循环神经网络(Recurrent Neural Network,简称 RNN)是一类专门为处理序列数据而设计的神经网络模型。它与传统的前馈神经网络(Feedforward Neural Network)的核心区别在于,RNN 能够有效捕捉并利用数据中的顺序依赖、上下文关联等时序信息。
典型的序列数据包括自然语言文本(如句子、段落)、时间序列数据(如股票价格、天气变化)等。因此,RNN 在语音识别、语言建模、机器翻译以及时序预测分析等任务中扮演着关键角色。
RNN 处理的任务示例:命名实体识别 (NER)
命名实体识别(Named Entity Recognition, NER)任务的目标是从自然语言文本中识别出表示真实世界实体的名称及其类别。例如:
- 句子(1):
I like eating apple! 中的 apple 指代的是 苹果(食物)。
- 句子(2):
The Apple is a great company! 中的 Apple 指代的是 苹果(公司)。
如果我们使用普通的深度神经网络(DNN)来处理,输入方式通常是逐元素独立地输入模型。这会导致上下文语义信息的丢失,模型只能根据词的孤立特征进行判断。在上面的例子中,如果训练数据集中“apple”一词大多被标注为食物,那么测试时所有“apple”都将被错误地分类为食物,反之亦然。而 RNN 的设计,正是为了解决这种无法有效利用上下文信息的缺陷。
RNN 的基本模型结构
