言纯手工编写的。这一点太关键了,它是我们理解复杂指令集诞生的底层逻辑。对现代程序员来说,这简直无法想象——别说手写汇编了,能把汇编代码看懂的都算少数了。当然,今天强大的编译器早已让我们几乎忘记了汇编的存在,这其实是生产力进步的体现:用高级语言写程序的效率,何止甩汇编几条街。
回到当时,大家每天都在手撸汇编,自然有一个很朴素的愿望:指令集能不能更丰富些?单条指令功能能不能更强些? 常用的操作,最好都有专属对应的一条指令。如果指令集又小、指令功能又单一,用汇编写程序就会无比繁琐、极其不便。换做你在那个年代,肯定也会这么想,而且这还可以缩小所谓的“语义鸿沟”——也就是高级语言的概念与底层机器指令之间的差距。所以,像函数调用、循环控制、复杂寻址、数据结构与数组访问这类高级语言中的常见概念,都应该有对应的机器指令。这正是今天我们所看到的复杂指令集 CISC 的鲜明特征。除了让汇编编程更顺手,当时还有一个更现实的刚需:存储极其昂贵。
物种起源
今天我们用的所有计算机,都遵从冯·诺依曼架构。该架构的核心思想之一就是:程序和数据一样,都作为比特存储在计算机的存储设备中。你正在阅读这篇文章所使用的任何设备——智能手机、平板、PC,或是托管这篇文章的微信后台服务器,其逻辑原型都是下面这张简单的图。可以说,它就是一切计算设备的起点。
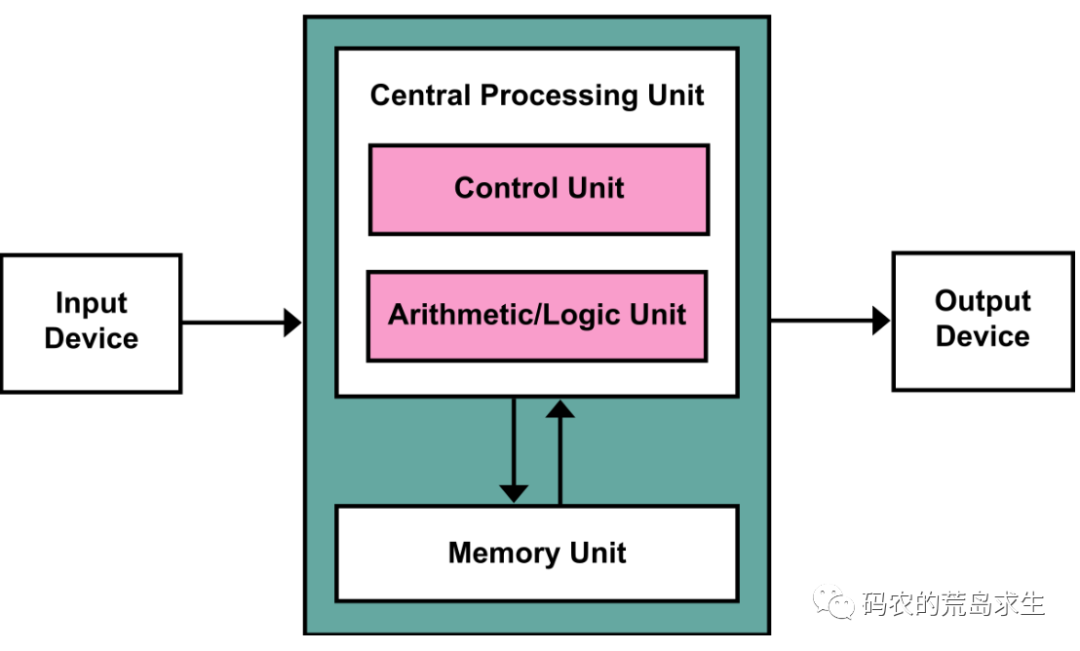
代码也是要占存储空间的
从冯·诺依曼结构中我们就能明白,为什么现在的可执行文件(比如 Windows 下的 EXE 或 Linux 下的 ELF)里,既包含着机器指令,也包含着数据。对程序员来说,不妨简单理解为可执行文件包含两大块:数据段与代码段。

可见,我们写下的代码,是要占据存储空间的。70 年代的内存有多大呢?只有几 KB 到几十 KB。今天的程序员恐怕很难想象——要知道,现在随便一部智能手机的内存都比这大上百万倍。下图就是 1974 年发布的 Intel 1103 内存芯片。