为了解决 DNN 在处理序列数据时的局限性,RNN 最根本的改进是引入了一个“记忆模块”,用于存储历史上下文信息。下图展示了一个经典 RNN 的结构示意图:
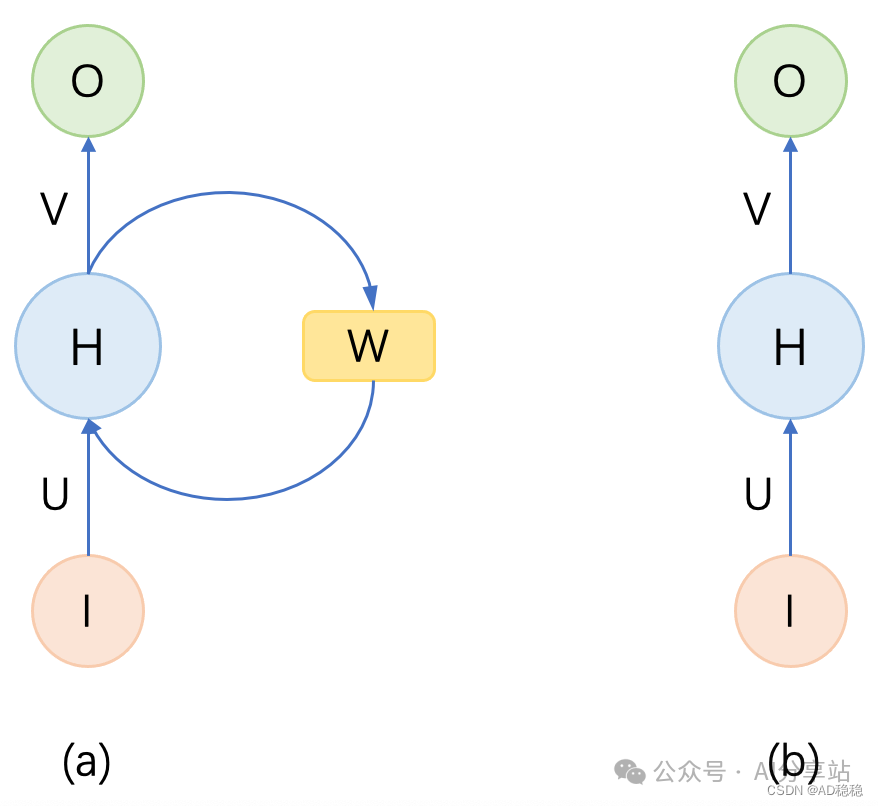
图 (a) 展示了一个典型的 RNN 结构。初次接触可能不易理解,我们可以先忽略图中右侧的权重矩阵 $W$,只看左侧的网络结构,即图 (b)。图 (b) 实际上就是一个标准的前馈神经网络。回过头来看图 (a),RNN 相较于前馈网络,核心在于增加了一个用于保存和传递上下文信息的权重矩阵 $W$。这意味着,模型在计算当前时刻的输出时,不仅要考虑当前的输入数据,还要结合之前所有时刻处理过的序列信息。
RNN 的展开结构与计算
我们已经知道 RNN 通过权重矩阵 $W$ 来传递上下文信息。接下来,我们深入其计算过程。为了更直观地理解 RNN 如何沿时间序列工作,我们将其“展开”。下图是 RNN 在时间维度上的展开示意图:
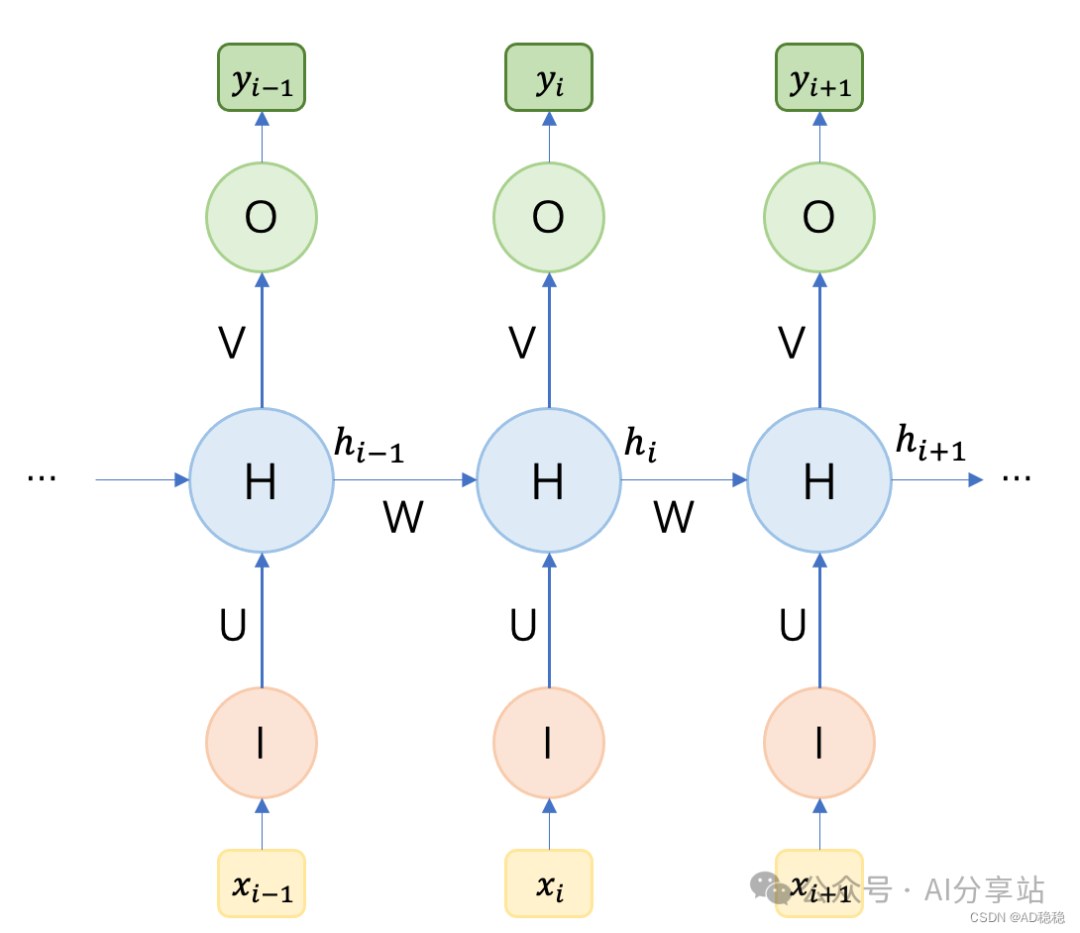
其中 $x_i$ 表示 $i$ 时刻的模型输入,$y_i$ 表示对应的输出。RNN 的核心计算公式如下:
$y_i = g(Vh_i)$
$h_i = f(Ux_i + Wh_{i-1})$
从公式中可以清晰地看到,隐藏层的输出 $h_i$ 不仅与当前时刻的输入 $x_i$ 有关,还与上一时刻的隐藏状态 $h_{i-1}$ 紧密相关。因此,我们可以认为 $h_{i-1}$ 承载了影响当前输入的所有历史“上下文”信息。而可学习的参数矩阵 $W$ 则决定了历史信息对当前时刻的影响程度。在整个序列处理过程中,参数 $U$, $V$, $W$ 是共享的,这大大减少了模型参数量,也体现了 RNN 处理序列的核心思想。