这款大小仅 1KB 的 Intel 1103 存储芯片发布于 1974 年,它的出现标志着计算机产业迈入动态随机存储器(DRAM)时代,也就是我们今天所熟知的“内存”。请各位想象一下,那时几 KB 的内存,真可谓寸土寸金。想用这么可怜的内存装下更多程序,就必须仔细推敲每一条指令的编码,以榨干每一点存储空间。 这自然催生出一些设计要求:
- 一条机器指令,最好能完成尽可能多的任务。道理很简单:你肯定更希望拥有一条“给我端杯水”这种高级指令,而不是自己去写“迈左脚;停下;迈右脚;走到饮水机;伸手;拿杯;接水……”这一大堆琐碎步骤。
- 机器指令长度可变,让简单指令尽量少占空间。
- 对机器指令进行高度编码,提升代码密度,省空间。
复杂指令集诞生的必然
让程序员用汇编编程更方便,同时尽可能节约代码占用的存储空间——这两股力量,直接推动了复杂指令集 CISC 的诞生。所以,CISC 在那个时代是无比自然且必然的选择,它也顺势成为主流。然而,过了些时日,新问题浮现出来:单条指令变复杂了,负责解码这些指令的硬件(CPU 的一部分),也跟着变得异常棘手。该怎么解决这个麻烦呢?
CPU真的在直接执行机器指令吗?
程序员都很熟悉一个操作:对于重复使用的代码,没必要一次次重写,把它封装成函数,每次调用就可以了。这个思路,同样可以用来化解解码硬件复杂度的困境。
指令集里的每一条机器指令,都可以对应 CPU 内部的一小段专用程序,这些程序由更简单、更底层的指令构成,我们称之为 “微代码”(Microcode)。
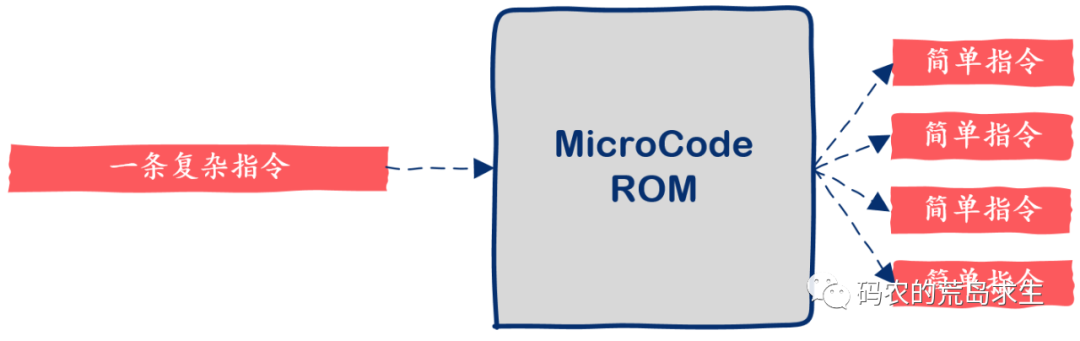
这个设计简直像开了挂一样:你想加多少条机器指令?没问题,在 CPU 里多加几段微代码就行了,成本相当低。在这里我们也看到了一个微妙之处:我们通常说 CPU 直接执行机器指令,严格来说并不完全准确。对于带有微代码设计的 CPU 而言,CPU 直接执行的是微代码,而不是机器指令本身。微代码实际上是横亘在 CPU 硬件与机器指令之间的一个中间层。机器指令对微代码来说,就像是一种更“高级的语言”。机器指令对程序员可见,但微代码对程序员不可见,程序员无法直接用它操控 CPU。

在那个年代,微代码普遍烧录在 ROM(只读存储器)中,而 ROM 要比 RAM 便宜不少。因此,利用廉价 ROM 中存放的微代码,去支持更多复杂的机器指令,从而间接节省程序本身对昂贵内存的占用,这笔账怎么算都划算。
新的问题
一切看起来都很美好:有了 CISC,程序员写汇编更顺手了,程序占的存储空间也降下来了,代价无非是 CPU 内部需要微代码帮衬一下。然而,随着时间的推移,这套设计也冒出了新的麻烦。
身为程序员,我们深知代码难逃 bug,微代码也不例外。但要命的是,修复微代码的 bug,远比修普通程序的 bug 困难得多。你没法像给应用做测试、调试那样去对待微代码,它太底层、太复杂了。而且,微代码方案非常消耗晶体管。1979 年的 Motorola 68000 处理器就采用了这种设计,有将近三分之一的晶体管,都投在了微代码上。同一年,计算机科学家 Dave Patterson 受命去改善微代码设计,为此还专门发表了论文——可他后来居然推翻了自己的想法,认为微代码设计的复杂性问题根深蒂固,真正出问题的正是微代码这整套思路本身。于是,一些先行者开始反思:会不会存在一种更好的路数呢?
预知后事如何,请听下回分解。
总结
CPU 是整个计算机系统中的核心,而 CPU 指令集(ISA)则是核心中的核心。本文从历史脉络出发,梳理了复杂指令集 CISC 诞生的必然性。对于那个时代直接手写汇编的程序员来说,CISC 无疑提供了极大的便利,同时更高的指令密度也让寸土寸金的内存能够塞进更多程序,这些因素共同将 CISC 推向了历史主流。然而,凡事有得必有失,CISC 也不例外。随着时间推移,采用 CISC 的 CPU 设计逐渐暴露出种种难题。面对这些问题,一些人开始重新思索指令集的未来方向。我们将在后续文章中继续讲述这段故事,希望本篇能为各位理解复杂指令集带来一些帮助。
在计算机底层的世界里,很多技术往往像生物进化一样,是对当时环境下各种约束的最优解。如果你对计算机体系结构、编译原理等基础领域感兴趣,不妨在云栈社区深入看看。
 发表于 2026-6-1 03:12:59
|
查看: 162|
回复: 0
发表于 2026-6-1 03:12:59
|
查看: 162|
回复: 0