RNN 的四种主要结构变体
根据输入序列与输出序列长度关系的不同,常见的 RNN 结构可以分为四类:N to N, N to 1, 1 to N 以及 N to M。
1. N to N 结构
这是最基本的 RNN 结构,输入序列长度与输出序列长度一致。每一个输入时间步都对应一个输出。这种结构适用于序列标注、视频逐帧分类、命名实体识别(NER)、分词等任务。
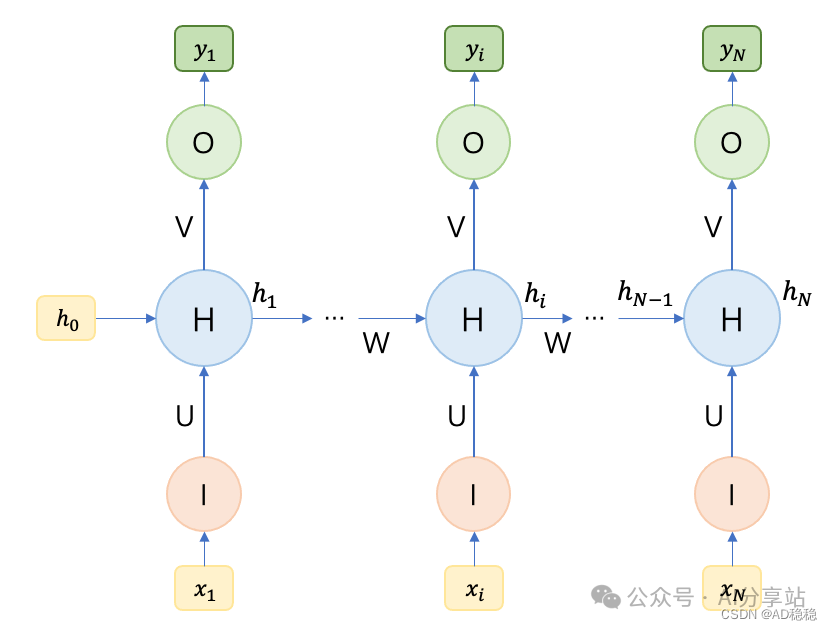
其计算方式与上述基础公式一致:
$y_i = g(Vh_i)$
$h_i = f(Ux_i + Wh_{i-1})$
2. N to 1 结构
这种结构输入一个完整序列,但只输出一个结果(通常是最后一个时间步对应的输出)。这个单一的输出凝聚了整个输入序列的语义和上下文信息。
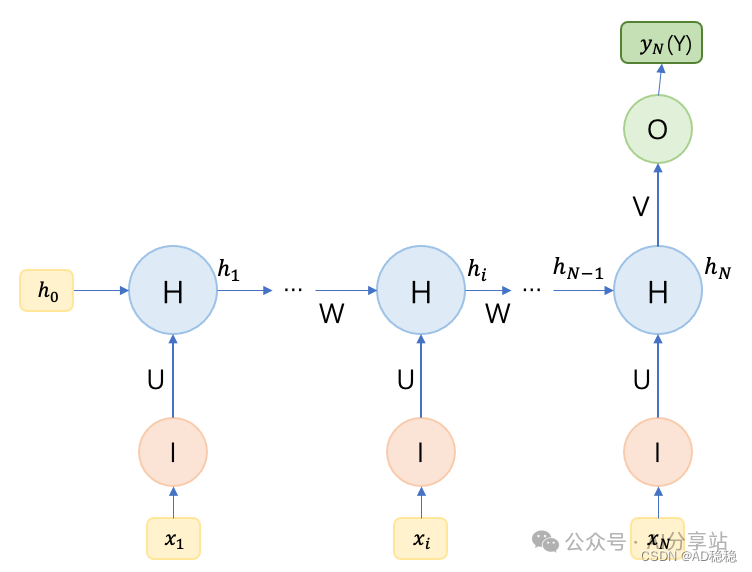
计算方式如下:
$Y = y_{N} = g(Vh_N)$
$h_i = f(Ux_i + Wh_{i-1})$
常见的应用场景包括:文本分类、情感分析、文章分类等。通过对序列信息的整合,RNN 能够做出更全局的判断。
3. 1 to N 结构
这种结构接收一个输入(可以视为一个“种子”或起始信号),然后生成一个完整的输出序列。这非常适合于生成式任务。
根据输入的应用方式,又可分为两种子结构:仅在第一个时刻输入(下图左),或在每一个时刻都输入相同的向量(下图右)。
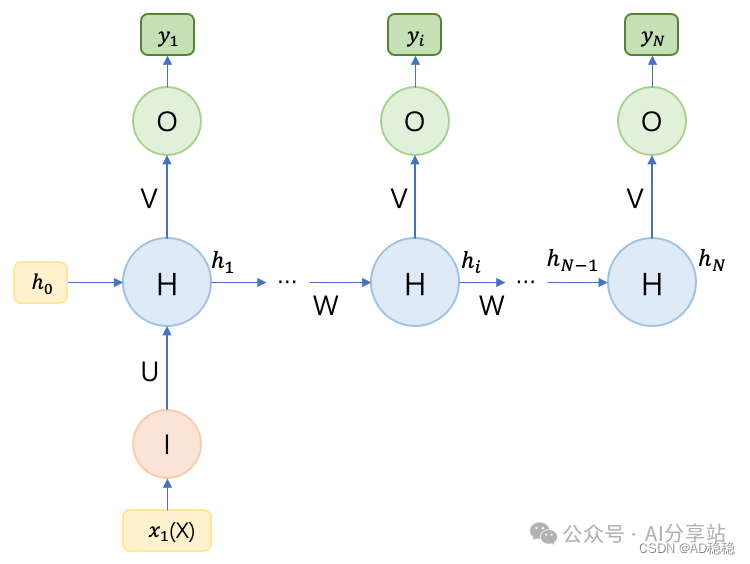
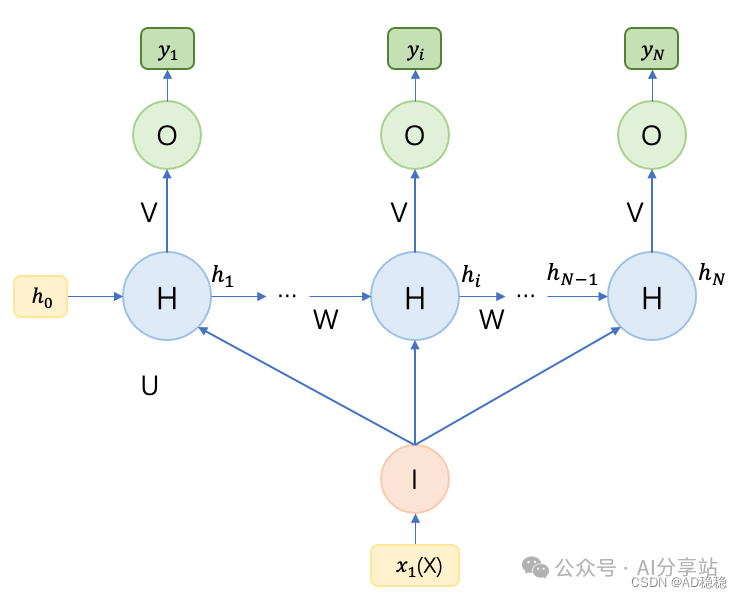
第一种(仅在首时刻输入)的计算方法:
$y_i = g(Vh_i)$
$h_i = \begin{cases} f(Wh_{i-1}) & \text{where } i > 1 \\ f(Ux_1 + Wh_0) & \text{where } i = 1 \end{cases}$
第二种(每个时刻均输入)的计算方法:
$y_i = g(Vh_i)$
$h_i = f(Ux_1 + Wh_{i-1})$
1 to N 结构 RNN 常用于根据图像生成描述文字(Image Captioning)、根据特定类别或风格生成音乐、诗歌,或进行代码补全等任务。
4. N to M 结构 (Encoder-Decoder / Seq2Seq)
这是最强大且通用的一种结构,输入序列和输出序列的长度可以不同($N \neq M$)。它通常由两部分组成:一个编码器(Encoder)和一个解码器(Decoder),因此也被称为编码器-解码器模型或序列到序列(Seq2Seq)模型。
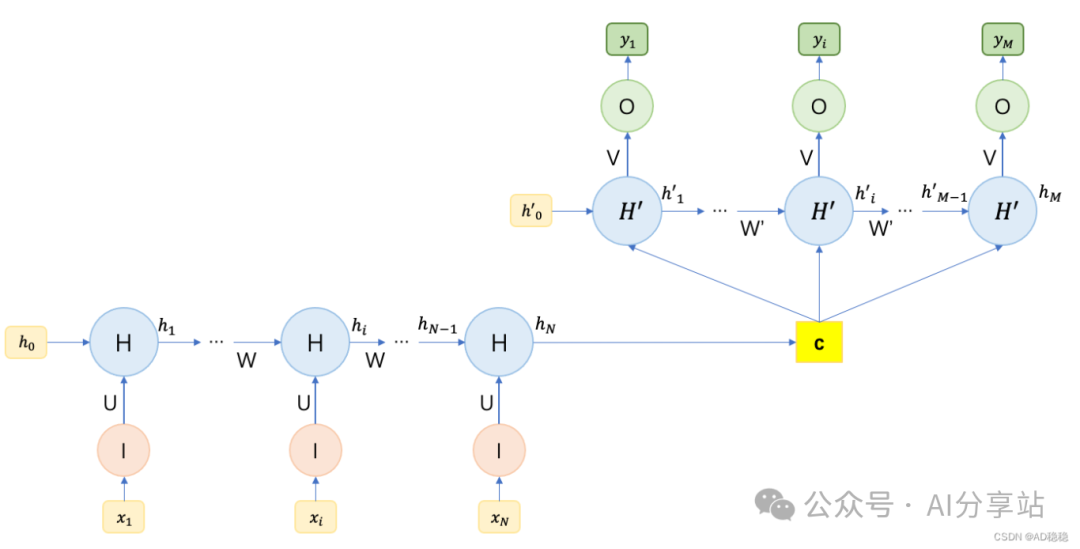
如图所示,模型首先用一个 RNN(Encoder)将整个输入序列编码为一个固定长度的上下文向量(Context Vector) $c$,这个向量包含了输入序列的全部语义信息。然后,再用另一个 RNN(Decoder)以 $c$ 为条件,逐步生成输出序列。在图示结构中,$c$ 被作为 Decoder 每个时间步的额外输入。
另一种常见做法是利用 $c$ 来初始化 Decoder 的初始隐藏状态 $h‘_0$,结构如下:
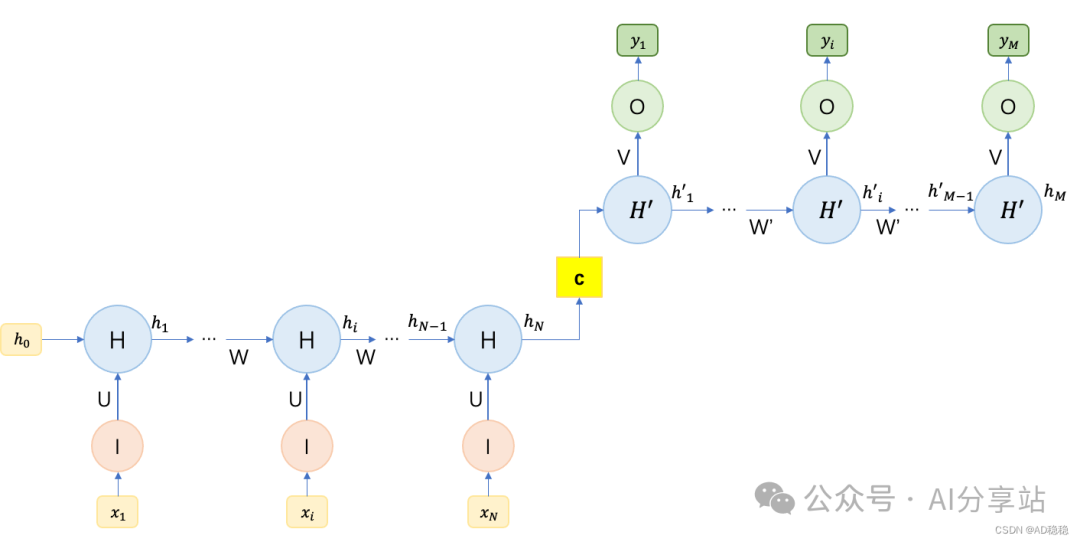
上下文向量 $c$ 的计算方式主要有三种:
- $c = h_N$ (直接使用 Encoder 最后的隐藏状态)
- $c = g(h_N)$ (对 Encoder 最后的隐藏状态做一次变换)
- $c = g(h_1, h_2, ..., h_N)$ (利用 Encoder 所有时间步的隐藏状态进行计算,这其实就是注意力机制(Attention Mechanism)的思想雏形)
N to M 结构极大地扩展了 RNN 的应用范围,使其能够胜任机器翻译、语音识别、文本摘要、对话生成等复杂任务。
RNN 的挑战:梯度消失与梯度爆炸
问题根源
由于 RNN 在时间维度上共享参数 $W$,在进行反向传播算法计算梯度时,损失函数对 $W$ 的偏导数会涉及沿着时间步的连乘运算($\prod$)。如果 $W$ 的特征值(或广义的“大小”)长期小于 1,经过多次连乘后梯度会指数级衰减至接近 0,导致模型无法更新学习,这就是梯度消失(Vanishing Gradient)。反之,如果 $W$ 的特征值长期大于 1,梯度则会指数级增长,变得异常巨大,导致训练不稳定,这就是梯度爆炸(Exploding Gradient)。
值得注意的是,RNN 的梯度消失/爆炸是沿着时间维度发生的,与深度前馈网络因层数过深导致的梯度问题有相似之处,但成因更为特定于序列处理的特性。
解决方案
-
应对梯度爆炸:
- 梯度裁剪(Gradient Clipping):在梯度更新前,设置一个阈值。如果梯度的范数超过这个阈值,就将其按比例缩放到阈值以内。这是一个简单有效的工程方法。
-
应对梯度消失:
- 使用 ReLU 等激活函数:ReLU 函数在正区间的导数为常数 1,这在一定程度上有助于缓解因激活函数饱和(如 tanh, sigmoid)导致的梯度衰减。
- 改进网络结构:这是更根本的解决方案。研究者们提出了具有门控机制(Gating Mechanism)的 RNN 变体,最著名的就是长短期记忆网络(LSTM)和门控循环单元(GRU)。这些结构通过精妙设计的“门”来控制信息的遗忘、记忆和输出,从而有效地解决了长程依赖中的梯度消失问题,成为了现代 深度学习 处理序列数据的基石。关于 LSTM 和 GRU 的详细原理,将在后续文章中探讨。
如果你对人工智能和序列模型的更多实践与讨论感兴趣,欢迎到技术社区交流分享。从基础的 RNN 到如今复杂的 Transformer,理解序列模型的演变是掌握现代 AI 技术的必经之路。
 发表于 2026-4-17 23:18:48
|
查看: 127|
回复: 0
发表于 2026-4-17 23:18:48
|
查看: 127|
回复: 0
